- Generative KI
- Amazon Bedrock
- Auswertungen
Amazon-Bedrock-Bewertungen
Evaluieren Sie Basismodelle, einschließlich benutzerdefinierter und importierter Modelle, um Modelle zu finden, die Ihren Anforderungen entsprechen. Sie können Ihren Abruf- oder durchgehenden RAG-Workflow auch in den Wissensdatenbanken von Amazon Bedrock auswerten.
Übersicht
Amazon Bedrock stellt Ihnen Evaluierungstools zur Verfügung, mit denen Sie die Einführung von Anwendungen für generative KI schneller und einfacher vorantreiben können. Evaluieren, vergleichen und wählen Sie das Basismodell für Ihren Anwendungsfall mithilfe der Modellbewertung aus. Bereiten Sie Ihre RAG-Anwendungen für den Produktionseinsatz vor – ob auf Amazon-Bedrock-Wissensdatenbanken oder auf Ihren eigenen benutzerdefinierten RAG-Systemen basierend – und evaluieren Sie dabei die Funktionen zum reinen Abrufen oder zum Abrufen und Generieren.
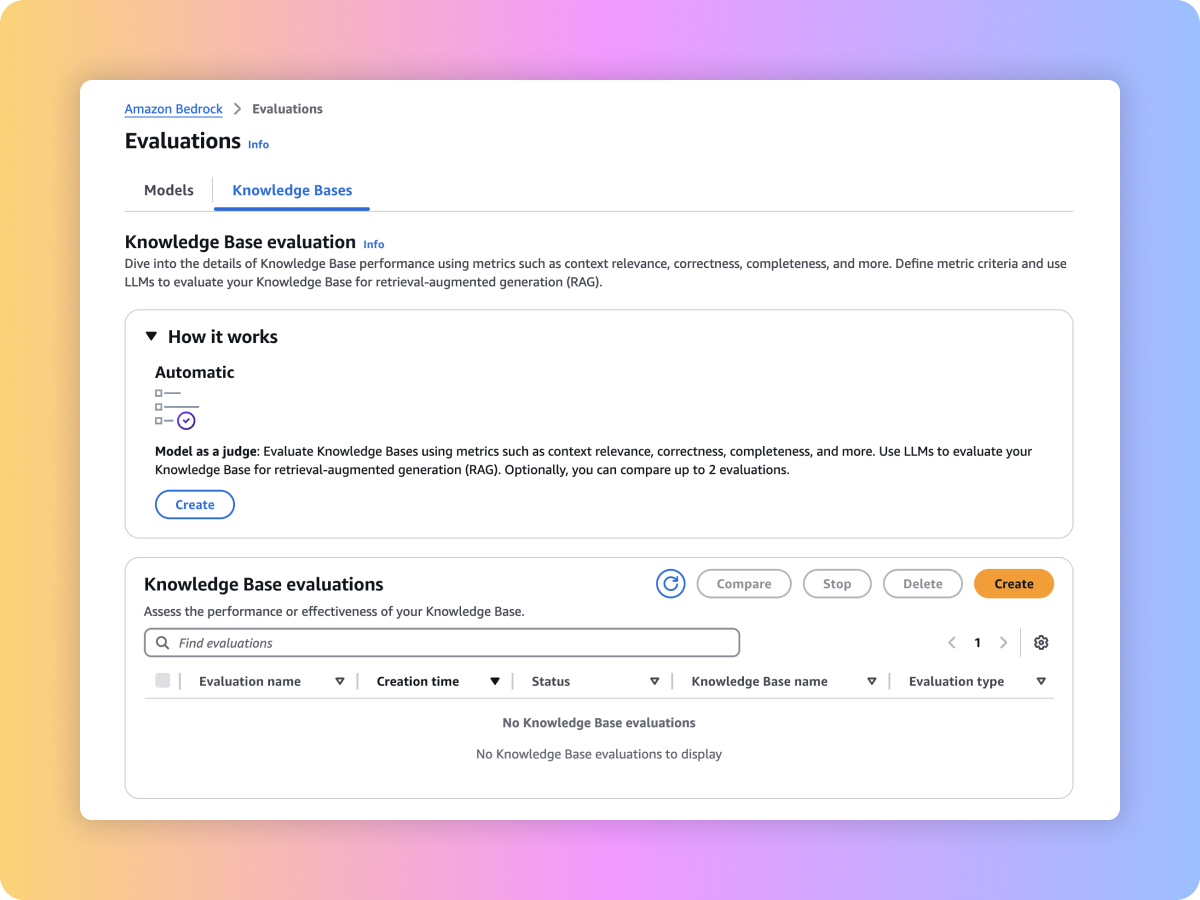
Bewertungstypen
Verwenden Sie LLM-as-a-Judge, um Modell-Ausgaben anhand Ihrer benutzerdefinierten Prompt-Datensätze mit Metriken wie Richtigkeit, Vollständigkeit und Schädlichkeit zu bewerten.
Evaluieren Sie Modellergebnisse mithilfe traditioneller Algorithmen und Metriken in natürlicher Sprache – etwa BERT Score, F1 und andere exakte Vergleichstechniken – und nutzen Sie dafür integrierte Prompt-Datensätze oder bringen Sie Ihre eigenen mit.
Bewerten Sie die Modellausgaben mit Ihren eigenen Mitarbeitern – oder überlassen Sie AWS die Verwaltung der Bewertungen für die Antworten auf Ihre benutzerdefinierten Prompt-Datensätze, wahlweise mit integrierten oder benutzerdefinierten Metriken.
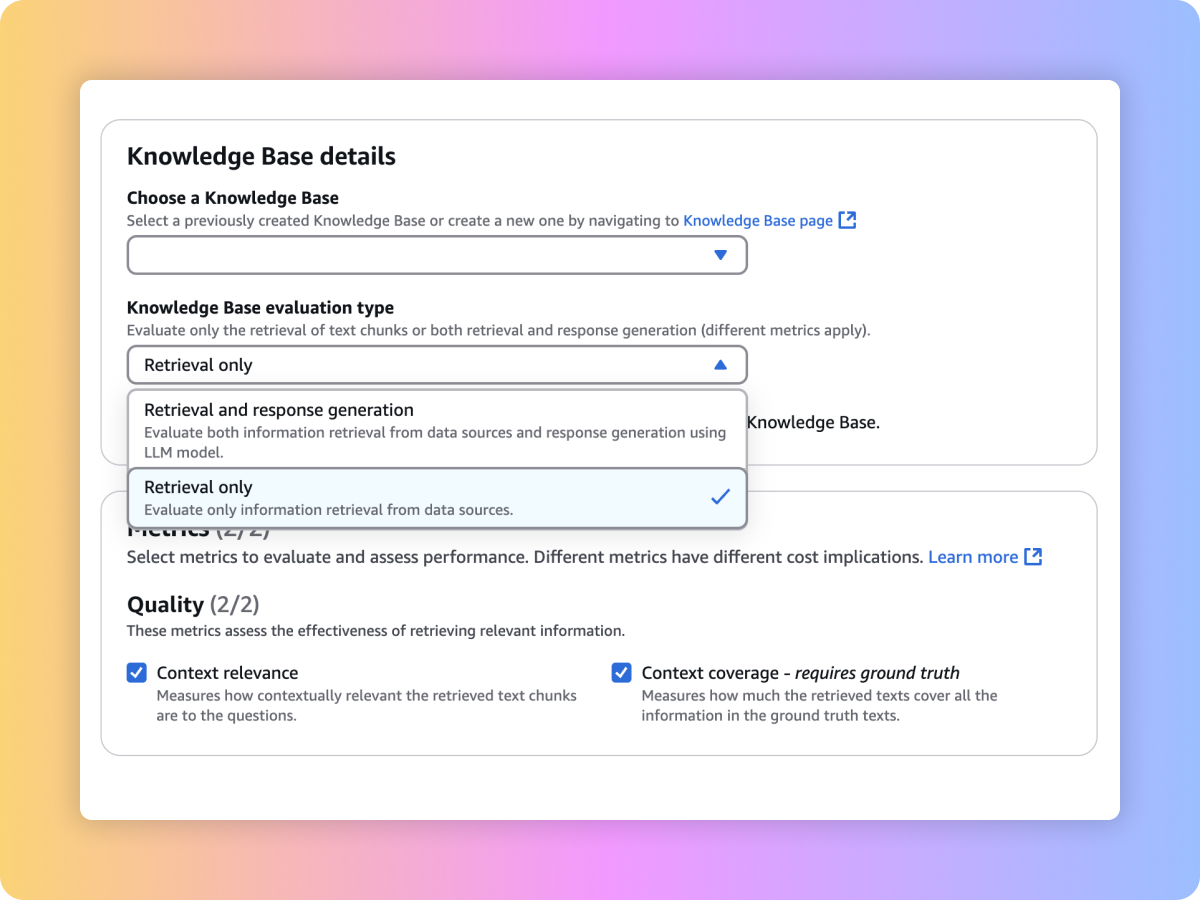
Bewerten Sie die Abrufqualität Ihres benutzerdefinierten RAG-Systems auf Amazon-Bedrock-Wissensdatenbanken mit Ihren benutzerdefinierten Prompts und Metriken wie Kontextrelevanz und Kontextabdeckung.
Evaluieren Sie den generierten Inhalt Ihres umfassenden RAG-Workflows entweder aus Ihrer benutzerdefinierten RAG-Pipeline oder aus den Amazon-Bedrock-Wissensdatenbanken. Verwenden Sie Ihre eigenen Prompts und Metriken wie Treue (Halluzinationserkennung), Richtigkeit und Vollständigkeit.
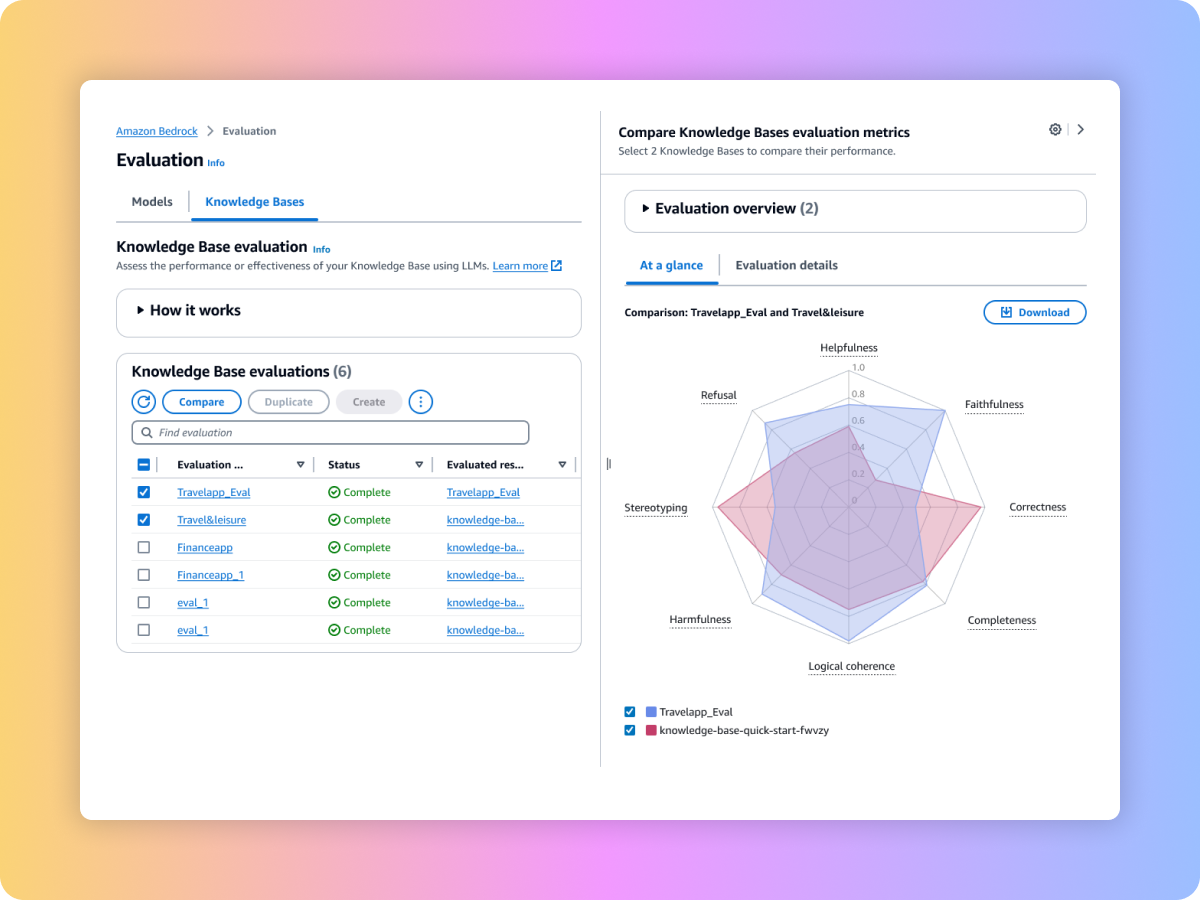
Ihren durchgängigen RAG-Workflow evaluieren
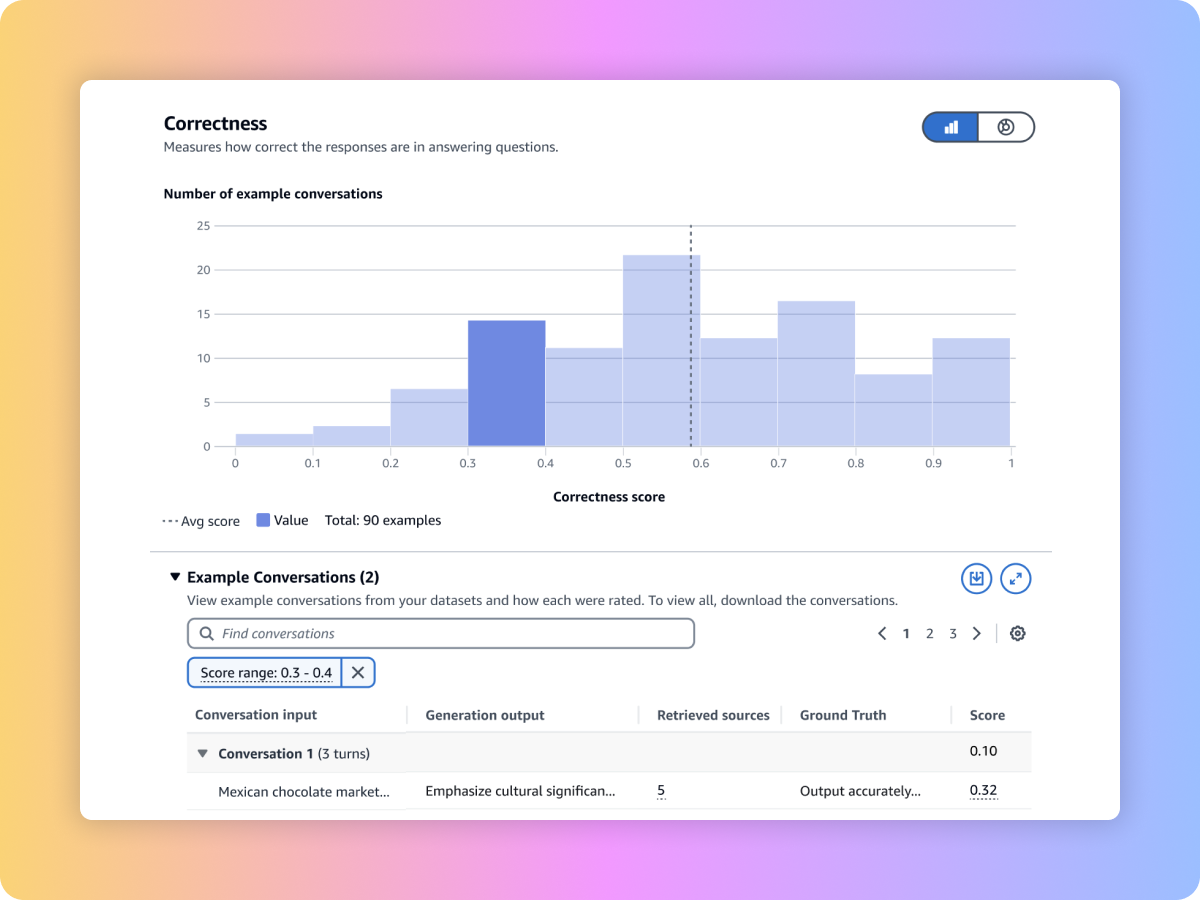
Gewährleisten Sie einen vollständigen und relevanten Abruf aus Ihrem RAG-System
Bewerten Sie FMs, um das Beste für Ihren Anwendungsfall auszuwählen
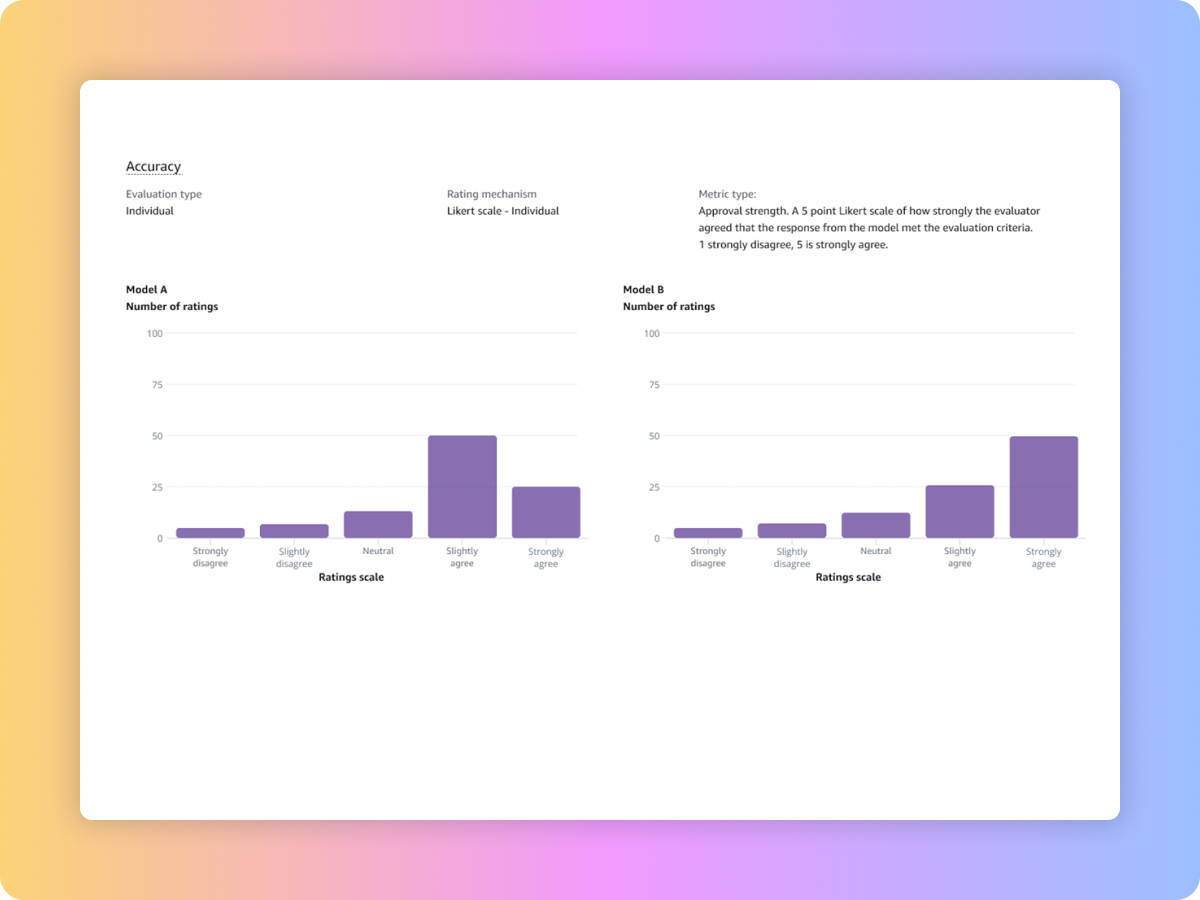
Vergleichen Sie die Ergebnisse mehrerer Bewertungsaufträge, um schneller Entscheidungen zu treffen