- Generative KI
- Amazon Bedrock
- Wissensdatenbanken
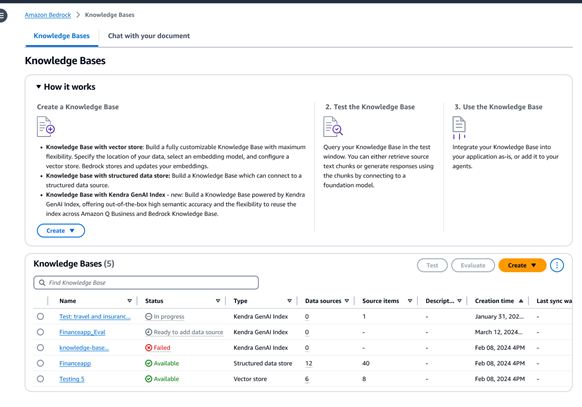
Amazon Bedrock Knowledge Bases
Mit Amazon Bedrock Knowledge Bases können Sie Basismodellen und Agenten kontextbezogene Informationen aus den privaten Datenquellen Ihres Unternehmens zur Verfügung stellen, um relevantere, genauere und individuellere Antworten liefern zu können
Vollständig verwaltete Unterstützung für einen durchgängigen RAG-Workflow
Um Basismodelle (FMs) mit aktuellen und geschützten Informationen auszustatten, verwenden Organisationen Retrieval Augmented Generation (RAG), eine Technik, die Daten aus Unternehmensdatenquellen abruft und den Prompt anreichert, um relevantere und genauere Antworten zu liefern. Amazon Bedrock Knowledge Bases ist eine vollständig verwaltete Funktion mit integriertem Sitzungskontextmanagement und Quellenangabe, die Sie bei der Implementierung des gesamten RAG-Workflows, von Erfassung über den Abruf bis hin zur Prompt-Erweiterung unterstützt, ohne dass Sie benutzerdefinierte Integrationen zu Datenquellen erstellen und Datenflüsse verwalten müssen. Sie können auch Fragen stellen und Daten aus einem einzigen Dokument zusammenfassen, ohne eine Vektordatenbank einrichten zu müssen. Wenn Ihre Daten strukturierte Quellen enthalten, bietet Amazon Bedrock Knowledge Bases eine integrierte Lösung für die Generierung eines Abfragebefehls zum Abrufen der Daten in strukturierter Abfragesprache (SQL), ohne dass diese in einen anderen Speicher verschoben werden müssen.
Sichere Verbindung von FMs und Agenten mit Datenquellen
Wenn Sie über unstrukturierte Datenquellen verfügen, ruft Amazon Bedrock Knowledge Bases automatisch Daten aus Quellen wie Amazon Simple Storage Service (Amazon S3), Confluence, Salesforce, SharePoint oder Web Crawler in der Vorversion ab. Darüber hinaus erhalten Sie eine programmatische Dokumentaufnahme, sodass Kunden Streaming-Daten oder Daten aus nicht unterstützten Quellen aufnehmen können. Nach der Aufnahme des Inhalts unterteilt Amazon Bedrock Knowledge Bases den Inhalt in Textblöcke, den Text in Einbettungen und speichert die Einbettungen in Ihrer Vektordatenbank. Sie können aus mehreren unterstützten Vektor-Stores wählen, darunter Amazon Aurora, Amazon Opensearch Serverless, Amazon Neptune Analytics, MongoDB, Pinecone und Redis Enterprise Cloud. Sie können sich auch dafür entscheiden, eine Verbindung zu einem Amazon-Kendra-Hybridsuchindex für den verwalteten Abruf herzustellen.
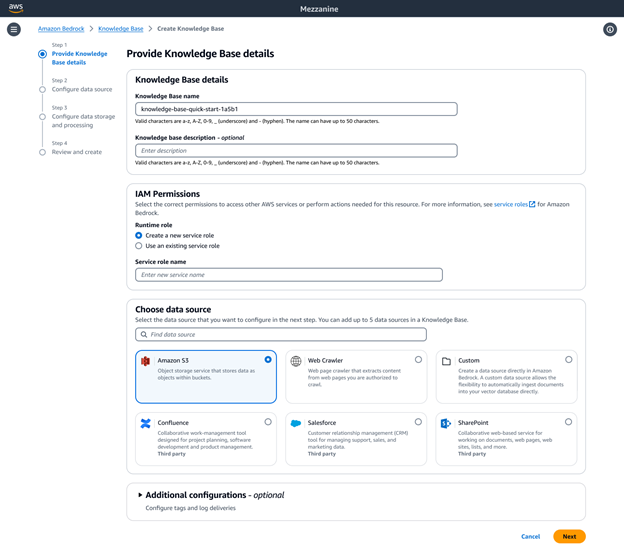
Mithilfe von Amazon Bedrock Knowledge Bases können Sie auch eine Verbindung zu Ihren strukturierten Datenspeichern herstellen, um fundierte Antworten zu generieren. Dies kann besonders nützlich sein, wenn Sie Quellmaterial wie Transaktionsdetails haben, die in Data Warehouses und Data Lakes gespeichert sind. Amazon Bedrock Knowledge Bases verwendet natürliche Sprache in SQL, um Abfragen in SQL-Befehle zu konvertieren und die Befehle zum Abrufen der Daten auszuführen, ohne sie aus Ihrer Quelldatenquelle verschieben zu müssen.
Anpassung von Amazon Bedrock Knowledge Bases, um genaue Antworten zur Laufzeit zu liefern
Mit Amazon Bedrock Knowledge Bases als vollständig verwaltete RAG-Lösung haben Sie die Flexibilität, die Abrufgenauigkeit anzupassen und zu verbessern. Für unstrukturierte Datenquellen, die multimodale Daten wie Bilder und visuell reichhaltige Dokumente mit komplexen Layouts (etwa Dokumente mit Tabellen, Abbildungen, Diagrammen und Schaubildern) enthalten, können Sie Wissensdatenbanken so konfigurieren, dass sie diese analysieren und daraus aussagekräftige Erkenntnisse extrahieren. Als Parser können Sie Bedrock Data Automation oder Basismodelle wählen. Dies ermöglicht die nahtlose Verarbeitung komplexer multimodaler Daten, sodass Sie hochpräzise GenAI-Anwendungen erstellen können.
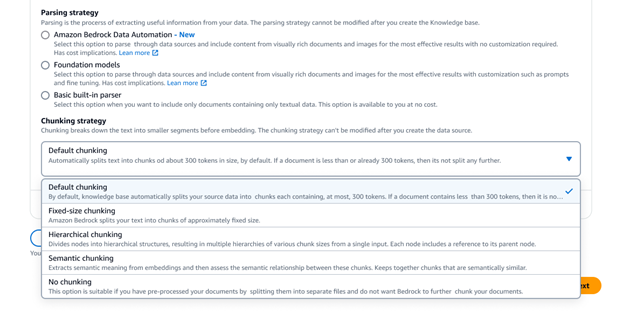
Amazon Bedrock Knowledge Bases bietet eine Vielzahl erweiterter Datenaufteilungsoptionen, darunter semantisches, hierarchisches Chunking und Chunking mit fester Größe. Für vollständige Kontrolle können Sie auch ihren eigenen Chunking-Code als Lambda-Funktion schreiben und sogar fertige Komponenten aus Frameworks wie LangChain und LlamaIndex verwenden. Wenn Sie Amazon Neptune Analytics als Vektorspeicher auswählen, erstellt Amazon Bedrock Knowledge Bases automatisch Einbettungen und Diagramme, die verwandte Inhalte über Ihre Datenquellen hinweg verknüpfen. Bedrock Knowledge Bases nutzt diese Inhaltsbeziehungen mit GraphRAG, um die Genauigkeit der Abfrage zu verbessern und umfassendere, relevantere und erklärbare Antworten für Endbenutzer zu ermöglichen.
Daten abrufen und Prompts erweitern
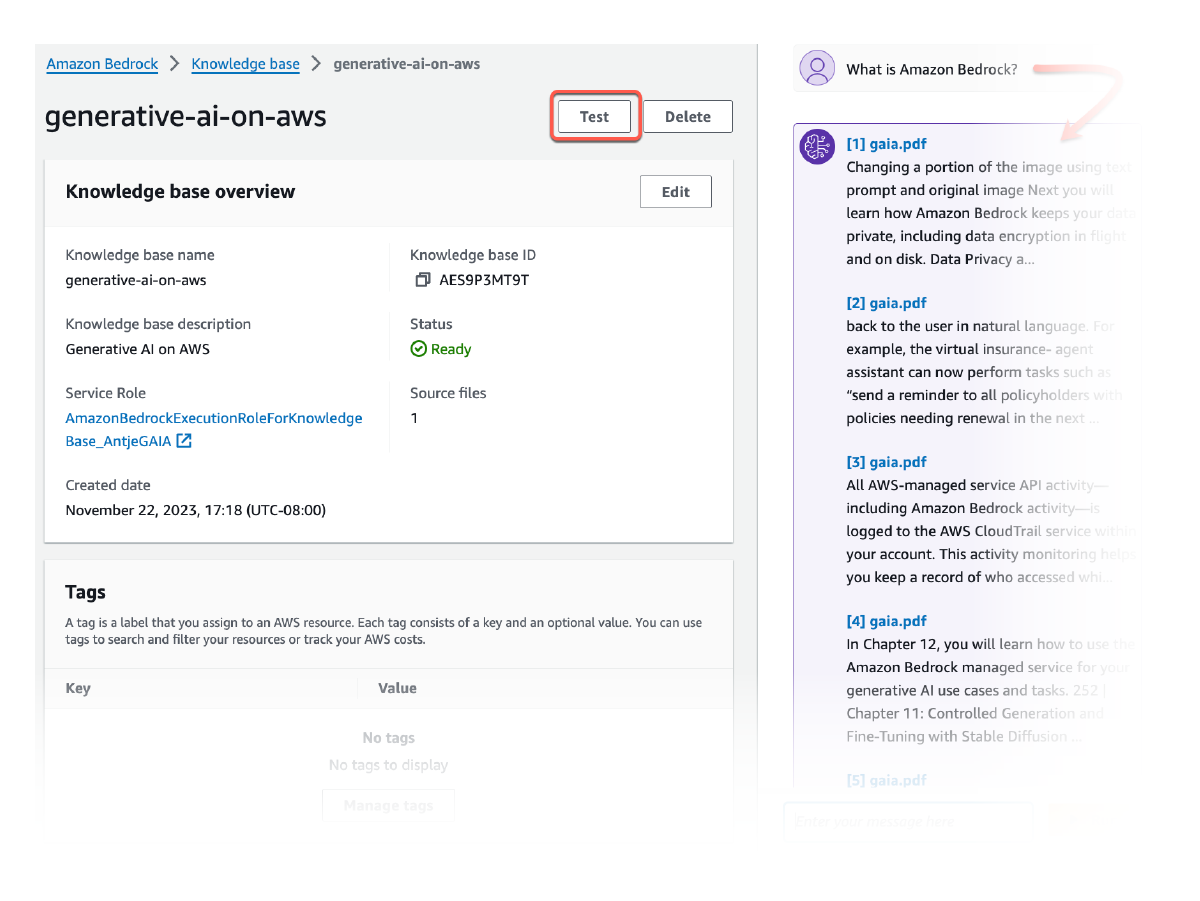
Mit der Retrieve-API können Sie relevante Ergebnisse für eine Benutzerabfrage aus Wissensdatenbanken abrufen, einschließlich visueller Elemente wie Bilder, Diagramme, Grafiken, Tabellen, Audio- und Videoinhalte oder strukturierter Daten aus Datenbanken, falls zutreffend. Die RetrieveAndGenerate-API geht noch einen Schritt weiter, indem sie die abgerufenen multimodalen Ergebnisse direkt verwendet, um den FM-Prompt zu ergänzen und die Antwort zurückzugeben. Sie können auch Filter bereitstellen oder FM verwenden, um implizite Filter zu generieren, um die zurückgegebenen Ergebnisse auf die relevanten Inhalte zu beschränken. Amazon Bedrock Knowledge Bases bietet Reranker-Modelle, um die Relevanz der abgerufenen Dokumentblöcke für Text-, Bild- und Multimediainhalte zu verbessern.
Quellenangabe benennen
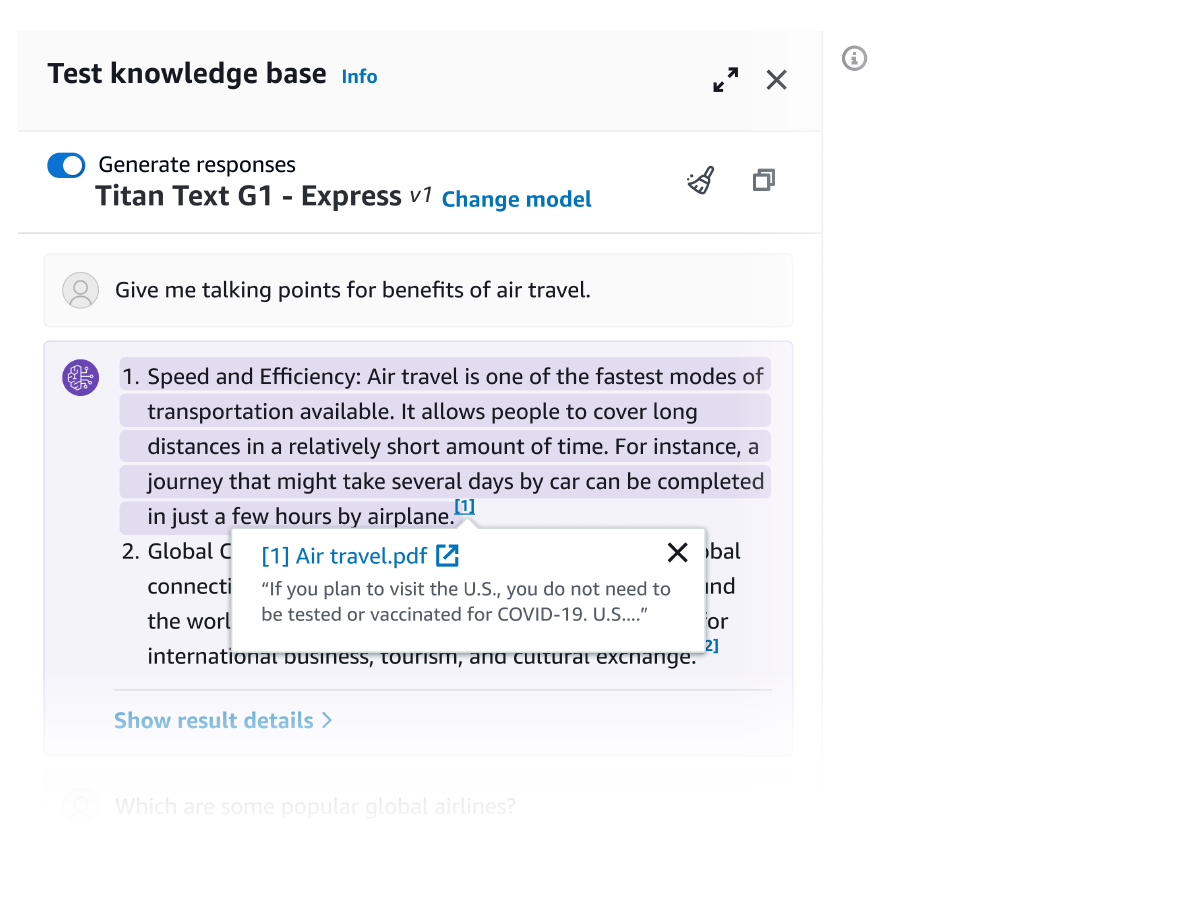
Alle aus Amazon Bedrock Knowledge Bases abgerufenen Informationen werden mit Zitaten (die auch visuelle Elemente enthalten) versehen, um die Transparenz zu verbessern und Halluzinationen zu minimieren.
Erste Schritte
Haben Sie die gewünschten Informationen gefunden?
Ihr Feedback hilft uns, die Qualität der Inhalte auf unseren Seiten zu verbessern.