Datenfreigabe in Amazon Redshift
Daten sicher zwischen Warehouses teilen, ohne Daten zu kopieren
Vorteile
-
Stellen Sie Daten für die Verwendung in mehreren Warehouses zur Verfügung, sobald sie sich in einer Amazon-Redshift-Datenbank befinden. Extract, Transform, Load (ETL) der Daten über ein einziges Warehouse, die Daten sind innerhalb und zwischen Unternehmen und AWS-Regionen zugänglich. Dateningenieure müssen keine zahlreichen Pipelines mehr erstellen und warten, welche die Daten an verschiedene Orte übertragen.
-
Greifen Sie auf Daten mit der Rechenleistung Ihrer Wahl zu: verschiedene Größen (Knoten oder RPUs), Typen (bereitgestellt oder Serverless) und Preispläne (On-Demand oder Reserved Instances). Wählen Sie das Warehouse nach den Preis-/Leistungsanforderungen des Teams, der Anwendung oder des Workloads aus. Verfolgung und Überwachung der Nutzung durch die einzelnen Teams, Kostenkontrolle und Erhöhung der Transparenz
-
Beseitigung von Datensilos und Datenduplikaten, weil die Teams die Daten nicht von einem Ort zum anderen verschieben oder kopieren müssen. Teams können an Live-Daten direkt an der Quelle zusammenarbeiten, um schnell auf Daten reagieren zu können. Der Zugriff wird zentral über AWS Lake Formation gesteuert, was eine differenzierte Zugriffskontrolle ermöglicht.
-
Greifen Sie sicher und einfach auf Daten von Drittanbietern zu, ohne manuelle Lizenzierungsprozesse oder ETL-Vorgänge in Ihrem Warehouse durchführen zu müssen. Abonnieren Sie einfach den Datensatz in AWS Data Exchange von Amazon Redshift aus. Datenanbieter können ihre Daten zu Geld machen und ihren Kunden einen Mehrwert bieten, indem sie die Daten mit nur wenigen Klicks in Kunden-Warehouses zur Verfügung stellen
Datenfreigabe in Amazon Redshift
Mit Amazon Redshift können Sie Daten innerhalb und zwischen Organisationen, AWS-Regionen und sogar Drittanbietern gemeinsam nutzen, ohne die Daten verschieben oder kopieren zu müssen. Lesen und Schreiben in dieselben Redshift-Datenbanken mithilfe mehrerer Data Warehouses und erweitern Sie die Benutzerfreundlichkeit, Leistung und Kostenvorteile, die Amazon Redshift für Data Mesh-Architekturen mit mehreren Warehouses bietet. Ermöglichen Sie den sofortigen Zugriff auf aktuelle Daten innerhalb und im gesamten Unternehmen, wodurch mehrere ETL-Pipelines (Extract, Transform, Load) entfallen, was die Zusammenarbeit an Daten ermöglicht und die Zeit für die Gewinnung von Erkenntnissen verkürzt. Darüber hinaus können Sie mehrere Warehouses verschiedener Typen/Größen für ETL verwenden, sodass Sie Ihre Warehouses auf der Grundlage der Preis-Leistungs-Anforderungen Ihrer Schreib-Workloads abstimmen können. Durch die Integration in AWS Data Exchange, den AWS-Marktplatz mit Tausenden von Datensätzen von Drittanbietern, können Amazon Redshift-Benutzer einfach und sicher Datensätze von Drittanbietern lizenzieren, um sie mit den Daten in ihren Redshift-Datenbanken zu kombinieren, um eine ganzheitliche Analyse durchzuführen und neue Möglichkeiten zur Datenmonetarisierung zu nutzen.
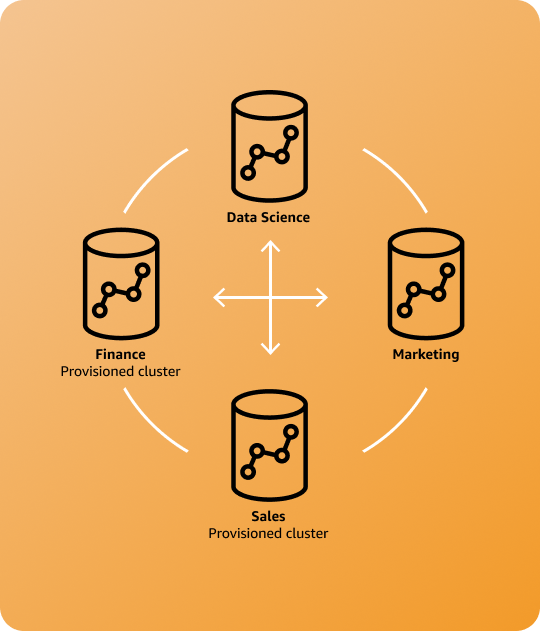
Anwendungsfälle
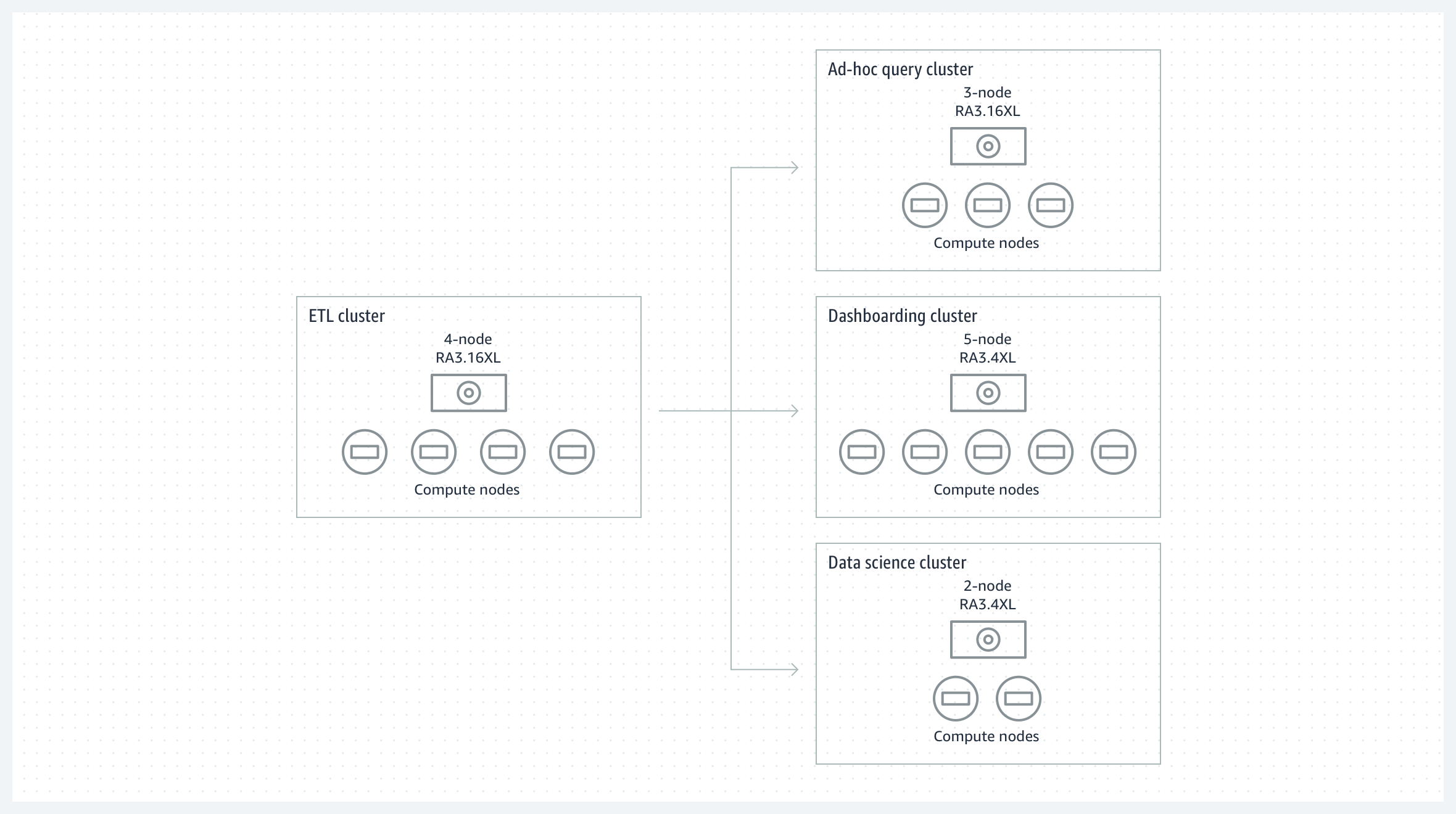
Workload-Isolierung und -Verrechenbarkeit
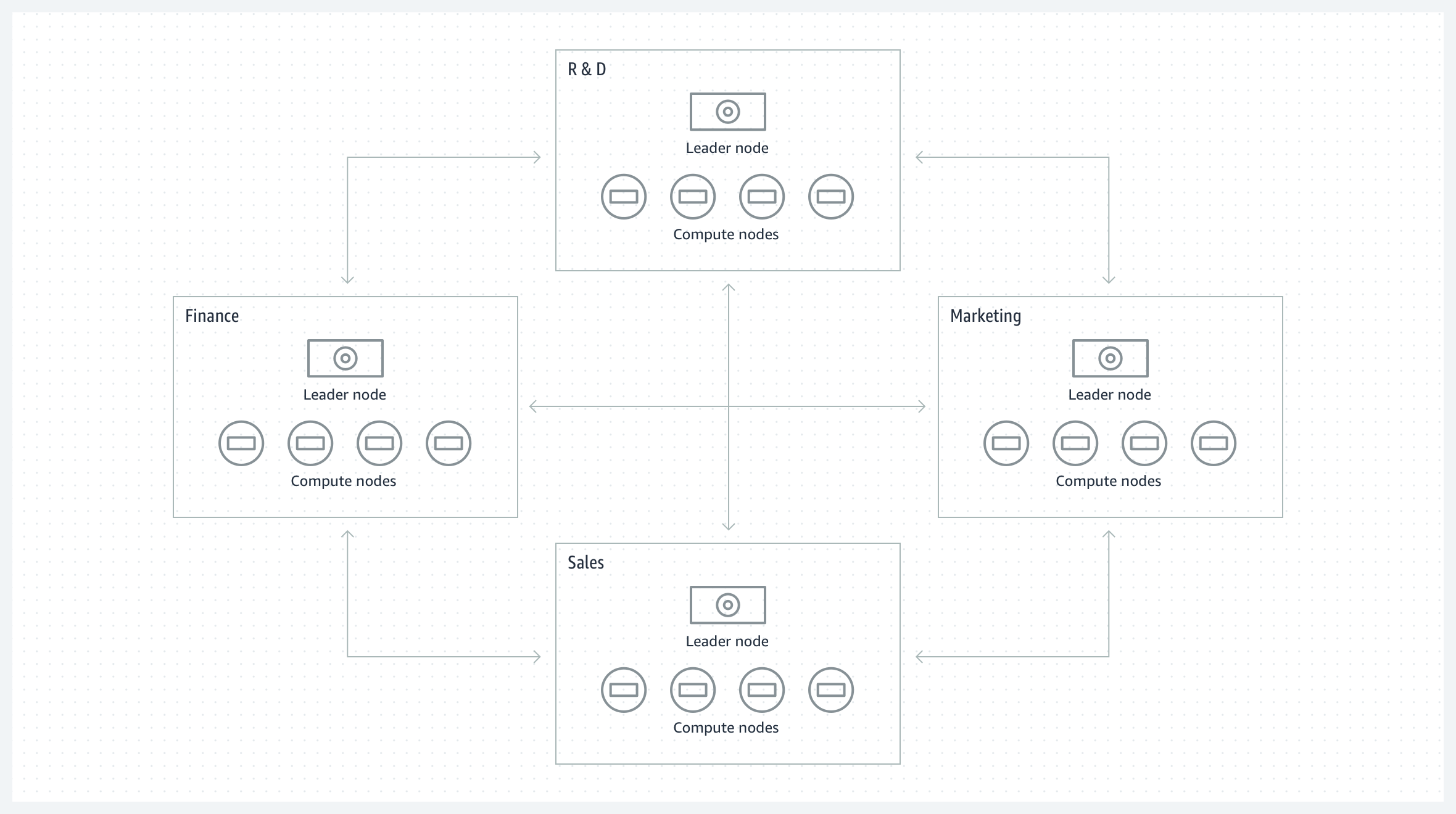
Gruppenübergreifende Zusammenarbeit
Daten und Analytik als Service

Entwicklungsagilität
