Bases de conocimiento de Amazon Bedrock
Con las bases de conocimiento de Amazon Bedrock, puede ofrecer información contextual de los orígenes de datos privados de su empresa a los modelos fundacionales y a los agentes para que la RAG ofrezca respuestas más relevantes, precisas y personalizadas
Soporte totalmente administrado de principio a fin para el flujo de trabajo RAG
Para dotar a los modelos fundacionales (FM) de información actualizada y patentada, las organizaciones utilizan la generación aumentada de recuperación (RAG), una técnica que obtiene datos de los orígenes de datos de la empresa y que enriquece la solicitud para ofrecer respuestas más pertinentes y precisas. Las Bases de conocimiento de Amazon Bedrock son una capacidad totalmente administrada, que incluyen administración de contextos de sesión y atribución de orígenes integrados. Esto permite implementar todo el flujo de trabajo de la RAG, desde la ingesta hasta la recuperación y el aumento de peticiones, sin tener que crear integraciones personalizadas con los orígenes de datos y administrar los flujos de datos. Como alternativa, puede hacer preguntas y resumir los datos de un único documento, sin necesidad de configurar una base de datos vectorial. Si los datos contienen orígenes estructurados, las Bases de conocimientos de Amazon Bedrock proporcionan una solución integrada de lenguaje natural administrado a lenguaje de consulta estructurado para generar un comando de consulta que permita recuperar los datos, sin necesidad de trasladarlos a otro almacén.
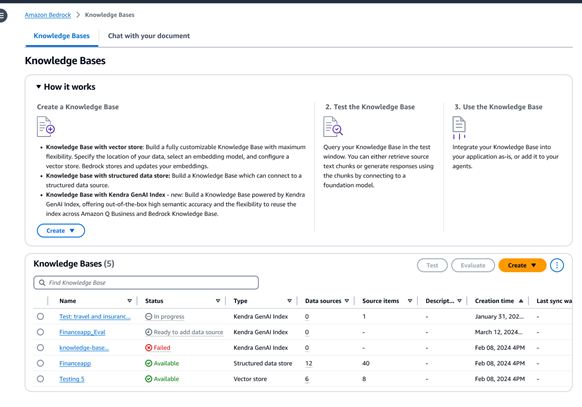
Conecte de forma segura los FM y los agentes a los orígenes de datos
Si tiene orígenes de datos no estructurados, las Bases de conocimiento de Amazon Bedrock obtienen automáticamente datos de orígenes como Amazon Simple Storage Service (Amazon S3), Confluence, Salesforce, SharePoint o Web Crawler, en versión preliminar. Además, también recibe la ingesta programática de documentos para permitir a los clientes ingerir datos de streaming o datos de orígenes no compatibles. Una vez que se incorpora el contenido, las Bases de conocimiento de Amazon Bedrock lo convierten en bloques de texto, el texto en incrustaciones y, luego, almacena las incrustaciones en su base de datos vectorial. Puede elegir entre varios almacenes vectoriales compatibles, como Amazon Aurora, Amazon Opensearch sin servidor, Amazon Neptune Analytics, MongoDB, Pinecone y Redis Enterprise Cloud. También puede conectarse a un índice de búsqueda híbrido de Amazon Kendra para una recuperación administrada.
Con las Bases de conocimiento de Amazon Bedrock, también puede conectarse a sus almacenes de datos estructurados para generar respuestas fundamentadas. Esto puede resultar especialmente útil cuando tiene material de origen, como detalles transaccionales, que se guardan en almacenes de datos y lagos de datos. Las Bases de conocimiento de Amazon Bedrock usan el lenguaje natural para convertir las consultas en comandos de SQL y ejecutar los comandos para recuperar los datos, sin necesidad de moverlos del origen.
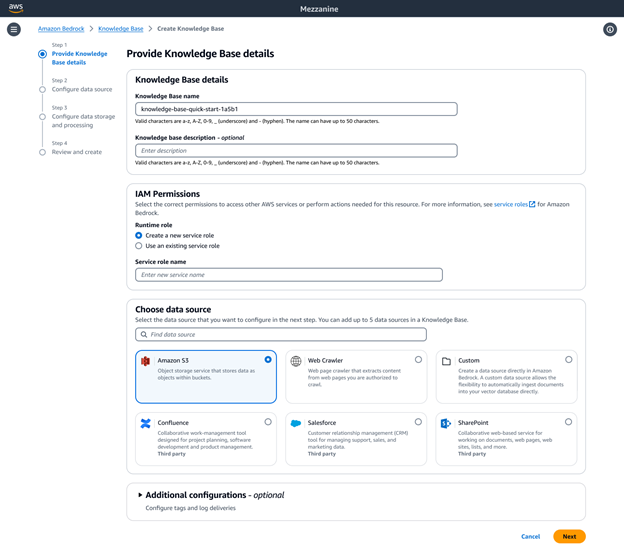
Personalización de las Bases de conocimiento de Amazon Bedrock y respuestas precisas durante la versión ejecutable
Con las Bases de conocimiento de Amazon Bedrock como su solución RAG totalmente administrada, tiene la flexibilidad de personalizar y mejorar la precisión de la recuperación. Para los orígenes de datos no estructurados que contienen datos multimodales, como imágenes y documentos visualmente ricos con diseños complejos (por ejemplo, documentos que contienen tablas, figuras, gráficos y diagramas), puede configurar las bases de conocimiento para procesar, analizar y extraer información significativa. Puede elegir Bedrock Data Automation o los modelos fundacionales como analizador. Esto permite realizar un procesamiento sin interrupciones de datos multimodales complejos, lo que le permite crear aplicaciones de IA generativa de alta precisión.
Las Bases de conocimiento de Amazon Bedrock ofrecen una variedad de opciones avanzadas de fragmentación de datos, incluida la fragmentación semántica, jerárquica y de tamaño fijo. Para tener un control total, también puede escribir su propio código de fragmentación como una función de Lambda e incluso usar componentes estándar de marcos como LangChain y LlamaIndex. Si elige Amazon Neptune Analytics como almacén vectorial, las Bases de conocimiento de Amazon Bedrock crean automáticamente incrustaciones y gráficos que vinculan el contenido relacionado en sus orígenes de datos. Las Bases de conocimiento de Bedrock aprovechan estas relaciones de contenido con GraphRAG para mejorar la precisión de la recuperación, lo que permite respuestas más completas, pertinentes e interpretables para los usuarios finales.
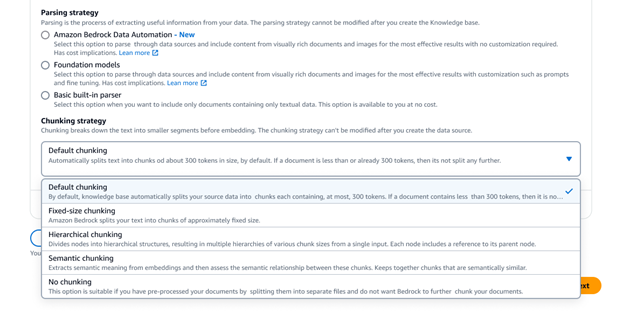
Recuperación de datos y aumento de las peticiones
Con la API Retrieve, puede obtener resultados pertinentes de una consulta de usuario de las bases de conocimiento, incluidos elementos visuales como imágenes, diagramas, gráficos, tablas, contenido de audio y vídeo, o datos estructurados de bases de datos, cuando corresponda. La nueva API RetrieveAndGenerate va un paso más allá debido a que utiliza directamente los resultados multimodales recuperados para aumentar las peticiones del FM y devolver la respuesta. Asimismo, puede proporcionar filtros o usar FM para generar filtros implícitos a fin de restringir los resultados devueltos solo al contenido adecuado. Las Bases de conocimiento de Amazon Bedrock ofrecen modelos de reclasificación para mejorar la relevancia de los fragmentos de documentos recuperados en contenidos de texto, visuales y multimedia.
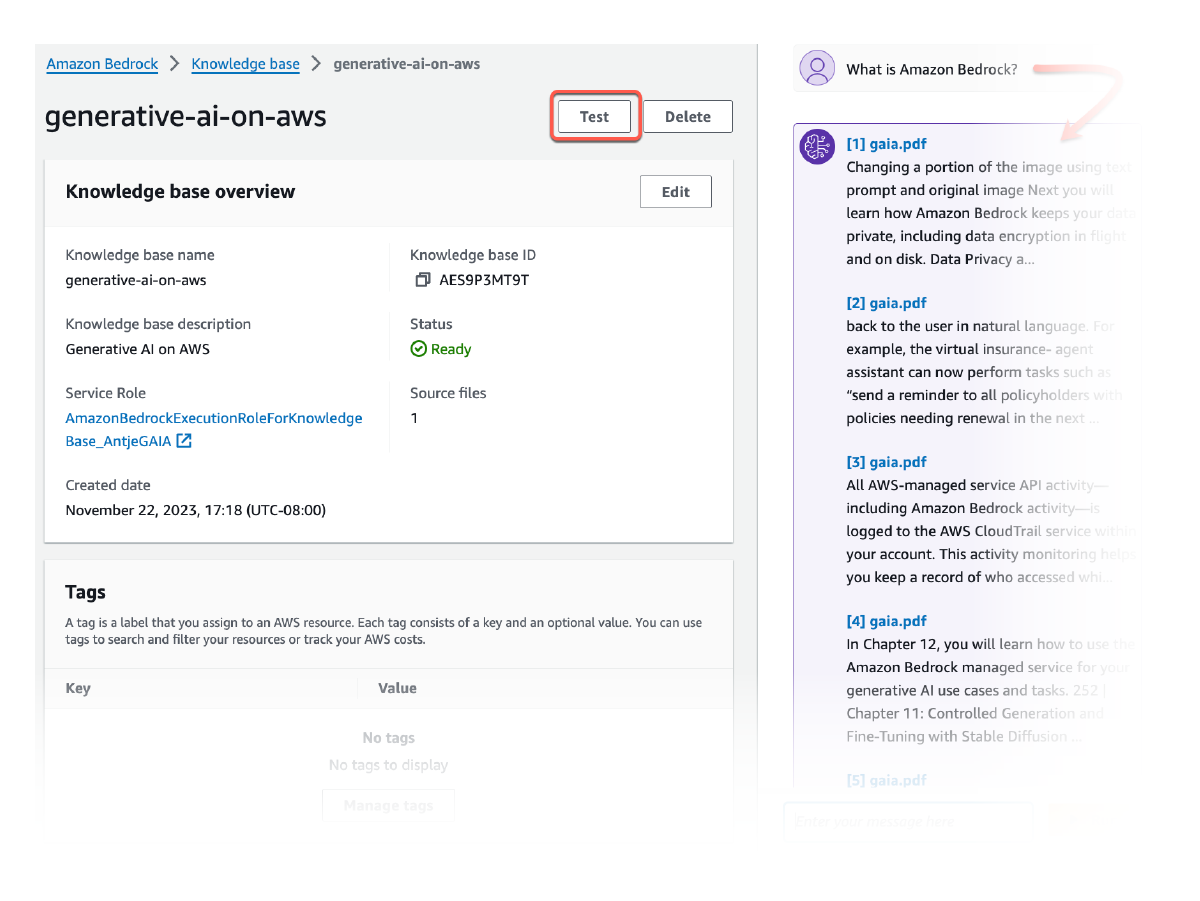
Proporcione la atribución de la fuente
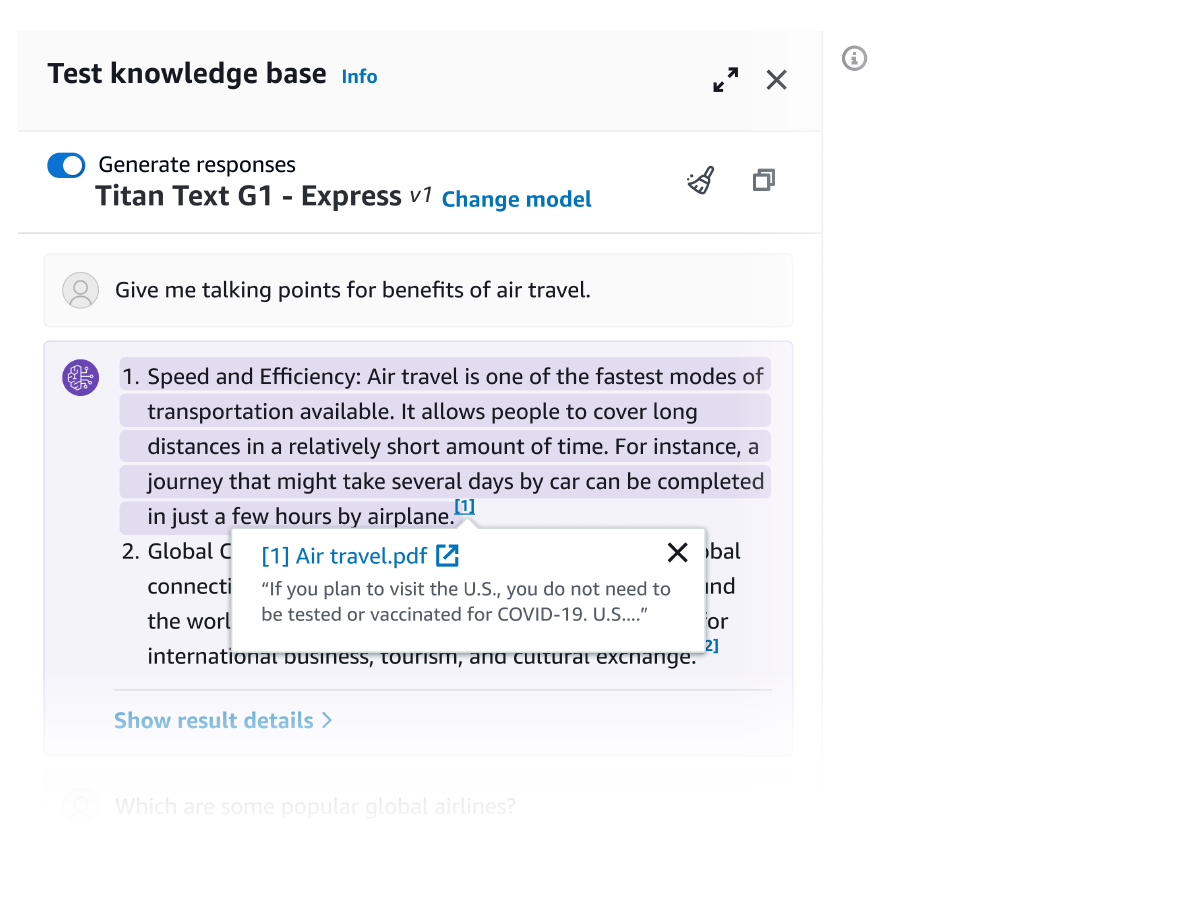
Toda la información recuperada de las Bases de conocimiento de Amazon Bedrock incluye citas (que también contienen elementos visuales) para mejorar la transparencia y minimizar las alucinaciones.
Introducción
¿Encontró lo que buscaba hoy?
Ayúdenos a mejorar la calidad del contenido de nuestras páginas compartiendo sus comentarios