- IA générative
- Amazon Bedrock
- Évaluations
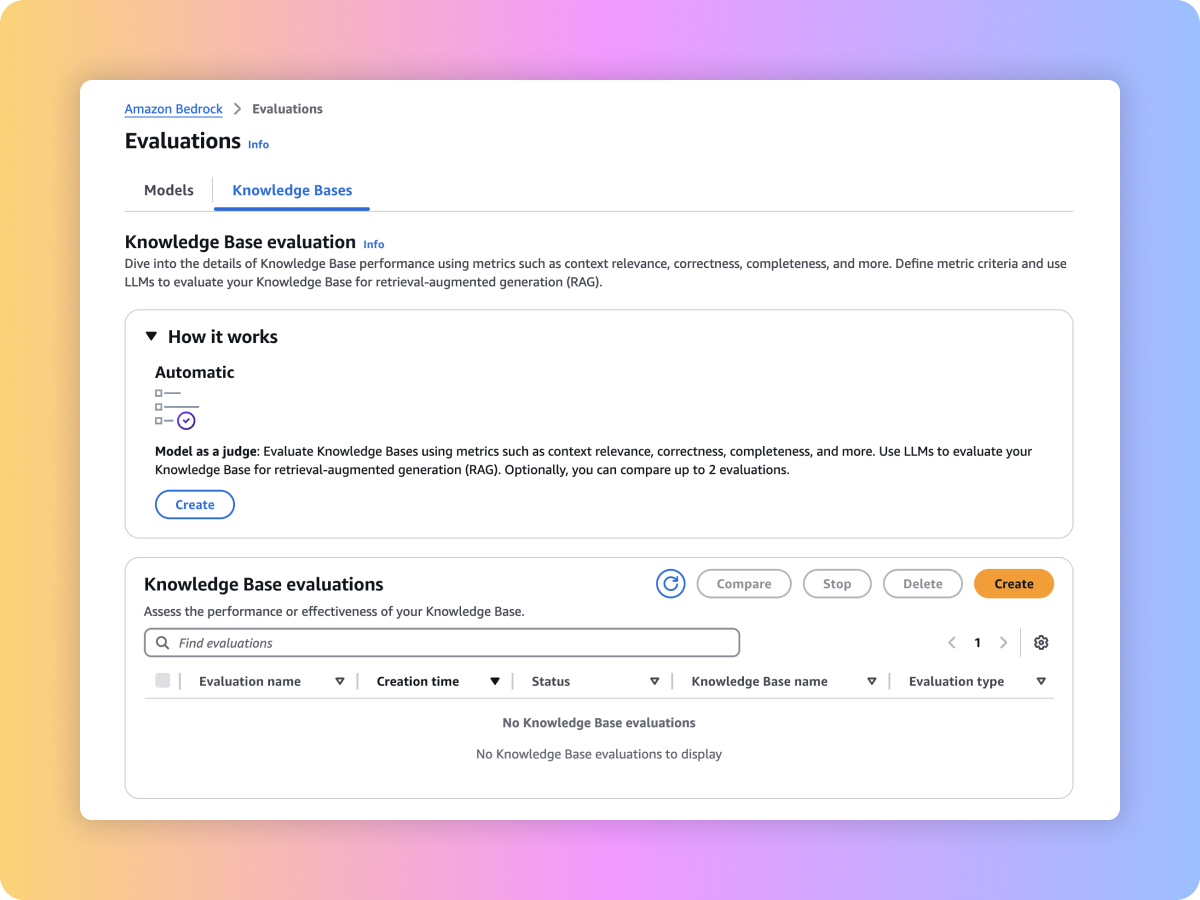
Évaluations Amazon Bedrock
Évaluez les modèles de fondation, y compris les modèles personnalisés et importés, afin de trouver ceux qui répondent à vos besoins. Vous pouvez également évaluer votre processus de récupération ou votre flux de travail RAG de bout en bout dans les bases de connaissances pour Amazon Bedrock.
Présentation
Amazon Bedrock fournit des outils d’évaluation qui vous permettent d’accélérer l’adoption d’applications d’IA générative. Évaluez, comparez et sélectionnez le modèle de fondation pour votre cas d’utilisation grâce à l’évaluation des modèles. Préparez vos applications RAG pour la production, qu’elles soient fondées sur les bases de connaissances pour Amazon Bedrock ou sur vos propres systèmes RAG personnalisés, en évaluant les fonctions de récupération ou de récupération et génération.
Types d’évaluation
Utilisez la méthodologie LLM-juge pour évaluer les résultats des modèles à l’aide de vos jeux de données d’invites personnalisés, avec des métriques telles que l’exactitude, l’exhaustivité et la dangerosité.
Évaluez les résultats des modèles à l’aide d’algorithmes et de métriques classiques de traitement du langage naturel, tels que BERT Score, F1 et d’autres techniques de correspondance exacte, en utilisant les jeux de données d’invites intégrés ou vos propres jeux de données.
Évaluez les résultats des modèles avec vos propres équipes ou confiez à AWS la gestion de vos évaluations sur les réponses à vos jeux de données d’invites personnalisés, en utilisant des métriques intégrées ou sur mesure.
Évaluez la qualité de récupération de votre système RAG personnalisé ou des bases de données pour Amazon Bedrock à l’aide de vos invites et de métriques telles que la pertinence du contexte et la couverture contextuelle.
Évaluez le contenu généré par votre flux de travail RAG de bout en bout à partir de votre pipeline RAG personnalisé ou des bases de connaissances pour Amazon Bedrock. Utilisez vos propres invites et métriques telles que la fidélité (détection des hallucinations), l’exactitude et l’exhaustivité.
Évaluation de votre flux de travail RAG de bout en bout
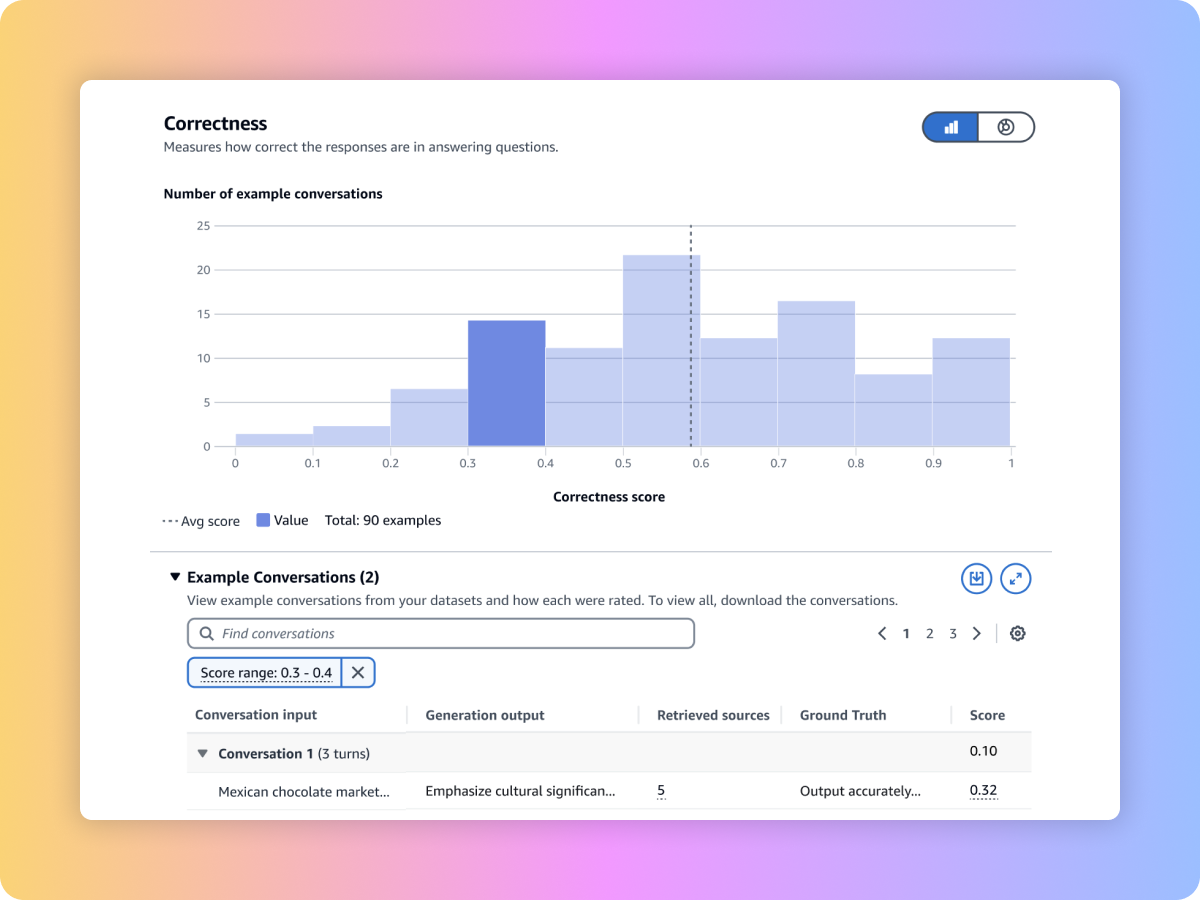
Garantissez une récupération complète et pertinente à partir de votre système RAG
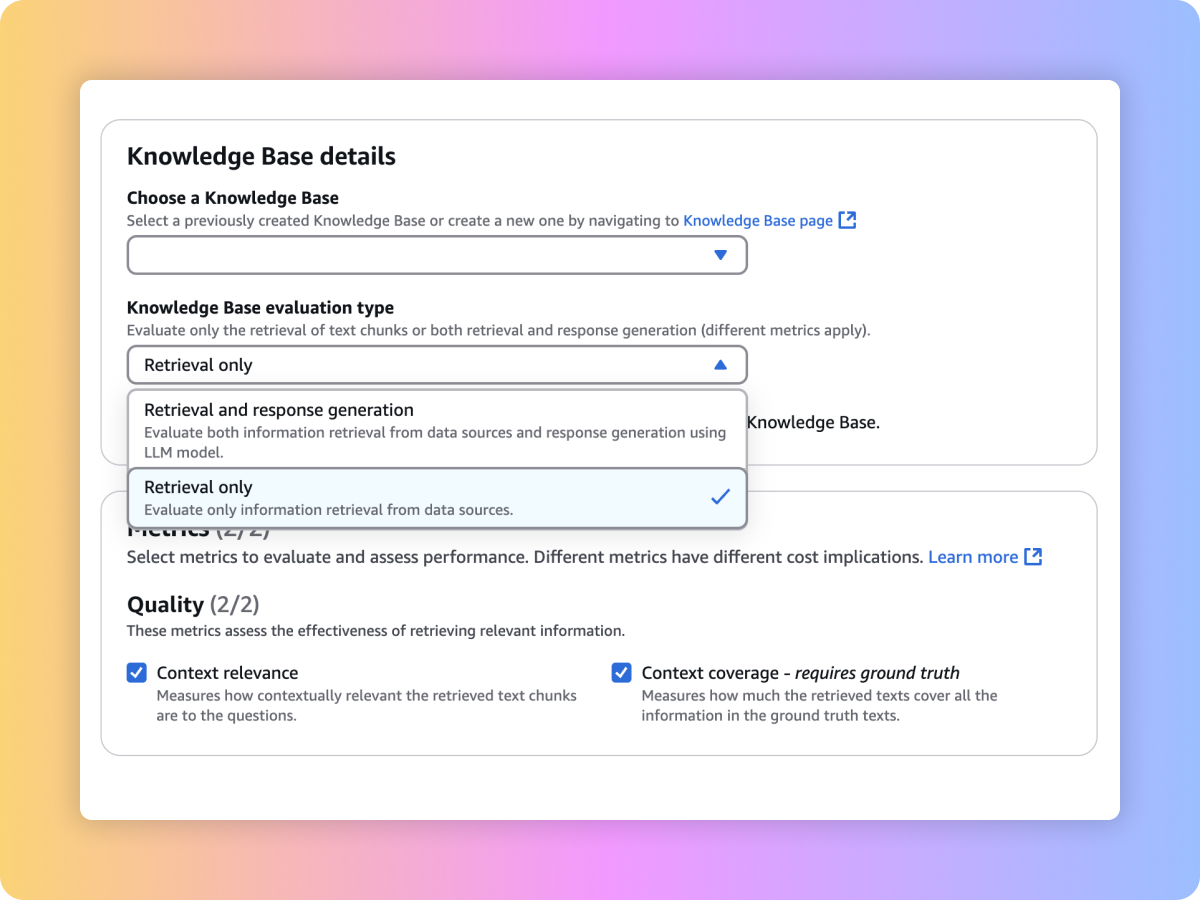
Évaluez les modèles de fondation pour sélectionner celui qui convient le mieux à votre cas d’utilisation
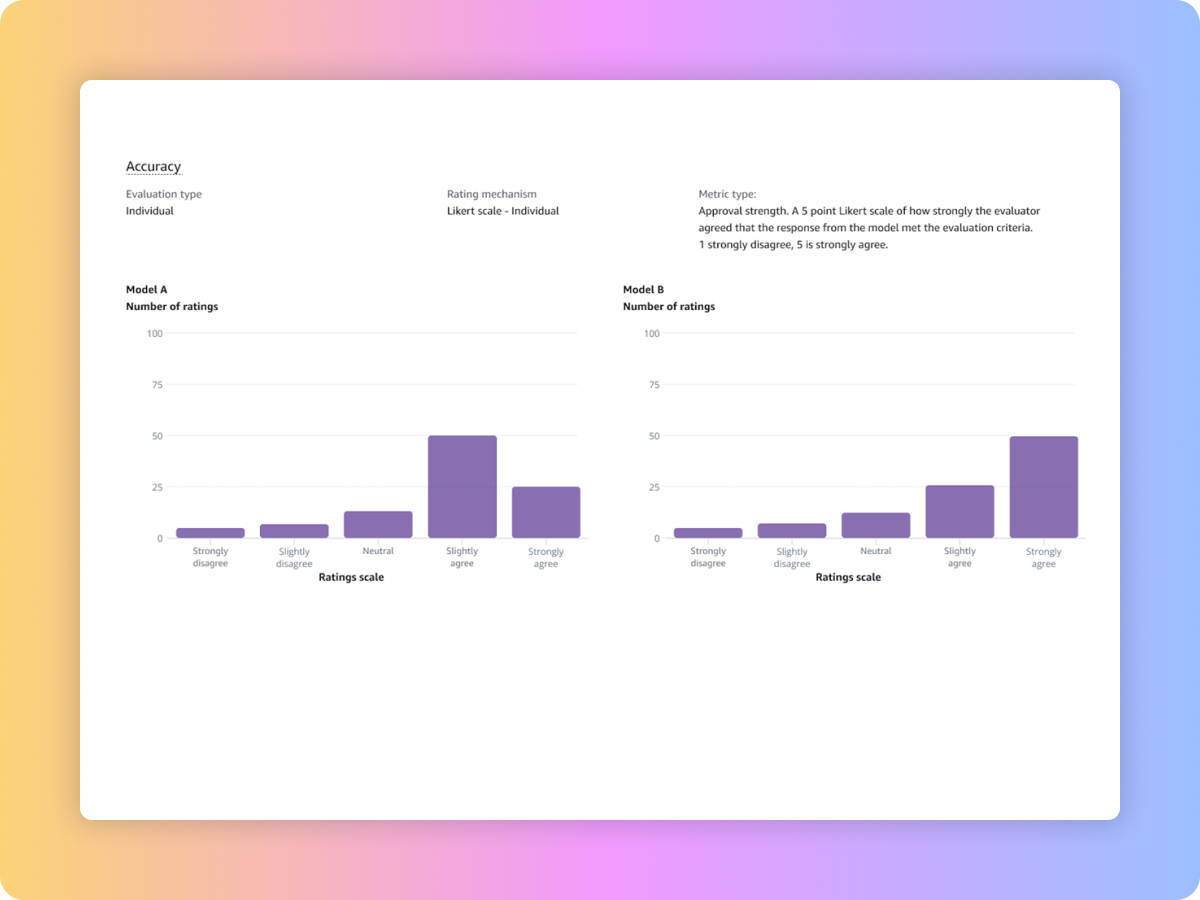
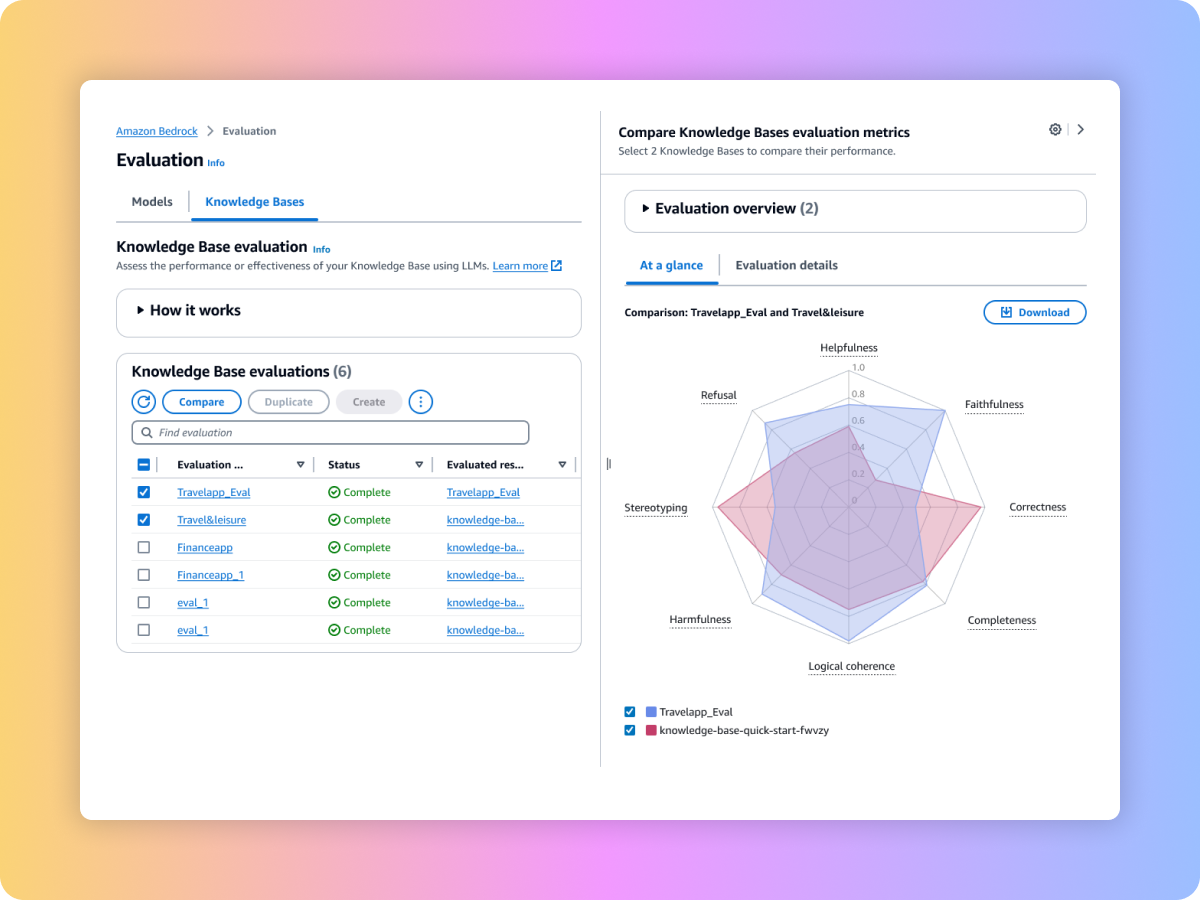
Comparez les résultats de plusieurs tâches d’évaluation pour prendre des décisions plus rapidement
Comment démarrer
Les bases de connaissances pour Amazon Bedrock prennent désormais en charge l’évaluation RAG
L’évaluation des modèles Amazon Bedrock inclut désormais la méthodologie LLM-juge
Découvrez comment évaluer des modèles en fonction de votre cas d’utilisation