Integrasi Amazon Redshift untuk Apache Spark
Buat aplikasi Apache Spark yang akan membaca dan menulis data dari Amazon Redshift
Mengapa Integrasi Amazon Redshift untuk Apache Spark?

Manfaat Amazon Redshift
-
Memperluas cakupan sumber data yang Anda gunakan di analitik yang kaya dan aplikasi machine learning (ML) yang berjalan di Amazon EMR, AWS Glue, atau SageMaker dengan membaca dari dan menulis data ke gudang data Anda.
-
Menyederhanakan proses yang rumit dan seringkali manual dalam menyiapkan konektor dan driver JDBC yang tidak bersertifikat sehingga mengurangi waktu persiapan tugas analitik dan ML.
-
Menggunakan kemampuan pushdown, seperti fungsi urutkan, agregasi, batasi, gabungkan, dan skalar sehingga hanya data yang relevan yang dipindahkan dari gudang data Amazon Redshift.
Cara kerjanya
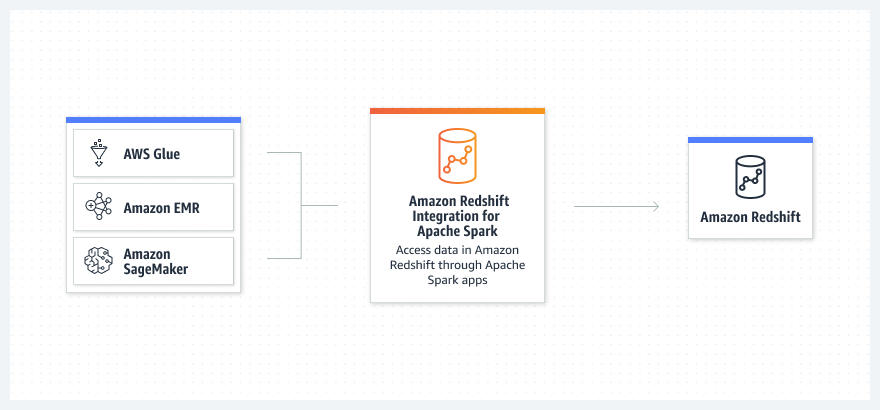
Kasus penggunaan
-
Buat aplikasi Apache Spark di Java, Scala, dan Python menggunakan layanan analitik AWS berbasis Apache Spark.
-
Baca dan tulis data ke dan dari Amazon Redshift menggunakan Amazon EMR, AWS Glue, SageMaker, serta layanan analitik AWS dan ML.
-
Gunakan Amazon EMR atau AWS Glue untuk mengambil kode kerangka data dari tugas Apache Spark atau notebook Anda dan hubungkan ke Amazon Redshift.
-
Sederhanakan proses Anda tanpa instalasi atau pengujian, keamanan yang ditingkatkan (kredensial berbasis IAM) dan pushdown operasional, serta format file Parquet untuk performa.
Pelanggan
Corey Johnson, Data Architect Manager - Huron Consulting
Huron adalah sebuah perusahaan layanan profesional global yang berkolaborasi dengan klien untuk mewujudkan berbagai kemungkinan dengan menciptakan strategi yang tepat, mengoptimalkan operasi, mempercepat transformasi digital, dan memberdayakan bisnis serta karyawan agar dapat menentukan masa depan mereka sendiri.
"Kami memberdayakan teknisi kami untuk membangun pipeline data dan aplikasi mereka dengan Apache Spark menggunakan Python dan Scala. Kami menginginkan solusi khusus yang menyederhanakan operasi serta mengirimkan dengan lebih cepat dan lebih efisien untuk klien. Hal itu kami dapatkan saat menggunakan Integrasi Amazon Redshift untuk Apache Spark."
Alcuin Weidus, Sr Principal Data Architect - GE Aerospace
GE Aerospace adalah penyedia global mesin jet, komponen, dan sistem untuk pesawat terbang komersial dan militer. Perusahaan ini telah merancang, mengembangkan, dan memproduksi mesin jet sejak Perang Dunia I.
“GE Aerospace menggunakan analitik AWS dan Amazon Redshift untuk memungkinkan wawasan bisnis utama yang mendukung keputusan bisnis penting. Dengan dukungan salin otomatis dari Amazon S3, kami dapat membangun pipeline data yang lebih sederhana untuk memindahkan data dari Amazon S3 ke Amazon Redshift. Hal ini mempercepat kemampuan tim produk data untuk mengakses data dan memberikan wawasan ke pengguna akhir. Kami menghabiskan lebih banyak waktu untuk menambahkan nilai melalui data dan lebih sedikit waktu untuk integrasi.”
Neema Raphael, Chief Data Officer - Goldman Sachs
Goldman Sachs Group, Inc.adalah institusi keuangan global terkemuka yang menghadirkan berbagai layanan keuangan di bidang perbankan investasi, sekuritas, manajemen investasi, dan perbankan konsumen untuk basis klien yang besar dan beragam, termasuk perusahaan, institusi keuangan, pemerintah, dan individu.
"Fokus kami adalah memberikan akses layanan mandiri ke data untuk semua pengguna di Goldman Sachs. Melalui Legend, platform manajemen dan tata kelola data sumber terbuka, kami memungkinkan pengguna untuk mengembangkan aplikasi pusat data dan memperoleh wawasan yang didukung data saat kami berkolaborasi di seluruh industri layanan keuangan. Dengan integrasi Amazon Redshift untuk Apache Spark, tim platform data kami dapat mengakses data dengan langkah manual minimum—memungkinkan ETL kode nol yang akan meningkatkan kemampuan kami untuk memudahkan teknisi fokus menyempurnakan alur kerja mereka saat mengumpulkan informasi yang lengkap dan tepat waktu. Kami berharap dapat menyaksikan peningkatan performa aplikasi dan keamanan karena pengguna kami kini dapat mengakses data terbaru di Amazon Redshift dengan mudah.”
Sumber Daya
Apakah Anda sudah menemukan yang Anda cari?
Beri tahu kami agar kami dapat meningkatkan kualitas konten di halaman kami