アベイラビリティーゾーンを使用した静的安定性
アーキテクチャ | レベル 300
ページトピック
はじめに
Amazon では、構築したサービスが非常に高い可用性の目標を満たしてなければなりません。これはつまり、システムが取る依存関係について、慎重に検討する必要があることを意味します。これらの依存関係が損なわれた場合でも復元力を維持するようにシステムを設計します。この記事では、このレベルの復元力を実現するために静的安定性と呼ばれるパターンを定義します。この概念を、AWS の重要なインフラストラクチャビルディングブロックであるアベイラビリティーゾーンに適用する方法を示します。したがって、すべてのサービスが構築される基盤になります。
静的に安定した設計では、依存関係が損なわれてもシステム全体が動作し続けます。おそらく、システムは、依存関係が提供するはずだった更新された情報(新しいもの、削除されたもの、変更されたものなど)を確認しません。しかし、依存関係が損なわれる前に行われていたすべての処理は、依存関係が損なわれているにもかかわらず機能し続けます。静的に安定するように Amazon Elastic Compute Cloud (EC2) を構築した方法について説明します。次に、アベイラビリティーゾーンの上に可用性の高いリージョナルシステムを構築するのに役立つ、静的で安定した 2 つのサンプルアーキテクチャを紹介します。
最後に、ソフトウェアレベルでアベイラビリティーゾーンの独立性を提供するためにどのように設計されているかなど、Amazon EC2 の背後にある設計理念の一部について詳しく説明します。さらに、このアーキテクチャを選択してサービスを構築する際のトレードオフについても説明します。
アベイラビリティーゾーンの役割
アベイラビリティーゾーンは、AWS リージョンの論理的に分離されたセクションです。各 AWS リージョンには、独立して動作するように設計された複数のアベイラビリティーゾーンがあります。アベイラビリティーゾーンは、落雷、竜巻、地震などの潜在的な問題からの相関的な影響から保護するために、意味のある距離で物理的に分離されています。電源やその他のインフラストラクチャは共有していませんが、高速で暗号化されたプライベート光ファイバーネットワークで相互に接続されているため、アプリケーションは中断することなく迅速にフェイルオーバーできます。つまり、アベイラビリティーゾーンは、インフラストラクチャの隔離を超えた抽象化されたレイヤーを提供します。アベイラビリティーゾーンを必要とするサービスにより、発信者は AWS にリージョン内のインフラストラクチャを物理的にプロビジョニングする場所を指示して、この独立性から利益を得ることができます。Amazonでは、独自の高可用性ターゲットを達成するためにこのゾーンの独立性を利用したリージョナル AWS サービスを構築しました。Amazon DynamoDB、Amazon Simple Queue Service (SQS)、Amazon Simple Storage Service (S3) などのサービスは、このようなリージョナルサービスの例です。
Amazon Virtual Private Cloud (VPC) 内のクラウドインフラストラクチャをプロビジョニングする AWS サービスとやり取りする場合、これらのサービスの多くでは、発信者がリージョンだけでなくアベイラビリティーゾーンも指定する必要があります。アベイラビリティーゾーンは、EC2 インスタンスの起動時、Amazon Relational Database Service (RDS) データベースのプロビジョニング時、Amazon ElastiCache クラスターの作成時など、必要なサブネット引数で暗黙的に指定されることがよくあります。アベイラビリティーゾーンに複数のサブネットがあることは一般的ですが、単一のサブネットは完全に単一のアベイラビリティーゾーン内に存在するため、発信者はサブネット引数を提供することにより、使用するアベイラビリティーゾーンも暗黙的に提供します。
静的安定性
アベイラビリティーゾーンの上にシステムを構築するときに学んだ1つの教訓は、障害が発生する前に障害に備えることです。1 つのアベイラビリティーゾーン内で障害が発生した場合に、サービスは他のアベイラビリティーゾーンでスケールアップし (おそらく AWS Auto Scaling を使用)、完全な健全性が復元されることを期待して、複数のアベイラビリティーゾーンにデプロイするのは、効果的ではないアプローチです。このアプローチは、障害が発生する前に障害に備えるのではなく、障害への対応に依存しているため、あまり効果的ではありません。言い換えれば、静的安定性に欠けています。それに対して、より効果的で静的に安定したサービスは、アベイラビリティーゾーンが損なわれた場合でも、新しい EC2 インスタンスを起動することなく、正常に動作し続けるまでインフラストラクチャをオーバープロビジョニングします。
静的安定性の特性をよりよく説明するために、Amazon EC2 を見てみましょう。AmazonEC2 は、これらの原則に従って設計されています。
Amazon EC2 サービスは、コントロールプレーンとデータプレーンで構成されています。「コントロールプレーン」と「データプレーン」はネットワーキングの専門用語ですが、AWS内のいたるところで使用しています。コントロールプレーンは、システムの変更 (リソースの追加、削除、変更) を行い、変更を有効にするために必要な場所にそれらの変更を反映させる役割を担っています。それに対して、 データプレーンは、これらのリソースの日常業務、つまりそれらが機能するために必要なものです。
Amazon EC2 では、コントロールプレーンは EC2 が新しいインスタンスを起動するときに発生するすべてのものです。コントロールプレーンのロジックは、多数のタスクを実行することにより、新しい EC2 インスタンスに必要なすべてのものをまとめます。いくつかの例を次に示します。
- 配置グループと VPC のテナント要件に従って、コンピューティング用の物理サーバーを見つけます。
- VPC サブネットからネットワークインターフェイスを割り当てます。
- Amazon Elastic Block Store (EBS) ボリュームを準備します、
- AWS Identity and Access Management (IAM) ロール認証情報を生成します。
- セキュリティグループルールをインストールします。
- さまざまなダウンストリームサービスのデータストアに結果を保存します。
- 必要に応じて、VPC のサーバーとネットワークエッジに必要な構成を伝播します。
それに対して、Amazon EC2 データプレーンは、既存の EC2 インスタンスを予定どおりに続け、次のようなタスクを実行します。
- VPC のルートテーブルに従ってパケットをルーティングします。
- Amazon EBS ボリュームから読み込みおよび書き込みを行います。
- その他いろいろ
大抵のデータプレーンとコントロールプレーンの場合と同様に、Amazon EC2 データプレーンはコントロールプレーンよりもはるかに単純です。比較的単純であるため、Amazon EC2 データプレーンの設計は、Amazon EC2 コントロールプレーンよりも高い可用性を目標としています。
重要な点として、Amazon EC2 データプレーンは、コントロールプレーンの可用性イベント (EC2 インスタンスを起動する機能の障害など) に直面した際も静的に安定するように、慎重に設計されています。たとえば、ネットワーク接続の中断を回避するために、EC2 インスタンスが実行される物理マシンが VPC の内外のポイントにパケットをルーティングするのに必要なすべての情報にローカルアクセスできるように、Amazon EC2 データプレーンは設計されています。Amazon EC2 コントロールプレーンの障害は、そのイベント中、VPC に追加された新しい EC2 インスタンスや新しいセキュリティグループルールなどの更新を、物理サーバーが確認しない可能性があることを意味します。しかしながら、イベントの前に送受信できたトラフィックは、引き続き機能します。
コントロールプレーン、データプレーン、静的安定性の概念は、Amazon EC2 を超えて幅広く適用できます。システムをコントロールプレーンとデータプレーンに分解できることは、さまざまな理由から、可用性の高いサービスを設計するための便利な概念ツールになります。
- データプレーンの可用性は、コントロールプレーンよりも、何よりサービスにおけるお客様の成功することが重要です。たとえば、開始後の EC2 インスタンスの継続的な可用性と正常な機能は、ほとんどの AWS のお客様にとって、新しい EC2 インスタンスを起動する機能よりもさらに重要です。
- データプレーンは、通常、コントロールプレーンよりも高いボリューム (多くの場合数桁異なる) で動作します。したがって、それぞれ関連するスケーリングディメンションに従ってスケーリングできるように、分離しておいた方がよいのです。
- システムのコントロールプレーンは、データプレーンよりも可動部分が多い傾向があるため、その理由だけで統計的に損なわれる可能性があることを長年にわたりわかりました。
これらの考慮事項をすべてまとめた上でのベストプラクティスは、コントロールプレーンとデータプレーンの境界に沿ってシステムを分離することです。
実際にこの分離を成功させるために、静的安定性の原則を適用します。データプレーンは通常、コントロールプレーンから届くデータに依存します。しかしながら、より高い可用性の目標を達成するために、データプレーンは既存の状態を維持し、コントロールプレーンの障害が発生しても機能し続けます。データプレーンは、障害の発生中は更新されない可能性がありますが、以前に機能していたものはすべて機能し続けます。
以前に、アベイラビリティーゾーンの障害に対応して EC2 インスタンスの交換を必要とするスキームは、あまり効果的なアプローチではないことに気付きました。新しい EC2 インスタンスを起動できないからではありません。障害が発生した場合、システムは Amazon EC2 コントロールプレーンの復旧パスに加えて、新しいインスタンスが価値ある作業を実行するために必要なアプリケーション固有のシステムすべてに、即座に依存する必要があるためです。アプリケーションに応じて、これらの依存関係には、ランタイム構成のダウンロード、インスタンスのディスカバリサービスへの登録、認証情報の取得などの手順が含まれます。コントロールプレーンシステムは、必然的にデータプレーンのシステムよりも複雑であり、システム全体に障害が発生した場合に正しく動作しない可能性が高くなります。
静的安定性パターン
このセクションでは、静的安定性を活用して高可用性を実現するシステムを設計するために AWS で使用している高レベルな 2 つのパターンを紹介します。それぞれが独自の状況に適用できますが、どちらもアベイラビリティーゾーンの抽象的概念を活用しています。
アベイラビリティーゾーンでのアクティブ - アクティブの例: 負荷分散されたサービス
いくつかの AWS サービスは、内部的に水平方向に拡張可能でステートレスな EC2 インスタンスのフリートまたは Amazon Elastic Container Service (ECS) コンテナーのセットで構成されています。これらのサービスは、3 つ以上のアベイラビリティーゾーンにわたって Auto Scaling グループで実行されます。さらに、これらのサービスはキャパシティをオーバープロビジョニングするため、1 つのアベイラビリティーゾーン全体に障害が発生した場合でも、残りのアベイラビリティーゾーンのサーバーが負荷を負担できます。たとえば、3 つのアベイラビリティーゾーンを使用すると、50% オーバープロビジョニングされます。別の言い方をすれば、各アベイラビリティーゾーンが負荷テストしたレベルの66%で動作するようにオーバープロビジョニングします。
最も一般的な例は、負荷分散 HTTPS サービスです。次の図は、HTTPS サービスを提供する公に向けた Application Load Balancer を示しています。ロードバランサーのターゲットは、eu-west-1 リージョンの 3 つのアベイラビリティーゾーンにまたがる Auto Scaling グループです。これは、アベイラビリティーゾーンを使用したアクティブ-アクティブ高可用性の例です。
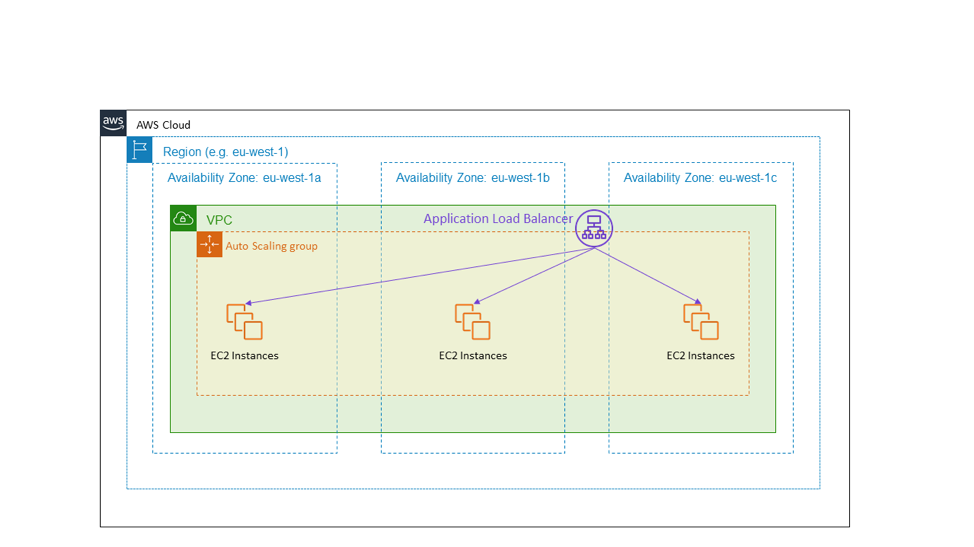
アベイラビリティーゾーンに障害が発生した場合、前の図に示されているアーキテクチャはアクションを必要としません。障害のあるアベイラビリティーゾーンの EC2 インスタンスはヘルスチェックに失敗し始め、Application Load Balancer はそれらからトラフィックを移動します。実際、Elastic Load Balancing サービスはこの原則に従って設計されています。スケールアップを必要とせずにアベイラビリティーゾーンの障害に耐えるのに十分な負荷分散能力をプロビジョニングしています。
また、ロードバランサーまたは HTTPS サービスがない場合でも、このパターンを使用します。たとえば、Amazon Simple Queue Service (SQS) キューからのメッセージを処理する EC2 インスタンスのフリートもこのパターンに従うことができます。インスタンスは、複数のアベイラビリティーゾーンにわたって Auto Scaling グループにデプロイされ、適切にオーバープロビジョニングされます。アベイラビリティーゾーンに障害が発生した場合、サービスは何もしません。障害のあるインスタンスは作業を停止し、他のインスタンスはスラックを拾います。
アベイラビリティーゾーンのアクティブ - スタンバイの例: リレーショナルデータベース
構築するサービスの一部はステートフルであり、作業を調整するために単一のプライマリノードまたはリーダーノードが必要です。この例として挙げられるのが、MySQL または Postgres データベースエンジンを備えた Amazon RDS などのリレーショナルデータベースを使用するサービスです。この種のリレーショナルデータベースの一般的な高可用性セットアップには、すべての書き込みが必要なプライマリインスタンスとスタンバイ候補があります。次の図には示されていない追加のリードレプリカもあります。このようなステートフルインフラストラクチャを使用すると、プライマリノードとは異なるアベイラビリティーゾーンにウォームスタンバイノードが存在します。
次の図は、Amazon RDS データベースを示しています。Amazon RDS でデータベースをプロビジョニングする場合、サブネットグループが必要です。サブネットグループは、データベースインスタンスがプロビジョニングされる複数のアベイラビリティーゾーンにまたがるサブネットのセットです。Amazon RDS は、スタンバイ候補をプライマリノードとは異なるアベイラビリティーゾーンに配置します。これは、アベイラビリティーゾーンを使用したアクティブ - スタンバイ高可用性の例です。
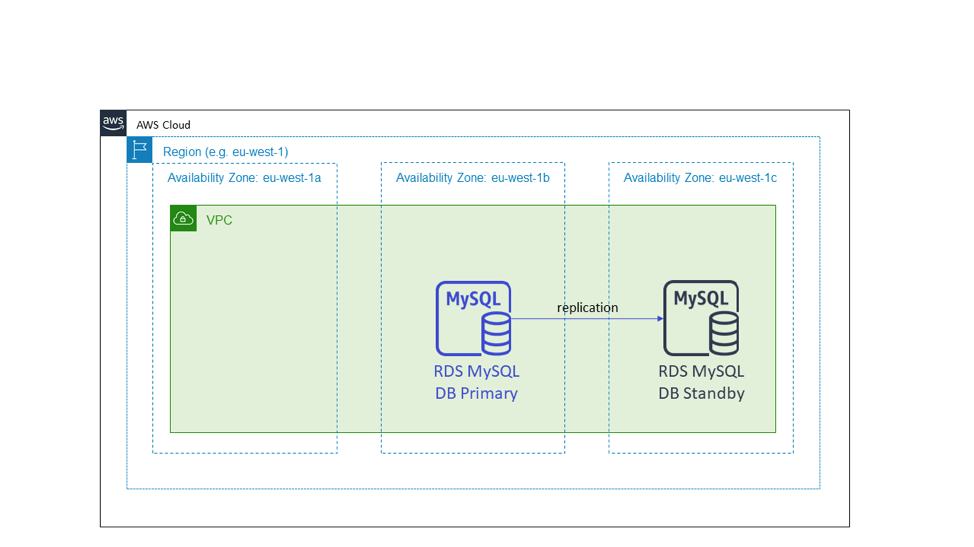
ステートレス、アクティブ-アクティブの例の場合と同様に、プライマリノードのアベイラビリティーゾーンが機能しなくなった場合、ステートフルサービスはインフラストラクチャに対して何もしません。Amazon RDS を使用するサービスの場合、RDS はフェイルオーバーを管理し、作業中のアベイラビリティーゾーンの新しいプライマリに DNS 名を再ポイントし直します。このパターンは、リレーショナルデータベースを使用しない場合でも、他のアクティブ/スタンバイ設定にも適用されます。特に、リーダーノードを含むクラスターアーキテクチャを備えたシステムにこれを適用します。「ジャストインタイム」に交換するのではなく、これらのクラスターをアベイラビリティーゾーン全体にデプロイし、スタンバイ候補から新しいリーダーノードを選択します。
これら 2 つのパターンの共通点は、アベイラビリティーゾーンの機能障害の発生に備えて、予め必要な容量をプロビジョニングしていることです。どちらの場合も、サービスはアベイラビリティーゾーンの障害に応じて計画的なコントロールプレーンの依存関係を持ちません。
内部の詳細:Amazon EC2 内の静的安定性
この記事の最後のセクションでは、障害耐性のあるアベイラビリティーゾーンのアーキテクチャをさらに一段階深く掘り下げ、Amazon EC2 のアベイラビリティーゾーンの独立性の原則に従う方法について説明します。これらの概念の一部を理解することは、高可用性のサービルを構築する場合だけではなく、他の高可用性のあるインフラストラクチャを提供する場合に役立ちます。Amazon EC2は、低レベル AWS インフラストラクチャのプロバイダーとして、アプリケーションが高可用性を実現するために使用できるインフラストラクチャです。他のシステムでその戦略を採用するべき場合もあります。
デプロイのプラクティスでは、Amazon EC2 のアベイラビリティーゾーンの独立性の原則に従います。Amazon EC2では、EC2 インスタンス、エッジデバイス、DNS リゾルバー、EC2 インスタンス起動パス内のコントロールプレーンコンポーネント、および EC2 インスタンスが依存する他の多くのコンポーネントをホストしている物理サーバーにデプロイされます。これらのデプロイは、ゾーンデプロイカレンダーに従います。これは、同じリージョン内の 2 つのアベイラビリティーゾーンが、異なる日に特定のデプロイを受け取ることを意味します。AWS 全体で、デプロイの段階的なロールアウトを使用します。たとえば、最初にワンボックスをデプロイし、次に 1 / N のサーバーなどをデプロイするといった、 ベストプラクティスに従います。(これは、デプロイするサービスの種類に依存しません。)ただし、Amazon EC2のようなサービスの特定のケースでは、展開はさらに一歩進められ、アベイラビリティーゾーンの境界に意図的に合わせられています。このように、デプロイの問題は 1 つのアベイラビリティーゾーンに影響します。ロールバックされ、修正が行われます。これは通常どおり機能している他のアベイラビリティーゾーンには影響しません。
Amazon EC2 で構築するときのアベイラビリティーゾーンの独立性の原則に沿ったもう1つの方法は、すべてのパケットフローを境界を越えないようにアベイラビリティーゾーン内にとどめる設計をすることです。ネットワークトラフィックをアベイラビリティーゾーンのローカルにとどめることの 2 つめの理由について、詳しく見ていきたいと思います。これは、独立したアベイラビリティーゾーンのコンシューマーである、リージョン内の可用性の高いシステムを構築する場合の、弊社の考えを示す一例です。(つまり、高可用性サービスを構築するための基盤として、アベイラビリティーゾーンの独立性を確保します。) アベイラビリティーゾーンに依存しないインフラストラクチャを他のユーザーに提供して、高可用性を実現するといった方法と対照的な手法です。
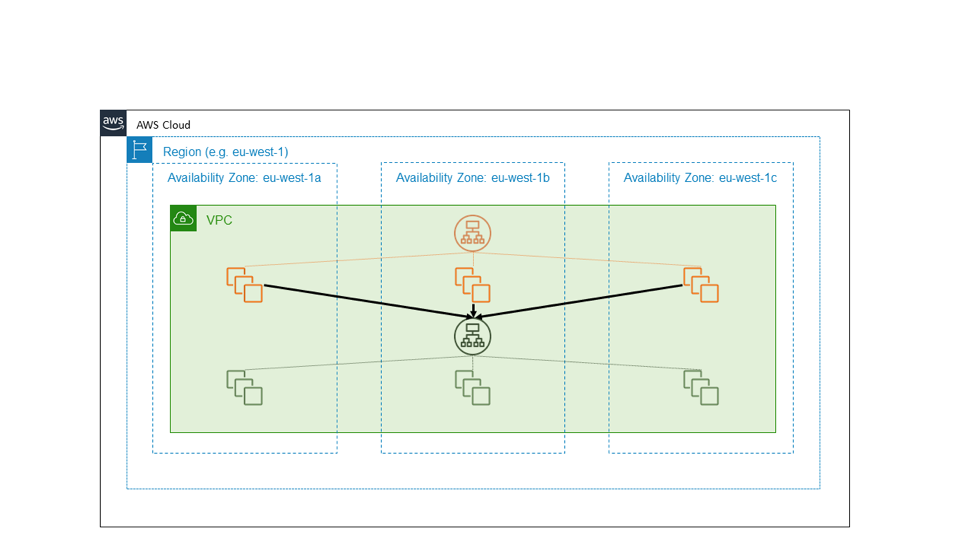
次の図では、高可用性の外部サービスをオレンジ色で示しています。これは、緑で示されている別の内部サービスに依存しています。シンプルな設計では、これらのサービスの両方を、独立した EC2 アベイラビリティーゾーンのコンシューマーとして扱います。オレンジとグリーンの各サービスの前には Application Load Balancer があり、各サービスには、3 つのアベイラビリティーゾーンに分散した、適切にプロビジョニングされたバックエンドホストのフリートがあります。1 つの高可用性のリージョナルサービスが別の高可用性のリージョナルサービスを呼び出します。これはシンプルな設計で、弊社がこれまで構築した多くのサービスに適用してきました。良い設計です。
ただし、グリーンのサービスは基本的なサービスであるとします。つまり、可用性が高いだけでなく、それ自体がアベイラビリティーゾーンの独立性を提供するためのビルディングブロックとして機能することを目的としているからです。その場合、代わりにゾーンローカルサービスの 3 つのインスタンスとして設計し、アベイラビリティゾーンに対応したデプロイポリシーに従います。次の図は、高可用性リージョナルサービスが高可用性ゾーンサービスを呼び出す設計を示しています。
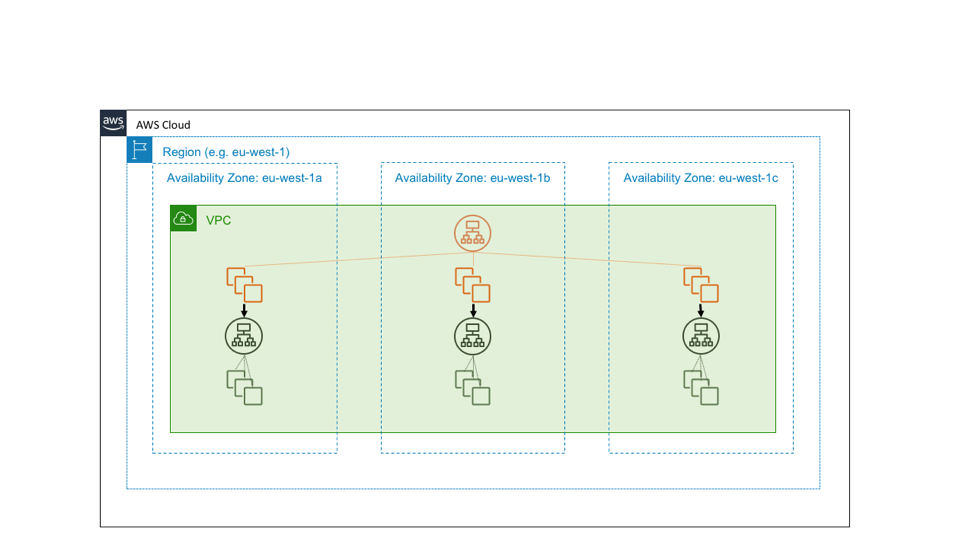
ブロック構築のサービスをアベイラビリティゾーンに依存しないように設計するには、単純な計算で求めることができます。アベイラビリティーゾーンに障害があるとしましょう。白黒の障害の場合、Application Load Balancer は影響を受けたノードから自動的に障害を取り除きます。ただし、すべての障害がすぐに判別でできるわけではありません。ソフトウェアのバグなど、判別しにくい障害が発生する可能性があります。ロードバランサーは、ヘルスチェックで障害を検出できず、正常に処理できません。
ある高可用性リージョナルサービスが別の高可用性リージョナルサービスを呼び出すという上述の例において、リクエストがシステムを介して送信され、障害のあるアベイラビリティーゾーンを回避する確率は、2/3 * 2 / 3 = 4/9 となります。つまり、このリクエストがイベントを回避できる確率は、五分五分の確率よりも低いということです。一方で、グリーンのサービスをゾーンのサービスとして構築した場合は、オレンジのサービスのホストは同じアベイラビリティゾーンにあるグリーンのエンドポイントを呼び出すことができます。この設計では、障害のあるアベイラビリティーゾーンを回避できる可能性は 2/3 になります。N 個のサービスがこのコールパスの一部である場合、N 個のリージョナルサービスでは (2/3) ^ N を、N 個のゾーンサービスでは 2/3 (一定) を、確率として一般化することができます。
ゾーンサービスとして Amazon EC2 NAT ゲートウェイを構築した理由がこれです。NAT ゲートウェイは、プライベートサブネットからのアウトバウンドインターネットトラフィックを許可する Amazon EC2 機能であり、リージョン内の VPC ワイドゲートウェイとしてではなく、ゾーンリソースとして表示され、次の図に示すようにアベイラビリティゾーンごとに個別にインスタンス化します。NAT ゲートウェイは、 VPC のインターネット接続経路にあるため、その VPC 内の EC2 インスタンスのデータプレーンの一部です。1つのアベイラビリティーゾーンに接続障害が起こる場合、他のゾーンに拡大するのを避けるために、その障害をそのアベイラビリティーゾーンにとどめたいと考えます。最後に、この記事で前述したものと同様のアーキテクチャ (つまり、 2 つ十分なストレージ容量を備え、3 つのアベイラビリティーゾーンにフリートをプロビジョニングして、フルロードを保持することが可能なアーキテクチャー) を構築したお客様は、あるアベイラビリティーゾーンで障害が起こっても他のアベイラビリティゾーンへの影響は完全に回避できます。これを行う唯一の方法は、NAT ゲートウェイなどのすべての基本コンポーネントをアベイラビリティーゾーン内に確実に配置することです。
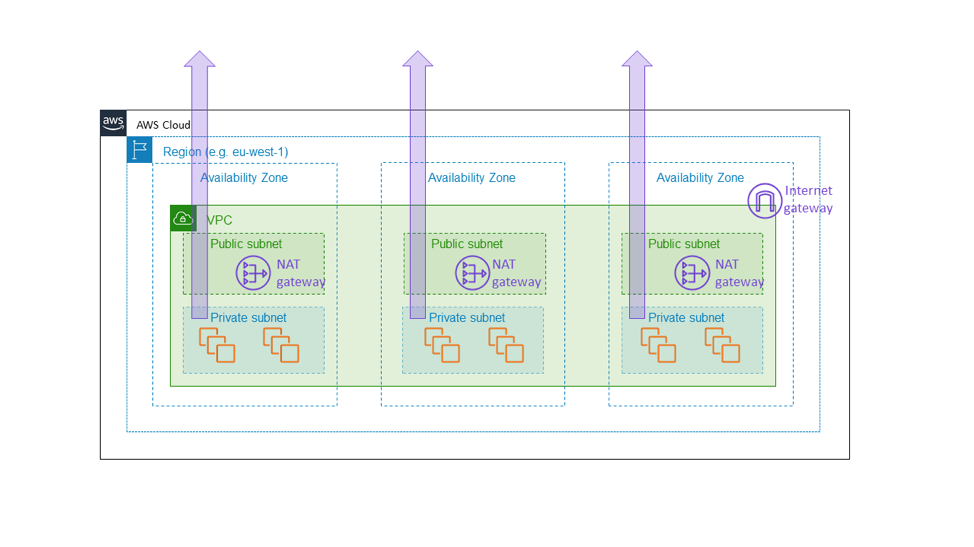
これを選択するとより複雑になりコストがかかります。Amazon EC2 におけるより複雑な構成では、リージョン内のサービス環境ではなく、ゾーンの管理環境という形でもたらされます。NAT ゲートウェイのお客様の場合、VPC のさまざまなアベイラビリティーゾーンで使用できる、複数の NAT ゲートウェイやルートテーブルを使用するという構成で複雑さが増します。NAT ゲートウェイ自体が基本的なサービスであり、ゾーンの可用性を確保する Amazon EC2 データプレーンの一部であるため、より複雑な構成は適切なのです。
アベイラビリティーゾーンに依存しないサービスを構築する際に考慮すべき点がもう 1 つあります。それはデータの耐久性です。前述の各ゾーンアーキテクチャは、単一のアベイラビリティゾーンに含まれるスタック全体を示していますが、災害復旧のために、複数のアベイラビリティゾーンにわたってハードウェアの状態をレプリケートします。たとえば、通常、定期的にデータベースのバックアップを Amazon S3 に保存し、アベイラビリティーゾーン間でデータストアのリードレプリカを維持します。これらのデータの複製は、プライマリアベイラビリティーゾーンで機能するために必要なものではありません。代わりに、顧客またはビジネスに不可欠なデータを複数の場所に確実に保存します。
AWSで実行されるサービス指向アーキテクチャを設計する際、これら 2 つのパターンのどちらか、または両方の組み合わせにするかを学びました。
- 比較的に単純なパターン:Regional-Calls-Regionalal。多くの場合、これは外部向けサービスに最適な選択肢ですが、ほとんどの内部サービスにも適しています。たとえば、Amazon API Gateway や AWS サーバーレステクノロジーなど、AWS で高レベルのアプリケーションサービスを構築する場合、このパターンを使用して、アベイラビリティゾーンの障害が発生しても高可用性を確保します。
- 比較的複雑なパターン:regional-calls-zonal または zonal-calls-zonal。Amazon EC2 の内部、場合によっては外部のデータプレーンコンポーネント (たとえば、重要なデータパスに直接配置されるネットワークアプライアンスまたはその他のインフラストラクチャ) を設計する場合、アベイラビリティーゾーンの独立性のパターンに従い、可用性でサイロ化されたインスタンスを使用します。これにより、ネットワークトラフィックが同じアベイラビリティゾーンにとどまります。このパターンは、アベイラビリティゾーンに隔離した障害を保持するのに役立つだけでなく、AWSでのネットワークトラフィックのコストにも優れています。
まとめ
この記事では、AWSでアベイラビリティーゾーンへの依存に関する簡単な戦略をいくつか説明しました。静的安定性の鍵は障害が発生する前に障害を予測することであることを学びました。システムがアクティブ/アクティブ構成の水平スケール可能なフリートで実行されているかどうか、またはステートフルなアクティブ/スタンバイパターンであるかどうかにかかわらず、アベイラビリティーゾーンを使用して高レベルの可用性をターゲットとします。障害が発生した場合に必要となる十分な容量が完全にプロビジョニングされ、すぐに使用できるようにシステムをデプロイします。最後に、Amazon EC2 自体が静的安定性の概念を使い、アベイラビリティーゾーン間を独立させる方法について詳しく見てきました。
著者について
Becky Weiss
 Becky Weiss は、アマゾン ウェブ サービスのシニアプリンシパルエンジニアです。彼女は現在、AWS で AWS Identity and Access Management (IAM) に携わっており、クラウド内の顧客に柔軟で包括的で信頼できるセキュリティコントロールを提供しています。彼女はこれまで Amazon Virtual Private Cloud (ネットワーク) と AWS Lambda に取り組み、AWS プロフェッショナルサービスと共に、顧客が AWS 上で環境の安全性を確保できるようにサポートしてきました。Becky は AWS の大ファンでもあり、暇なときには AWS で便利なもの、役に立たないもの、様々なものを構築しています。Beckyは、AWS で働く前は Microsoft でWindows や Windows Phone に関わっていました。
Becky Weiss は、アマゾン ウェブ サービスのシニアプリンシパルエンジニアです。彼女は現在、AWS で AWS Identity and Access Management (IAM) に携わっており、クラウド内の顧客に柔軟で包括的で信頼できるセキュリティコントロールを提供しています。彼女はこれまで Amazon Virtual Private Cloud (ネットワーク) と AWS Lambda に取り組み、AWS プロフェッショナルサービスと共に、顧客が AWS 上で環境の安全性を確保できるようにサポートしてきました。Becky は AWS の大ファンでもあり、暇なときには AWS で便利なもの、役に立たないもの、様々なものを構築しています。Beckyは、AWS で働く前は Microsoft でWindows や Windows Phone に関わっていました。
Mike Furr
 Mike Furr は、アマゾン ウェブ サービスのプリンシパルエンジニアです。彼は、メリーランド大学カレッジパーク校でコンピューターサイエンスの博士号を取得した後、2009 年に Amazon に入社しました。Amazon 在職中、彼は Virtual Private Cloud、Direct Connect、および AWS Metering と AWS Billing にも取り組んできました。彼は現在、EC2 に専念しており、チームのクラウドのスケーリングのサポートをしています。
Mike Furr は、アマゾン ウェブ サービスのプリンシパルエンジニアです。彼は、メリーランド大学カレッジパーク校でコンピューターサイエンスの博士号を取得した後、2009 年に Amazon に入社しました。Amazon 在職中、彼は Virtual Private Cloud、Direct Connect、および AWS Metering と AWS Billing にも取り組んできました。彼は現在、EC2 に専念しており、チームのクラウドのスケーリングのサポートをしています。
関連コンテンツ
今日お探しの情報は見つかりましたか?
ぜひご意見をお寄せください。ページのコンテンツ品質の向上のために役立てさせていただきます