Containers
Introducing the AWS Controllers for Kubernetes (ACK)
AWS Controllers for Kubernetes (ACK) is a new tool that lets you directly manage AWS services from Kubernetes. ACK makes it simple to build scalable and highly-available Kubernetes applications that utilize AWS services.
Today, ACK is available as a developer preview on GitHub.
In this post we will give you a brief introduction to the history of the ACK project, show you how ACK works, and how you can start to use the ACK or contribute.
How did we get here?
In late 2018, Chris Hein introduced the AWS Service Operator as an experimental personal project. We reviewed the feedback from the community and internal stakeholders and decided to relaunch as a first-tier open source project. In this process, we renamed the project to AWS Controllers for Kubernetes (ACK). The tenets we put forward are:
- ACK is a community-driven project, based on a governance model defining roles and responsibilities.
- ACK is optimized for production usage with full test coverage including performance and scalability test suites.
- ACK strives to be the only code base exposing AWS services via a Kubernetes operator.
Over the past year, we have significantly evolved the project’s design, continued the discussion with internal stakeholders (more in a moment why this is important), and reviewed related projects in the space. A special shout-out in this context to the Crossplane project which does an awesome job for cross-cloud use cases and deservedly became an CNCF project in the meantime.
The new ACK project continues the spirit of the original AWS Service Operator, but with a few updates:
- AWS cloud resources are managed directly through the AWS APIs instead of CloudFormation. This allows Kubernetes to be the single ‘source of truth’ for a resources desired state.
- Code for the controllers and custom resource definitions is automatically generated from the AWS Go SDK, with human editing and approval. This allows us to support more services with less manual work and keep the project up-to-date with the latest innovations.
- This is an official project built and maintained by the AWS Kubernetes team. We plan to continue investing in this project in conjunction with our colleagues across AWS.
How ACK works
Our goal with ACK to provide a consistent Kubernetes interface for AWS, regardless of the AWS service API. One example of this is ensuring field names and identifiers are normalized and tags are handled the same way across AWS resources.
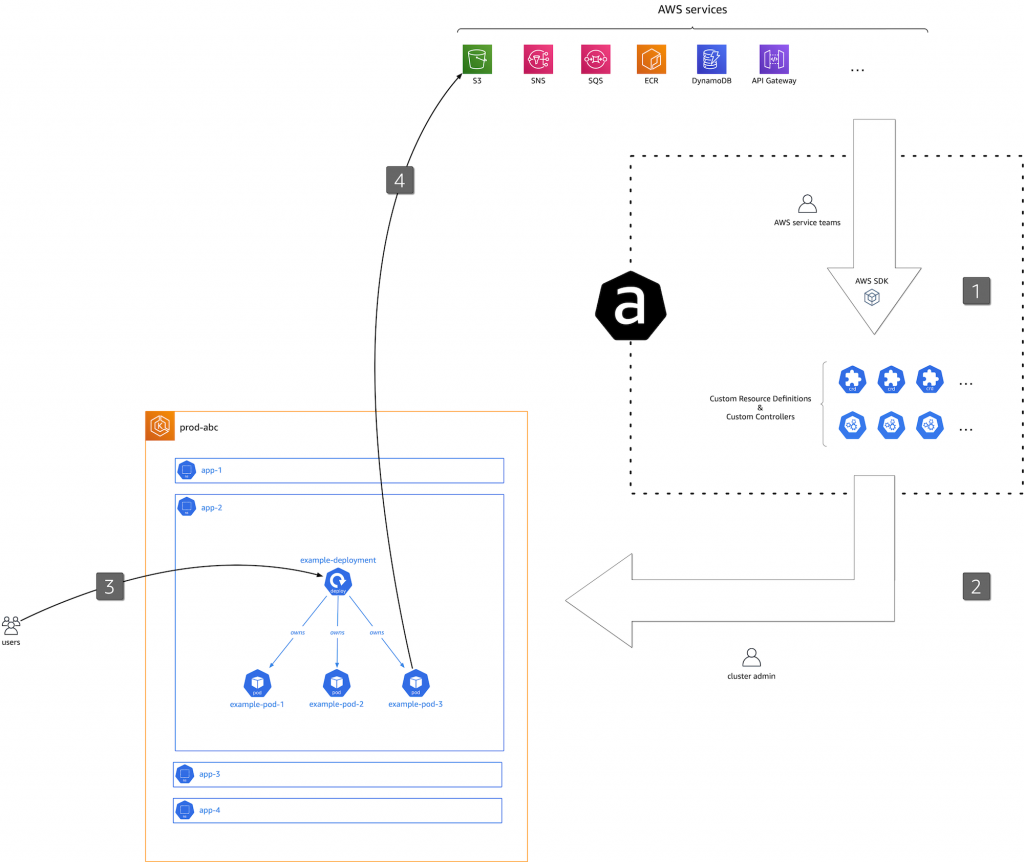
As depicted above, from a high level, the ACK workflow is as follows:
- We, as in “the project team lead by the authors”, generate and maintain a collection of artifacts (binaries, container images, Helm charts, etc.). These artifacts are automatically derived from the AWS services APIs and represent the business logic of how to manage AWS resources from within Kubernetes.
- As a cluster admin you select one or more ACK controllers you want to install and configure for a cluster you’re responsible.
- As an application developer, you create (Kubernetes) custom resources representing AWS resources.
- The respective ACK controller (installed in the step 2.) manages said custom resources and with it the underlying AWS resources. Based on the custom resource defined in the step 3., the controller creates, updates, or deletes the underlying AWS resources using the AWS APIs.
Let’s now have a closer look at the workflow, using a concrete example.
1. Generation of artifacts
Artifacts generation creates the required code components that allow you to manage AWS services using Kubernetes. We took an multi-phased approach, yielding hybrid custom+controller-runtimes:
- First, we consume model information from a canonical source of truth about AWS services. We settled on the source of truth as the model files from the
aws/aws-sdk-gorepository. AWS SDKs are regularly updated with all API changes so this is an accurate source of information and closely tracks the service API avilability. In this phase we generate files containing code that exposes Go types for objects and interfaces found there. - After generating Kubernetes API type definitions for the top-level resources exposed by the AWS API, we then need to generate the interface implementations enabling those top-level resources and type definitions to be used by the Kubernetes runtime package
- Next, we generate the custom resource definition (CRD) configuration files, one for each top-level resource identified in earlier steps. Then, we generate the implementation of the ACK controller for the target service. Along with these controller implementations in Go, this steps also outputs a set of Kubernetes manifests for the
Deploymentand theClusterRoleBindingof theRolefor the next step. - Finally, we generate the Kubernetes manifests for a Kubernetes
Rolefor the KubernetesDeploymentrunning the respective ACK service controllers. Abiding the least privileges principle, thisRoleneeds to be equipped with the exact permissions to read and write custom resources of theKindthat said service controller manages.
The above artifacts—Go code, container images, Kubernetes manifests for CRDs, roles, deployments, etc.—represent the business logic of how to manage AWS resources from within Kubernetes and are the responsibility of AWS service teams to create and maintain along with input from the community.
2. Installation of custom resources & controllers
To use ACK in a cluster you install the desired AWS service controller(s), considering that:
- You set the respective Kubernetes Role-based Access Control (RBAC) permissions for ACK custom resources. Note that each ACK service controller runs in its own pod and you can and should enforce existing IAM controls including permissions boundaries or service control policies to define who has access to which resources, transitively defining them via RBAC.
- You associate an AWS account ID to a Kubernetes namespace. Consequently that mean every ACK custom resource must be namespaced (no cluster-wide custom resources).
As per the AWS Shared Responsibility Model, in the context of the cluster administration, you are responsible for regularly upgrading the ACK service controllers as well as applying security patches as they are made available.
3. Starting AWS resources from Kubernetes
As an application developer, you create a namespaced custom resource in one of your ACK-enabled clusters. For example, let’s say you want ACK to create an Amazon Elastic Container Registry (ECR) repository, you’d define and subsequently apply something like:
apiVersion: "ecr.services.k8s.aws/v1alpha1"
kind: Repository
metadata:
name: "my-ecr-repo"
spec:
repositoryName: "encrypted-repo-managed-by-ack"
encryptionConfiguration:
encryptionType: AES256
tags:
- key: "is-encrypted"
value: "true"
4. Managing of AWS resources from Kubernetes
ACK service controllers installed by cluster admins can create, update, or delete AWS resources, based on the intent found in the custom resource defined in the previous step, by developers. This means that in an ACK-enabled target cluster, the respective AWS resource (in our example case the ECR repo) will be created, with you having access to it, once you apply the custom resource.
Let’s focus a little bit more on the creation and management of AWS resources from Kubernetes, since this is how most users will interact with ACK. In our example, we will create an S3 bucket from our cluster.
Walkthrough: managing an S3 bucket with ACK
In the following, we want to use ACK to manage an S3 bucket for us. Given that this is a developer preview, we’re using the testing instructions as per contributor docs. In this context, we’re use kind to do local end-to-end testing with Docker as its only dependency.
Building the container image for the S3 service controller, creating the cluster and deploying all the resources with the make kind-test -s SERVICE=s3 command will likely take some 45min the first time around (cold caches). Once that’s done, you can have a look at the ACK setup:
$ kubectl -n ack-system get all
NAME READY STATUS RESTARTS AGE
pod/ack-s3-controller-86d9cf5cd7-z7l42 1/1 Running 0 10m
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/ack-s3-controller 1/1 1 1 10m
NAME DESIRED CURRENT READY AGE
replicaset.apps/ack-s3-controller-86d9cf5cd7 1 1 1 10Further, we’d expect the S3 CRD to be installed and available in the test cluster, and indeed:
$ kubectl get crd
NAME CREATED AT
buckets.s3.services.k8s.aws 2020-08-17T06:15:22ZBased on the CRD we would further expect to find an S3 bucket custom resource:
$ kubectl get buckets
NAME AGE
ack-test-smoke-s3 3m8sLet’s now have a cluster look at the S3 bucket customer resource (note: what is shown here is the automatically generated custom resource from the integration test, edited for readability):
$ kubectl get buckets ack-test-smoke-s3 -o yaml
apiVersion: s3.services.k8s.aws/v1alpha1
kind: Bucket
metadata:
name: ack-test-smoke-s3
namespace: default
spec:
name: ack-test-smoke-s3Taking all together, the above setup looks as follows:

OK, with this hands-on completed you should now have an idea how ACK works. Let us now turn our attention to how you can get engaged and what’s up next.
Next steps
We are super excited that as of today, ACK is available as a developer preview, supporting the following AWS services:
- Amazon API Gateway V2
- Amazon DynamoDB
- Amazon ECR
- Amazon S3
- Amazon SNS
- Amazon SQS
You can get started with installing and using ACK with our documentation. Note that developer preview means that the end-user facing install mechanisms are not yet in place.
Future services
In time, we expect to support and enable as many AWS services as possible, and onboard them with full support to ACK. Specifically, in the coming months we plan to focus on:
- Amazon Relational Database Service (RDS), track via the RDS label.
- Amazon ElastiCache offers fully managed Redis and Memcached, track via the Elasticache label.
In addition to RDS and ElastiCache, we are also considering support for Amazon Elastic Kubernetes Service (EKS) as well as Amazon Managed Streaming for Apache Kafka (MSK).
Upcoming features
Important features we’re working on and which should be available as well within the next couple of weeks and months include:
-
- Enabling cross-account resource management.
- Native application secrets integration.
Help us build
ACK is still a new project, and we’re looking for input from you to help guide our development. Conceptually, we are interested in your feedback about:
- The expected behavior of destructive operations in ACK.
- Whether or not ACK should be able to adopt AWS resources.
Starting today, during the AWS Container Day as well as during the entire KubeCon EU 2020 we will have a number of opportunities to discuss the current state of ACK and the next steps. Fire up your clusters, we can’t wait to see what you build!