Amazon Redshift Integration for Apache Spark
Amazon Redshift에서 데이터를 읽고 쓰는 Apache Spark 애플리케이션 구축
Amazon Redshift Integration for Apache Spark를 사용해야 하는 이유는 무엇인가요?
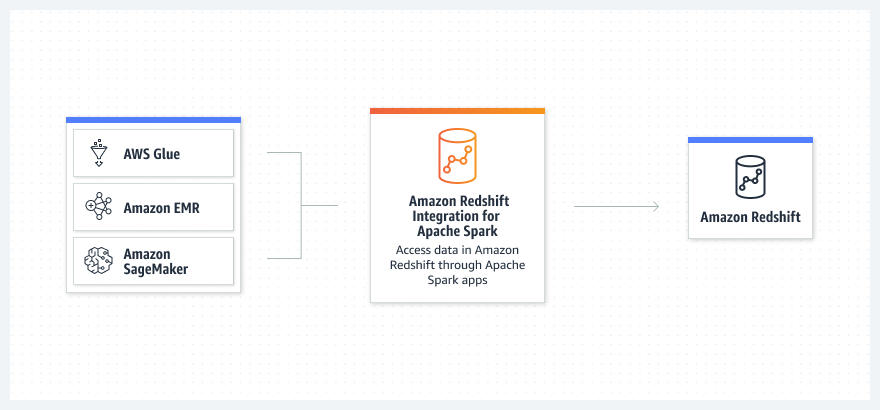
Amazon Redshift Integration for Apache Spark는 Amazon EMR, AWS Glue, Amazon SageMaker 등과 같은 AWS 분석 서비스에서 Amazon Redshift 데이터에 액세스하는 Apache Spark 애플리케이션을 단순화하고 가속화합니다. Amazon EMR, AWS Glue 및 SageMaker를 사용하여 성능이나 트랜잭션 일관성을 해치지 않고 Amazon Redshift 데이터 웨어하우스에서 데이터를 읽고 쓰는 Apache Spark 애플리케이션을 신속하게 구축할 수 있습니다. 또한, Amazon Redshift Integration for Apache Spark는 AWS Identity and Access Management(IAM) 기반 보안 인증을 사용하여 보안을 개선합니다. Amazon Redshift Integration for Apache Spark를 사용하면 서드 파티 커넥터의 인증되지 않은 버전을 수동으로 설정하고 유지 관리할 필요가 없습니다. Amazon Redshift에서 몇 초 이내로 데이터를 사용하여 Apache Spark 작업을 시작할 수 있습니다. 이 새로운 통합은 Amazon Redshift 데이터를 사용하여 Apache Spark 애플리케이션의 성능을 개선합니다.

Amazon Redshift의 이점
-
Amazon EMR, AWS Glue 또는 SageMaker에서 실행되는 기능이 풍부한 분석 도구 및 기계 학습(ML) 애플리케이션에서 데이터 웨어하우스로 데이터를 읽고 쓸 수 있는 데이터 소스의 범위를 넓힐 수 있습니다.
-
인증되지 않은 커넥터와 JDBC 드라이버를 설정하는 번거롭고 수동적인 프로세스를 간소화하여 분석 및 ML 작업을 위한 준비 시간을 단축합니다.
-
정렬, 집계, 제한, 조인 및 스칼라 함수와 같은 여러 푸시다운 기능을 사용하여 Amazon Redshift 데이터 웨어하우스에서 관련 데이터만 이동할 수 있습니다.
사용 사례
-
Apache Spark 기반 AWS 분석 서비스를 사용하여 Java, Scala, Python으로 Apache Spark 애플리케이션을 생성합니다.
-
Amazon EMR, AWS Glue, SageMaker, AWS Analytics와 ML 서비스로 Amazon Redshift에서 데이터를 읽고 씁니다.
-
Amazon EMR 또는 AWS Glue를 사용하여 Apache Spark 작업이나 노트북에서 데이터 프레임 코드를 가져오고 Amazon Redshift로 연결합니다.
-
설치나 테스트 없이 프로세스를 간소화하고, 향상된 보안(IAM 기반 보안 인증)과 운영 푸시다운, 성능 향상을 위한 Parquet 파일 형식을 지원합니다.
고객
Corey Johnson, Huron Consulting Data Architect Manager
Huron은 클라이언트와 협력하여 철저한 전략을 수립하고, 운영을 최적화하고, 디지털 트랜스포메이션을 가속화하며, 비즈니스 및 직원이 미래를 가질 수 있도록 잠재력을 실현하는 글로벌 전문 서비스 회사입니다.
"저희는 엔지니어들이 Python과 Scala를 사용하여 Apache Spark로 데이터 파이프라인과 애플리케이션을 구축할 수 있도록 지원합니다. 운영을 간소화하고 클라이언트에게 더욱 빠르고 효율적으로 제공할 수 있는 맞춤형 솔루션을 원했고, 새로운 Amazon Redshift Integration for Apache Spark가 바로 그런 제품이었습니다."
Alcuin Weidus, GE Aerospace Sr Principal Data Architect
GE Aerospace는 상업용 항공기와 군용 항공기의 제트 엔진, 부품, 시스템을 제공하는 글로벌 업체입니다. 이 회사는 1차 세계대전부터 제트 엔진을 설계, 개발 및 제조해 오고 있습니다.
"GE Aerospace는 AWS 분석과 Amazon Redshift를 사용하여 중요한 비즈니스 결정을 내리는 데 도움을 주는 중요한 비즈니스 인사이트를 얻습니다. Amazon S3에서 자동 사본이 지원되기 때문에 Amazon S3에서 Amazon Redshift까지 데이터를 이동하는 더욱 단순한 데이터 파이프라인을 구축할 수 있습니다. 따라서 데이터 제품 팀이 데이터에 액세스하고, 최종 사용자에게 인사이트를 제공하는 능력이 더욱 향상됩니다. 저희는 데이터를 통해 가치를 창출하는 데 더 많은 시간을 투자하고, 통합에 들이는 시간은 줄일 수 있게 되었습니다."
Neema Raphael, Goldman Sachs Chief Data Officer
Goldman Sachs Group, Inc.는 투자 은행, 증권, 투자 관리 및 소비자 금융 전반에 걸쳐 광범위한 금융 서비스를 기업, 금융 기관, 정부 및 개인을 비롯한 크고 다양한 고객층에 제공하는 선도적인 글로벌 금융 기관입니다.
"저희는 Goldman Sachs의 모든 사용자에게 데이터에 대한 셀프 서비스 액세스를 제공하는 데 중점을 두고 있습니다. 오픈 소스 데이터 관리 및 거버넌스 플랫폼인 Legend를 통해 사용자는 금융 서비스 산업 전반에서 협업하면서 데이터 중심 애플리케이션을 개발하고 데이터 중심 인사이트를 얻을 수 있습니다. Amazon Redshift Integration for Apache Spark를 통해 저희 데이터 플랫폼 팀은 최소한의 수동 단계를 거쳐 Amazon Redshift 데이터에 액세스합니다. 엔지니어가 완전하고 적시에 정보를 수집할 때 워크플로를 완벽하게 만드는 데 더 쉽게 집중할 수 있는 제로 코드 ETL가 지원됩니다. 이제 사용자가 Amazon Redshift의 최신 데이터에 쉽게 액세스할 수 있으므로 애플리케이션의 성능이 향상되고 보안이 향상될 것으로 기대합니다."
오늘 원하는 내용을 찾으셨나요?
페이지의 콘텐츠 품질을 개선할 수 있도록 피드백을 보내주세요.