Amazon SageMaker Canvas
Build highly accurate ML models using a visual interface, no code required
What is SageMaker Canvas?
Amazon SageMaker Canvas empowers you to transform data at petabyte-scale, and build, evaluate, and deploy production-ready machine learning (ML) models without coding. It streamlines the end-to-end ML lifecycle in a unified and secure enterprise environment. With Amazon Q Developer now available in SageMaker Canvas, you can get guidance throughout your ML journey – from data preparation to model deployment – using conversational chat
SageMaker Canvas fosters collaboration across teams, provides transparency into the generated code, and ensures governance through model versioning and access controls. With SageMaker Canvas, you can accelerate innovation and more quickly solve business problems by democratizing ML development across all skill levels and regardless of coding expertise.
SageMaker Canvas Benefits
-
Access end-to-end ML capabilities across the lifecycle, from data preparation to building, evaluating, and deploying models at petabyte-scale.
-
Canvas trains multiple models using several algorithms to produce highly accurate custom machine learning models, all through a no-code experience.
-
Enable model sharing and integration with other AWS services including SageMaker Model Registry and Amazon DataZone for governance and ML Ops.
-
Boost collaboration with experts through code-level transparency.
-
Describe your objectives using natural language chat. Amazon Q Developer guides you through the machine learning process, from data preparation to model building, while addressing queries about your data and model.
Build across the ML lifecycle

1. Visually Prepare Your Data at Petabyte-Scale
- Access and import data from 50+ sources, including Amazon S3, Athena, Redshift, Snowflake, and Databricks
- Improve data quality and model performance with 300+ pre-built analyses and transformations
- Visually build and refine your data pipelines with an intuitive, low-code / no-code interface
- Scale to petabyte-size data with a few clicks

2. Chat-Guided ML Development with Amazon Q Developer
- Describe your business problem in natural language, and let Amazon Q Developer guide you to a solution through the entire ML process using a chat interface
- Q Developer breaks down problems into actionable ML tasks and assists with data preparation, model building, evaluation, and deployment
- Ask questions and receive answers about ML terms and your data and models
- Q Developer applies advanced data preparation and model building techniques while allowing full control to execute tasks on your own

3. Train and Evaluate Models Across Multiple Problem Types
- Harness the power of AutoML to automatically explore and optimize models for your specific use case
- Train models for regression, classification, time series forecasting, natural language processing, computer vision, and fine-tune foundation models with just a few clicks
- Tailor your model training with flexible options for objective metrics, data splits, and model controls like algorithm selection and hyperparameters
- Gain insights into model performance with interactive visualizations and model explanations
- Select the best-performing model from a model leaderboard, and export the generated code for further customization
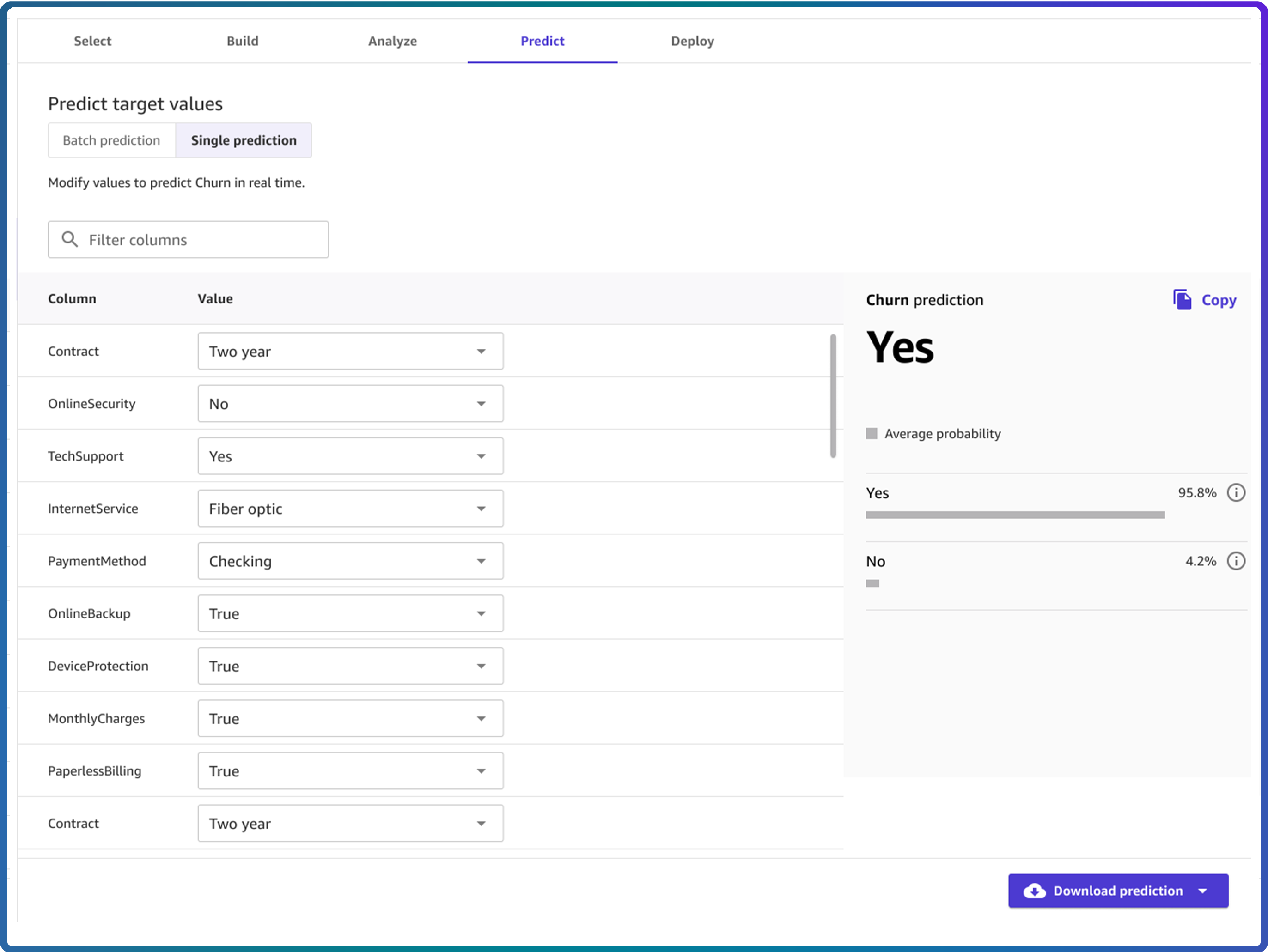
4. Generate Accurate Predictions at Scale - Batch or Real-Time
- Perform interactive predictions and what-if analyses directly within the application
- Deploy models with a single click to a SageMaker endpoint for real-time inference, or run batch predictions ad-hoc or with automated schedules
- Ensure governance and version control by registering models in the SageMaker Model Registry
- Seamlessly share models with Amazon SageMaker Studio for advanced customization and collaboration
- Visualize and share predictions with stakeholders using Amazon QuickSight for enhanced decision-making
Collaborate and ensure governance
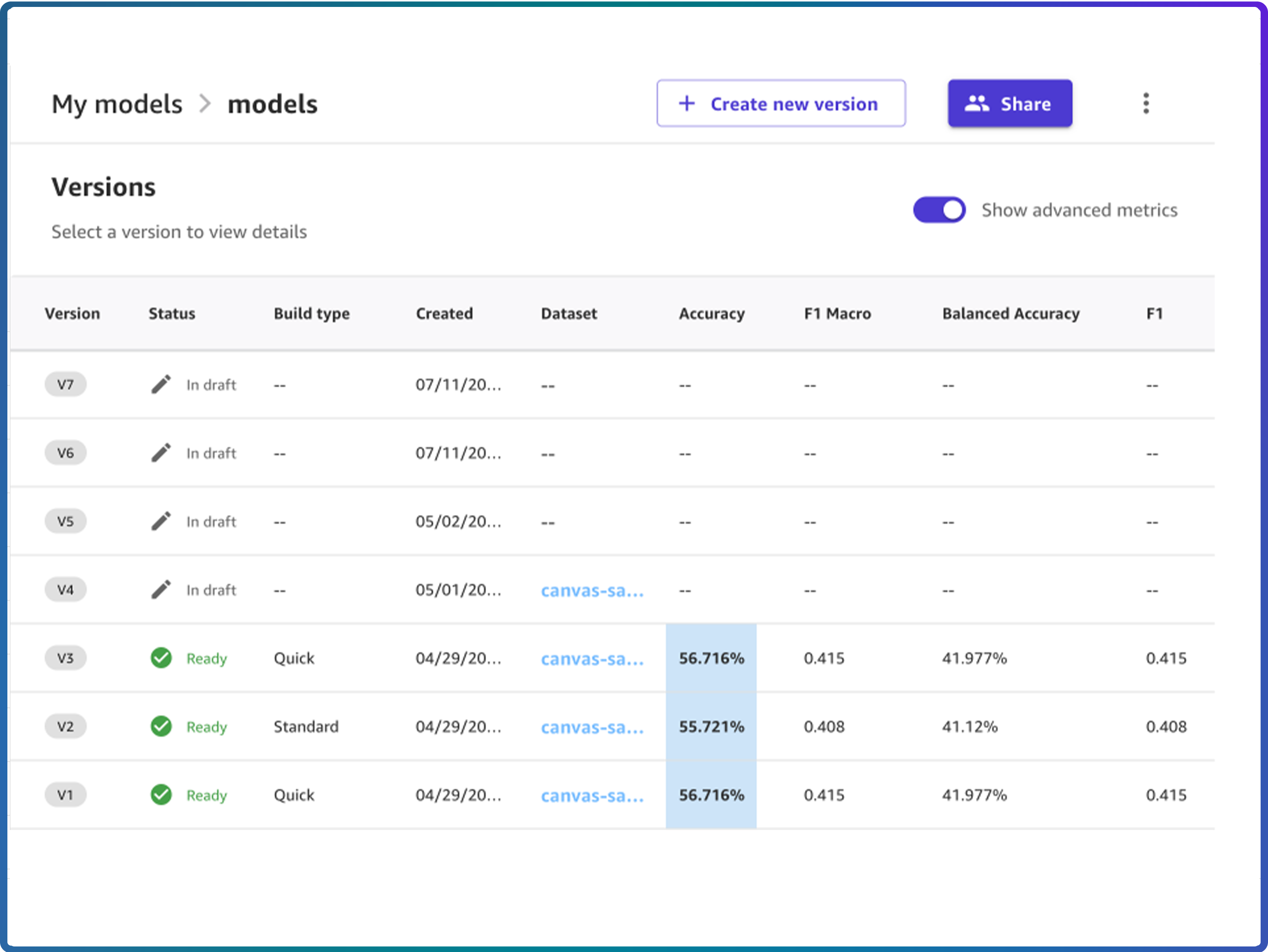
1. Foster Cross-Team Collaboration and Knowledge Sharing
- Collaborate with data scientists and experts through easy model sharing with SageMaker Studio
- Use models built by data scientists within Canvas workspace to generate predictions
- Increase trust with code transparency with automatically generated notebooks
- Share models, predictions, and insights with stakeholders via Amazon QuickSight dashboards
- Maintain version control and model lineage tracking, ensuring reproducibility and traceability across teams

2. Ensure Governance and MLOps Best Practices
- Implement granular user-level permissions and access controls for secure model management
- Enable seamless authentication with single sign-on (SSO) capabilities
- Adhere to model governance and versioning by registering models in the SageMaker Model Registry
- Streamline MLOps pipelines by exporting model notebooks for further customization and integration
- Optimize costs and resource utilization with auto-shutdown features
Build with foundation models
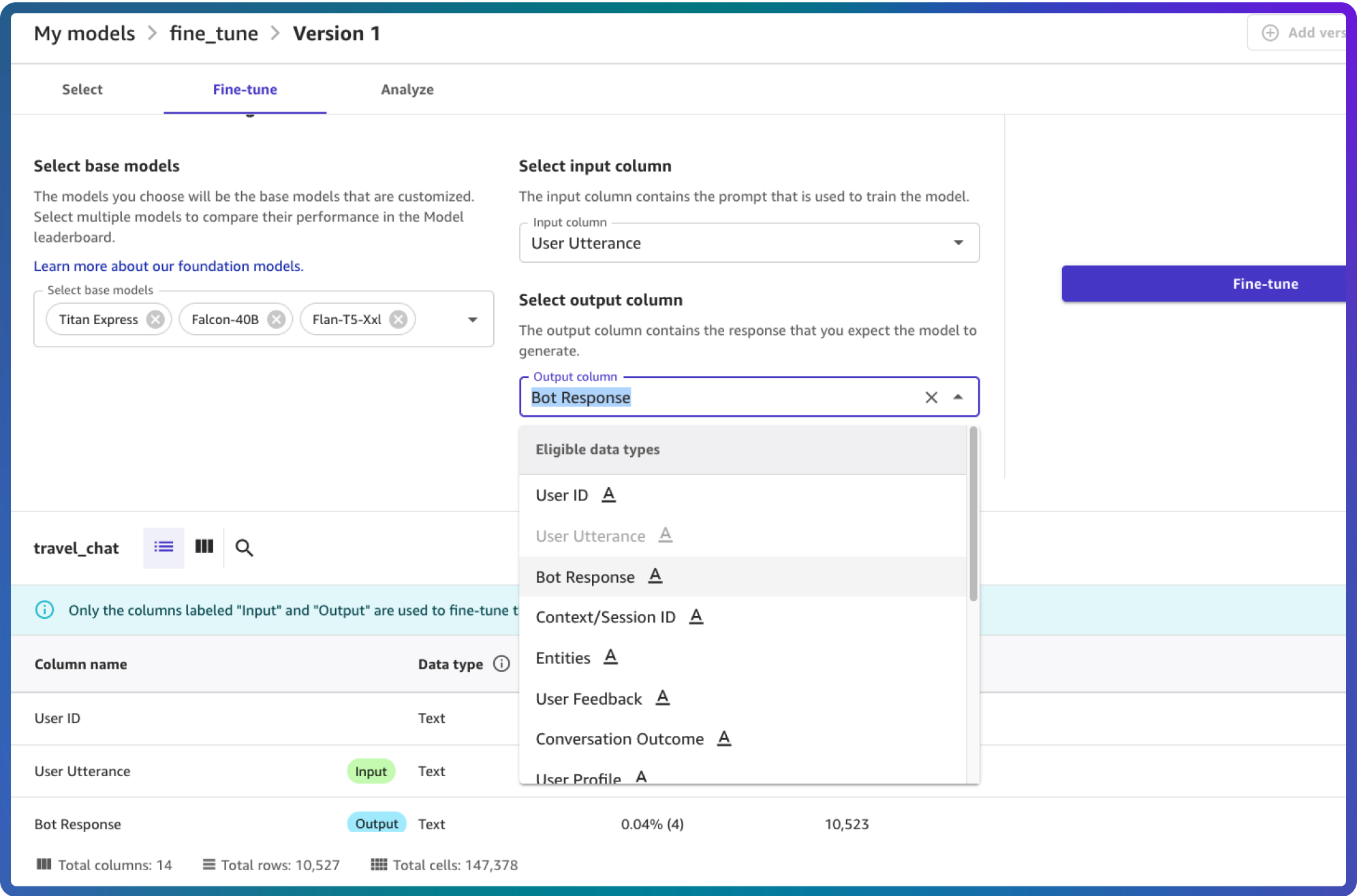
- Easily compare and select the most suitable foundation model for your task
- Fine-tune foundation models using your labeled training dataset for business use-cases in a few clicks
Make use of your generative AI
- Query your own documents and knowledge bases stored in Amazon Kendra to generate tailored outputs
- Gain insights into model performance with interactive visualizations, model explanations, and leaderboards
- Productionize and deploy the most suitable foundation models to real-time SageMaker endpoints
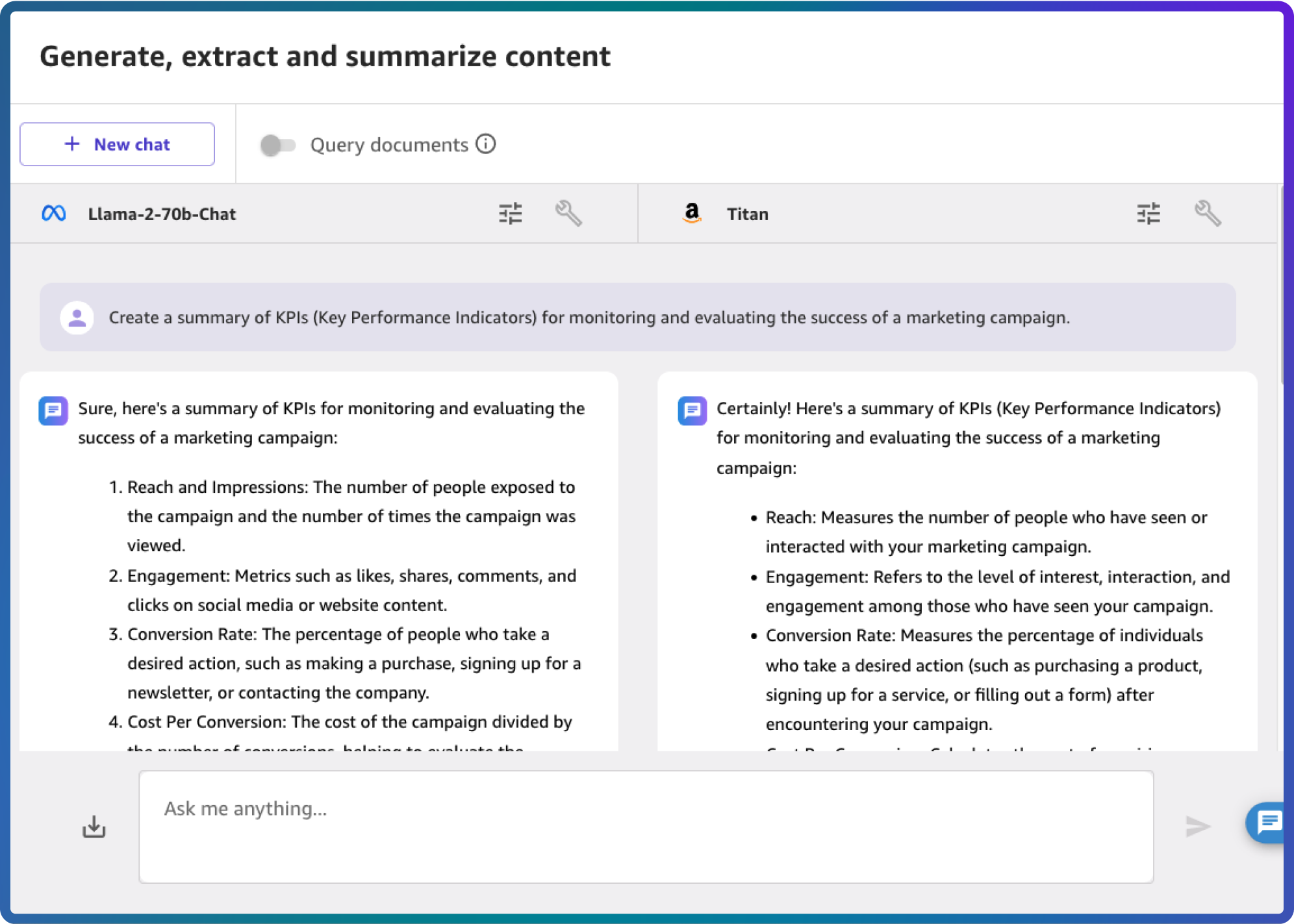
Use cases
-
Use product consumption and purchase history data to understand sales propensity and uncover customer churn patterns.
-
Forecast inventory levels by combining historical sales and demand data with associated web traffic, pricing, product category, and holiday data.
-
Predict failures for manufacturing equipment by analyzing sensor data and maintenance logs and avoid downtimes.
-
Create personalized, engaging, and high-quality sales and marketing content such as social media posts, product descriptions, and email campaigns.
-
Analyze and extract information from a variety of documents, such as insurance claims, invoices, expense reports, or identity documents.
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages