With Deep Learning, Disney Sorts Through a Universe of Content
In a 1957 episode of the TV series Disneyland, Walt Disney leads viewers into the depths of his Burbank animation studio. “In our morgue,” he says, referring to the underground library, “these shelves, tables, and file cabinets hold all our history as a motion picture studio.”
In a 1957 episode of the TV series Disneyland, Walt Disney leads viewers into the depths of his Burbank animation studio. “In our morgue,” he says, referring to the underground library, “these shelves, tables, and file cabinets hold all our history as a motion picture studio.”
Well before other animation studios, Disney insisted that its archive be accessible to writers and illustrators who might need it for reference or inspiration. Drawings, concept artwork, and more from favorites like Dumbo and Peter Pan were carefully tucked away in this vault. And in the years since, Disney has stayed committed to preservation.
With nearly a century of content on its hands, a growing percent of it digital, Disney must organize its library more carefully than ever. Keeping order and cleanliness among the (virtual) stacks is a small team of R&D engineers and information scientists within Disney’s Direct-to-Consumer & International (DTCI) Technology team. DTCI was formed in 2018, in part to bring together technologists and expertise from across The Walt Disney Company and align technology to support the huge array of unique content and business needs at Disney.
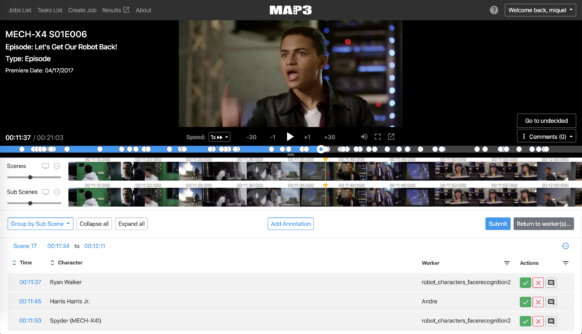
The foundation of the organizational system is metadata: information about the stories, scenes and characters in Disney’s shows and movies. For example, Bambi would have metadata tags that identify not only characters like Thumper the rabbit or Faline (Bambi’s fawn friend), but the type of animal, relationships between animals, and the character archetypes each animal portrays. Things like the nature scenes—down to the specific types of flowers depicted—music, sentiment and tone of the story, also have specific tags. As a result, appropriately tagging all of this content with the right metadata that allows it to be sorted properly is challenging, particularly considering the sheer pace of Disney’s growth:
“We have new characters in TV shows, football players changing teams, new weapons for superheroes, new shows,” said Miquel Farré, the team’s technical lead, and all of it requires a heap of fresh metadata.
With the help of AWS services, he and his team are building machine-learning and deep-learning tools to automatically tag this content with descriptive metadata to make the archiving process more efficient. As a result, writers and animators can quickly search for, and familiarize themselves with, everyone from Mickey Mouse to Modern Family’s Phil Dunphy.
What’s so magical about metadata?
Image Courtesy of Disney
The team leading this work was originally formed in 2012, as a part of the Disney & ABC Television Group. Over the years, it has grown, and now as a part of Disney’s DTCI Technology group, it has become the index and knowledge base of the styles and conventions of the Disney universe (for example, in Bambithe animals talk—in Snow White, they don’t). For their machine-learning tools to generate metadata that accurately describes the creative content, the team depends on the writers and animators to explain the stylistic features that make each show unique.
These creative team members benefit from their cooperation. Once the content is tagged with accurate metadata, they can quickly find what they need through a search interface. For example, a writer for Grey’s Anatomy, to avoid redundancy, might need to know how many times the Whipple surgery has been featured in an episode. Meanwhile, an artist drawing underwater life for a new cartoon taking place under the sea might want to look for a specific character pose or positioning in The Little Mermaidor Finding Nemo for inspiration.
But tagging everything with the right metadata quickly presents a labor problem: even though manual tagging is an important part of the process, the DTCI Technology team doesn’t have time to manually categorize every frame. That’s why Farré’s team has put machine learning—and more recently, deep learning—to the task of generating metadata. The goal is to build deep-learning algorithms that can automatically tag the components of a scene in a way that’s consistent with the rest of the Disney knowledge base. Humans still need to approve the algorithm’s tags, but the project is meaningfully reducing the work that goes into organizing the Disney library, improving the accuracy of searches within it.
What’s more, this progress is freeing up engineers to focus more on developing deep-learning models using AWS (Amazon Web Services). And as a result, their efforts to automate metadata creation across different kinds of Disney content are humming along.

Deep learning gives animations an identity
Image Courtesy of Disney
One of the most successful deep learning/metadata projects has been solving the problems presented by animation recognition.
In a live-action movie or TV show, for a machine, separating a character from her surroundings is relatively simple. But animation makes things more complicated. For example, take an animated scene in which a character appears both in the flesh and in a poster (say the character is a criminal, and Wanted signs have been posted throughout town). “For an algorithm, this is extremely complex,” said Farré.
In the last year, Farré’s team has developed a deep-learning method that can distinguish animated characters from their static representations, identify them within a crowd of doppelgangers (as in DuckTales, where many characters are pretty much identical), and recognize them in scenes with funky lighting (in Alice in Wonderland,when Alice first meets in the Cheshire Cat, all he reveals is his toothy grin). Having decided what’s what, the algorithm can tag the scenes with the appropriate metadata.
But the model’s real power is that it can be applied to any piece of animated content. That is, rather than create a new model for every Goofy, Hercules, and Elsa, the team only need use their generic model, which, with slight adjustments, will work for any character in any show or movie.
Before this year, the team was working with more traditional machine-learning algorithms, which require less data than a deep-learning approach – but also resulted in more limited, less flexible results. With fewer data inputs, traditional algorithms perform well. But when you have exponentially more data is when deep learning can make a huge difference.
Now, says Farré, the deep-learning model can benefit from already trained networks and fine tune for specific-use cases. In the specific case of animated characters, Disney fine-tuned a neural network with thousands of images to make sure it understands the concept of an “animated character.” Then, for each specific show, the neural network is readjusted using just a few hundred images from across a few episodes for it to learn how “animated characters” should be detected and interpreted within the specific show.
AWS has been a key partner in Disney’s transition from traditional machine learning to deep learning, especially when it comes to experimentation. Elastic cloud computing EC2 instances allow the team to quickly test new versions of the model. (For the animation-recognition project, Disney is using the PyTorch framework with pre-trained models.) Since there’s a lot of research going on in deep learning, the team is constantly experimenting with new and novel methods.
The metadata research has been so successful that departments across Disney have caught wind. Farré said his team recently engaged with ESPN’s personalization team to provide detailed metadata about all the articles and videos that go on the industry-leading digital applications and websites. If the product knows you are a fan of the Los Angeles Dodgers, Steph Curry, the Minnesota Vikings, and Manchester United, the more metadata it has about each article can ensure you are served content most aligned to your preferences. Additionally, the machine-learning algorithms, and the metadata they deliver, can power more advanced AI to drive further implicit personalization (based on data relationships and behavior) over time.
As Farré sees it, the applications for metadata are endless, especially given Disney’s vast and growing library of distinctive content, characters, and products. “I think we won’t get bored,” he said.