O blog da AWS
Processando arquivos posicionais com AWS Glue
Por Luiz Yanai, arquiteto especialista sênior em Data & AI na AWS.
Você já precisou processar arquivos em larga escala e teve dificuldade porque o layout é posicional?
O processamento de arquivos com layout posicional ainda é importante no cenário tecnológico atual, mesmo com o surgimento de formatos mais modernos. Essa importância deriva principalmente da necessidade de manter a compatibilidade com sistemas legados, que ainda são amplamente utilizados em setores críticos como o bancário, empresas de telecomunicações ou mesmo empresas ligadas ao governo. A eficiência no processamento de grandes volumes de dados e a economia de espaço de armazenamento são outras vantagens notáveis desse formato, tornando-o uma escolha preferencial em situações onde a performance e a otimização de recursos são cruciais.
Além disso, a natureza estruturada e padronizada dos arquivos posicionais oferece benefícios substanciais em termos de integridade de dados, facilidade de auditoria e precisão no controle de informações. Essas características são particularmente valiosas em ambientes regulamentados ou em processos que exigem alta confiabilidade. A simplicidade inerente ao formato também contribui para sua robustez, reduzindo a probabilidade de erros de formatação e facilitando a validação dos dados. Em um contexto de integração entre sistemas heterogêneos, o layout posicional muitas vezes serve como um “denominador comum”, permitindo a troca eficiente de dados entre plataformas diversas.
Introdução
Neste blog post demonstramos como você pode processar seu arquivo de forma simples (sem uso de código) usando duas funcionalidades do AWS Glue: Classificadores personalizados e AWS Glue DataBrew.
O AWS Glue é um serviço de integração de dados com tecnologia sem servidor que facilita a descoberta, preparação, movimentação e integração de dados de várias fontes para análise, machine learning (ML) e desenvolvimento de aplicações. AWS Glue é um serviço composto por diferentes componentes para auxiliar na sua jornada de dados: Data Catalog, Glue crawlers, Glue Job e Glue DataBrew.
Usando Classificadores personalizados
Uma primeira estratégia possível para analisar seus arquivos que tem características de formatação posicional é fazer a decomposição de campos diretamente na leitura deles usando uma definição de classificador personalizado. Um classificador lê os dados em uma armazenamento de dados. Se reconhecer o formato dos dados, ele gerará um esquema. O classificador também retornará um número para indicar o nível de certeza referente ao reconhecimento do formato.
O AWS Glue fornece um conjunto de classificadores integrados, mas você também pode criar classificadores personalizados. O AWS Glue invoca classificadores personalizados primeiro, na ordem especificada na definição do crawler. Dependendo dos resultados retornados dos classificadores personalizados, o AWS Glue também poderá invocar classificadores integrados. Se um classificador retornar certainty=1.0 durante o processamento, ele indicará que está 100% certo sobre a criação do esquema correto. Em seguida, o AWS Glue usa a saída desse classificador. Se nenhum classificador retornar certainty=1.0, o AWS Glue usará a saída do classificador que tiver a maior certeza. Se nenhum classificador retornar uma certeza maior que 0.0, o AWS Glue retornará a string de classificação padrão UNKNOWN.
Cenário de Exemplo
Para demonstrar um caso prático de uso de classificadores personalizados, vamos utilizar o seguinte formato de arquivo posicional de onde se deseja extrair dados. Nota: os dados abaixo são fictícios.
1LUIZ PAULO ROCHA YANAIM41RUA JOAO DIAS 123 AP89 123400
2FULANO LUIZ SILVA M30RUA XPTO 25 324900
Estrutura de campos:
| ORDEM | CAMPO | TIPO | TAMANHO |
| 1 | ITEM | INTEIRO | 1 |
| 2 | NOME | TEXTO | 22 |
| 3 | SEXO | CARACTER | 1 |
| 4 | IDADE | INTEIRO | 2 |
| 5 | ENDEREÇO | TEXTO | 39 |
| 6 | RENDA | INTEIRO | 6 |
Tabela 1 – Estrutura do arquivo posicional
Neste exemplo específico, todas as linhas possuem a mesma estrutura sem variações. Para cenários deste tipo, o crawler consegue analisar os arquivos do seu data lake e criar os metadados correspondentes no Data Catalog para posterior análise. Seguem os passos para criar um classificador personalizado utilizando a console da AWS. Lembrando que este procedimento pode ser realizado via linha de comando, SDK e APIs do AWS Glue.

- Acessar a página do serviço AWS Glue na console da AWS;
- Na seção de Data Catalog, selecionar o link Classifiers or Classificadores;
- Clicar no botão para Adicionar um novo classificador;
- Dê um nome para seu classificador personalizado.
- Selecione o tipo de classificador como Grok que é indicado para arquivos não estruturados como arquivos de log ou arquivos posicionais.
Grok é um dialeto de expressão regular que suporta expressões com alias reutilizáveis. O Grok funciona muito bem com logs syslog, logs Apache e outros webserver, logs Mysql e, geralmente, qualquer formato de log que seja escrito para humanos e não para consumo de computador. O Grok é construído sobre a biblioteca de expressões regulares Oniguruma, expandindo suas funcionalidades. Então qualquer expressão regular é válida em Grok. O Grok usa essa linguagem de expressão regular para permitir nomear padrões existentes e combiná-los em padrões mais complexos que correspondem aos seus campos.
6. Em Classification, descreva o formato do dados classificados. (p.ex. arquivo posicional).
Obs.: Este nome aparecerá nos metadados das tabelas registradas onde o crawler identificou o formato sendo utilizado.
7. Os dois últimos campos são os mais importantes para definir como seus dados serão lidos. Como mencionado anteriormente, usamos expressões Grok para definir o formato que listamos na tabela 1.
Como o formato do nosso cenário de exemplo é bem peculiar, isto é, não utiliza nenhum padrão já existente de logs, precisamos definir os Grok patterns personalizados que representam cada campo da nossa estrutura. Estes padrões devem ser definidos em linhas diferentes e usando o seguinte formato:
PATTERN <regular-expression>
Por exemplo, para o campo NOME, pode-se utilizar uma expressão regular simples que representa uma lista de 22 caracteres quaisquer em sequência (NOME .{22}).
Obs.: É possível criar uma expressão mais exata ignorando caracteres inválidos como números, mas neste caso deixamos mais simples para mais fácil assimilação.
Depois de definir a expressão regular que expressa cada campo preenchendo a caixa de texto Custom patterns, precisamos definir como os campos estão organizados em cada linha/registro. Para isto usamos o campo Grok patterns concatenando os padrões e usando a seguinte notação:
%{PATTERN:field-name:data-type}
Neste cenário, para o primeiro campo que é um número de ordem sequencial das linhas do arquivo, vamos nomeá-lo de SEQ cujo nome do campo no schema gerado será num e o tipo será int. Ele é seguido pelo campo NOME que aparecerá como customer no schema gerado e será do tipo string. Para os dois primeiros campos, a estrutura seria a seguinte:
%{SEQ:num:int}%{NOME:customer:string}
8. Complementando com os demais campos na estrutura, chegamos ao seguinte resultado para nosso classificador personalizado.
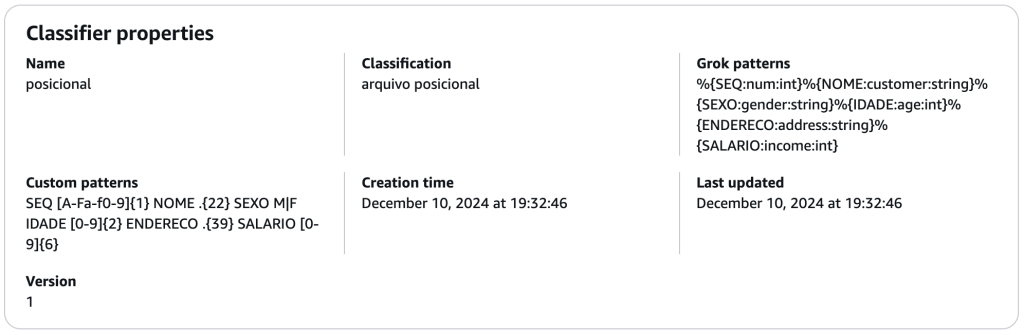
Fig. 1 – Configuração de classificador personalizado para processar arquivo posicional
9. Preenchidos todos os campos conforme figura 1, devemos clicar no botão Create para criar o seu classificador personalizado.
Uma vez que já se tem o classificador definido, podemos utilizá-lo em um crawler para identificar arquivos que seguem este padrão e gerar as respectivas tabelas de metadados no Data Catalog.
O detalhe do passo para configurar o classificador personalizado na criação/edição de um crawler pode ser visto nas referências ao final deste blog post.
Depois de executar o crawler e termos novas tabelas registradas, podemos utilizar diferentes motores de análise de dados na AWS para consumir os dados. Por exemplo, vemos na figura 2 uma consulta SQL feita no Amazon Athena que retorna os dados já “parseados” sem nenhum outra implementação necessária.
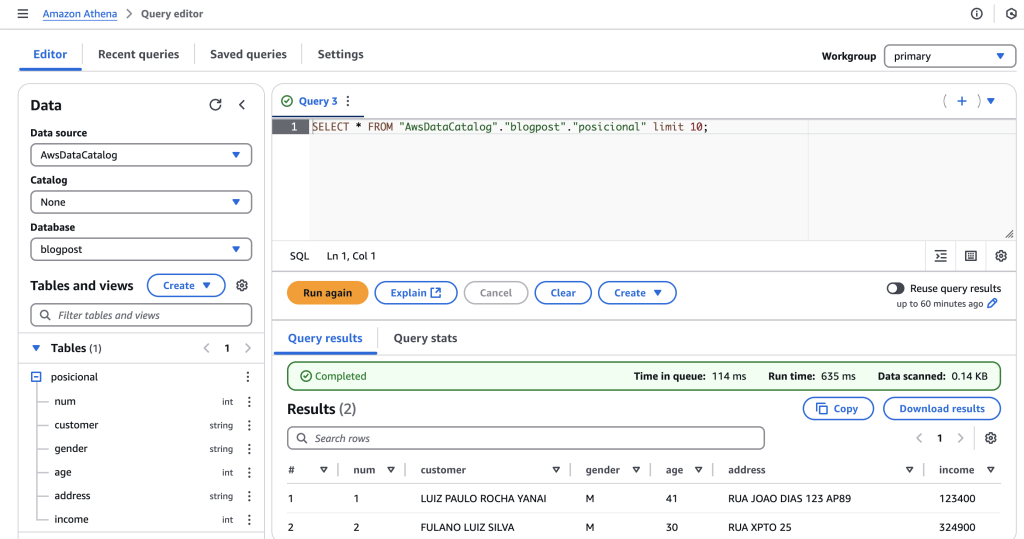
Fig. 2 – Consumindo tabela de cadastrado no AWS Glue diretamente usando o Amazon Athena
O processo que foi apresentado e usa crawlers do AWS Glue, também pode ser feito sem o uso dos crawlers. É possível criar a tabela diretamente no Data Catalog usando o seguinte DDL (Data Definition Language) pelo Athena:
CREATE EXTERNAL TABLE `posicional`(
`num` int,
`customer` string,
`gender` string,
`age` int,
`address` string,
`income` int)
ROW FORMAT SERDE
'com.amazonaws.glue.serde.GrokSerDe'
WITH SERDEPROPERTIES (
'input.format'='%{SEQ:num:int}%{NOME:customer:string}%{SEXO:gender:string}%{IDADE:age:int}%{ENDERECO:address:string}%{SALARIO:income:int}',
'input.grokCustomPatterns'='ENDERECO .{39}\nIDADE [0-9]{2}\nNOME .{22}\nSALARIO [0-9]{6}\nSEQ [A-Fa-f0-9]{1}\nSEXO M|F')
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
's3://blogpost-posicional/datasets/posicional/'Usando um job do AWS Glue DataBrew
A segunda estratégia apresentada neste artigo para processamento de arquivos posicionais é via receitas do AWS Glue DataBrew.
O AWS Glue DataBrew é uma ferramenta de preparação de dados visuais que facilita para analistas e cientistas de dados limpar e normalizar dados com o objetivo de prepará-los para análise bem como para implementar práticas de Machine Learning (ML). Você pode escolher entre mais de 250 transformações pré-criadas para automatizar tarefas de preparação de dados sem precisar escrever código.
Dentre as transformações existentes, podemos usar parte delas para transformar nosso arquivo de entrada em um formato pronto para ser utilizado em análises e extração de insights.
A seguir são apresentados os passos para criar uma receita e parsear o arquivo de exemplo:
- Acessar a página do serviço AWS Glue DataBrew na console da AWS;
- No menu esquerdo, clicar sobre o menu Datasets;
- Criar um novo dataset apontando para o arquivo de exemplo. Para isso, clicar em Connect new dataset;
- Dê um nome para seu dataset e inclua o caminho onde está armazenado no Amazon S3. Em additional configurations, selecione o tipo de arquivo como CSV e marque a opção Add default header na seção Column header values.
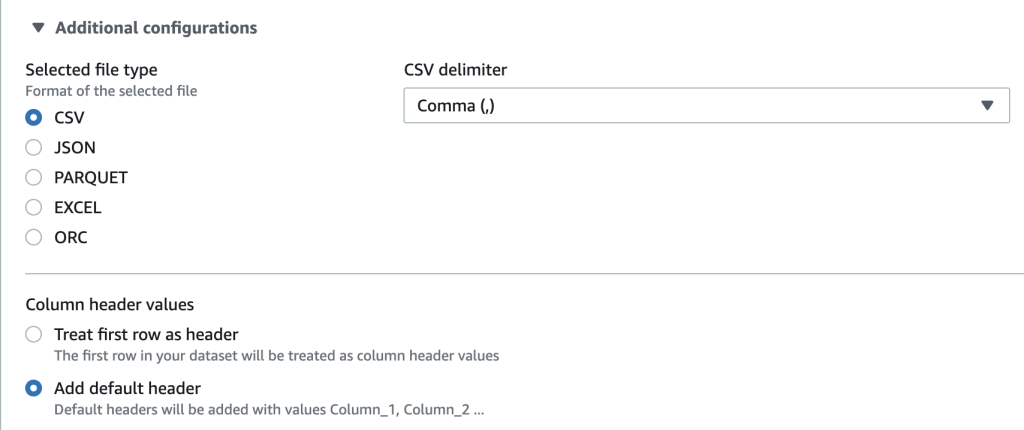
Fig. 3 – Configuração do formato dos arquivos para o dataset a ser transformado
5. Por fim, clicar em Create dataset;
Obs.: A escolha do formato CSV com separação por vírgula foi utilizado para considerar cada linha do arquivo como um único registro/coluna que depois será transformada em múltiplas colunas.
6. Com o dataset definido, deve-se criar um projeto do DataBrew usando o mesmo. Com o dataset selecionado, clicar em Create project with this dataset.
7. Depois de carregada a interface de edição do AWS Glue DataBrew, veremos que o dataset contém somente uma coluna (Column_1) e várias linhas. A partir desta coluna, vamos utilizar a transformação “split column” para dividir esta coluna nas diferentes colunas de compõem o formato.
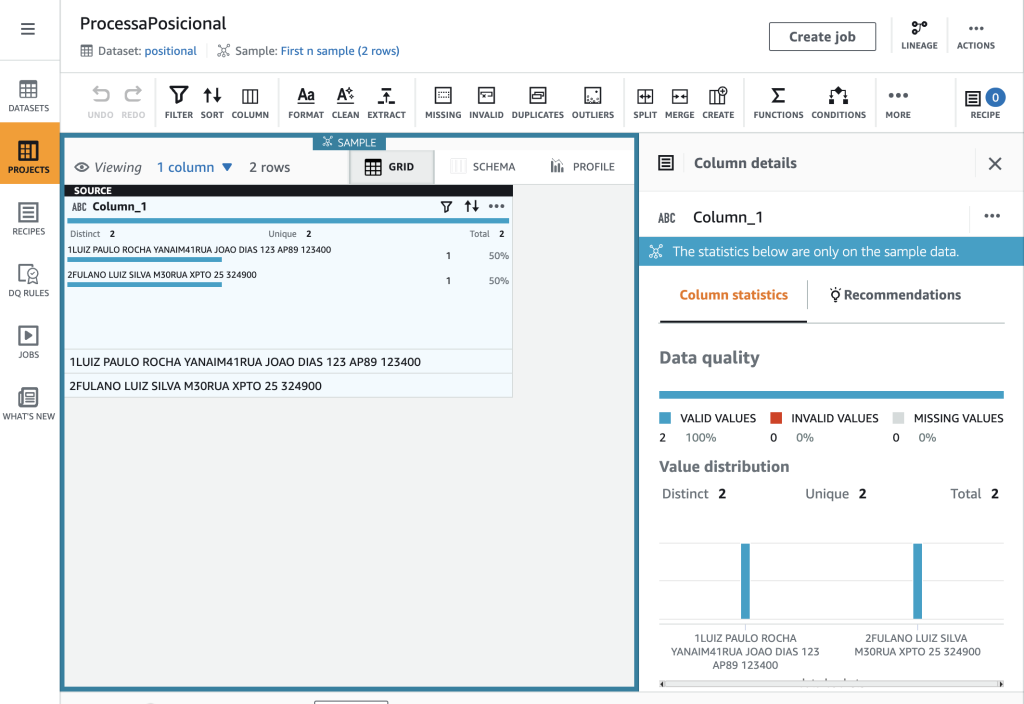
Fig. 4 – Tela do editor do AWS Glue DataBrew
8. Selecionar a coluna Column_1 e clicar na transformação SPLIT na barra de ferramentas. Selecione a opção “Using positions” → “Position from the beginning”. Na parte direita da tela será apresentada a tela de configuração da transformação. No campo de texto position from the beginning, inserir o valor do tamanho da primeira coluna (1). E clicar em Apply.
9. O resultado da transformação será a criação de duas novas colunas (Column_1_1, Column_1_2) e extinção da anterior. A coluna Column_1_1 possui o valor da primeira coluna do nosso cenário e a coluna Column_1_2 possui os restante das colunas ainda não transformadas. Para continuar o processo, basta selecionar a última coluna e repetir o passo anterior somente trocando o valor da variável position from the beginning para o tamanho do próximo campo. Deve-se continuar o processo até que não haja novas colunas a serem divididas.
10. Após a quebra de todas as colunas, basta renomear cada coluna conforme nomenclatura desejada. No Databrew deve-se clicar nos 3 pontinhos a direita do nome da coluna e selecionar a opção Rename. Novamente abre-se um caixa de edição na direita da tela e colocamos o novo nome da coluna na caixa de texto New column name.
11. Repita o passo anterior para renomear todas as colunas do cenário. Ao final teremos uma receita semelhante a listada a seguir.
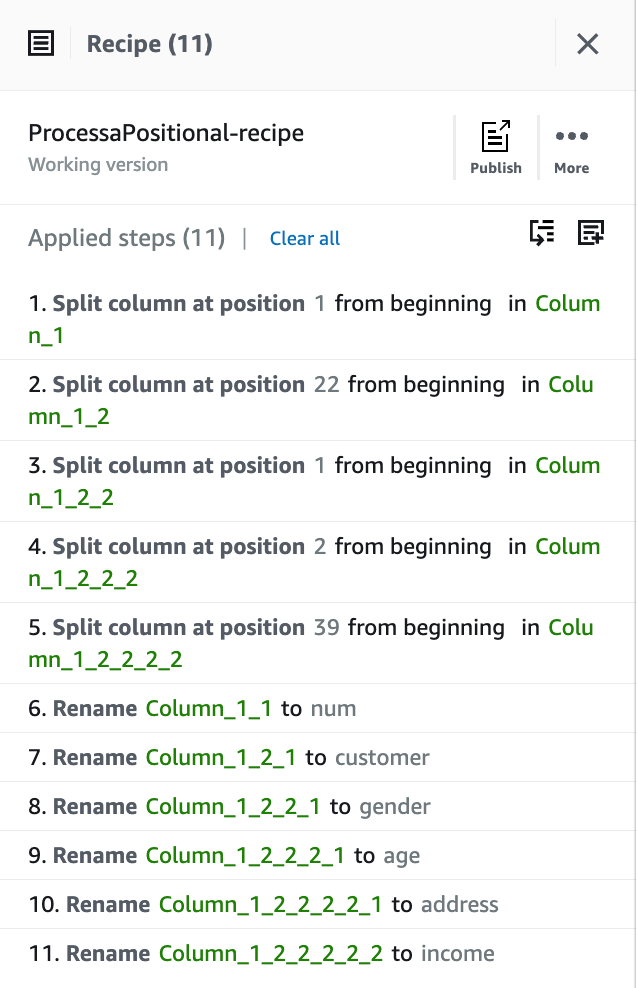
Fig. 5 – Receita do AWS Glue DataBrew com passos de transformação de dados
E o resultado da transformação já com a estrutura no formato desejado fica conforme a figura a seguir:
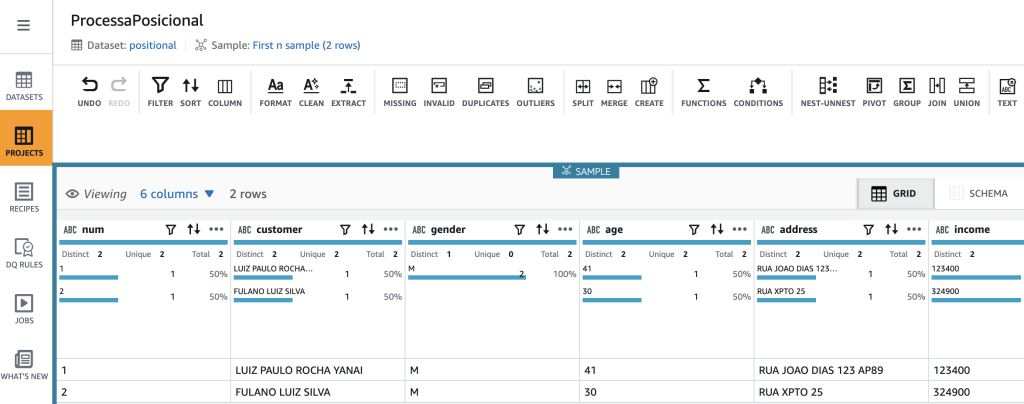
Fig. 6 – Tela do AWS Glue DataBrew com resultado final das transformações aplicados sobre amostra de dados
A receita criada e todas as transformações observadas na interface do AWS Glue DataBrew não foram aplicadas aos dados originais, mas somente a uma amostra dos dados e sem gerar saídas no Amazon S3. Para que os dados sejam transformados é necessário criar um job usando a receita anterior. Com o editor aberto, basta clicar no botão Create job e fornecer os dados necessários para a execução.
Considerações sobre arquivos com múltiplos formatos em diferentes registros
A primeira estratégia utilizando classificadores personalizados do AWS Glue não suporta um cenário mais complexo de formato que é encontrado em saídas de aplicações que geram relatórios com cabeçalhos, detalhes e sumarização em arquivos textos. Contudo, usando o AWS Glue DataBrew que na prática acaba transformando os dados, é possível tratar os diferentes formatos por linha usando lógicas condicionais e de filtragem presentes nas transformações.
CONCLUSÃO
Neste artigo, exploramos como é possível processar eficientemente diversos tipos e formatos de arquivos em seu ambiente de dados em larga escala, facilitando a extração de insights valiosos para o negócio. Demonstramos que não é necessário dominar linguagens de programação complexas ou criar códigos elaborados para analisar documentos e acessar as características essenciais para sua análise. Ferramentas modernas de processamento de dados simplificam esse processo, permitindo que profissionais de diversas áreas possam realizar análises sofisticadas sem a necessidade de habilidades avançadas em programação. Esta abordagem democratiza o acesso aos dados e acelera a tomada de decisões baseadas em evidências nas organizações
Seguem abaixo algumas referências para auxiliar no processamento do seu formato personalizado:
Escrevendo classificadores personalizados
https://docs.aws.amazon.com/glue/latest/dg/custom-classifier.html#custom-classifier-grok
Configurando classificadores personalizados durante a criação do crawler do AWS Glue
https://docs.aws.amazon.com/glue/latest/dg/define-crawler-choose-data-sources.html
Autor
|
|
Luiz Yanai é arquiteto especialista sênior em Data & AI na AWS atuando com clientes nativos na nuvem e empresas do ramo financeiro em suas jornadas para se tornarem data-driven. Possui 20 anos de experiência em arquitetura e desenvolvimento de soluções envolvendo sistemas empresariais e de missão crítica sendo que os últimos 5 anos estão focados na nuvem AWS. |

Revisores
 |
Daniel Abib é Senior Solution Architect na AWS, com mais de 25 anos trabalhando com gerenciamento de projetos, arquiteturas de soluções escaláveis, desenvolvimento de sistemas e CI/CD, microsserviços, arquitetura Serverless & Containers e segurança. Ele trabalha apoiando clientes corporativos, ajudando-os em sua jornada para a nuvem. |
 |
Hugo Chimello é um arquiteto de soluções com mais de 4 anos de experiencia em AWS. Com múltiplas certificações AWS, Hugo utiliza seus 9 anos de experiencia no mercado de tecnologia para atender a maior empresa de telecomunicação da América Latina. |