Amazon Redshift
Используйте SQL для озер данных, чтобы получить высочайшую производительность при масштабировании
Почему именно Amazon Redshift?
Применение Amazon Redshift способствует современной масштабной аналитике данных, что обеспечивает в 3 раза лучшее соотношение цены и производительности и в 7 раз большую пропускную способность по сравнению с другими облачными хранилищами данных. С помощью бессерверного Redshift можно легко масштабировать аналитические рабочие нагрузки без управления инфраструктурой хранилища данных. Благодаря интеграции с нулевым использованием ETL можно обеспечивать аналитику практически в режиме реального времени, легко соединяя данные из потоковых сервисов, операционных баз данных и сторонних корпоративных приложений, без необходимости применения сложных конвейеров данных. Amazon Q в Redshift повышает производительность, упрощая создание SQL посредством естественного языка. Используйте Redshift в качестве структурированной базы знаний в Amazon Bedrock для получения более точных результатов от приложений на основе генеративного искусственного интеллекта. Redshift легко интегрируется с Amazon SageMaker нового поколения, что позволяет использовать мощные аналитические возможности SQL для унифицированных данных в Хранилище в озере данных Amazon SageMaker.
Новый уровень возможностей для следующего поколения Amazon SageMaker
Преимущества
-
Масштабируйте рабочие нагрузки по анализу данных в Redshift и повысьте производительность в 3 раза, а пропускную способность – в 7 раз по сравнению с другими облачными хранилищами данных. Сократите расходы и соблюдайте критически важные для бизнеса соглашения об уровне обслуживания, изолировав рабочие нагрузки с помощью масштабируемых архитектур хранилищ нескольких данных по всей организации. Благодаря комплексным функциям безопасности, таким как изоляция сети, детальные средства управления доступом (например, разрешения на уровне строк и столбцов), вы можете защитить свои данные без дополнительных затрат.
-
Используйте мощные аналитические возможности SQL Redshift для всех унифицированных данных благодаря беспрепятственной интеграции в Хранилище в озере данных Amazon SageMaker. Запрашивайте данные в открытых форматах, хранящихся в Amazon S3, с высокой производительностью, устраняя необходимость перемещения или дублирования данных между озерами и хранилищем данных. Легко включите данные Redshift в Хранилище в озере данных SageMaker, открыв к ним доступ с помощью широкого спектра аналитических движков и инструментов машинного обучения, совместимых с AWS и Apache Iceberg.
-
Ускорьте внедрение инноваций, предоставляя петабайты данных для аналитики без необходимости создавать сложные конвейеры и управлять ими, что обеспечивает доступ к сценариям использования аналитики практически в режиме реального времени. Применяйте интеграцию с нулевым использованием ETL для беспрепятственного переноса транзакционных данных из таких баз данных, как Amazon Aurora, RDS и DynamoDB, в Redshift без снижения производительности. Получайте большие объемы данных в режиме реального времени из Amazon Kinesis и Управляемой потоковой передачи Amazon для Apache Kafka (Amazon MSK) с помощью встроенных интеграций потоковых сервисов. Собрав все данные в одном месте, используйте аналитику, близкую к реальному времени, и напрямую создавайте прогнозные модели машинного обучения в Amazon Redshift для получения эффективной бизнес-аналитики.
-
Начните анализировать данные за несколько секунд с помощью бессерверного Amazon Redshift. Бессерверный Redshift учится на ваших рабочих нагрузках и автоматически масштабирует вычислительные ресурсы в соответствии с растущими потребностями в аналитике, поэтому вы можете сосредоточиться на извлечении ценной информации без управления инфраструктурой. Просто подключитесь к источникам данных и начните анализировать их без необходимости настройки или обслуживания инфраструктуры.
-
Создавайте персонализированные приложения с петабайтами организационных данных благодаря беспрепятственной интеграции Redshift с Amazon Bedrock. Повысьте производительность, предоставив пользователям данных возможность быстрее и легче писать SQL-запросы на естественном языке с помощью генеративного SQL Amazon Q в редакторе запросов Redshift. Используйте большие языковые модели Amazon Bedrock и SageMaker для сложных задач обработки естественного языка, таких как суммирование текста, извлечение сущностей и анализ настроений, чтобы получить более глубокое представление о данных с помощью SQL.
Отчет Gartner за 2025 год о критически важных возможностях облачных систем управления базами данных
AWS входит в число двух поставщиков с наивысшими оценками по всем сценариям использования аналитики.
1 место в категории «Аналитика событий»
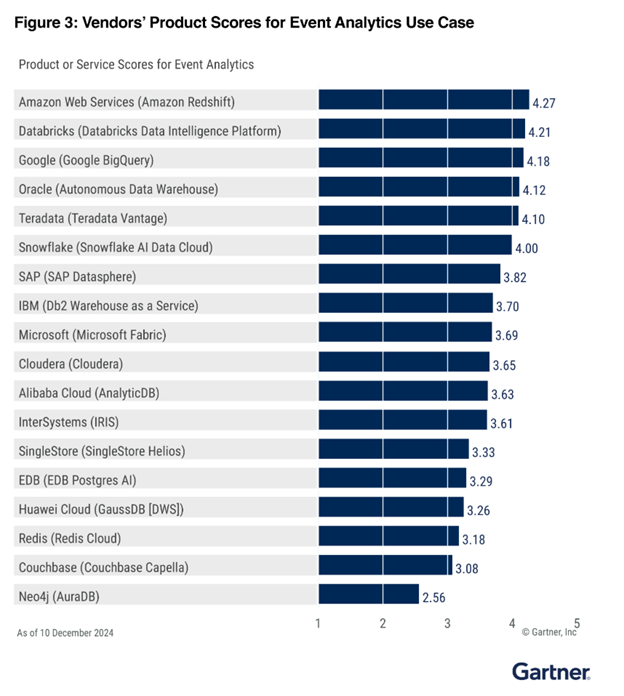
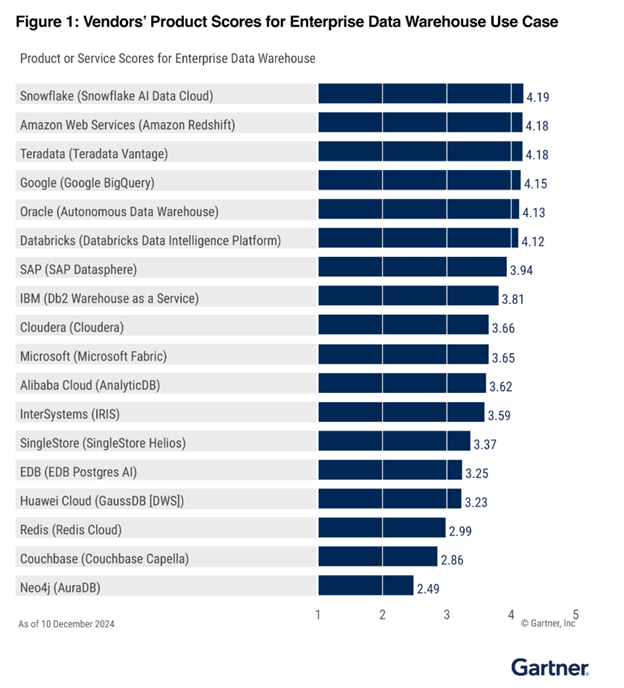
2 место в категории «Корпоративное хранилище данных»
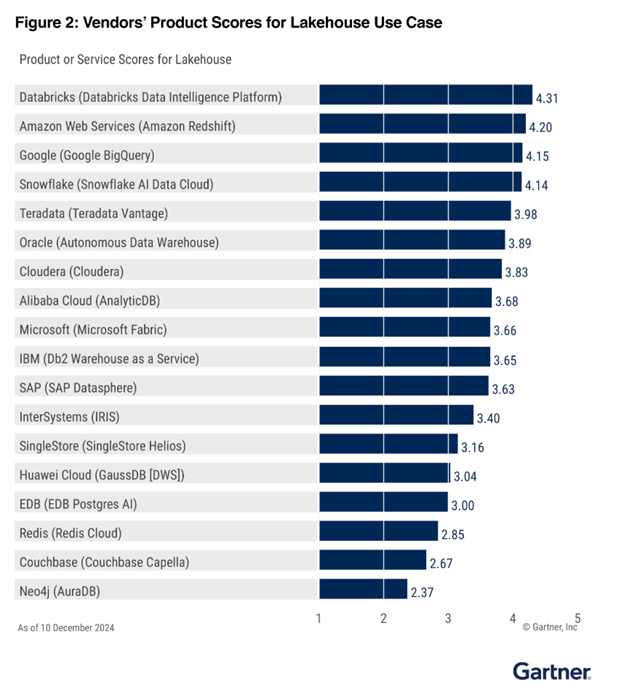
2 место в категории «Хранилище в озере данных»
Отказ от ответственности
GARTNER является зарегистрированной торговой маркой и товарным знаком компании Gartner, Inc. и/или ее филиалов в США и за рубежом и используется в настоящем документе с разрешения. Все права защищены.
Компания Gartner не выступает в поддержку каких-либо поставщиков, продуктов или сервисов, описанных в своих исследовательских публикациях и не рекомендует пользователям технологий выбирать исключительно поставщиков с наивысшим рейтингом или по другим описанным параметрам. В исследовательских публикациях Gartner представлены мнения специалистов исследовательской организации Gartner, и эти мнения не следует принимать как фактические утверждения. Gartner отказывается от любых явных или подразумеваемых гарантий в отношении этого исследования, включая гарантии товарной пригодности или пригодности к использованию в определенных целях. Данная схема была опубликована Gartner, Inc. как часть более обширного документа об исследовании и должна рассматриваться в контексте всего документа. Отчет компании Gartner можно получить в AWS по запросу.
Примеры использования
Сервис способен принимать сотни мегабайтов данных в секунду, что позволяет запрашивать данные практически в реальном времени и создавать аналитические приложения с низкими задержками для обнаружения мошенничества, создания динамических таблиц лидеров и работы с Интернетом вещей.
Создавайте отчеты на основании аналитической информации и панелей управления с помощью Amazon Redshift и инструментов бизнес-аналитики, например Amazon QuickSight, Tableau или Microsoft PowerBI.
Применяйте SQL для создания, обучения и развертывания моделей машинного обучения для разных сценариев использования, таких как прогнозная аналитика, классификация, регрессия и так далее, чтобы организовать расширенную аналитику по большим объемам данных.
Создавайте приложения на основе любых данных, сохраненных в ваших базах данных, хранилищах данных и озерах данных. Легко и безопасно предоставляйте данные для совместного доступа и работы, чтобы создавать дополнительные преимущества для клиентов, монетизировать данные в формате услуги и находить новые источники доходов.
С чем бы вы ни работали: с рыночными данными, аналитикой социальных сетей, погодными данными и т. д., подписывайтесь на сторонние данные в сервисе обмена данными AWS и объединяйте их с данными в Amazon Redshift, не беспокоясь о лицензировании, адаптации и перемещении данных в хранилище.
Бессерверный Amazon Redshift
Легко запускайте и масштабируйте аналитические задачи за считаные секунды, не тратя время на распределение ресурсов хранилища данных и управление ими.
Нашли то, что искали сегодня?
Скажите, как улучшить качество контента на наших страницах