Аналитика в AWS
Полный набор возможностей для любых аналитических рабочих нагрузок, которые оптимизированы по цене, производительности и масштабируемости
Обзор
AWS предлагает полный набор возможностей для любой аналитической рабочей нагрузки. AWS обеспечивает непревзойденное соотношение цены, производительности и масштабируемости благодаря встроенному управлению – от обработки данных и аналитики SQL до потоковой передачи, поиска и бизнес-аналитики. Выбирайте специализированные сервисы, оптимизированные для конкретных рабочих нагрузок, или рационализируйте рабочие процессы обработки данных и искусственного интеллекта и управляйте ими с помощью Amazon SageMaker. Независимо от того, начинаете ли вы работу с данными или ищете интегрированный интерфейс, AWS предоставляет вам необходимые аналитические возможности, которые помогут переосмыслить бизнес с помощью данных.
Обеспечьте ощутимые бизнес-результаты с помощью аналитики на AWS
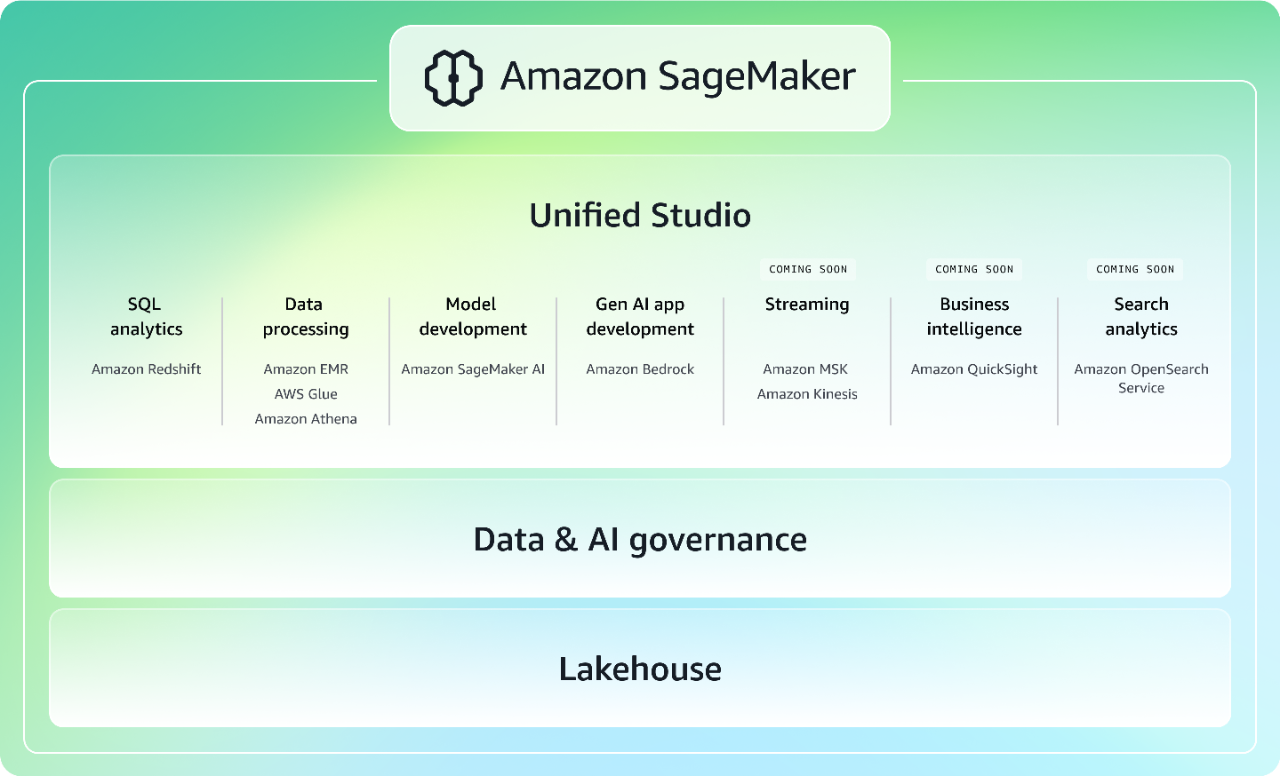
Ускорьте обработку данных, получение аналитической информации и работу с ИИ за счет интегрированного интерфейса
Amazon SageMaker нового поколения объединяет широко используемые возможности машинного обучения и аналитики AWS, а также предоставляет интегрированный опыт аналитики и искусственного интеллекта с унифицированным доступом ко всем вашим данным. Сотрудничайте и разрабатывайте решения быстрее в единой студии, используя привычные инструменты AWS для разработки моделей, приложений на базе генеративного искусственного интеллекта, обработки данных и SQL-аналитики. Данные инструменты ускорены Amazon Q для разработчиков, что самым мощным ассистентом на базе генеративного искусственного интеллекта для разработки программного обеспечения. Получайте доступ ко всем своим данным, независимо от того, хранятся ли они в озерах данных, хранилищах данных, сторонних либо федеративных источниках данных, благодаря встроенным средствам управления, отвечающим требованиям корпоративной безопасности. Подробнее о SageMaker.
Внедрение мультиоблачных стратегий с помощью AWS
AWS предоставляет полный набор мощных аналитических сервисов, обеспечивающих беспрепятственный доступ к данным и их обработку в мультиоблачных и гибридных средах. Такой гибкости можно достичь за счет федеративных запросов, интеграции данных, безопасного перемещения данных и совместимости с открытыми стандартами, что позволяет получать ценную аналитическую информацию на основе всех своих данных независимо от их местонахождения.
Amazon Athena позволяет запрашивать и анализировать данные, хранящиеся в различных внешних источниках данных, включая Azure Data Lake Storage, Google Cloud Storage, Microsoft SQL Server и многие другие, без необходимости копировать или преобразовывать данные.
AWS Glue упрощает обнаружение, подготовку и интеграцию всех данных в любом масштабе с помощью соединителей для более 100 различных источников данных, включая облачное хранилище, базы данных и аналитические сервисы. Интеграция Glue с нулевым использованием ETL упрощает прием и репликацию данных из сторонних приложений, таких как Salesforce, SAP, Facebook Ads и Instagram Ads, непосредственно в хранилища в озерах данных, озера данных и хранилища данных AWS. AWS Glue также обеспечивает совместимость данных благодаря поддержке открытых стандартов, таких как Apache Hive, Apache Parquet и Apache Iceberg.
Новое поколение Amazon SageMaker разработано на базе архитектуры открытых данных, обеспечивающей унифицированный доступ к озерам данных и хранилищам данных на AWS, а также к федеративным источникам данных, таким как Google BigQuery и Snowflake. Эта архитектура Lakehouse полностью совместима с Apache Iceberg, что обеспечивает гибкий доступ к данным и запросы к ним на месте с помощью любых инструментов и движков, совместимых с Iceberg.
Использование аналитики для людей и искусственного интеллекта
Используйте масштабируемую аналитику с помощью специализированных сервисов для хранения, запросов, потоковой передачи, обработки и управления данными. От форматов открытых таблиц (OTF) до агентской инфраструктуры – AWS развивает аналитические движки и приложения для быстро меняющейся сферы аналитики. На этом семинаре вы узнаете, как AWS предоставляет оптимизированные решения, созданные как для обычных пользователей, так и для рабочих процессов агентов.

Сервисы
|
Категория «Аналитика»
|
Описание
|
Сервис AWS и его возможности
|
|---|---|---|
|
Потоковая передача
|
Создавайте, масштабируйте и используйте конвейеры данных и приложения в режиме реального времени без необходимости управлять инфраструктурой. |
|
|
Хранилище в озере данных, хранилище данных, озеро данных
|
Получайте доступ ко всем своим данным и анализируйте их в хранилищах озер данных, хранилищах данных и озерах данных. |
|
|
Обработка данных
|
Анализируйте, готовьте и интегрируйте данные для аналитики и искусственного интеллекта с помощью фреймворков с открытым исходным кодом. |
|
|
Бизнес‑аналитика
|
Создавайте и обнаруживайте ценную аналитическую информацию, а также делитесь ею с помощью современных интерактивных информационных панелей, отчетов с идеально точной разбивкой, запросов на естественном языке и встроенной аналитики. |
|
|
Поисковая аналитика
|
Обеспечьте безопасный поиск, мониторинг и анализ бизнес- и операционных данных в режиме реального времени. |
|
|
Управление данными и искусственным интеллектом
|
Каталогизируйте, обнаруживайте, делитесь данными, которые хранятся в AWS, локальных и сторонних источниках, а также управляйте ими. |
Общий экономический эффект современной стратегии применения данных AWS
По сведениям Forrester, благодаря современной стратегии применения данных на основе Amazon Web Services можно сократить расходы и получить дополнительные преимущества для бизнеса.
Статистика
Нашли то, что искали сегодня?
Скажите, как улучшить качество контента на наших страницах