AWS Cloud Financial Management
Improve cost visibility of Amazon EKS with AWS Split Cost Allocation Data
We’re excited to announce granular cost visibility for Amazon Elastic Kubernetes Service (Amazon EKS) in the AWS Cost and Usage Reports (CUR), enabling you to analyze, optimize, and chargeback cost and usage for your Kubernetes applications. With AWS Split Cost Allocation Data for Amazon EKS, customers can now allocate application costs to individual business units and teams based on how Kubernetes applications consume shared EC2 CPU and memory resources. Split Cost Allocation Data for Amazon EKS is available to customers in all AWS commercial regions, excluding China regions, with no additional cost.
The challenges of monitoring and allocating container costs
Kubernetes helps customers automate the management, scaling, and deployment of containerized applications. With Amazon EKS, customers get a managed service that eliminates the need to install, operate, and maintain their own Kubernetes control plane on AWS. However, getting fine grained visibility into Kubernetes costs is not easy. This is because traditional FinOps cost allocation (e.g. mapping costs of resources back to teams or projects) doesn’t work. You can’t simply allocate the cost of a resource, such as EC2 instance to a tag or label, because the EC2 instance may be running multiple containers, with each supporting a different application. The resources also may be attached to different cost centers around the organization. Customers have requested for finer-grained visibility into the cost allocation of applications running on Amazon EKS that share AWS resources like Amazon EC2 instances. Nearly half (49%) of those surveyed in CNCF’s latest microsurvey report on Cloud Native and Kubernetes FinOps saw an increase in cloud spend driven by Kubernetes usage. The report also identified a gap in the level of cost monitoring customers have in place with 40% respondents said they estimated their Kubernetes costs and there was no monitoring in place for 38%. Additionally, the report also identified a gap in the level of cost monitoring customers have in place with only 19% doing accurate showback and 2% for chargeback, and 38% with no monitoring mechanisms in place at all
While customers can track their Kubernetes control plane and EC2 costs using AWS Cost and Usage Reports, they need deeper insights to accurately track Kubernetes resource level costs by namespace, cluster, pod, or organizational entities such as by team or application. For example, to determine the resources used by a specific group of pods, customers previously invested in complex solutions to understand pod level usage and integrate that with the EC2 cost data from AWS Cost and Usage Reports. Containers are also often short-lived and scale at various levels, so the resource usage fluctuates over time, further adding complexity to this equation. Amazon EKS is commonly used in dynamic and/or multi-tenant environments, which require purpose-built features for accurate cost monitoring.
Get granular cost visibility for EKS with Split Cost Allocation Data
With Split Cost Allocation Data, you can now easily distribute your Amazon EC2 instance costs at the Kubernetes pod level, based on the actual consumption of the CPU and memory utilized by your Kubernetes pods. The granular cost information at the container level lets you analyze the cost efficiency of your containerized applications and simplifies the chargeback process to your business entities.
After Split Cost Allocation Data is enabled, it will scan for all of your Kubernetes pods in Amazon EKS clusters across your Consolidated Billing family and ingest Kubernetes attributes such as namespace, node, cluster as well as CPU and memory requests for the pods. Alternatively, split cost allocation data will also read your Amazon Managed Service for Prometheus workspaces to bring in Kubernetes CPU and memory utilization metrics. Then it would compute Kubernetes pod-level cost metrics, e.g., split cost, unused cost, actual usage, and reserved usage (i.e. resource requests), including net cost metrics after discounts and make this available in your AWS Cost and Usage Report.
Split cost allocation data will create new cost allocation tags for some Kubernetes attributes. These tags include aws:eks:cluster-name, aws:eks:namespace, aws:eks:node, aws:eks:workload-type, aws:eks:workload-name and aws:eks:deployment. For more details on these tags, visit Understanding split cost allocation data.
Get started with Split cost allocation data
To enable “Split cost allocation data”, you need to complete a simple two-step opt-in process.
Step 1: First, as a payer account owner, you need to opt-in “Split cost allocation data” from your AWS Billing and Cost Management/AWS Cost Management preference page. Here you select Amazon Elastic Kubernetes Service. You have two additional options.
- Resource requests: supports allocating your EC2 costs by Kubernetes pod CPU and memory resource requests only. Allocating costs by resource requests incentivizes application teams to only provision what they need
- Amazon Managed Service for Prometheus: supports allocating your EC2 costs by the higher of Kubernetes pod CPU and memory resource requests and actual utilization. This ensures each application team pays for what they use. See the next section on how to setup a Amazon Managed Service for Prometheus workspace.

Figure 1. Split cost allocation data in Cost Management preferences
Step 2: Then you will enable “Split cost allocation data” for a new or existing CUR report from the Cost and Usage Reporting preference page in the AWS Billing and Cost Management console. Alternatively you can enable ‘Split cost allocation data’ for a new or existing CUR 2.0 report in the Data Exports page in the AWS Billing and Cost Management console. We recommend including resource IDs and setting an hourly report to get the most granular data.
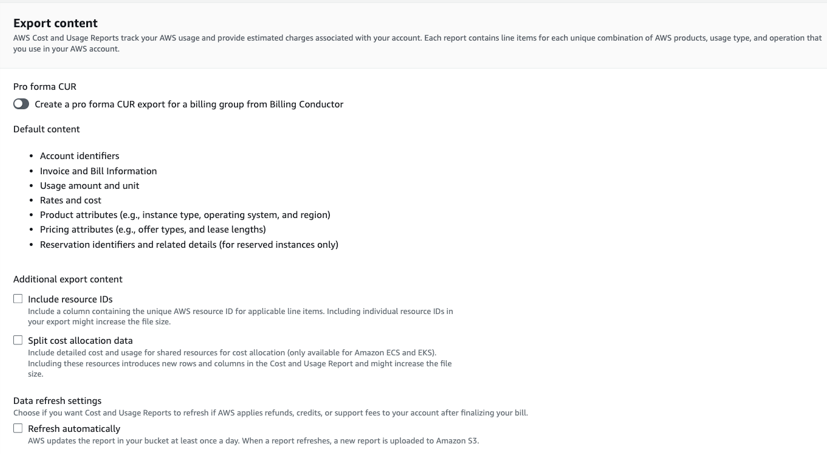
Figure 2. Split cost allocation data in Data Exports legacy CUR export
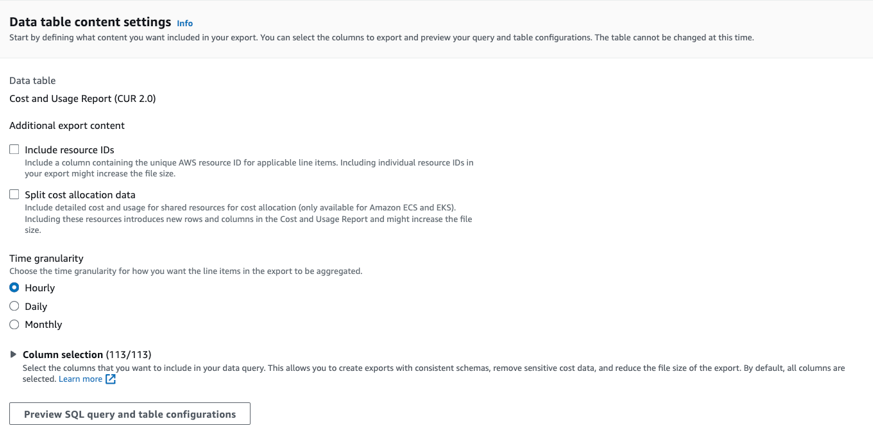
Figure 3. Split cost allocation data in Data Exports standard CUR export
For more details on the opt in process visit Enabling split cost allocation data
Once enabled, the report will automatically scan for Kubernetes pods for the entire Consolidated Billing family (all clusters belonging to member accounts across all regions) and start preparing the granular cost data for the current month. In 24 hours, your CUR report will be ready with the new EKS cost and usage metrics.
Setup Amazon Managed Service for Prometheus
Split cost allocation data for Amazon EKS requires the setup of an observability metrics store to allocate costs based on actual utilization of memory and CPU. To learn more how to setup a Amazon Managed Service for Prometheus workspace click here. There are two ways you can forward EKS telemetry to Amazon Managed Service for Prometheus to be ingested by Split cost allocation data.
- Set up a Prometheus server on the EKS cluster with remote write to the Amazon Managed Service for Prometheus workspace
- Use a managed Amazon Managed Service for Prometheus collector
For more details, please read documentation Using split cost allocation data with Amazon Managed Service for Prometheus
How it works
To help you understand how the cost model works, we’ll start by explaining a few key terms and calculation logic. Split cost allocation data for EKS collects the requested and actual usage data of compute and memory resources for each EC2 instance associated with an EKS cluster. Actual usage data is only collected if you opted in to Amazon Managed Service for Prometheus. If you opted in to Resource request only option, then actual usage is considered to be 0. It then calculates the allocated CPU and memory data for each Kubernetes pod based on the greater value between the requested amount and the used amount.
Since multiple Kubernetes pods can run on a single EC2 instance, split cost allocation data for EKS computes the allocated CPU and memory for all pods on the instance. It then computes a split-usage-ratio, which is the percentage of CPU or memory allocated to each Kubernetes pods compared to the overall CPU or memory available on the EC2 instance. It also identifies the unused capacity left on the instance.
When sharing the cost of the EC2 instance among all the Kubernetes pods, Split cost allocation data totals the split cost and then proportionally redistributes the unused cost according to instance utilization by pod.
Lets take an example and see how it works in practice.
Example: EC2 cost allocation across multiple Kubernetes pods
Now, let’s plug in some numbers and show how the cost of an EC2 instance is allocated across multiple Kubernetes pods running on that instance.
Below you can see an EKS cluster run on a single node of m7g.2xlarge EC2 instance with 8 vCPU and 32GB RAM. The cluster is operating 4 Kubernetes pods across 2 namespaces within a single Amazon EKS cluster. We will use the on-demand pricing for m7g.2xlarge for demonstration purposes, but note that split cost allocation data will use the amortized costs of the EC2 instance (which includes upfront and partial upfront charges if there was a Savings Plan or Reserved Instance in place on the EC2 instance). Split cost allocation data uses relative unit weights for CPU and memory based on a 9:1 ratio. This is derived from average relative price of vCPU to memory based on AWS Fargate pricing. Using these weights, it computes the cost per vCPU-Hour and cost per GB-Hour as $0.029 and $0.003, respectively.

Figure 4. Sample cost per CPU-hour and GB-hour
The vCPU and memory request and actual usage across the 4 Kubernetes pods are listed in the table below. Pod 2 used more CPU and memory than what was requested because it didn’t configure a limit. As mentioned earlier, Split Cost Allocation Data computes allocated vCPU and memory based on the greater value between the requested and actual usage. In this example, we don’t have any unused vCPU, but there is 2GB of unallocated memory.
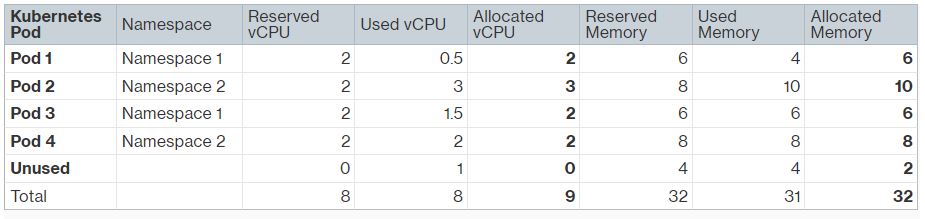
Figure 5. Sample Reserved, used, and allocated CPU and memory
Split Cost Allocation Data computes a split-usage ratio as the percentage of CPU or memory allocated by the Kubernetes pods compared to the overall CPU or memory available on the EC2 instance. It also computes an unused ratio as the percentage of CPU or memory allocated by the Kubernetes pods compared to the overall CPU or memory allocated on the EC2 instance (that is, not factoring in the unallocated CPU or memory on the instance). For instance, there is 2GB of unallocated memory on the instance, which is 2/32 = 0.063 of the total instance memory. Pod1 has allocated 6GB, which is 6/32 = 0.188 of the total instance memory. Therefore, the total unused memory ratio for Pod 1 is 0.188 / (1-0.063) = 0.200.
The pod-level split costs are calculated based on split-usage ratios multiplied by the cost per vCPU-Hour and cost per GB-Hour. If there is unused resource, in this case unused memory capacity of 2GB, the unused instance cost ($0.006) is proportionally distributed to each pod based on the unused ratio computed for each pod. The total allocated cost for each pod will be the total of the split cost and proportionally redistributed unused cost. Once the EC2 cost is available at the pod level, you can calculate the aggregate namespace-level costs. In this example, the total allocated cost for Namespace 1 and Namespace 2 are $0.142 and $0.188, respectively. You can also aggregate the costs using Cost Categories or the new EKS cost allocation tags that were added to the Kubernetes pods, allowing you to compute the cost by your desired business entity level.
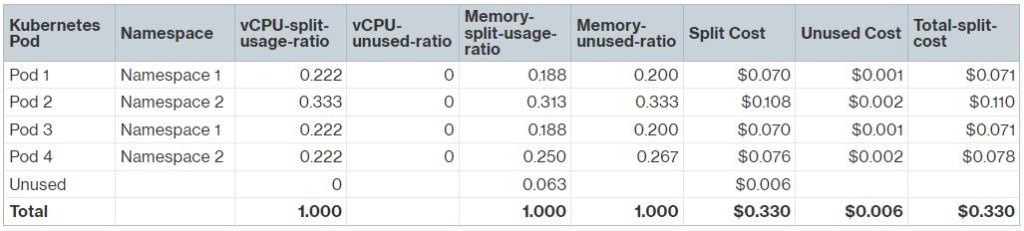
Figure 6. Sample calculation of split cost
What are the new Cost and Usage Report columns?
As Split cost allocation data computes Kubernetes pod-level metrics, you will see the new columns in your CUR reports. For instance, “SplitLineItem/SplitUsage” is the usage for CPU or memory allocated for the specified time period to the Kubernetes pod. You can view CUR data dictionary for a complete list of the new CUR columns and their definitions.
To wrap up with our example, below is a demo CUR report. You can see how data will be displayed in the new CUR columns.
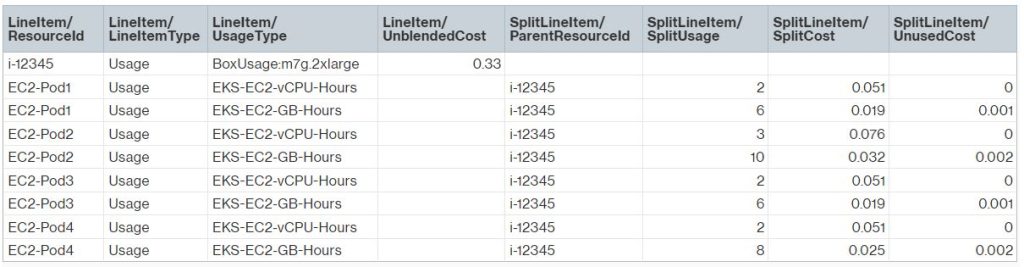
Figure 7. Sample Cost and Usage Report columns
You can also use the Containers Cost Allocation dashboard to query and visualize your EKS costs in Amazon QuickSight and CUR query library to query your EKS costs using Amazon Athena.
Conclusion
The visibility of EKS cost data provides insights to improve efficiency and cost optimization. Enable this granular level of cost data today and learn more about this capability.