AWS Compute Blog
Deploying a Burstable and Event-driven HPC Cluster on AWS Using SLURM, Part 2
Contributed by Amr Ragab, HPC Application Consultant, AWS Professional Services
In part 1 of this series, you deployed the base components to create the HPC cluster. This unique deployment stands up the SLURM headnode. For every job submitted to the queue, the headnode provisions the needed compute resources to run the job, based on job submission parameters.
By provisioning the compute nodes dynamically, you can immediately see the benefit of elasticity, scale, and optimized operational compute costs. As new technologies are released, you can take advantage of heterogeneous deployments, such as scaling high, tightly coupled, CPU-bound workloads independently from high memory or distributed GPU-based workloads.
To further extend a cloud-native approach to designing HPC architectures, you can integrate with existing AWS services and provide additional benefits by abstracting the underlying compute resources. It is possible for the HPC cluster to be event-driven in response to requests from a web application or from direct API calls.
Additional frontend components can be added to take advantage of an API-instantiated execution of an HPC workload. The following reference architecture describes the pattern.

The difference from the previous reference architecture in Part 1 is that the user submits the job described as JSON through an HTTP call to Amazon API Gateway, which is then processed by an AWS Lambda function to submit the job.
Deployment
I recommend that you start this section after completing the deployment in Part I . Write down the private IP address of the SLURM controller.
In the Amazon EC2 console, select the SLURM headnode and retrieve the private IPv4 address. In the Lambda console, create a new function based on Python 2.7 authored from scratch.

Under the environment variables, add a new entry for “HEADNODE”, “SLURM_BUCKET_S3”, “SLURM_KEY_S3” and set the value to the private IPv4 address of the SLURM controller noted earlier, plus the bucket and key pair. This allows the Lambda function to connect to the instance using SSH.
In the AWS GitHub repo that you cloned in part 1, find the lambda/hpc_worker.zip file and upload the contents to the Function Code section of the Lambda function. A derivative of this function was referenced by Puneet Agarwal, in the Scheduling SSH jobs using AWS Lambda post.

The Lambda function needs to launch in the VPC as the SLURM node and have the same security groups as the SLURM headnode. This is because the Lambda function connects to the SLURM controller using SSH. Ignore the error about creating the Lambda function across two Availability Zones for high availability (HA).
The default memory settings, with a timeout of 20 seconds, are sufficient. The Lambda execution role needs access to Amazon EC2, Amazon CloudWatch, and Amazon S3.
In the API Gateway console, create a new API from scratch and name it “hpc.” Under Resources, create a new resource as “hpc.” Then, create a new method under the “hpc” resource for POST.
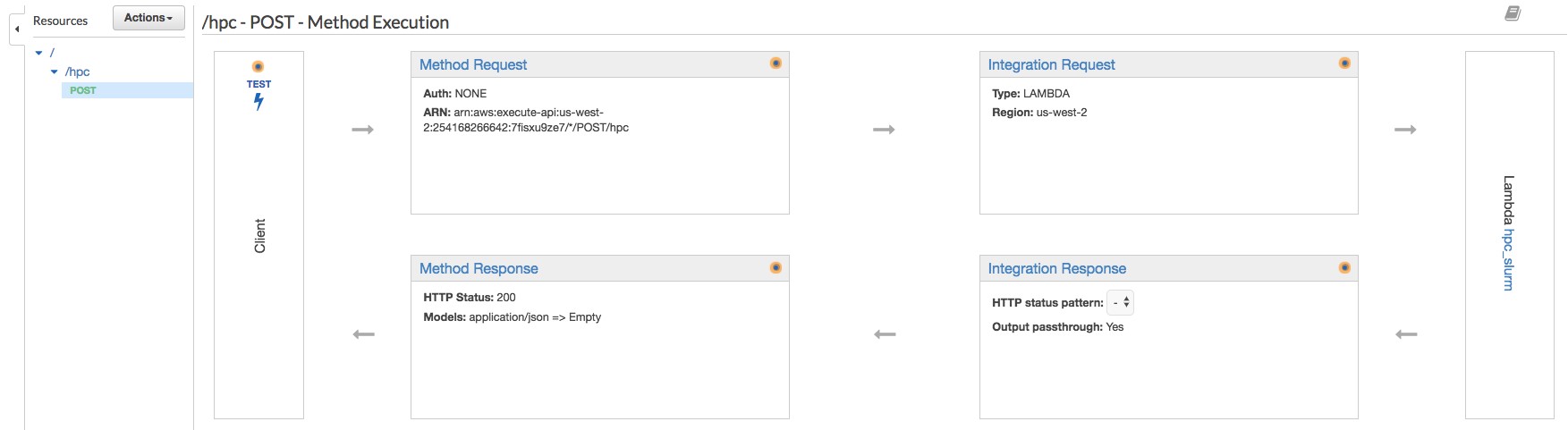
Under the POST method, set the integration method to the Lambda function created earlier.
Under the resource “hpc”, choose to deploy the API for staging, calling the endpoint “dev.” You get an endpoint to execute:
Then, create a JSON file with the following code.
Next, in the API Gateway console, watch the following four events happen:
- The API gateway passes the input JSON to the Lambda function.
- The Lambda function writes out a SLURM sbatch job submission file.
- The job is executed and held until the instance is provisioned
- After the instance is running, the job script executes, copies data from S3, and completes the job.
In the response body of the API call, you return the job ID.
When the job completes, the instance is held for 60 seconds in case another job is submitted. If no jobs are submitted, the instance is terminated by the SLURM cluster.
Conclusion
End-to-end scalable job submission and instance provisioning is one way to execute your HPC workloads in a scalable and elastic fashion. Now, go power your HPC workloads on AWS!