AWS Compute Blog
Implementing Default Directory Indexes in Amazon S3-backed Amazon CloudFront Origins Using Lambda@Edge
With the recent launch of Lambda@Edge, it’s now possible for you to provide even more robust functionality to your static websites. Amazon CloudFront is a content distribution network service. In this post, I show how you can use Lambda@Edge along with the CloudFront origin access identity (OAI) for Amazon S3 and still provide simple URLs (such as www.example.com/about/ instead of www.example.com/about/index.html).
Background
Amazon S3 is a great platform for hosting a static website. You don’t need to worry about managing servers or underlying infrastructure—you just publish your static to content to an S3 bucket. S3 provides a DNS name such as <bucket-name>.s3-website-<AWS-region>.amazonaws.com. Use this name for your website by creating a CNAME record in your domain’s DNS environment (or Amazon Route 53) as follows:
www.example.com -> <bucket-name>.s3-website-<AWS-region>.amazonaws.com
You can also put CloudFront in front of S3 to further scale the performance of your site and cache the content closer to your users. CloudFront can enable HTTPS-hosted sites, by either using a custom Secure Sockets Layer (SSL) certificate or a managed certificate from AWS Certificate Manager. In addition, CloudFront also offers integration with AWS WAF, a web application firewall. As you can see, it’s possible to achieve some robust functionality by using S3, CloudFront, and other managed services and not have to worry about maintaining underlying infrastructure.
One of the key concerns that you might have when implementing any type of WAF or CDN is that you want to force your users to go through the CDN. If you implement CloudFront in front of S3, you can achieve this by using an OAI. However, in order to do this, you cannot use the HTTP endpoint that is exposed by S3’s static website hosting feature. Instead, CloudFront must use the S3 REST endpoint to fetch content from your origin so that the request can be authenticated using the OAI. This presents some challenges in that the REST endpoint does not support redirection to a default index page.
CloudFront does allow you to specify a default root object (index.html), but it only works on the root of the website (such as http://www.example.com > http://www.example.com/index.html). It does not work on any subdirectory (such as http://www.example.com/about/). If you were to attempt to request this URL through CloudFront, CloudFront would do a S3 GetObject API call against a key that does not exist.
Of course, it is a bad user experience to expect users to always type index.html at the end of every URL (or even know that it should be there). Until now, there has not been an easy way to provide these simpler URLs (equivalent to the DirectoryIndex Directive in an Apache Web Server configuration) to users through CloudFront. Not if you still want to be able to restrict access to the S3 origin using an OAI. However, with the release of Lambda@Edge, you can use a JavaScript function running on the CloudFront edge nodes to look for these patterns and request the appropriate object key from the S3 origin.
Solution
In this example, you use the compute power at the CloudFront edge to inspect the request as it’s coming in from the client. Then re-write the request so that CloudFront requests a default index object (index.html in this case) for any request URI that ends in ‘/’.
When a request is made against a web server, the client specifies the object to obtain in the request. You can use this URI and apply a regular expression to it so that these URIs get resolved to a default index object before CloudFront requests the object from the origin. Use the following code:
'use strict';
exports.handler = (event, context, callback) => {
// Extract the request from the CloudFront event that is sent to Lambda@Edge
var request = event.Records[0].cf.request;
// Extract the URI from the request
var olduri = request.uri;
// Match any '/' that occurs at the end of a URI. Replace it with a default index
var newuri = olduri.replace(/\/$/, '\/index.html');
// Log the URI as received by CloudFront and the new URI to be used to fetch from origin
console.log("Old URI: " + olduri);
console.log("New URI: " + newuri);
// Replace the received URI with the URI that includes the index page
request.uri = newuri;
// Return to CloudFront
return callback(null, request);
};
To get started, create an S3 bucket to be the origin for CloudFront:
On the other screens, you can just accept the defaults for the purposes of this walkthrough. If this were a production implementation, I would recommend enabling bucket logging and specifying an existing S3 bucket as the destination for access logs. These logs can be useful if you need to troubleshoot issues with your S3 access.
Now, put some content into your S3 bucket. For this walkthrough, create two simple webpages to demonstrate the functionality: A page that resides at the website root, and another that is in a subdirectory.
<s3bucketname>/index.html
<!doctype html>
<html>
<head>
<meta charset="utf-8">
<title>Root home page</title>
</head>
<body>
<p>Hello, this page resides in the root directory.</p>
</body>
</html>
<s3bucketname>/subdirectory/index.html
<!doctype html>
<html>
<head>
<meta charset="utf-8">
<title>Subdirectory home page</title>
</head>
<body>
<p>Hello, this page resides in the /subdirectory/ directory.</p>
</body>
</html>
When uploading the files into S3, you can accept the defaults. You add a bucket policy as part of the CloudFront distribution creation that allows CloudFront to access the S3 origin. You should now have an S3 bucket that looks like the following:

Root of bucket

Subdirectory in bucket
Next, create a CloudFront distribution that your users will use to access the content. Open the CloudFront console, and choose Create Distribution. For Select a delivery method for your content, under Web, choose Get Started.
On the next screen, you set up the distribution. Below are the options to configure:
- Origin Domain Name: Select the S3 bucket that you created earlier.
- Restrict Bucket Access: Choose Yes.
- Origin Access Identity: Create a new identity.
- Grant Read Permissions on Bucket: Choose Yes, Update Bucket Policy.
- Object Caching: Choose Customize (I am changing the behavior to avoid having CloudFront cache objects, as this could affect your ability to troubleshoot while implementing the Lambda code).
- Minimum TTL: 0
- Maximum TTL: 0
- Default TTL: 0
You can accept all of the other defaults. Again, this is a proof-of-concept exercise. After you are comfortable that the CloudFront distribution is working properly with the origin and Lambda code, you can re-visit the preceding values and make changes before implementing it in production.
CloudFront distributions can take several minutes to deploy (because the changes have to propagate out to all of the edge locations). After that’s done, test the functionality of the S3-backed static website. Looking at the distribution, you can see that CloudFront assigns a domain name:

Try to access the website using a combination of various URLs:
http://<domainname>/: Works
This is because CloudFront is configured to request a default root object (index.html) from the origin.
http://<domainname>/subdirectory/: Doesn’t work
If you use a tool such like cURL to test this, you notice that CloudFront and S3 are returning a blank response. The reason for this is that the subdirectory does exist, but it does not resolve to an S3 object. Keep in mind that S3 is an object store, so there are no real directories. User interfaces such as the S3 console present a hierarchical view of a bucket with folders based on the presence of forward slashes, but behind the scenes the bucket is just a collection of keys that represent stored objects.
http://<domainname>/subdirectory/index.html: Works
This request works as expected because you are referencing the object directly. Now, you implement the Lambda@Edge function to return the default index.html page for any subdirectory. Looking at the example JavaScript code, here’s where the magic happens:
var newuri = olduri.replace(/\/$/, '\/index.html');
You are going to use a JavaScript regular expression to match any ‘/’ that occurs at the end of the URI and replace it with ‘/index.html’. This is the equivalent to what S3 does on its own with static website hosting. However, as I mentioned earlier, you can’t rely on this if you want to use a policy on the bucket to restrict it so that users must access the bucket through CloudFront. That way, all requests to the S3 bucket must be authenticated using the S3 REST API. Because of this, you implement a Lambda@Edge function that takes any client request ending in ‘/’ and append a default ‘index.html’ to the request before requesting the object from the origin.
In the Lambda console, choose Create function. On the next screen, skip the blueprint selection and choose Author from scratch, as you’ll use the sample code provided.
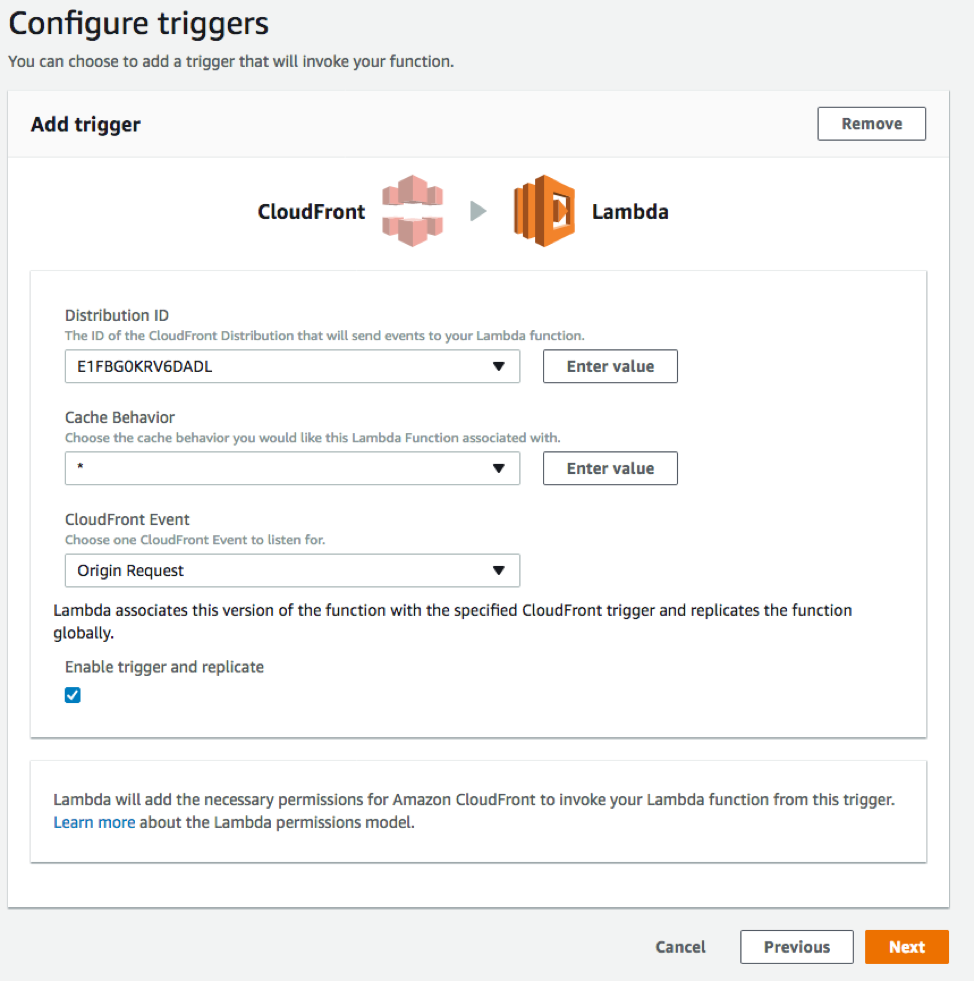
Next, configure the trigger. Choosing the empty box shows a list of available triggers. Choose CloudFront and select your CloudFront distribution ID (created earlier). For this example, leave Cache Behavior as * and CloudFront Event as Origin Request. Select the Enable trigger and replicate box and choose Next.
Next, give the function a name and a description. Then, copy and paste the following code:
'use strict';
exports.handler = (event, context, callback) => {
// Extract the request from the CloudFront event that is sent to Lambda@Edge
var request = event.Records[0].cf.request;
// Extract the URI from the request
var olduri = request.uri;
// Match any '/' that occurs at the end of a URI. Replace it with a default index
var newuri = olduri.replace(/\/$/, '\/index.html');
// Log the URI as received by CloudFront and the new URI to be used to fetch from origin
console.log("Old URI: " + olduri);
console.log("New URI: " + newuri);
// Replace the received URI with the URI that includes the index page
request.uri = newuri;
// Return to CloudFront
return callback(null, request);
};
Next, define a role that grants permissions to the Lambda function. For this example, choose Create new role from template, Basic Edge Lambda permissions. This creates a new IAM role for the Lambda function and grants the following permissions:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:PutLogEvents"
],
"Resource": [
"arn:aws:logs:*:*:*"
]
}
]
}
In a nutshell, these are the permissions that the function needs to create the necessary CloudWatch log group and log stream, and to put the log events so that the function is able to write logs when it executes.
After the function has been created, you can go back to the browser (or cURL) and re-run the test for the subdirectory request that failed previously:
You have now configured a way for CloudFront to return a default index page for subdirectories in S3!
Summary
In this post, you used Lambda@Edge to be able to use CloudFront with an S3 origin access identity and serve a default root object on subdirectory URLs. To find out some more about this use-case, see Lambda@Edge integration with CloudFront in our documentation.
If you have questions or suggestions, feel free to comment below. For troubleshooting or implementation help, check out the Lambda forum.