Containers
How to build highly available Kubernetes applications with Amazon EKS Auto Mode
As organizations scale their Kubernetes deployments, many find themselves facing critical operational challenges. Consider how DevOps teams spend countless hours planning and executing cluster upgrades, managing add-ons, and making sure that security patches are applied consistently. There is a clear need for reliable, automated cluster lifecycle management with teams struggling to maintain consistent cluster configurations and security postures across environments. Amazon Elastic Kubernetes Service (Amazon EKS) Auto Mode addresses these challenges by automating control plane updates, streamlining add-on management, and making sure that clusters maintain current best practices.
This post explores the capabilities of EKS Auto Mode in depth, subjecting it to a series of challenging scenarios such as failure simulations, node recycling, and cluster upgrades—all while maintaining uninterrupted service traffic. This guide delves into strategies for achieving high availability in the face of the dynamic nature of EKS Auto Mode by using a range of Kubernetes features to maximize uptime. The goal is to provide a comprehensive guide that shows how to harness the potential of EKS Auto Mode, thus making sure that your services remain robust and resilient in the demanding environments. Although there is a wealth of comprehensive literature on the broader subject of reliability in container ecosystems, this post specifically narrows its scope to the nuanced considerations of operating reliable workloads within EKS Auto Mode environments.
Solution overview
Before delving into the specifics of Amazon EKS and its Auto Mode feature, you must understand key Kubernetes concepts that are instrumental in maximizing service uptime during different cluster events. These foundational elements form the bedrock of resilient application architectures in Kubernetes environments, regardless of the specific cloud provider or management mode. Mastering these concepts enables you to use EKS Auto Mode effectively and build highly available systems that withstand various operational challenges. In the rest of this section we explore these essential Kubernetes features that play a pivotal role in maintaining service continuity during both planned and unplanned events.
Pod Disruption Budgets (PDBs) limit the number of concurrent disruptions that the application experiences, allowing for high availability. PDBs provide protection when nodes drain for scale or maintenance and make sure that the majority of replicas of a service do not go down at the same time.
Pod Readiness Gates are essential for achieving zero-downtime deployments when using AWS load balancers. New pods typically register with target groups more slowly than the deployment rolls out, thus service disruptions can occur when only Initial or Draining targets remain. Implementing Pod Readiness Gates at the namespace level means that pods won’t terminate until their replacements are confirmed Healthy in Application Load Balancers (ALBs)/Network Load Balancers (NLBs), thus eliminating deployment gaps.
Deregistration Delay Timeout is the time period between when a target is marked for removal and when it stops receiving new requests. This allows in-flight requests to complete gracefully before termination, and it is typically used with load balancers. The default value is 300 seconds. This helps minimize disruption to your users and make sure of a smoother transition when you remove targets from the target group.
Topology Spread Constraints provide critical control over pod distribution across failure domains (nodes, Availability Zones (AZs), and AWS Regions), serving as a powerful mechanism to make sure of high availability by preventing the concentration of workloads at single failure points. maxSkew: 1 means that the configuration makes sure that no zone or node can have more than one added pod when compared to others. This promotes optimal workload distribution while maintaining scheduling flexibility with ScheduleAnyway.
Termination Grace Period is the time given to a pod to shut down gracefully before being forcefully terminated (default 30 s). This allows applications to clean up resources and connections before being killed.
SIGTERM Handling is application-level implementation for gracefully handling shutdown signals from Kubernetes. This enables the proper cleanup of resources, saving state, and closing connections before termination.
Liveness probes check if a container is running properly and restart it if checks fail, while readiness probes determine if a container is ready to serve traffic and remove it from the load balancer if not ready. These two probe types work together in Kubernetes to make sure of application health and proper traffic management.
The sample application implements a comprehensive resilience strategy featuring multiple protection mechanisms. Pod Disruption Budget maintain 80% minimum availability during maintenance, and Pod Readiness Gates (through elbv2.k8s.aws/pod-readiness-gate-inject: enabled) prevent premature termination, optimized 30 s deregistration delay, and balanced pod distribution across AZs and nodes using topology constraints (maxSkew=1). Graceful lifecycle management is achieved through a 60 s termination sequence combining a 10 s preStop hook with 50 s for SIGTERM handling. Furthermore, it’s complemented by dual health monitoring using readiness probes for traffic management alongside liveness probes that handle container health checks to maintain system stability. This architecture makes sure of consistent availability, intelligent load distribution, and zero-downtime transitions throughout the application lifecycle.
Test scenarios
For our demonstration, we’ve chosen the Amazon EKS Elastic Load Balancer example as our reference workload. The specific application is less important here because the purpose is effectively showcasing universal principles that apply across all Kubernetes workloads.
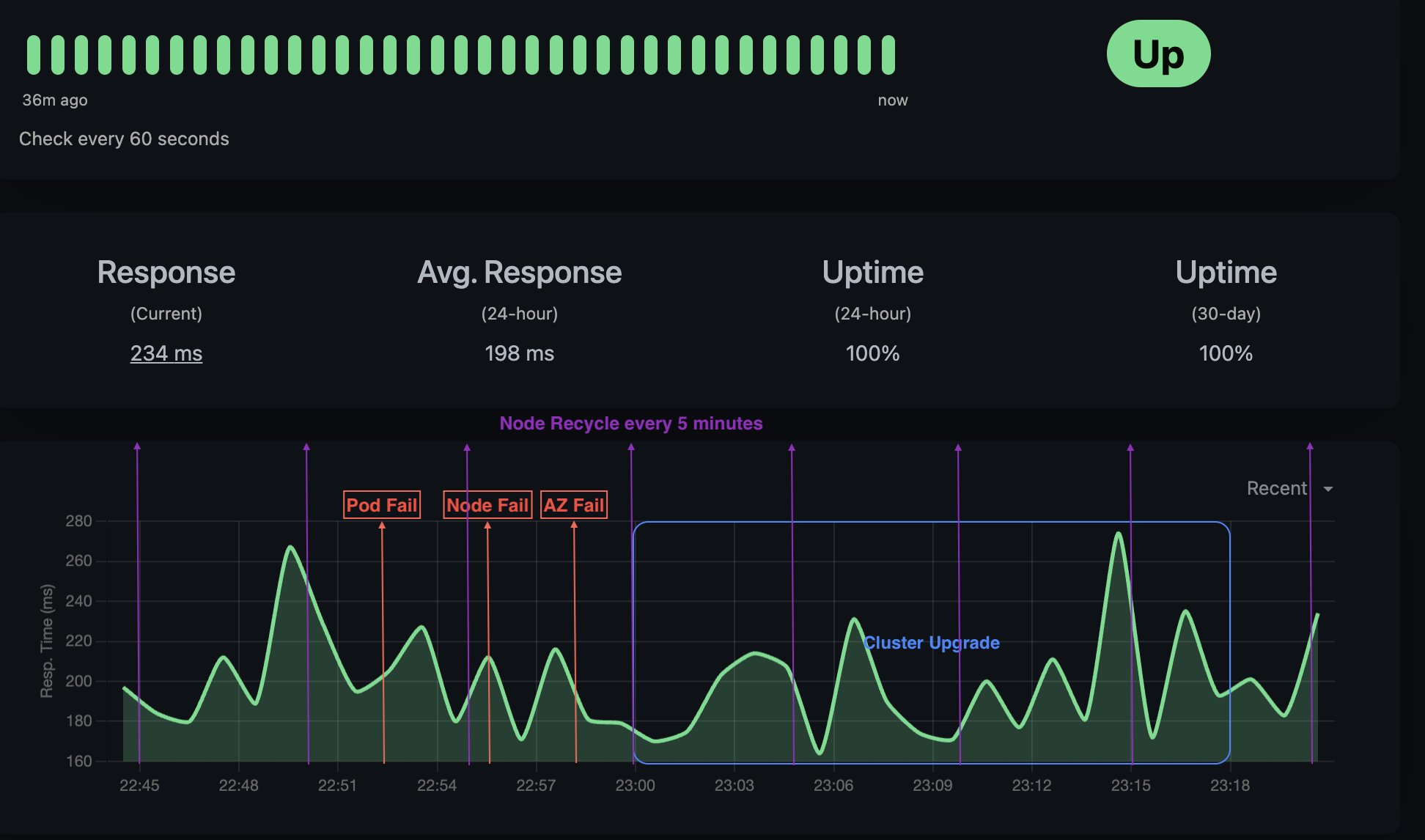
Figure 1: Different failure scenarios are shown on the uptime graph powered by uptime-kuma
For our demonstration, we are using the third-party Uptime Kuma monitoring tool. You can simulate this graph and the following examples by running the uptime-kuma tool in a docker container or locally using the GitHub instructions provided in the link and configuring it to monitor your ALB. This allows you to track the traffic and availability of applications exposed through your ALB.
Pod fail scenario
When individual pods fail unexpectedly, Kubernetes must rapidly restore service capacity. This test deliberately terminates a single pod to verify automatic recreation by controllers, validate readiness probe effectiveness, and measure recovery time. The purpose is to assess how well the application maintains service continuity during these common microservice failures.
After we delete one pod, Kubernetes immediately detects the pod termination. A new pod is instantly scheduled and created to replace the terminated one. The readiness probe makes sure that the new pod is fully operational before receiving traffic. And the PDB makes sure that a minimum number of pods remain available during this process. Therefore, service continuity is maintained with minimal disruption. The preceding figure helps verify that the system behaves as expected and maintains the desired level of availability.
Node fail scenario
Node failure tests simulate complete host outages by cordoning and draining nodes. This validates pod rescheduling mechanics, evaluates how topology spread constraints redistribute workloads, and measures the efficacy of PDBs in maintaining minimum availability. This test reveals whether applications withstand hardware failures without service disruption.
After we delete a node, Kubernetes marks the node as unschedulable (cordon) and existing pods are safely evicted from the node (drain). Pods are automatically rescheduled to healthy nodes based on the available resources, topology spread constraints, and PDB requirements for minimum availability. The preceding figure shows service continuity during the node failure simulation, demonstrating the system’s resilience to hardware failures.
AZ fail scenario
Simulating a complete AZ outage allows us to validate our multi-AZ architecture’s resilience. These tests confirm that topology configurations correctly distribute workloads across zones and that the application can operate at reduced capacity when an entire AZ becomes unavailable. This is crucial for regional disaster recovery planning. To simulate this, we delete all nodes from a single AZ to verify if nodes are drained gracefully and pods in that zone become unhealthy. Kubernetes reschedules them into healthy nodes as per the topology spread constraints, and new nodes are up as per the workload requirement and the health of the restored AZ. The preceding figure shows how service continues with reduced capacity but remains operational, thereby validating the effectiveness of our disaster recovery planning and zone redundancy strategy.
Cluster version upgrade scenario
The upgrade resilience test validates application compatibility across Kubernetes versions and measures downtime during control plane and data plane transitions. The upgrade verifies that the deployment strategies accommodate rolling upgrades of nodes while respecting PDBs and Node Disruption Budgets (NDBs).
Upgrades are initiated from the console. The following figure demonstrates the application availability by pinging the ALB URL every 20 s during both control plane and worker node upgrades.

Figure 2: Cluster upgraded
Karpenter node disruption
The Karpenter node disruption assessment implemented a custom nodepool configuration manifest that replaces Kubernetes nodes at five-minute intervals as shown below, creating controlled infrastructure volatility to methodically evaluate application availability. The evaluation identified key resilience factors: properly implemented shutdown handlers improved service continuity, connection management required optimization to accommodate node lifecycle events, capacity management through Pod Disruption Budgets prevented cascading failures, and health probe configurations directly impacted service availability.
Figure 1 demonstrates the service availability metrics during this controlled infrastructure volatility period, showing how the application maintains stability despite frequent node replacements.
To summarize the preceding test scenarios, the EKS Auto mode features indicate the tradeoff between application resiliency and cost optimization aspects.
For resilience, EKS Auto Mode maintains application high availability by dynamically adding or removing nodes based on application demands. It replaces nodes in the allocated timeframe (every 21 days at maximum) to make sure that nodes run the latest security patches and updates. In Kubernetes upgrade testing, EKS Auto Mode intelligently respects and adheres to the PDB configuration.
For cost optimization, EKS Auto Mode actively monitors and terminates unused or underused instances to make sure that organizations don’t waste resources on idle compute capacity. Furthermore, it continuously evaluates to consolidate workloads onto appropriate nodes and balances the compute costs by maintaining strict adherence to NodePool requirements for instance types.
Conclusion
Comprehensive testing of Amazon EKS Auto Mode with failure and upgrade scenarios has demonstrated the cluster’s resilience when properly configured with Kubernetes best practices for high availability. Implementing features such as Pod Disruption Budgets, Pod Readiness Gates, Topology Spread Constraints, and efficient pod lifecycle management allowed the application to achieve consistent uptime across pod failures, node disruptions, simulated AZ outages, and cluster upgrades. These results underscore that while EKS Auto Mode streamlines cluster management, it’s the careful implementation of Kubernetes-native features that truly enables high availability. Moreover, the fundamental principles and established practices outlined in the AWS resources—namely the Operating Resilient Workloads on Amazon EKS and the Amazon EKS Reliability Best Practices documentation—remain relevant and applicable. These resources serve as essential foundational knowledge that complements the specialized focus described here.
For teams aiming to maximize their EKS cluster’s reliability, we recommend implementing comprehensive PDBs, using Pod Readiness Gates with AWS load balancer integration, designing applications with proper shutdown handling and health checks, and using Karpenter for efficient node management. Combining the directness of EKS Auto Mode with these advanced Kubernetes features enables organizations to achieve a highly available and manageable Kubernetes environment that meets the demands of modern, cloud-native applications. To learn more about EKS Auto Mode, review the workshop.
About the authors
 Doruk Ozturk is a Senior Containers Specialist Solutions Architect at Amazon Web Services, specializing in the Healthcare and Life Sciences industries. With over a decade of software engineering experience, he provides technical guidance to customers leveraging AWS container technologies. Based in New York City, Doruk enjoys traveling with his wife, playing drums with local bands, and recreational pool in his free time.
Doruk Ozturk is a Senior Containers Specialist Solutions Architect at Amazon Web Services, specializing in the Healthcare and Life Sciences industries. With over a decade of software engineering experience, he provides technical guidance to customers leveraging AWS container technologies. Based in New York City, Doruk enjoys traveling with his wife, playing drums with local bands, and recreational pool in his free time.
 Divya Gupta is an Associate Specialist Solutions Architect at AWS.
Divya Gupta is an Associate Specialist Solutions Architect at AWS.
 Nikita Ravi Shetty is an Associate Solutions Architect at AWS focusing on containers. She supports global Telecommunications and Retail/Consumer Goods industries in migrating and modernizing applications on AWS. Outside of work, she enjoys streaming shows, exploring different cuisines, and connecting with friends and family.
Nikita Ravi Shetty is an Associate Solutions Architect at AWS focusing on containers. She supports global Telecommunications and Retail/Consumer Goods industries in migrating and modernizing applications on AWS. Outside of work, she enjoys streaming shows, exploring different cuisines, and connecting with friends and family.