AWS Physical AI Blog
Sim-to-Real and Real-to-Sim: The Engine Behind Capable Physical AI
Introduction
Physical AI systems – robots that perceive, reason, and act in the real world, are advancing rapidly. The Sim-to-Real pipeline is at the heart of this progress. However, building models that work reliably outside the lab remains one of the hardest problems in the field. The gap between what works in simulation and what works on physical hardware is where most projects stall.
This post examines why Sim-to-Real (Sim2Real) and Real-to-Sim (Real2Sim) have become the most critical techniques for building AI models that operate in physical environments. It covers what makes the sim-to-real gap so persistent, how modern approaches close it, and why the class of models now driving robotics – Vision Language Action models (VLAs) – depend entirely on the quality of this pipeline.
Why Real-World Training Alone Does Not Scale
Training a robot to perform a manipulation task typically requires tens of thousands of demonstration episodes to generalize across lighting, object positions, surface textures, and gripper orientations. Running those episodes on physical hardware is slow, expensive, and risky.
The constraint is universal. Warehouse automation typically needs thousands of SKU variations. Autonomous vehicles usually require millions of driving scenarios. Surgical robots need procedures that cannot ethically be rehearsed on real patients. Physical data collection at the required scale is simply not feasible.
Simulation addresses this directly. A physics-accurate virtual environment normally generates training data orders of magnitude faster, at a fraction of the cost, from a virtual and safe environment. However, a model trained purely in simulation tends to fail when deployed to the real world due to the physical nature of operating in an ever-changing and not always predictable environment. This failure mode has a name: the sim-to-real gap, or reality gap.
The Sim-to-Real Gap
The sim-to-real gap is the performance difference between a model trained in simulation and that same model deployed to physical hardware. It exists because simulation is an approximation. Real cameras introduce noise, distortion, and exposure variation that synthetic renders do not capture by default. Real surfaces have friction coefficients that no physics engine models perfectly. Real actuators have backlash, latency, and thermal drift. A model trained on clean synthetic data learns to exploit the perfection of the simulation, and that learned behavior does not transfer.
Closing the gap requires two complementary strategies.
Improving simulation fidelity. Modern physics simulators like NVIDIA Isaac Sim model rigid-body dynamics, deformable objects, fluid behavior, and contact forces at a level of accuracy that was not available mere years ago. Photorealistic rendering using path tracing and physically-based materials produces visual inputs that are increasingly hard to distinguish from real camera feeds.
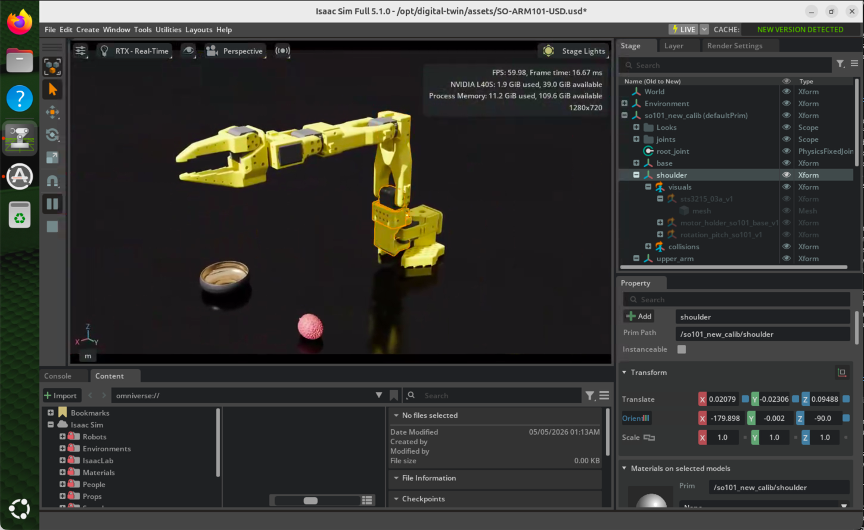
Figure 1: NVIDIA Isaac Sim running on an Amazon EC2 G6e.4xlarge instance
Domain randomization. Rather than making a single simulation perfectly accurate, you train across many randomized variants. Vary lighting, texture, object mass, joint friction, sensor noise, so the policy learns robustness across a broad distribution of conditions. The key is sufficient diversity and coverage of simulation parameters, not just raw volume. This helps the neural networks learn to identify key elements of interest in numerous distinct environments.

Figure 2: A robot solving a Rubik’s Cube, as demonstrated by OpenAI. (Source: OpenAI, https://openai.com/index/solving-rubiks-cube/)
Real-to-Sim: Turning the Physical World Into Training Infrastructure
Real-to-Sim is the process of capturing real-world environments and converting them into simulation-ready digital representations. If Sim2Real is about transferring learned policies to physical hardware, Real2Sim is about ensuring those simulations reflect the environments where the hardware will operate.
The techniques span several disciplines. LiDAR scanning and photogrammetry produce point clouds that can be processed into 3D meshes. Neural Radiance Fields (NeRF) and 3D Gaussian Splatting reconstruct scene geometry and appearance from standard camera footage, producing assets that feed directly into physics simulation environments. This helps solve the reality gap, where there are performative differences between how virtual and physical assets are modeled. These assets are brought into the virtual world using techniques that help preserve the state of how they look and feel in the real world, across numerous lighting conditions and camera angles.
For Physical AI training pipelines, Real2Sim plays an especially important role in teleoperation data collection. A human operator controls a physical robot arm through a demonstration interface, and the system simultaneously mirrors those movements in a digital twin running in simulation. This gives you two things at once: a human-quality demonstration dataset recorded in the real world, and a synchronized simulation trace that can generate additional synthetic variations of the same task.

Figure 3: Teleoperations using the SO-101
This approach is a practical accelerator because it addresses the central bottleneck of imitation learning – the paradigm where a robot learns by observing human demonstrations rather than through reward-based trial and error. High-quality human demonstrations are the training signal that imitation learning depends on, and Real2Sim infrastructure lets you scale that signal without proportionally scaling physical hardware costs.
Synthetic Data Generation and Filtering
Real-world and teleop-captured data provide distribution-aligned supervision, meaning the training examples reflect the actual conditions (lighting, object types, camera angles) the robot will face during deployment. Simulation provides scale. Modern Physical AI training pipelines combine the two.
Synthetic data generation involves programmatically producing labeled training examples at scale inside simulation environments. For manipulation tasks, this means rendering thousands of variations of a grasping scenario across different object poses, lighting conditions, and gripper configurations, each automatically annotated with ground-truth depth, segmentation masks, and action labels.
Volume alone is not sufficient. Filtering pipelines use automated quality metrics and learned discriminators to remove out-of-distribution or physically implausible samples before they enter the training set. The output of a well-constructed pipeline is a training dataset with the physical grounding of real demonstrations, the scale of synthetic generation, and the quality control of automated filtering.
VLMs, VLAs, and Why Simulation Quality Determines Model Capability
The models that Physical AI teams are now targeting as the foundation layer for robot control are Vision Language Models (VLMs) and Vision Language Action models (VLAs).
A VLM is a multimodal foundation model trained on large corpora of image and text data. It develops broad visual understanding, the ability to reason about what is in an image, describe spatial relationships, identify objects, and follow language instructions that reference visual content. Models on Amazon Bedrock like Amazon Nova, Anthropic Claude, Qwen, and Mistral, are examples of this class. Amazon Bedrock provides a managed API layer for accessing these models without managing the underlying infrastructure, which matters when you are integrating visual reasoning into a broader Physical AI pipeline that already has its own infrastructure complexity.
A VLA extends the VLM paradigm into physical action. Rather than producing text as output, a VLA produces robot actions, joint positions, velocity commands, or end-effector trajectories, in response to visual observations and language instructions. The training objective for a VLA is to learn a policy grounded in both visual understanding and physical causality: given what I see and what I have been asked to do, what action should I take?
The quality of simulation data directly determines how well a VLA generalizes to tasks it has not been explicitly trained on. If the visual domain it trained on (synthetic renders) does not match the deployment domain (real world), the learned policy breaks down and you face immediate performative issues like jerky motor control, task failures and low accuracy for policy evaluation. Domain randomization makes the policy robust by taking in a base high-quality dataset and augmenting it to produce even more high-quality datasets consisting of newer objects, environments with different lighting conditions and colors etc. High-fidelity physics ensures the action outputs are physically meaningful when transferred.
Synthetic data pipelines also allow teams to train VLAs on task distributions impossible to cover with real demonstrations alone, rare failure modes, edge-case configurations, and environments that don’t yet physically exist.
Industry Applications
The industries where this pipeline delivers the most immediate value share a common characteristic: the physical environments are high-stakes, variable, and expensive or dangerous to learn directly.
In Manufacturing, warehouse automation systems need to generalize across SKU variation, packaging damage, and changing floor layouts. Real2Sim capture feeds simulation training, and Sim2Real transfer produces policies that hold up across real-world variation.
In Automotive, autonomous driving systems normally require training across millions of edge-case scenarios that cannot be safely orchestrated in the real world.
In Healthcare, surgical and patient care applications face strict safety and regulatory constraints. High-fidelity simulation allows model training and validation to proceed independently of patient contact.
In Energy and Utilities, autonomous robots for inspection operate in substations, pipelines, and wind farms where sending a human carries real physical risk.
In Retail, autonomous fulfillment systems must handle enormous SKU variety across constantly changing layouts. Simulation that generates training data across thousands of product variations is the only practical path to production-scale generalization.
What Comes Next
This post has covered the why and the what of the Sim2Real/Real2Sim pipeline, the core engine that makes Physical AI models capable of operating in the real world. In the next post in this series, we make it concrete with a hands-on technical deep-dive into the LeRobot SO-101 AWS Sim2Real2Sim reference project: a fully deployable architecture that implements these concepts end-to-end using AWS infrastructure, NVIDIA Isaac Sim, and the publicly available LeRobot platform.
To get started, explore Amazon Bedrock for foundation model access, and review the Amazon EC2 G6e instances optimized for simulation workloads.