Amazon Supply Chain and Logistics
Automating Amazon ATS Labor Planning with Serverless AWS
Amazon manages one of the world’s most complex logistics networks, with 100+ middle mile sortation centers across North America processing millions of packages daily. Behind every package movement is a labor plan — planning for over 100k associates annually, determining week by week how many are needed, when they should work, and how to balance capacity against forecasted volume. Getting this right is critical: understaffing leads to delayed packages and missed Service Level Agreement(SLA’s), while overstaffing drives unnecessary labor costs.
In this post, we explore how Amazon’s North America Sort Center (NASC) organization built ALAP (Automated Labor Assumptions Platform) — a serverless web platform that replaced a 28-hour-per-week manual planning process with an automated, event-driven system. ALAP processes 31 planning metrics across 100+ sites using AWS Lambda, Amazon DynamoDB, Amazon EventBridge, Amazon SQS, and Amazon S3, enabling labor planners to dramatically increase their operational efficiency while improving planning accuracy.
Prerequisites
This post assumes an understanding of the following services and concepts:
- Serverless compute with AWS Lambda
- NoSQL databases with Amazon DynamoDB
- Event-driven architectures with Amazon EventBridge and Amazon SQS
- Object storage with Amazon S3
- Content delivery with Amazon CloudFront
- Authentication with Amazon Cognito
- Data integration with AWS Glue and Amazon Aurora PostgreSQL
Although hands-on experience is not required, a conceptual understanding of these services will help in understanding the architecture and design patterns discussed throughout this article.
Business challenges
Each week, Labor Planning Analysts (LPAs) facilitate meetings to review labor planning guidance recommendations for their assigned sort centers. During these calls, they review 31 input metrics — including attendance, attrition, throughput per hour (TPH), roster, and hiring constraints — with Operations, HR, Finance, and Workforce Staffing teams for each day and shift across a 13-week planning horizon.
Initially this process was entirely manual:
- Strategy teams published guidance in wiki pages and released Assumptions Decks via shared documents
- LPAs downloaded Excel-based Assumptions Files, reviewed inputs with site stakeholders over video calls, and manually generated planning input files
- Dry runs in the planning system took hours due to manual adjustments required to generate input files for labor planning model runs,
- Regional managers reviewed deviations to guidance on Wednesdays, requiring additional coordination
At scale, this process consumed a combined 20+ hours per week across all stakeholders for a single site. For an LPA managing ~3-4 sites (the standard ratio), assumptions planning alone consumed 10+ hours per week — leaving little time for high-value analysis.
The key pain points were:
- Error-prone manual data entry — transferring values between spreadsheets and planning input files introduced inconsistencies
- No audit trail — override decisions and approvals happened over video calls with no systematic tracking
- Slow feedback loops — LPAs couldn’t see the impact of assumption changes until after hours-long dry runs
- Scalability ceiling — the manual process couldn’t keep pace with network growth
- No standardization — each LPA had slightly different processes and Excel templates
Solution overview
Architecture Diagram
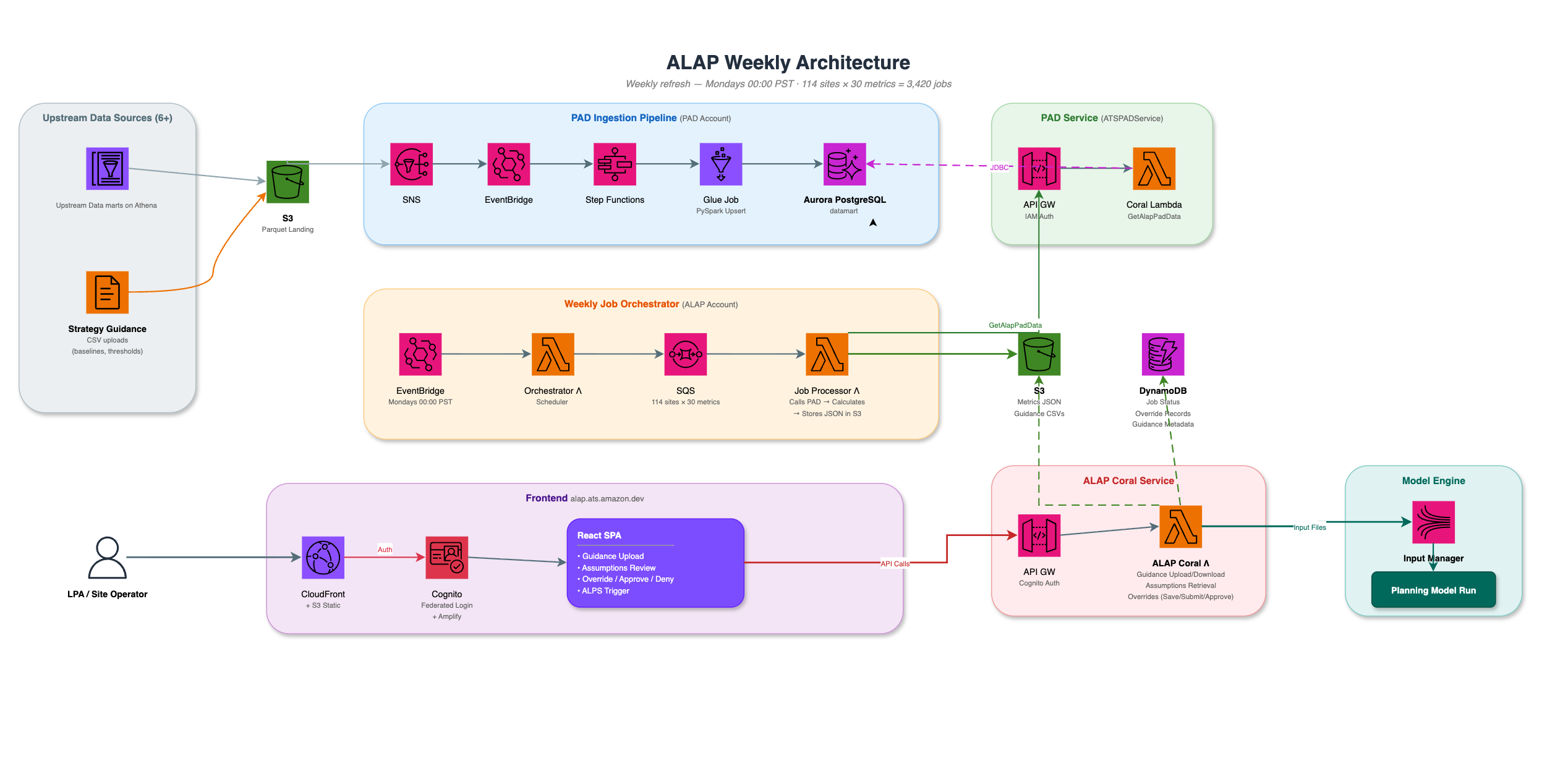
Figure 1: ALAP Architecture Diagram
ALAP is a serverless web platform that automates the end-to-end labor planning assumptions workflow. It consumes historical data and ML model outputs from a centralized data layer, applies strategy guidance, calculates standardized final inputs, and enables site stakeholders to review, override, and approve assumptions through a web interface — all without touching a spreadsheet.
The architecture consists of five major components:
1. Web application — Frontend
Users access ALAP through a modern web application. The frontend is a single-page application hosted on Amazon S3 and served through Amazon CloudFront for fast global delivery. Authentication uses Amazon Cognito with federated login, providing role-based access control for different personas:
- Strategy PMs — upload and manage guidance files
- Site Operators — review assumptions and submit overrides
- Regional Managers — approve or deny override requests
- LPAs — publish finalized assumptions and trigger planning runs
The frontend communicates with backend APIs using secure authentication tokens, providing a seamless login experience while maintaining strict security standards.
2. Backend APIs — Serverless compute
A single AWS Lambda function handles all backend operations through a set of APIs:
- Guidance management — secure file upload/download for strategy guidance documents
- Assumptions retrieval — serving calculated metrics data to the frontend
- Override workflow — save, submit, approve, and deny overrides with full audit trail
- Job management — triggering metric recalculations and tracking job status
- Planning system integration — generating and publishing input files to the downstream labor planning optimizer
We chose AWS Lambda (pay-per-request serverless compute) because ALAP serves approximately 1,000 users with very low average request volume — making the pay-per-invocation model significantly more cost-effective.
3. Data aggregation layer — Centralized datamart
The data aggregation layer is the backbone of the system. It solves the fundamental challenge of integrating data from 6+ diverse upstream sources into a unified, queryable layer that ALAP can consume.
How it works:
- Database: Amazon Aurora PostgreSQL — Chosen for its superior performance with complex queries / Joins across multiple dimensions (site, shift, labor pools, date ranges etc), advanced indexing capabilities, and support for parallel query execution
- Data pipeline: AWS Glue — processes raw data files from upstream data input systems, transforms them into a standardized format, and loads them into the database. The pipeline is fully event-driven — when new data arrives in S3, it automatically triggers processing without manual intervention
- Scale: Data Aggregation layer is the highest-throughput component in the system, handling ~500 requests per second during peak processing windows and serving over 400,000 requests within a 15-minute window during nightly batch runs
- Performance optimization: API-level caching absorbs repeated queries for the same data combinations, reducing database load by over 60% during peak processing
Each planning metric has dedicated calculation logic that applies the appropriate guidance rules (standard guidance, ML-model-based guidance, or fallback guidance), enabling clean separation of business rules from data access.
4. Job orchestrator — Automated metrics generation
The Job Orchestrator is the engine that transforms raw data into actionable planning metrics every week. Here’s how it works in plain terms:
- Scheduled trigger: Every Monday at midnight (PST), an automated scheduler kicks off the weekly metrics generation
- Parallel processing: The system creates one independent task per site/metric combination — that’s over 3,000 parallel tasks running simultaneously
- Each task does the following:
- Fetches historical data and guidance parameters from the data layer
- Applies metric-specific calculation logic (historical averages, ML model outputs, guidance rules)
- Generates a structured data file with calculated values for the 13-week planning horizon
- Stores the result in Amazon S3 for the frontend to consume
- Status tracking: Each task’s progress (scheduled → in-progress → completed/failed) is tracked in DynamoDB so operators can monitor the pipeline from the web interface
The entire pipeline completes within approximately 3 hours, ensuring all metrics data is available by 6 AM PST — well before planners begin their workday.
5. Assumptions deck generation — Preview and production modes
Beyond the web interface, ALAP generates Excel-based Assumptions Decks (31 sheets covering 29 dynamic metrics plus 2 parameter sheets) for downstream consumption. The system supports two modes:
- Production decks — incorporate only approved overrides, used for official planning runs
- Dry Run decks — incorporate both approved and submitted (pending) overrides, enabling LPAs to preview the impact of pending changes before approval. Cells with pending overrides are visually highlighted.
This dual-mode capability eliminated hours of waiting time in the planning cycle, allowing LPAs to run preliminary scenarios while overrides are still pending approval.
Data flow
The following describes the new end-to-end weekly planning cycle using the ALAP methodology
Monday 00:00 PST — Automated Metrics Generation
- The scheduled trigger kicks off the job orchestrator
- 3,000+ parallel tasks query the data layer and generate metrics files
- By 6 AM PST, all calculated assumptions are available for planners
Monday–Tuesday — Strategy Guidance Upload
- Strategy PMs upload guidance files through the ALAP web interface
- ALAP validates and stores guidance metadata
- Metrics are recalculated incorporating the latest guidance
Tuesday — Assumptions Review
- Site stakeholders log into ALAP and review calculated assumptions by metric, day, shift, and labor pool
- Site Operators submit overrides where they disagree with guidance
- Overrides below threshold are auto-approved; those above threshold route to Regional Managers
Wednesday — Override Approval
- Regional Managers review pending overrides with projected impact analysis
- Approved overrides update the finalized metrics; denied overrides retain guidance values
- LPAs are notified once all overrides are resolved
Thursday — Plan Publication
- LPAs publish finalized assumptions with one click
- ALAP generates the planning input file incorporating all approved overrides
- The input file is automatically loaded into the labor planning optimizer
- The optimizer triggers a run to determine labor orders, Voluntary Extra Time(VET)/Voluntary Time Off (VTO) recommendations
Business outcomes
The implementation of ALAP has delivered measurable improvements across multiple dimensions:
- 70% reduction in assumptions planning time — from 10+ hours/week to approximately 3-4 hours/week per planner, primarily spent on reviewing overrides rather than manual data manipulation
- Dramatically improved planner efficiency — each planner can now effectively manage significantly more sites, enabling the organization to scale operations without scaling effort proportionally
- Eliminated manual errors — built-in validation rules prevent invalid assumptions from reaching the planning system (e.g., negative attendance values, mathematically inconsistent overrides)
- Complete audit trail — every override, approval, and guidance change is tracked with who, when, old value, new value, and reason code
- Standardized process for 100 sites+ — eliminated regional variations in planning methodology
- 3-hour metrics generation — 3,parallel tasks complete by 6 AM PST, compared to hours of manual Excel manipulation
- Real-time impact visibility — operators can see projected impact of overrides before submitting, enabling better decision-making
Lessons learned and best practices
Choose the right database for the workload
We evaluated multiple database options for the data aggregation layer. While DynamoDB (a NoSQL key-value store) excels for the metadata layer — tracking guidance status, override records, and job progress — Aurora PostgreSQL (a managed relational database) was the clear choice for the analytical workload. The planning data requires complex queries across multiple dimensions (site, shift, labor pool, date range) and joins between metrics. The lesson: use each database for what it does best rather than forcing a single technology across all use cases.
Event-driven fan-out for parallel workloads
Processing 31 metrics for 100+ sites is a naturally parallel problem — each site/metric combination is independent of the others. By using a message queue (Amazon SQS) as the distribution mechanism with independent serverless function invocations per task, we achieved:
- Natural parallelism without managing servers or thread pools
- Built-in retry and error handling for failed tasks
- Cost efficiency — paying only for actual compute time used
- Independent failure isolation — one failed metric doesn’t block others
Caching for bursty read patterns
During the nightly metrics generation window, the data layer receives ~500 requests per second as 3,000+ concurrent tasks query historical data. API-level caching absorbs repeated queries for the same site/metric combinations, reducing database load by over 60% during peak processing. This is a critical pattern for any system with predictable burst traffic.
On-demand pricing for unpredictable workloads
ALAP’s metadata tables see highly variable traffic — near-zero during off-hours, moderate during business hours, and spikes during Tuesday assumptions meetings. DynamoDB’s on-demand pricing mode is cheaper for these workloads, compared to the operational overhead of provisioning and managing fixed capacity. For low-volume, bursty workloads, on-demand pricing eliminates capacity planning entirely.
Conclusion
ALAP has fundamentally transformed how Amazon’s North America Sort Center organization approaches labor planning. By replacing a fragmented, manual process with a unified serverless platform, we’ve enabled planners to focus on high-value decision-making rather than data manipulation.
The serverless, event-driven architecture proved ideal for this workload: highly parallel batch processing (3,000+ tasks weekly), low-volume interactive APIs, and bursty read patterns during planning meetings. The combination of Lambda for compute, DynamoDB for metadata, Aurora PostgreSQL for analytical queries, and SQS for parallel task distribution delivered both cost efficiency and operational simplicity.
Looking ahead, we’re extending ALAP with:
- Intra-week planning — using ML models to dynamically adjust TPH assumptions 3× daily based on package mix changes.
- AI-powered scenario planning — an intelligent assistant integrated into ALAP that enables operations managers to run “what-if” labor scenarios through natural language
- Expanded automation — moving toward a fully automated labor planning process with minimal manual intervention
For those interested in implementing similar solutions, we recommend exploring AWS Serverless Architecture Patterns and the AWS Architecture Blog for additional insights and best practices in building scalable, event-driven platforms.