亚马逊AWS官方博客
异构 ETL 环境的 AI 驱动数据血缘管理系统
背景介绍
随着企业的不断发展和数字化转型,数据已经成为最宝贵的资产。在这个过程中,企业构建并运行着海量的数据管道(Data Pipelines)作业,这些作业是驱动业务决策和创新的核心引擎。然而,这种快速的增长也带来了新的挑战:这些关键的数据资产和数据管道往往分散在不同的业务项目管理者手中,甚至在异构的、多平台的环境中独立运行,导致数据全景视图的碎片化。
试想一个真实的场景:企业的数据流程被分割成两个截然不同的阶段。第一阶段,核心的数据清洗和预处理(ETL)工作由一个由客户自定义的 Spark 项目维护,并且运行在 AWS Glue 这一无服务器计算平台上。第二阶段,更加侧重于数据建模和业务逻辑的转换(ELT),则由 dbt (Data Build Tool) 项目负责管理,并在高性能的 Amazon Redshift 数据仓库中运行。关键在于,AWS Glue 项目所产出的许多数据集是 dbt 项目在 Redshift 中进行后续建模的直接上游数据。这就形成了一个跨越技术栈和平台的关键数据血缘链。但在血缘上缺少统一的管理。
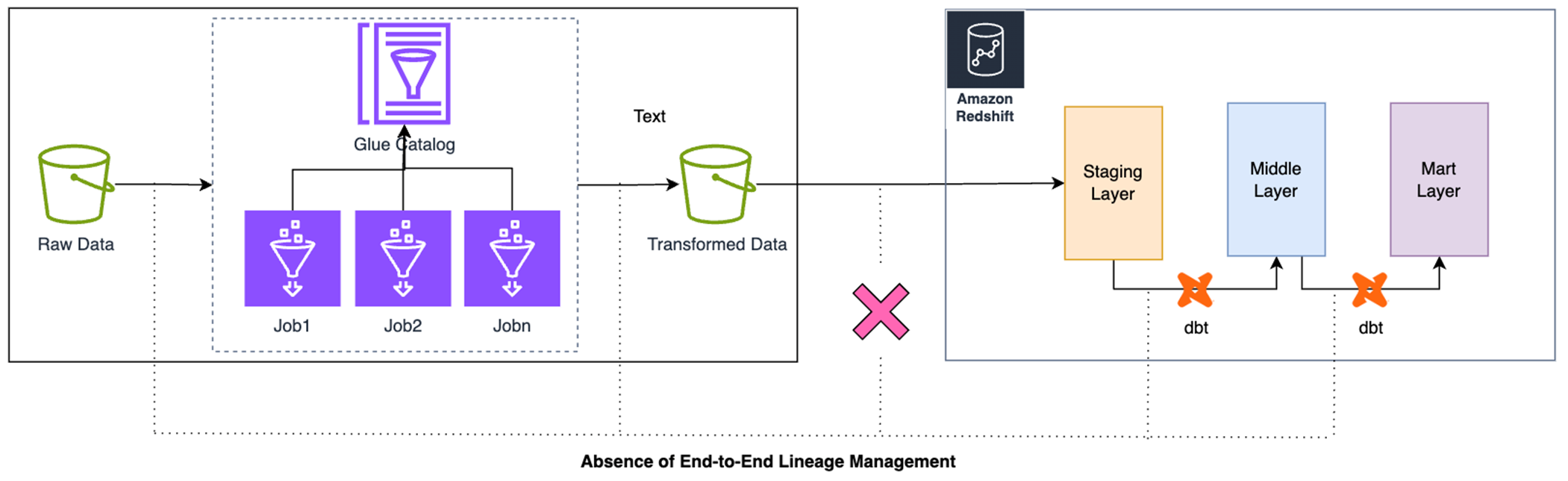 |
正是这种跨异构平台的数据管道碎片化,导致了核心数据治理能力的缺失,并带来了重大的调试难题。
 |
场景一:数据可追溯性与调试的挑战
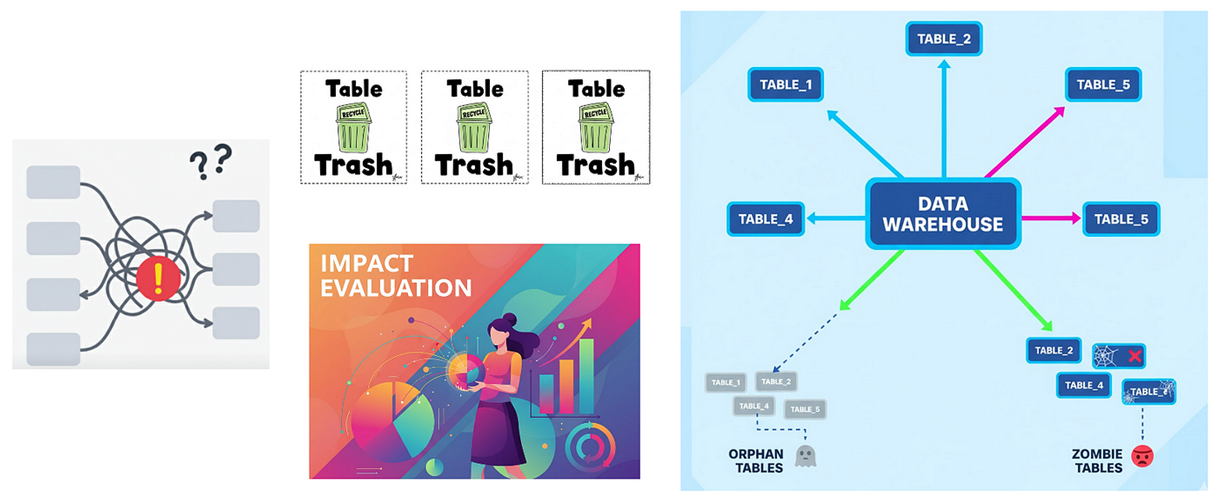
在日常开发、调试和排障过程中,团队经常面临这样的问题:当某个字段的值出现错误时,很难快速定位其计算逻辑的具体定义及其最终的原始数据来源。
此外,当遇到字段名称相同但数值不一致的情况时,迫切需要确认这些字段的聚合指标及其上游依赖是否一致,以及是否存在冗余的数据管道任务。
缺乏端到端的数据血缘视图,使得精准定位这些问题几乎成为不可能。
场景二:下线废弃的数据资产
在大型数据生态系统中,某些历史报表或上游数据集可能已不再使用,或失去了其业务价值。挑战在于如何快速识别这些已废弃的数据集和作业,从而使团队能够及时下线冗余流程,清理未使用的资源——以提升数据治理效率和资源利用率。
场景三:评估字段修改的影响
在日常数据维护过程中,团队经常需要判断某个表字段是否可以修改或删除。该字段可能被多个下游作业、报表或应用所引用。若缺乏对数据血缘和依赖关系的清晰可见性,即便是一次微小的改动,也可能引发连锁问题,导致数据不一致或业务中断。因此,准确评估字段变更的影响,是保障数据生态系统稳定性的关键。
场景四:异常作业与数据集的告警
在复杂的数据管道中,部分作业或数据集可能出现异常状态,需要及时检测与干预。
“孤立节点”指的是没有上游依赖且未被调度系统管理的作业或数据集,这类节点可能形成管理盲区并造成资源浪费。
“僵尸节点”则指虽然存在上游依赖,但长期未被更新或执行的作业或数据集。这些节点可能持续占用系统资源,影响整体性能。
通过对孤立节点和僵尸节点的实时监控与告警,团队能够有效提升数据管道的可靠性,并优化资源使用效率。
目标
面对异构ETL环境中的诸多挑战,我们的目标是构建一个由 AI 驱动的数据血缘系统。
该系统能够在尽可能少改动现有工作流程的前提下,实现端到端、跨平台的数据血缘可视化与追踪。正如下图所示,两个 ETL 平台(Glue + dbt)通过统一血缘管理系统,实现原始数据到数据仓库的端到端血缘追踪。
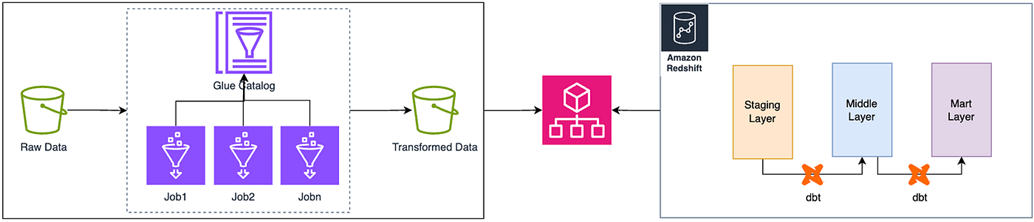 |
通过引入 AI 能力,用户可以深入理解业务关系、发现优化机会并快速解决问题,将数据资产转化为值得信赖的业务智能。
实现上述目标所需技术栈:
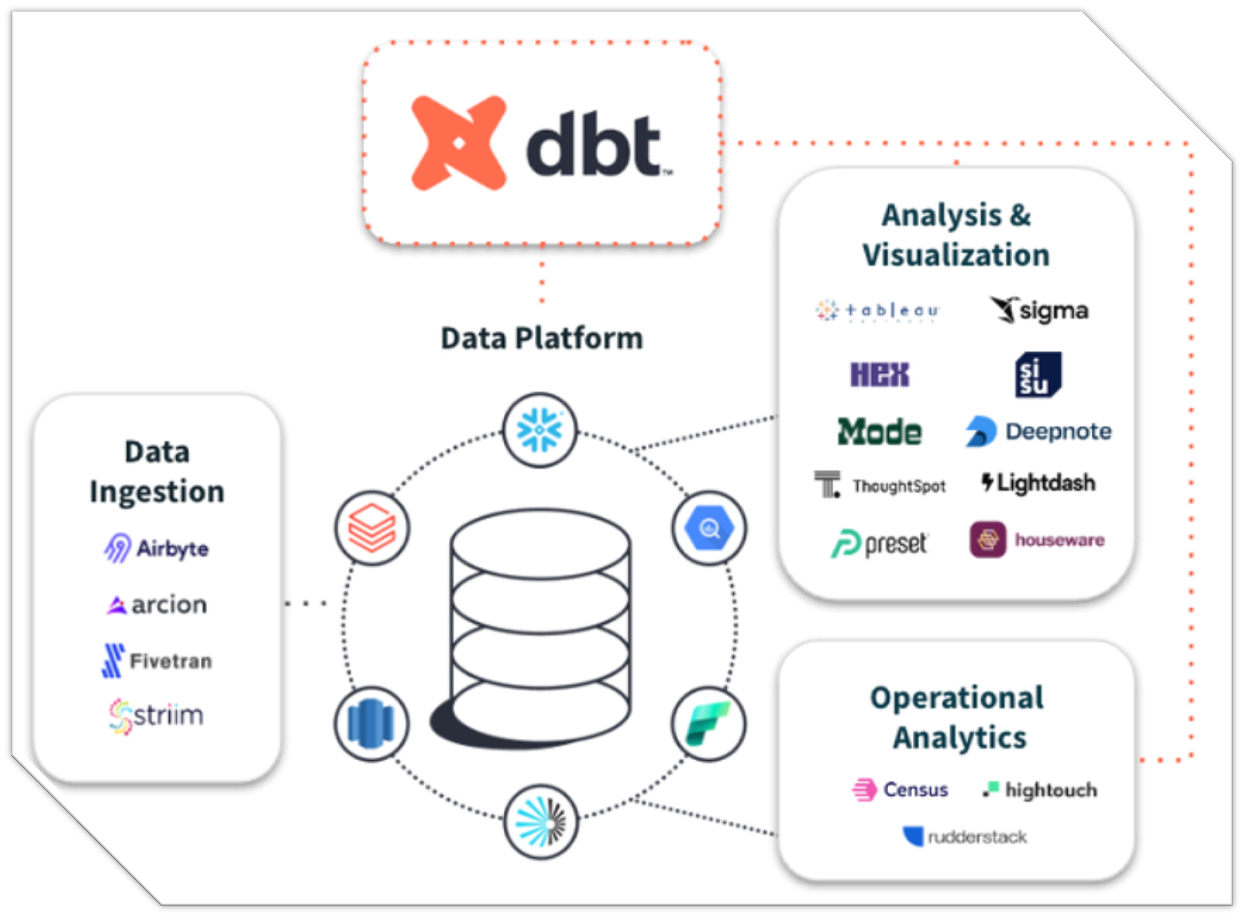
- DBT(数据构建工具)是一个开源命令行工具,让数据分析师和工程师能够通过编写模块化的SQL或Python来转换数据仓库中的数据,并像管理软件代码一样进行版本控制、测试和文档化。
下图展示了dbt作为核心的现代数据平台架构,dbt与多个数据摄取、分析可视化以及运营分析工具紧密集成,支持多种平台的数据处理、转换和可视化,形成一个完整的数据工作流。
 |
- OpenLineage 是一个开源的、与工具无关的数据血缘标准/协议。
无论是计算引擎,还是调度工具,抑或是data build tool,它都有很好的集成。
 |
- Marquez是一个 开源的数据治理和数据血缘 (data lineage) 服务,包括:
 |
-
- 元数据存储:集中存储数据集(datasets)和作业(job)的元信息。
- 数据血缘:自动记录和展示数据流向(哪个 job 读写了哪个 dataset)。
- 开放 API:提供 REST API 和 Java 客户端,便于集成各种 ETL/ELT 工具。
- 可视化 UI:内置简单的前端界面展示数据血缘关系。
如何实现?
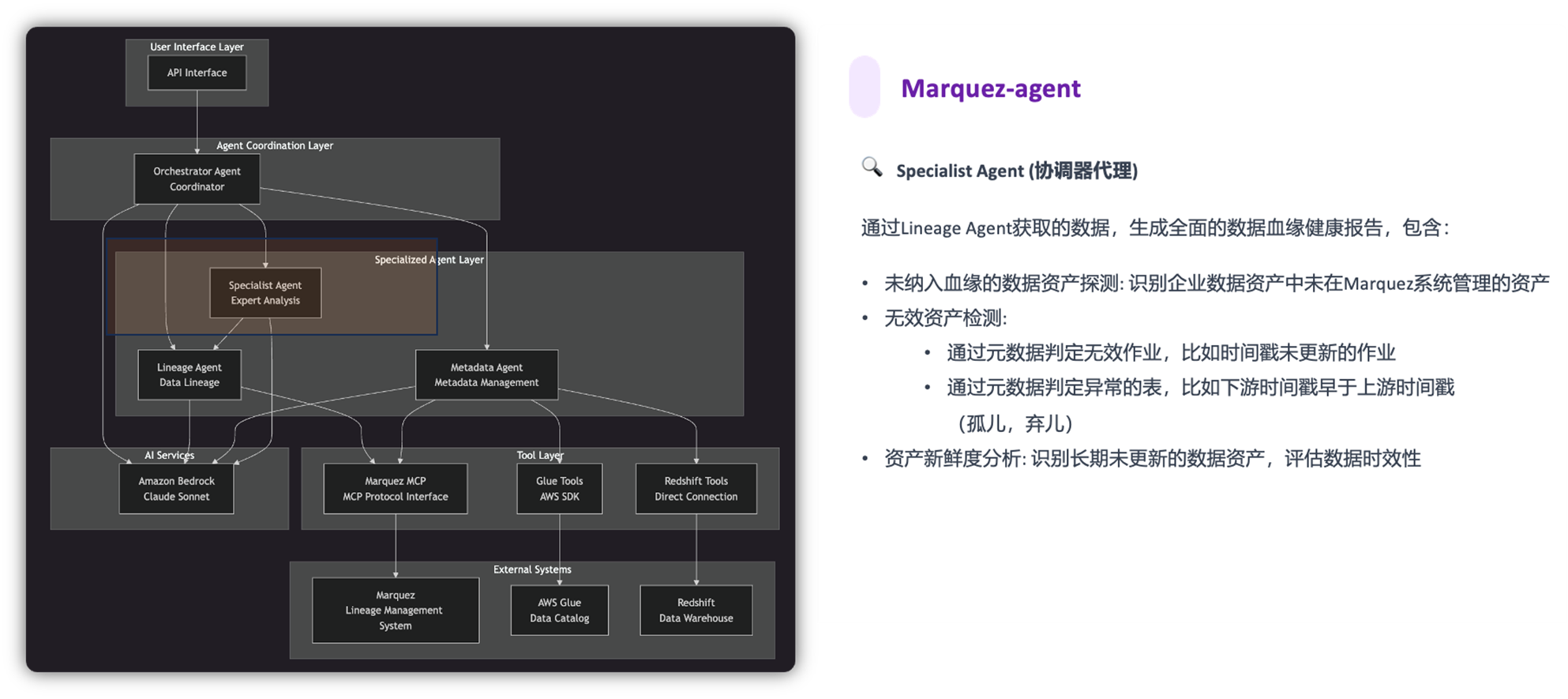
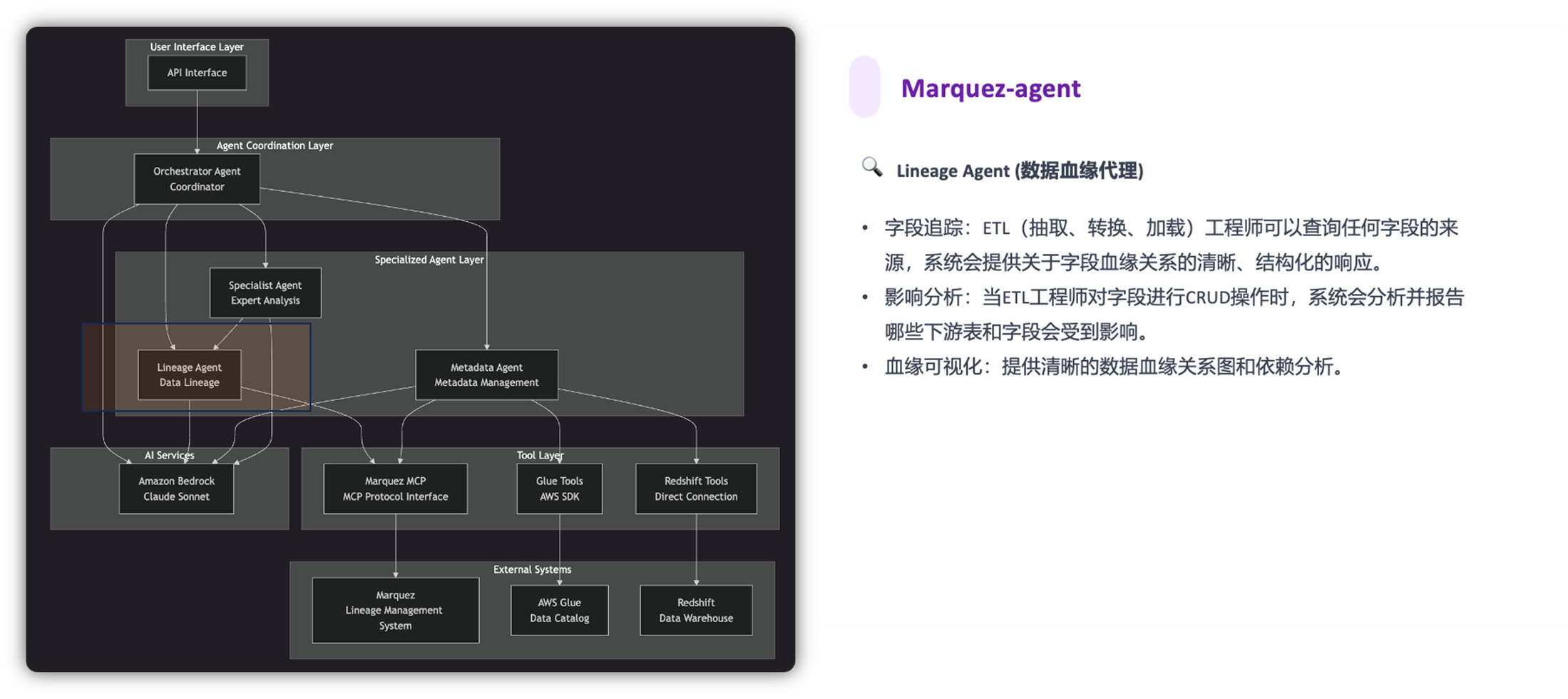
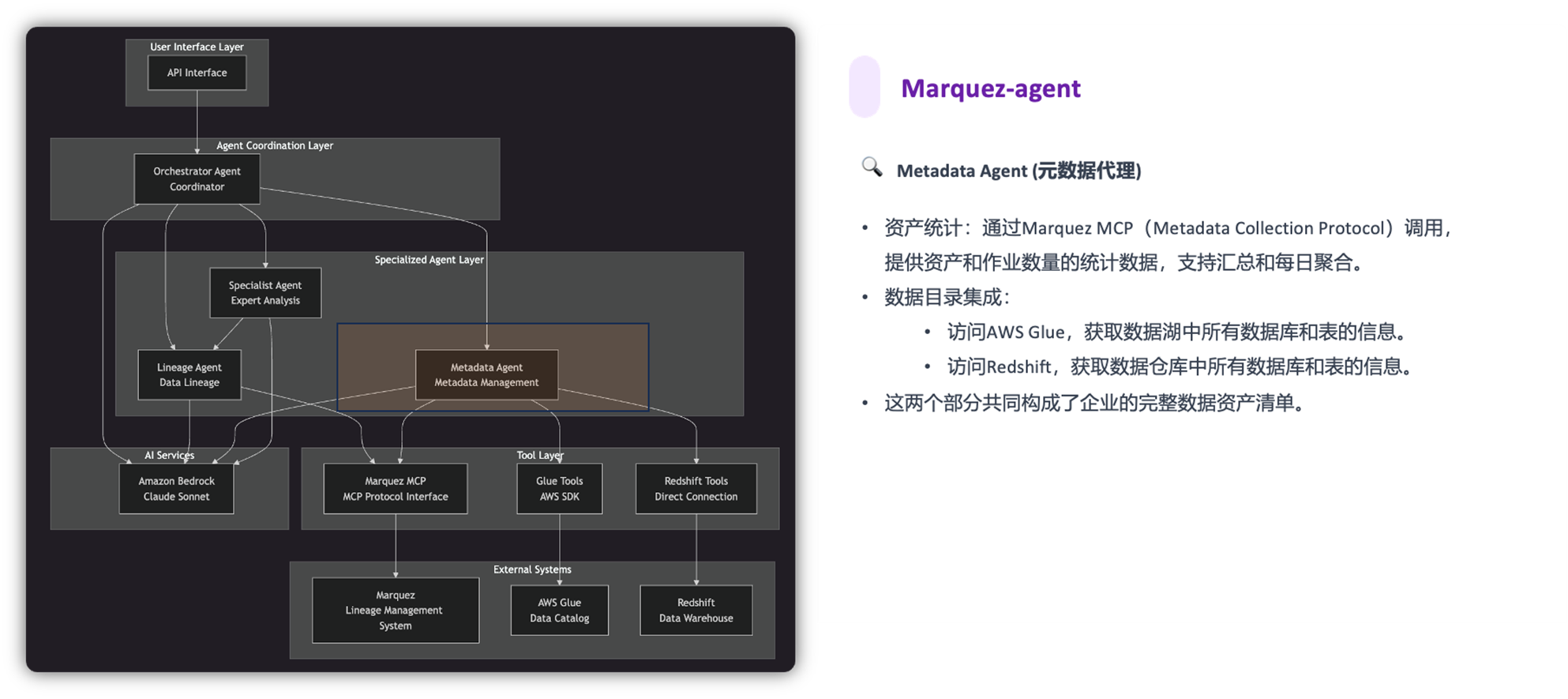
我们的任务是模拟这些层级从而复现数据管道,并在数据作业运行中采集并持久化这些血缘。同时在EKS中部署Marquez Agent和Marquez MCP,以服务方式提供AI能力。
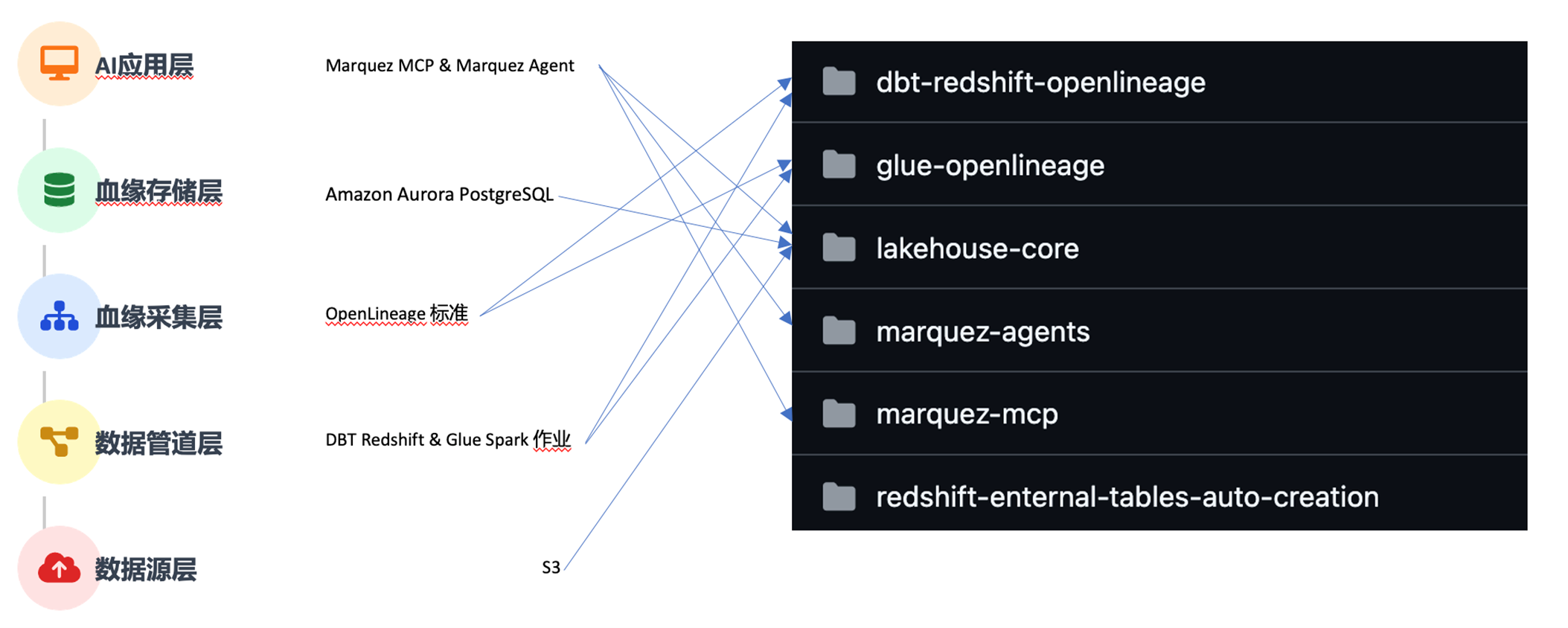 |
如果需要在 AWS 上部署该项目,请参考 GitHub 仓库 sample-agentic-data-lineage 中的说明。本文不会详细介绍部署步骤,而是重点阐述项目中核心功能。
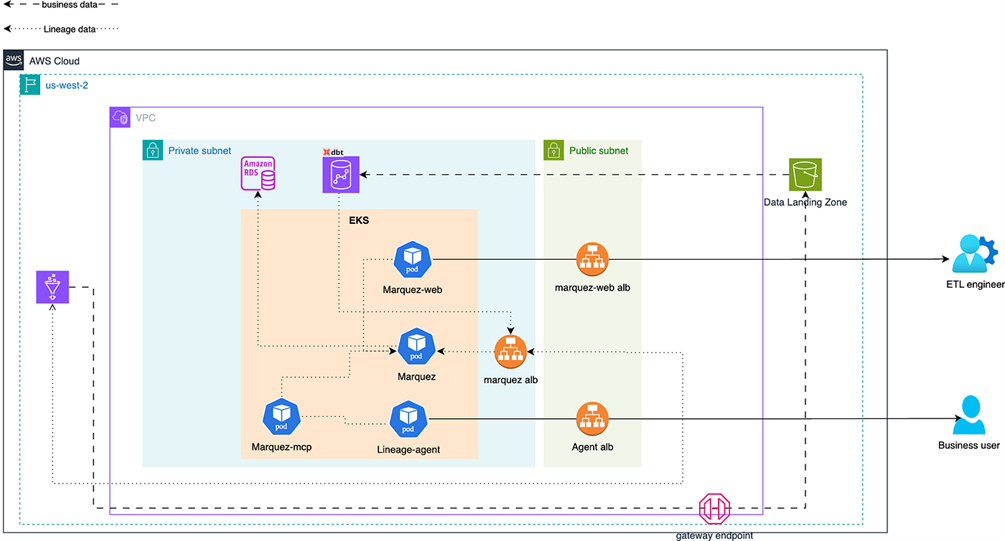
基础设施:由lakehouse-core子工程负责。
- 使用 Terraform 实现 AWS 环境的自动化部署,可通过脚本快速生成变量文件,支持标准化环境上线。
- 集成 Karpenter 实现 Kubernetes 节点自动扩缩容,提升资源利用率与运行效率,降低云成本。
- 动态响应负载变化,无需人工干预即可实现弹性伸缩。
下图为基础设施架构图,
 |
此外,我们需要复现企业的数据管道(在我们的实例中为glue和dbt)。一般来说,这些都是已有的。如何尽可能少改动现有工作流程的前提下,实现端到端、跨平台的数据血缘可视化与追踪,是项目能够推进的重要前提。我们的方案是低代码、非侵入式集成。具体如下:
通过在 AWS Glue 作业的 default_arguments 中添加特定的 Spark 配置,将 OpenLineage 集成进去。
对于 dbt 的列级血缘,无需修改业务代码;只需在外层引入 dbt-colibri 插件即可。
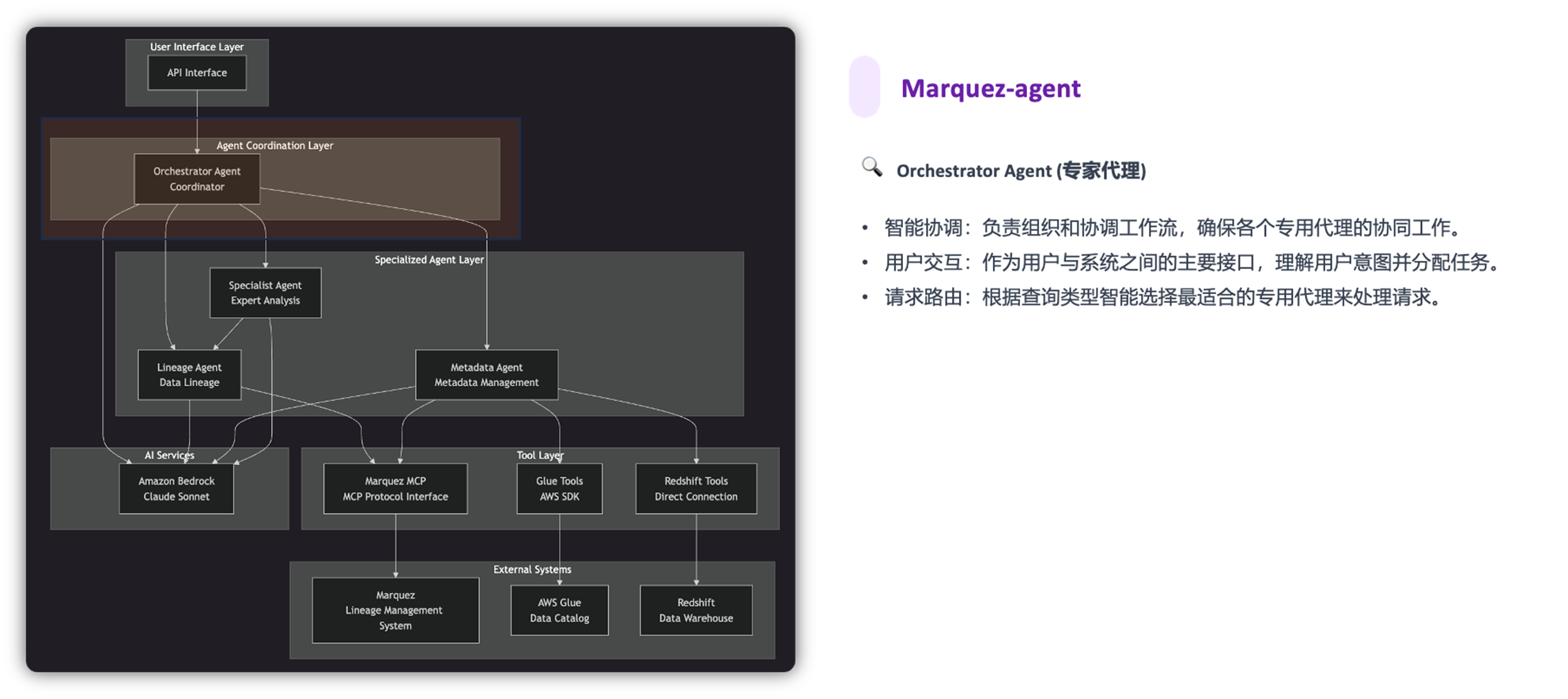
最后,AI 应用层以服务的方式(Marquez Agent 和 Marquez MCP Server)赋予血缘AI的能力。
Marquez-agent @ Claude Sonnet 4.0 提供以下功能:
 |
 |
 |
 |
Marquez API 服务器基于 FastMCP 框架构建,利用该框架可以快速搭建 MCP 服务器。
整体效果
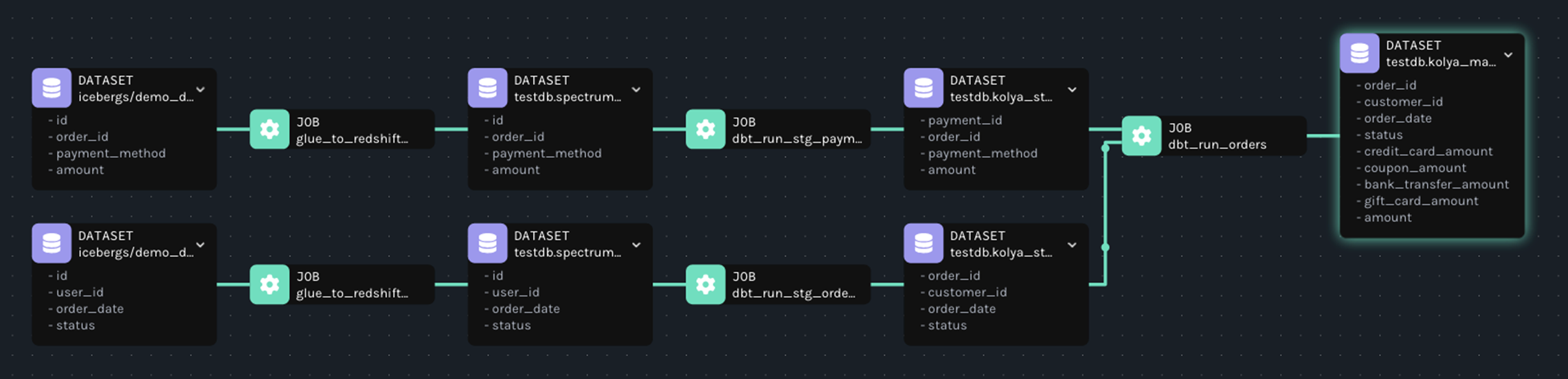
首先,我们回顾下测试数据集,s3存储桶中为客户入湖的源数据,经过glue spark作业清洗完后以iceberg形式写入另外一个s3存储桶中,这些iceberg表成为redshift的外部表,dbt ELT作业分层计算,将结果写入不同层级。整个ETL流程是跨平台的,即便如此,我们希望任何一个血缘问题都是贯穿完整的数据管道。
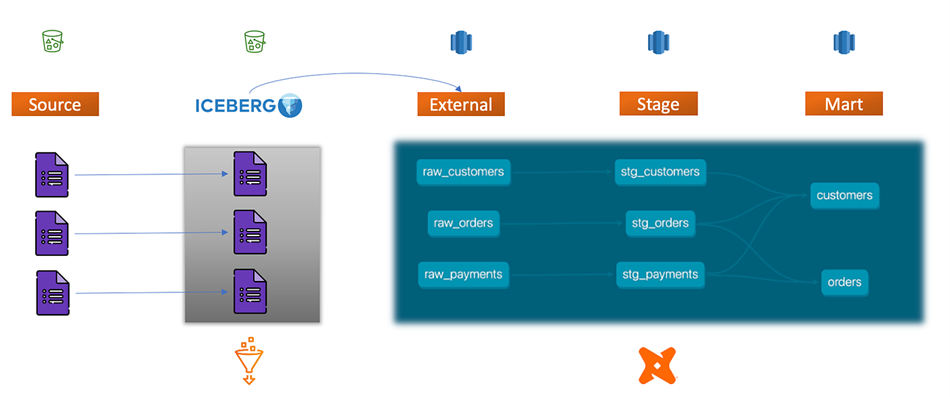 |
我们期待上述端到端的血缘能被清晰的捕获,而且能达到字段级别。
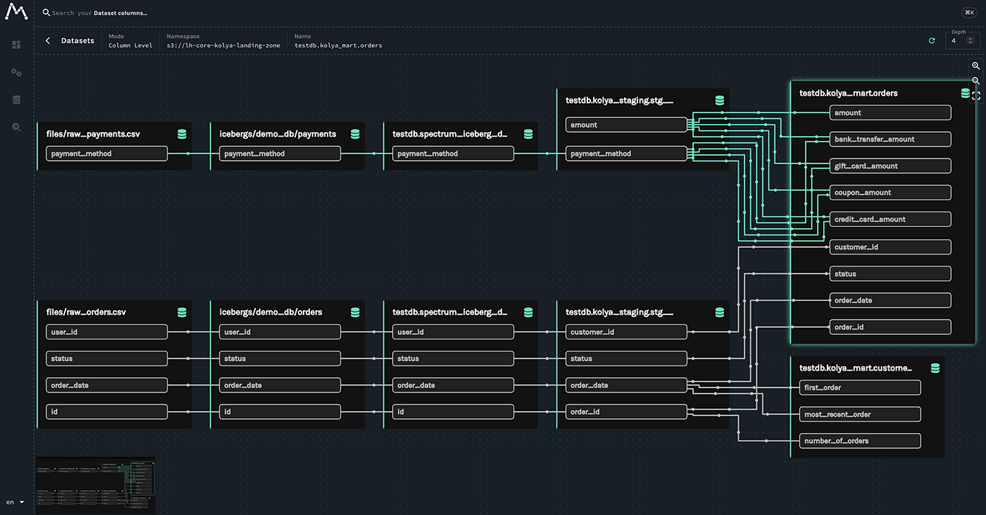 |
此外,我们能够轻松定位字段上游依赖,如下图:
 |
同时,我能够评估表字段变更对下游的影响。
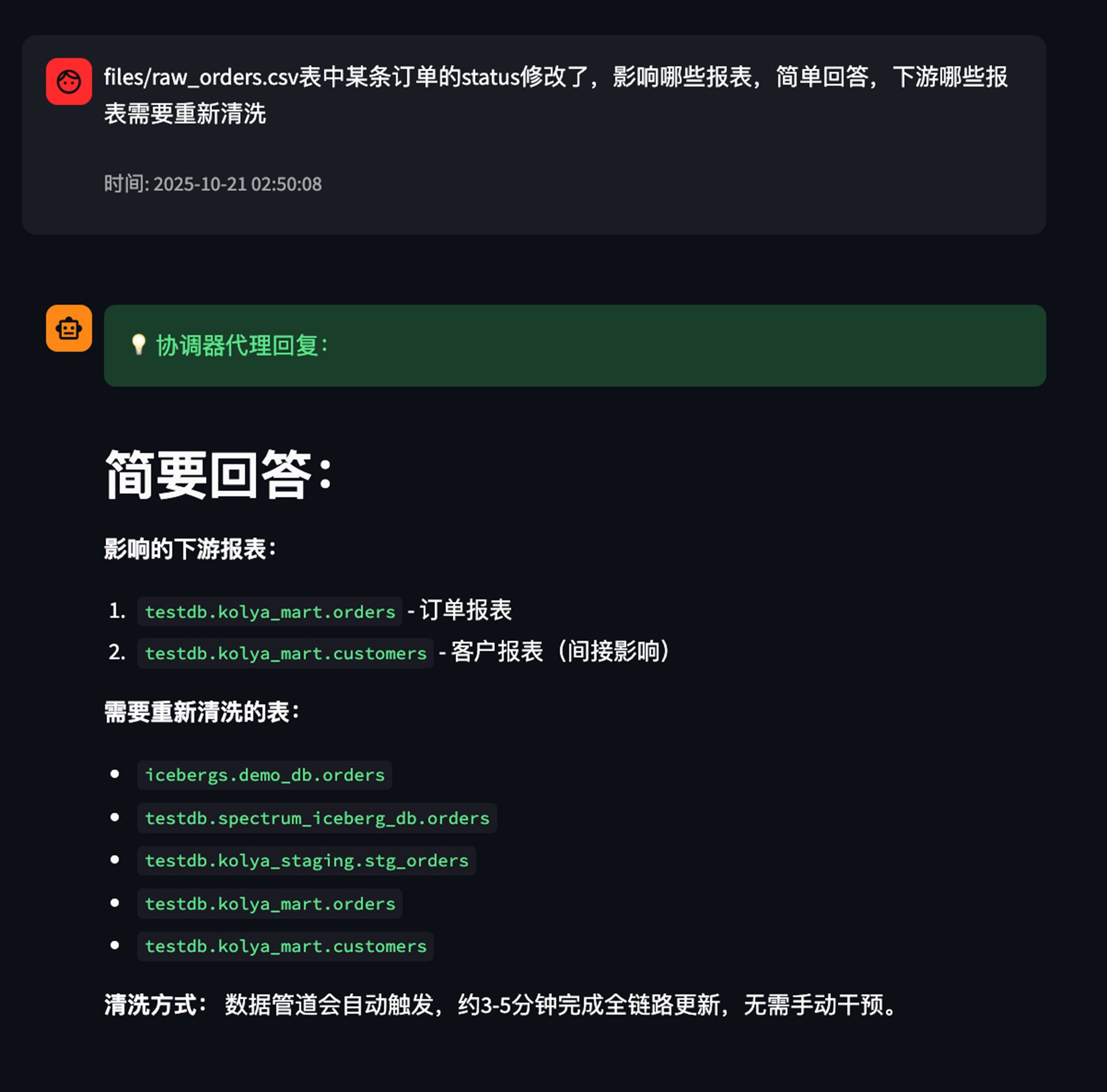 |
最后,血缘分析报告用于展示数据匹配、未匹配情况、以及数据血缘的异常状态。它通过追踪数据的上下游依赖关系,帮助用户监控数据质量和数据管道的健康状态,确保数据生产的准确性和时效性。
 |
注意事项
- GitHub 代码仓库:sample-agentic-data-lineage
- 样例数据模型与模式结构,来源于 dbt-labs/jaffle-shop-classic
- Dbt-colibri: A lightweight, developer-friendly CLI tool and self-hostable dashboard for extracting and visualizing column-level lineage from your dbt projects.
- 仅供概念验证(POC)使用,不适用于生产环境
*前述特定亚马逊云科技生成式人工智能相关的服务目前在亚马逊云科技海外区域可用。亚马逊云科技中国区域相关云服务由西云数据和光环新网运营,具体信息以中国区域官网为准。
本篇作者
AWS 架构师中心:云端创新的引领者探索 AWS 架构师中心,获取经实战验证的最佳实践与架构指南,助您高效构建安全、可靠的云上应用
|
 |
