Amazon EMR 是一个托管集群平台,可简化在 AWS 上运行大数据框架(如 Apache Hadoop 和 Apache Spark)以处理和分析海量数据的操作。借助这些框架和相关的开源项目 (如 Apache Hive 和 Apache Pig)。您可以处理用于分析目的的数据和商业智能工作负载。此外,您可以使用 Amazon EMR 转换大量数据和将大量数据移入和移出其他 AWS 数据存储和数据库,如 Amazon S3 或 Amazon DynamoDB等。
以前,在EMR单主节点的情况下,会有单点失败的问题。当主节点出现故障时,整个集群会被终止,从而导致正在运行的任务执行失败。今天,我们很高兴地告诉您:EMR在5.23.0的版本上推出了高可用(High Availability)的功能。您现在可以启动一个带有三个主节点的EMR集群,来实现多个应用的高可用,包括:YARN Resource Manager, HDFS Name Node,HBase,Hive,Spark和Ganglia等。当active的主节点出现故障时,比如Resource Manager或Name Node崩溃,EMR会自动切换到standby的主节点,新的主节点会保留和之前主节点相同的配置和引导操作(boot-strap actions)。
阅读本文,您将会了解到:
- 如何启用一个高可用(HA)的EMR集群
- HDFS HA的工作原理和配置变化
- Yarn Resource Manager HA的工作原理和配置变化
- 如何验证EMR的HA
- 如何监控EMR的HA
如何启用一个高可用的EMR集群
1.登陆到EMR的控制台,创建集群,点击“转到高级选项”
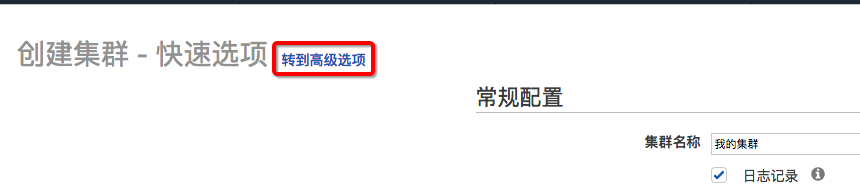
2.确保EMR的版本为23.0,勾选需要的服务组件,勾选“启用多主控支持”
注:如果集群配置了Hive,Hive HA要求使用外部表元数据,所以建议在下面的“AWS Glue Data Catalog设置”部分,勾选“用于Hive表元数据”

3.在硬件配置页,可以看到主节点数目已经是3个,选择合适的实例类型以及核心节点和任务节点数量。为了保证核心节点的高可用,官方建议是启动至少4个核心节点

4.点击下一步,按照向导配置对应参数,完成后点击“创建集群”。集群启动后,可以看到在集群的配置信息中已经有三个主节点的DNS域名列表
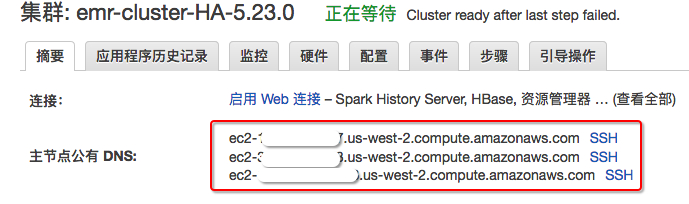
如何确认一个集群是否启用了HA?
在EMR控制台中,选中要查看的集群,在“摘要”选项卡中的【网络和硬件】部分,如果主实例个数显示为3,表面该集群启用了HA

注意:
目前,我们还不能为一个正在运行的EMR集群启用HA
HDFS HA的工作原理和配置变化
【工作原理】
在一个高可用的EMR集群中, HDFS Name Node运行在三个主节点中的其中两个。一个为active状态,另一个为 standby状态。当active的Name Node出现故障时,standby的Name Node会变为active并接管所有客户端的操作。EMR会启用一个新的主节点将故障的Name Node替换,并设为standby状态。
您可以SSH登陆到任一台主节点上,运行如下命令来查看active/standby 的Name Node:
hdfs haadmin -getAllServiceState
输出示例如下:
ip-##-#-#-##1.us-west-2.compute.internal:8020 active
ip-##-#-#-##2.us-west-2.compute.internal:8020 standby
EMR HDFS 高可用的实现是使用Quorum Journal Manager(QJM)。这里引入一个概念是JournalNodes(JNs),这是一组独立的Daemon来负责主备Name Node的状态信息同步。active的Name Node会将HDFS文件系统的所有更新操作写入到JournalNodes,standby的Name Node会持续观察JournalNodes的编辑日志(edit log),并将这些操作实时地更新到自己的命名空间。同时,JournalNodes还能保证同一时间只允许一个Name Node来写,避免“脑裂”导致的状态不一致和数据丢失。
【配置变化】
通过查看HDFS配置文件, 我们可以看到在hdfs-site.xml配置文件中有如下新增或更新的属性:
- ha.namenodes.ha-nn-uri (主备Name Node的id)
- namenode.rpc-address.ha-nn-uri.xxx(主备Name Node的RPC地址)
- namenode.https-address.ha-nn-ur.xxx (主备Name Node的HTTP地址)
- namenode.shared.edits.dir(JournalNodes的地址组)
- client.failover.proxy.provider.xxx(HDFS客户端来获取active Name Node的java类)
- ha.fencing.methods (在自动故障转移时用于隔离active Name Node的脚本或java类)
示例如下:
<property>
<name>dfs.ha.namenodes.ha-nn-uri</name>
<value>nn1,nn2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.ha-nn-uri.nn1</name>
<value>ip-172-31-3-61.us-west-2.compute.internal:8020</value>
</property>
<property>
<name>dfs.namenode.https-address.ha-nn-uri.nn1</name>
<value>ip-172-31-3-61.us-west-2.compute.internal:50470</value>
</property>
……
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://ip-172-31-3-61.us-west-2.compute.internal:8485;ip-172-31-7-112.us-west-2.compute.internal:8485;ip-172-31-10-171.us-west-2.compute.internal:8485/ha-nn-uri</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.ha-nn-uri</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>shell(/bin/true)</value>
</property>
另外,在hdfs-site.xml和core-site.xml配文件中,新增加了如下2个属性,表明启用了自动故障转移:
- ha.automatic-failover.enabled
- zookeeper.quorum
示例如下:
hdfs-site.xml:
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
core-site.xml:
<property>
<name>ha.zookeeper.quorum</name>
<value>ip-172-31-3-61.us-west-2.compute.internal:2181,ip-172-31-7-112.us-west-2.compute.internal:2181,ip-172-31-10-171.us-west-2.compute.internal:2181</value>
</property>
关于EMR HDFS高可用实现的更多信息,您可以参考此链接。
Yarn Resource Manager HA的工作原理和配置变化
【工作原理】
与HDFS不同的是,Yarn ResourceManager(RM)运行在所有的三个主节点上。其中,一个RM是active状态,另外两个是standby状态。当active的RM出现故障时,EMR会进行自动故障转移,将其中一个standby节点变为新的active来接管所有操作。之后EMR会将出现故障的master 节点替换,并设为standby状态。
您可以SSH登陆到任一台主节点上,运行如下命令来查看当前的active/standby RM:
yarn rmadmin -getAllServiceState
输出示例如下:
ip-##-#-#-##1.us-west-2.compute.internal:8033 standby
ip-##-#-#-##2.us-west-2.compute.internal:8033 standby
ip-##-#-#-##3.us-west-2.compute.internal:8033 active
EMR RM的HA使用了RM Restart的功能,在RM发生故障自动恢复后,新的active RM会从内部的状态存储中尽力读取之前active RM留下的状态信息,将未完成的应用继续运行。EMR目前使用的是基于zookeeper的状态存储(ZooKeeper based state-store),该存储能够支持隔离机制(fencing mechanism),确保任何时间点只有一个RM去写状态存储,避免“脑裂”的发生。
【配置变化】
与HDFS HA类似,通过查看yarn的配置文件,我们可以看到在yarn-site.xml配置文件中,有如下新增或更新的属性:
- resourcemanager.ha.automatic-failover.enabled (启用HA)
- resourcemanager.ha.rm-ids (高可用的RM id列表)
- resourcemanager.hostname.xx(RM hostname列表)
- resourcemanager.xxx.address.xx(RM web,管理等地址列表)
- resourcemanager.recovery.enabled(启用RM Recovery的功能)
- resourcemanager.store.class(指定RM使用基于zookeeper的状态存储)
- resourcemanager.zk-address (ZK-quorum的地址,用于状态存储和嵌入式领导选举)
示例如下:
<property>
<name>yarn.resourcemanager.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2,rm3</value>
</property>
…..
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>ip-172-31-9-76.us-west-2.compute.internal:8088</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>172.31.9.76</value>
</property>
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>ip-172-31-9-76.us-west-2.compute.internal:2181,ip-172-31-3-219.us-west-2.compute.internal:2181,ip-172-31-4-251.us-west-2.compute.internal:2181</value>
</property>
关于EMR RM HA的更多信息,您可以参考此链接。
如何验证EMR的HA
以ResourceManager为例,我们分别验证在没有任何job和有job运行时的自动故障转移。
没有job时RM故障转移:
1.查看当前RM的高可用状态,active的RM是地址为172.31.7.112的实例
[hadoop@ip-172-31-7-112 hadoop-yarn]$ yarn rmadmin -getAllServiceState
ip-172-31-3-61.us-west-2.compute.internal:8033 standby
ip-172-31-7-112.us-west-2.compute.internal:8033 active
ip-172-31-10-171.us-west-2.compute.internal:8033 standby
2.将RM进程停止,然后启动
[hadoop@ip-172-31-7-112 hadoop-yarn]$ sudo stop hadoop-yarn-resourcemanager
hadoop-yarn-resourcemanager stop/waiting
[hadoop@ip-172-31-7-112 hadoop-yarn]$ sudo start hadoop-yarn-resourcemanager
hadoop-yarn-resourcemanager start/running, process 5608
3.再次查看RM状态,我们可以看到active的RM已经切换为172.31.10.171这台实例
[hadoop@ip-172-31-7-112 hadoop-yarn]$ yarn rmadmin -getAllServiceState
ip-172-31-3-61.us-west-2.compute.internal:8033 standby
ip-172-31-7-112.us-west-2.compute.internal:8033 standby
ip-172-31-10-171.us-west-2.compute.internal:8033 active
在job运行时RM自动故障转移:
我们运行一个示例的hive job,该job会创建一个基于s3的hive表,并将样例数据(CloudFront日志)做聚合查询,统计出每种OS的请求数。您可以通过直接运行如下命令来提交示例的hive job:
aws emr add-steps --cluster-id <your cluster id> --steps Type=HIVE,Name='Caculate number of request per OS',ActionOnFailure=CONTINUE,Args=[-f,s3://us-west-2.elasticmapreduce.samples/cloudfront/code/Hive_CloudFront.q,-d,INPUT=s3://us-west-2.elasticmapreduce.samples,-d,OUTPUT=s3://your/s3/output/path] --region us-west-2
注意:请确保您具有运行EMR step相关的IAM权限,<your cluster id>填写您的EMR cluster id,s3://your/s3/output/path替换为您S3的路径,作为hive查询结果的数据输出路径,region与您EMR cluster所启用的region保持一致。
1.首先,查看当前active 的RM是172.31.10.171:
[hadoop@ip-172-31-10-171 ~]$ yarn rmadmin -getAllServiceState
ip-172-31-3-61.us-west-2.compute.internal:8033 standby
ip-172-31-7-112.us-west-2.compute.internal:8033 standby
ip-172-31-10-171.us-west-2.compute.internal:8033 active
2.运行以上hive job,当观察到step处于running状态后,通过EC2控制台或AWS cli将172.31.10.171这台实例终止(注意在终止前需要禁用终止保护:选择实例,点击 操作 -》实例设置-》更改终止保护,点击请禁用 )。

3.随后,可以观察到EMR自动启动一台新的实例作为standby 的主节点。新的主节点仍然沿用之前节点的private IP地址,以确保各个节点间的正常通信,但public IP地址会发生改变。
4.Step继续运行直到成功,查看S3对应路径下有如下预期的结果:
Android855
Linux813
MacOS852
OSX799
Windows883
iOS794
在新的active RM上,我们可以看到在RM故障转移时有类似如下的日志,它首先检查是否有旧的active RM需要隔离,然后切换到active状态,并从RMStateStore中读取所有application的状态,将未完成的application继续运行:
2019-06-02 06:05:24,078 INFO org.apache.hadoop.ha.ActiveStandbyElector (main-EventThread): Checking for any old active which needs to be fenced...
2019-06-02 06:05:24,079 INFO org.apache.hadoop.ha.ActiveStandbyElector (main-EventThread): No old node to fence
2019-06-02 06:05:24,079 INFO org.apache.hadoop.ha.ActiveStandbyElector (main-EventThread): Writing znode /yarn-leader-election/ha-rm-uri/ActiveBreadCrumb to indicate that the local node is the most recent active...
…………..
2019-06-02 06:05:24,125 INFO org.apache.hadoop.yarn.server.resourcemanager.ResourceManager (main-EventThread): Transitioning to active state
2019-06-02 06:05:24,142 INFO org.apache.hadoop.yarn.server.resourcemanager.ResourceManager (main-EventThread): Recovery started
2019-06-02 06:05:24,142 INFO org.apache.hadoop.util.JvmPauseMonitor (org.apache.hadoop.util.JvmPauseMonitor$Monitor@47f6f422): Starting JVM pause monitor
2019-06-02 06:05:24,144 INFO org.apache.hadoop.yarn.server.resourcemanager.recovery.RMStateStore (main-EventThread): Loaded RM state version info 1.3
…
2019-06-02 06:05:25,482 INFO org.apache.hadoop.yarn.server.resourcemanager.rmapp.RMAppImpl (main-EventThread): Recovering app: application_1559362602877_0014 with 1 attempts and final state = null
需要注意的是,新的active 的RM会尽力恢复之前job的状态信息,但仍有一定概率job会失败(比如中间数据丢失),这种情况建议您重新运行job。
5.再次查看当前的active 的ResourceManager,可以看到active的已经切换到172.31.3.61这台实例。至此,高可用验证完成。
[hadoop@ip-172-31-10-171 ~]$ yarn rmadmin -getAllServiceState
ip-172-31-3-61.us-west-2.compute.internal:8033 active
ip-172-31-7-112.us-west-2.compute.internal:8033 standby
ip-172-31-10-171.us-west-2.compute.internal:8033 standby
如何监控EMR高可用状态
EMR提供了三个新的CloudWatch指标来监控集群的高可用状态:
- MultiMasterInstanceGroupNodesRunning
- MultiMasterInstanceGroupNodesRunningPercentage
- MultiMasterInstanceGroupNodesRequested
您可以监控running的主节点数量,当主节点数低于3个时,设置告警,通知主节点的故障转移事件。举例如下:
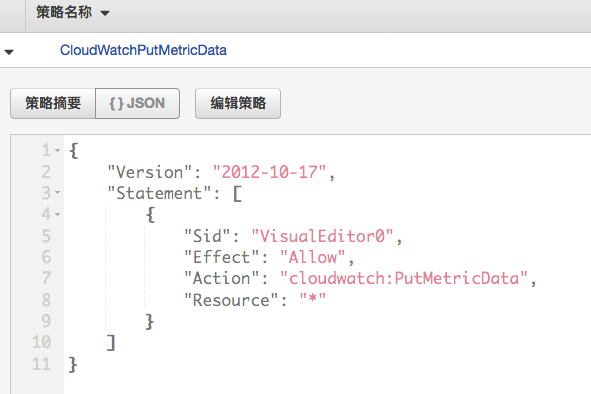
1.首先确认您的EMR_DefaultRole有CloudWatch PutMetricData的权限(需在23.0的版本做此配置,后续版本可能做调整)
2.在Cloudewatch控制面板找到您EMR集群的MultiMasterInstanceGroupNodesRunning指标,创建告警:周期选择1分钟,条件是小于3时触发告警。

3.点击下一步,配置发送通知和接收告警的电子邮件列表。
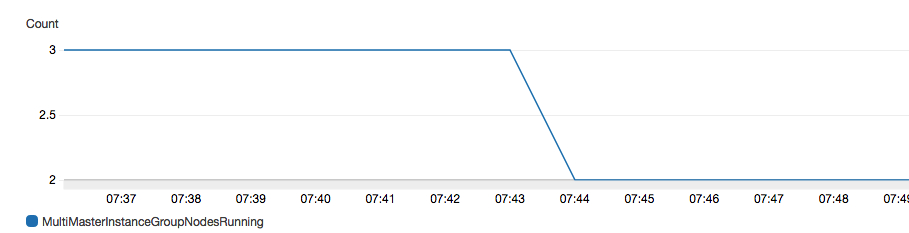
4.告警配置完成后,通过手工终止active的主节点来触发告警。我们可以看到,active的主节点终止后,MultiMasterInstanceGroupNodesRunning从3变为2,同时告警控制面板有告警产生(如果配置了接收邮件列表,则会收到告警邮件)。

5.当EMR启动新的主节点并provision完成后,告警回到正常状态。

关于EMR配置告警的更多信息,您可以参考此链接。
综述,从5.23.0版本开始,当您为EMR启用了高可用之后,对于需要长期运行的EMR集群,主节点宕机将不会导致整个集群失效,从而保证了业务的连续性。现在,就去启动您的高可用EMR集群吧。
关于EMR高可用的更多信息,您可以参考此链接。
本篇作者