亚马逊AWS官方博客
Amazon EMR 迁移指南
Original URL: https://amazonaws-china.com/blogs/big-data/amazon-emr-migration-guide/
世界各地的企业逐渐认识到新型大数据处理和分析框架(如 Apache Hadoop 和 Apache Spark)的强大功能,但同时也发现在本地数据湖环境中运行这些技术面临着挑战。他们也对当前供应商的未来表示担忧。
为了解决这个问题,我们推出了 Amazon EMR 迁移指南(注:英文版首次出版于 2019 年 6 月,这是我们首次推出中文版)。 本文是一份全面的指南,旨在提供合理的技术建议,帮助客户规划如何从本地大数据部署迁移到 EMR。
本地大数据环境的常见问题包括缺乏敏捷性、成本过高和管理难题,IT 组织都在全力配置资源、大规模处理不均衡的工作负载并跟上快速变化的社区驱动型开源软件创新的步伐。很多大数据计划因评估、选择、采购、接收、部署、集成、配置、修补、维护、升级和支持底层硬件和软件基础架构而受到延迟并加重负担。
一个较为微妙但同样重要的问题是,公司数据中心部署 Apache Hadoop 和 Apache Spark 的方式是直接将计算和存储资源绑定在同一服务器中,因此必须采用锁步操作进行扩展,导致创建的模型并不灵活。这意味着几乎任何本地环境都要为大量未充分利用的磁盘容量、处理能力或系统内存支付费用,因为每个工作负载对这些组件具有不同的要求。 典型工作负载在不同类型的集群上以不同的频率和时间运行。应释放这些大数据工作负载,以便在最高效的情况下运行,同时访问相同的共享底层存储或数据湖。如下图 1 所示。
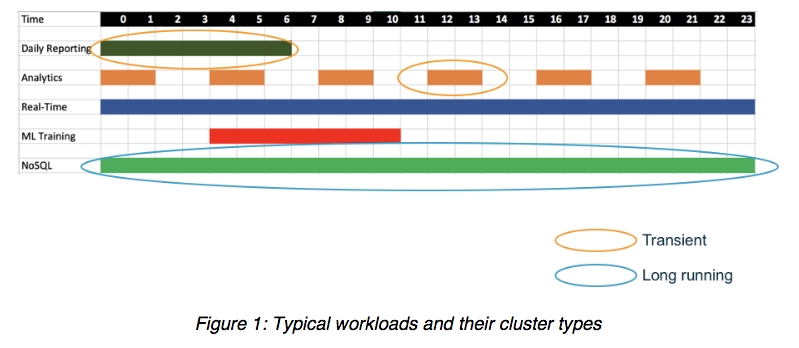
智慧企业如何通过大数据计划获得成功? 将大数据(和机器学习)迁移到云具有多种优势。AWS 等云基础架构服务提供商提供了广泛的按需和弹性计算资源选择、富有灵活性且价格低廉的持久存储以及提供最新、熟悉的环境来开发和操作大数据应用程序的托管服务。数据工程师、开发人员、数据科学家和 IT 人员可以集中精力准备数据和提取有价值的洞察。
Amazon EMR、AWS Glue 和 Amazon S3 等服务使您能够独立解耦和扩展计算和存储,同时提供集成、管理完善和高度弹性的环境,直接减少了本地方法存在的诸多问题。这种方法可实现更快、更敏捷、更易于使用和更经济高效的大数据和数据湖计划。
但传统的本地 Apache Hadoop 和 Apache Spark 的传统观念并不总是基于云的部署中的最佳策略。采用简单的直接迁移方法在云中运行集群节点,这种方法从概念上来说很简单,但在实践中并非最佳。在将大数据迁移到云架构时,不同的设计决策有助于最大限度地提高您的收益。
本指南提供了下列最佳实践:
- 迁移数据、应用程序和目录
- 使用持久和瞬态资源
- 配置安全策略、访问控制和审计日志
- 估算和最小化成本,同时最大化价值
- 利用 AWS 云实现高可用性 (HA) 和灾难恢复 (DR)
- 自动执行常见的管理任务
虽然本指南并非用来替代专业服务,但它涵盖了广泛的常见问题,以及将大数据和数据湖计划迁移到云的场景。
在开启将大数据平台迁移到云的旅程时,必须先决定如何进行迁移。一种方法是重新架构您的平台,以最大限度地利用云的优势。另一种方法称为直接迁移,采用现有架构并直接迁移到云。最后一种方案是混合方法,将直接迁移与重新架构相结合。做出这个决定并不容易,因为每种方法各有优缺点。
直接迁移方法通常更为简单,歧义更少,风险更小。此外,如果工期紧迫,比如说您的数据中心租约快到期时,这种方法更好。但直接迁移的缺点是,它并不总是最经济有效的,并且现有体系结构可能不容易映射到云中的解决方案。
重新架构具有很多优势,包括成本和效率的优化。通过重新架构,您可以迁移到最新最好的软件,更好地与原生云工具集成,并利用原生云产品和服务来减轻运营负担。
本文从 Apache Spark 和 Hadoop 生态系统的角度介绍了每种迁移方法的优缺点。如要阅读本文,请立即下载 Amazon EMR 迁移指南 (中文版)。
有关确定哪种方法最适合您的工作流程的通用资源,请参阅适合您企业的云最佳实践电子书,其中概述了在更高级别执行迁移到云的最佳实践。
关于作者
 Nikki Rouda 是 AWS 数据湖和大数据的首席产品营销经理。20 多年来,Nikki 一直帮助 40 多个国家或地区的企业开发和实施解决方案,来应对分析和 IT 基础架构挑战。Nikki 拥有剑桥大学的 MBA 学位和布朗大学的地球物理和数学学士学位。
Nikki Rouda 是 AWS 数据湖和大数据的首席产品营销经理。20 多年来,Nikki 一直帮助 40 多个国家或地区的企业开发和实施解决方案,来应对分析和 IT 基础架构挑战。Nikki 拥有剑桥大学的 MBA 学位和布朗大学的地球物理和数学学士学位。