亚马逊AWS官方博客
Amazon SageMaker Ground Truth — 构建高度准确的数据集并将添加标签的成本最高降低 70%
1959 年,Arthur Samuel 将机器学习定义为“让计算机能够无需明确编程而进行学习的研究领域”。但世界上没有“机器神”:学习过程需要算法(“如何学习”)和训练数据集(“学习什么”)。
今天,大部分机器学习任务都使用一种被称为监管学习的方法:通过一种算法从带标签的数据集中学习模式或行为。带标签的数据集包含数据样本以及每个样本的准确答案,也就是“地面实况”。根据所拥有的问题不同,人们可以使用带标签的图像(“这是一只狗”、“这是一只猫”)、带标签的文本(“这是垃圾邮件”、“这不是”)等等。
幸运的是,开发人员和数据学家现在可以借助十分广泛的现成算法(如 Amazon SageMaker 中的内置算法所演示)和参考数据集。深度学习让 MNIST、CIFAR-10 或 ImageNet 等图像数据集普及起来,机器翻译或文本分类等任务的参考数据集更多。这些参考数据集对于初学者和经验丰富从业者都极为有用,但许多公司和组织仍然需要依据自己的数据集进行机器学习模型训练:例如医学影像识别、汽车驾驶等。
构建此类数据集是一个复杂的问题,尤其是涉及的规模很大时。让一个人为一千张图像或文档加标签要花费多少时间? 答案也许是“相当长”! 而现在需要为一百万张图像或文档添加标签:您将需要多少人来完成? 对于大多数公司和组织而言,这是争议问题,因为他们从来都不能聚集到足够的人手。
好吧,不扯远了! 今天,我很高兴地宣布推出 Amazon SageMaker Ground Truth,这是 Amazon SageMaker 的一个新功能,可方便客户高效准确地为机器学习系统训练所需的数据集添加标签。
隆重推出 Amazon SageMaker Ground Truth
Amazon SageMaker Ground Truth 可帮助您为下列目的构建数据集:
- 文本分类。
- 图像分类,即将图像分类为特定的类别。
- 对象检测,即使用边界框找到图像中的对象。
- 语义分割,即以像素级的精确度找到图像中的对象。
- 用户自定义任务。
Amazon SageMaker Ground Truth 可以选择使用主动学习功能来自动为输入的数据添加标签。主动学习是一种机器学习方法,它会识别需要人工添加标签的数据以及可以由机器添加标签的数据。自动化添加数据标签将会发生 Amazon SageMaker 训练和推理费用,但与人工为整个数据集添加标签相比,它可以降低为数据集添加标签的成本(最高可减少 70%)和时间。
如果需要人工干预,您可以选择使用有 500000 劳动力的 Amazon Mechanical Turk 众包服务、您自己的工人或者 AWS Marketplace 上列出的推荐第三方供应商。
下面我们来看为数据集添加标签的简要步骤:
- 将数据存储到 Amazon S3;
- 创建添加标签劳动力;
- 创建添加标签作业;
- 开始工作;
- 显示结果。
举个例子? 下面我来演示为来自 CBCL StreetScenes 数据集的图像添加标签的例子。此数据集包含 3548 张这样的图像。为简单起见,我仅使用前 10 张图像并仅标注汽车。

将数据存储到 Amazon S3
第一步是为该数据集创建一个 manifest 文件。这是一个简单的 JSON 文件,列举了数据集中存在的所有图像。我的文件是下面这个样子:请注意每行对应一个对象,这是一个独立的 JSON 文档。
{"source-ref": "s3://jsimon-groundtruth-demo/SSDB00001.JPG"}
{"source-ref": "s3://jsimon-groundtruth-demo/SSDB00002.JPG"}
{"source-ref": "s3://jsimon-groundtruth-demo/SSDB00003.JPG"}
{"source-ref": "s3://jsimon-groundtruth-demo/SSDB00004.JPG"}
{"source-ref": "s3://jsimon-groundtruth-demo/SSDB00005.JPG"}
{"source-ref": "s3://jsimon-groundtruth-demo/SSDB00006.JPG"}
{"source-ref": "s3://jsimon-groundtruth-demo/SSDB00007.JPG"}
{"source-ref": "s3://jsimon-groundtruth-demo/SSDB00008.JPG"}
{"source-ref": "s3://jsimon-groundtruth-demo/SSDB00009.JPG"}
{"source-ref": "s3://jsimon-groundtruth-demo/SSDB00010.JPG"}然后,我会直接将 manifest 文件和对应的图像复制到一个 Amazon S3 存储桶。
创建添加标签劳动力
Amazon SageMaker Ground Truth 为我们提供了多种选项:
- Amazon Mechanical Turk 支持的公共劳动力;
- 内部资源组成的私人劳动力;
- 第三方供应商提供的供应商劳动力。
第一个选项也许是可扩展性最好的方案。但如果您的作业要求保密、服务保证或特殊的技能,后两个选项也许更为适合。
此例中我只能依赖自己,因此我创建了一个使用新的 Amazon Cognito 组来进行身份验证的私人团队。实际上,任何劳动者访问数据集前都必须通过身份验证。
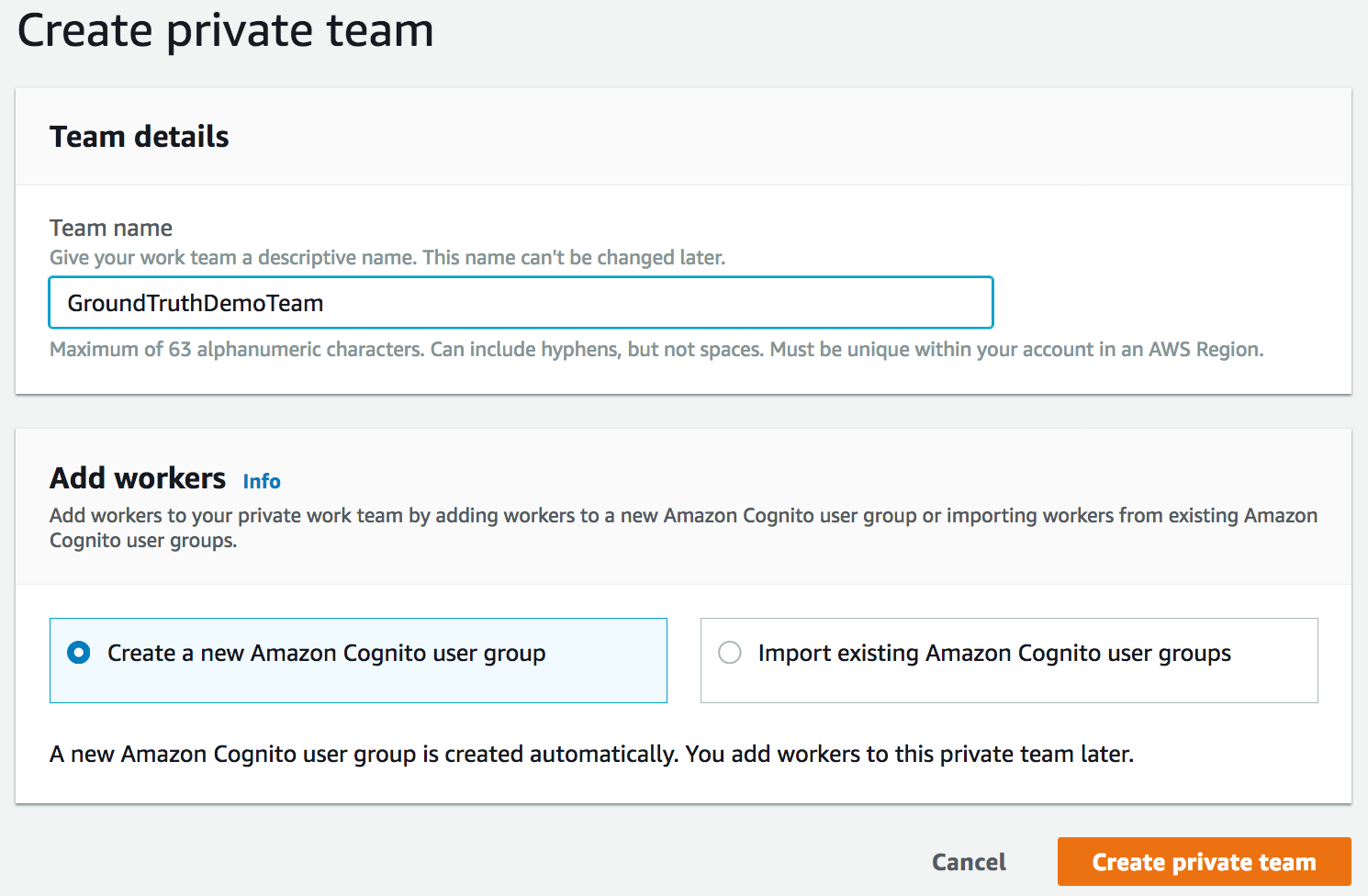
然后我输入我的电子邮件地址,将自己添加到该团队。几秒钟后,我收到一条包含凭证和一个 URL 的邀请信。此 URL 也可以在添加标签劳动力控制面板上看到。

当我点击链接并修改密码后,我将被注册为此团队的认证劳动者。

现在这个一人的团队已经成立,可以创建添加标签作业本身。
创建添加标签作业
正如您所预期的那样,我必须指定 manifest 文件和数据集的位置。
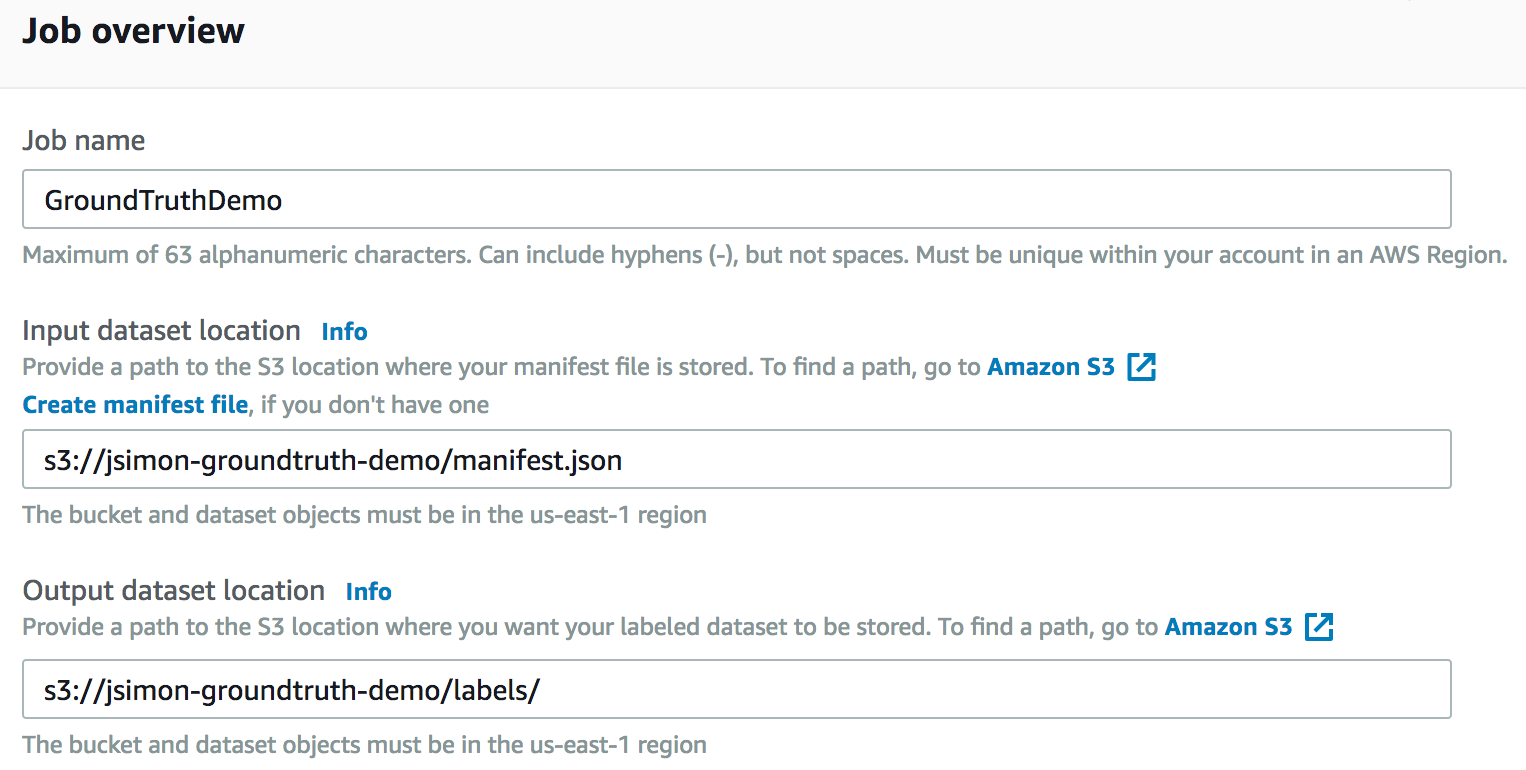
然后我可以决定是要使用完整的数据集还是使用子集:我甚至可以编写一个 SQL 查询来筛选文件。在此例中我们将使用完整的数据集,因为它仅包含 10 张图像。

然后我必须选择添加标签作业的类型。如前面所提到,这里有多种选项,此处我计划为我的图像添加边界框。
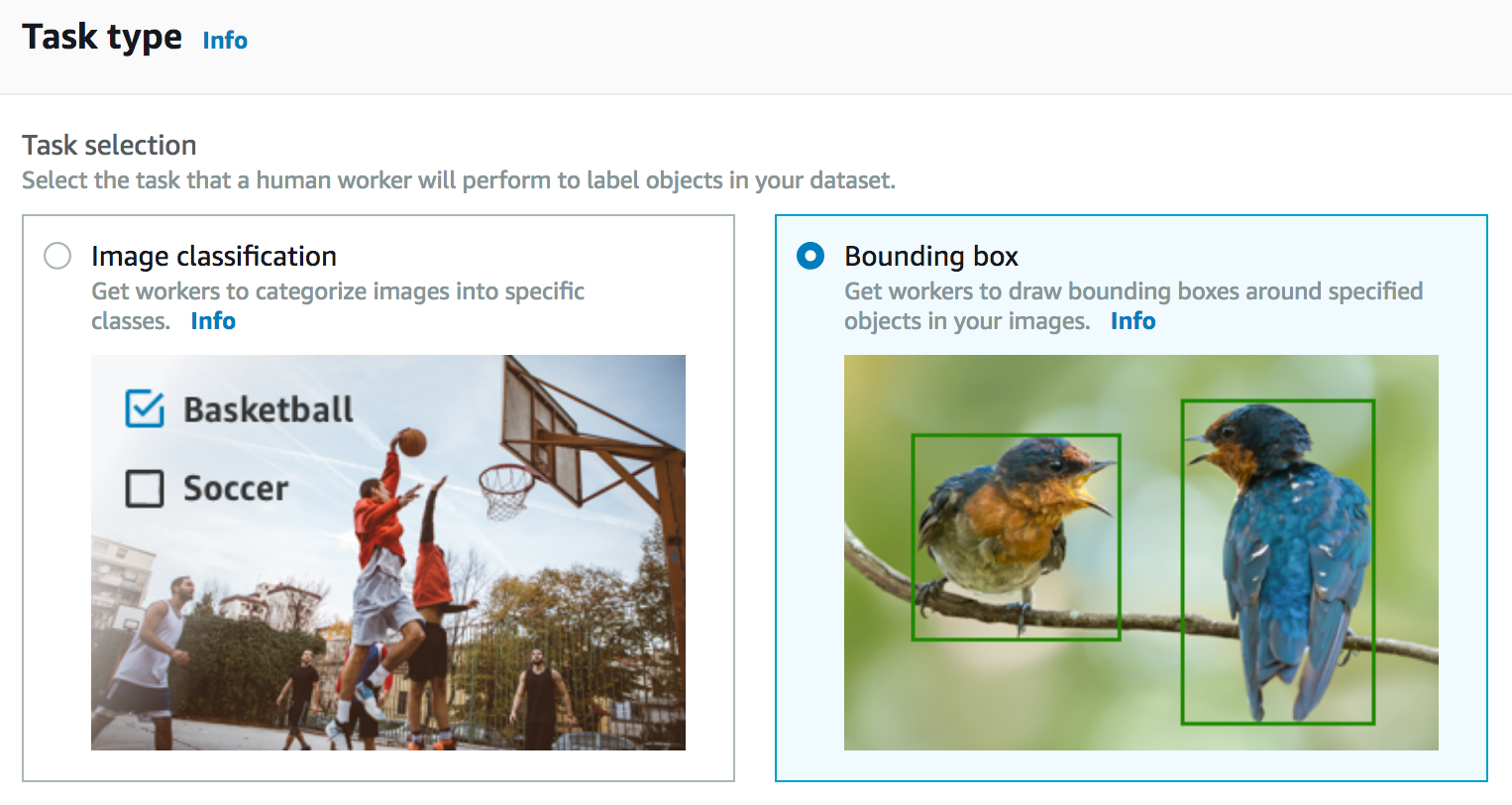
然后我会选择我希望为其分配此作业的团队。这就是我可以选择自动添加数据标签的地方。我还可以决定要求多个劳动者来为同一张图像添加标签,从而提高准确度。

最后,我可以为劳动者提供额外的指令,详细说明需要执行的具体任务,并他们提供一些示例。

一切搞定。我们的添加标签作业已经准备就绪。现在可以让团队(呃,好吧,就是我)开始工作。

为图像添加标签
登录我通过电子邮件收到的 URL,我将看到分配给我的作业列表。

当我单击“Start working(开始工作)”按钮,将看到说明以及需要处理的第一张图像。我可以使用工具箱执行画边框、放大缩小等操作。这相当直观,但要画出恰好吻合的边界框需要时间和细心。现在我知道为什么这是如此耗费时间了……幸好我只有十张图像需要处理!

下面是另一张图像的放大。您有没有看到所有七辆汽车?

当我处理完所有十张图像后,我可以好好休息一下,享受完成添加标签作业的成就感。

显示结果
标记后的图像可在 AWS 控制台中直接显示,非常方便进行完整性检查。我也可以点击任何图像,查看已经应用的标签列表。
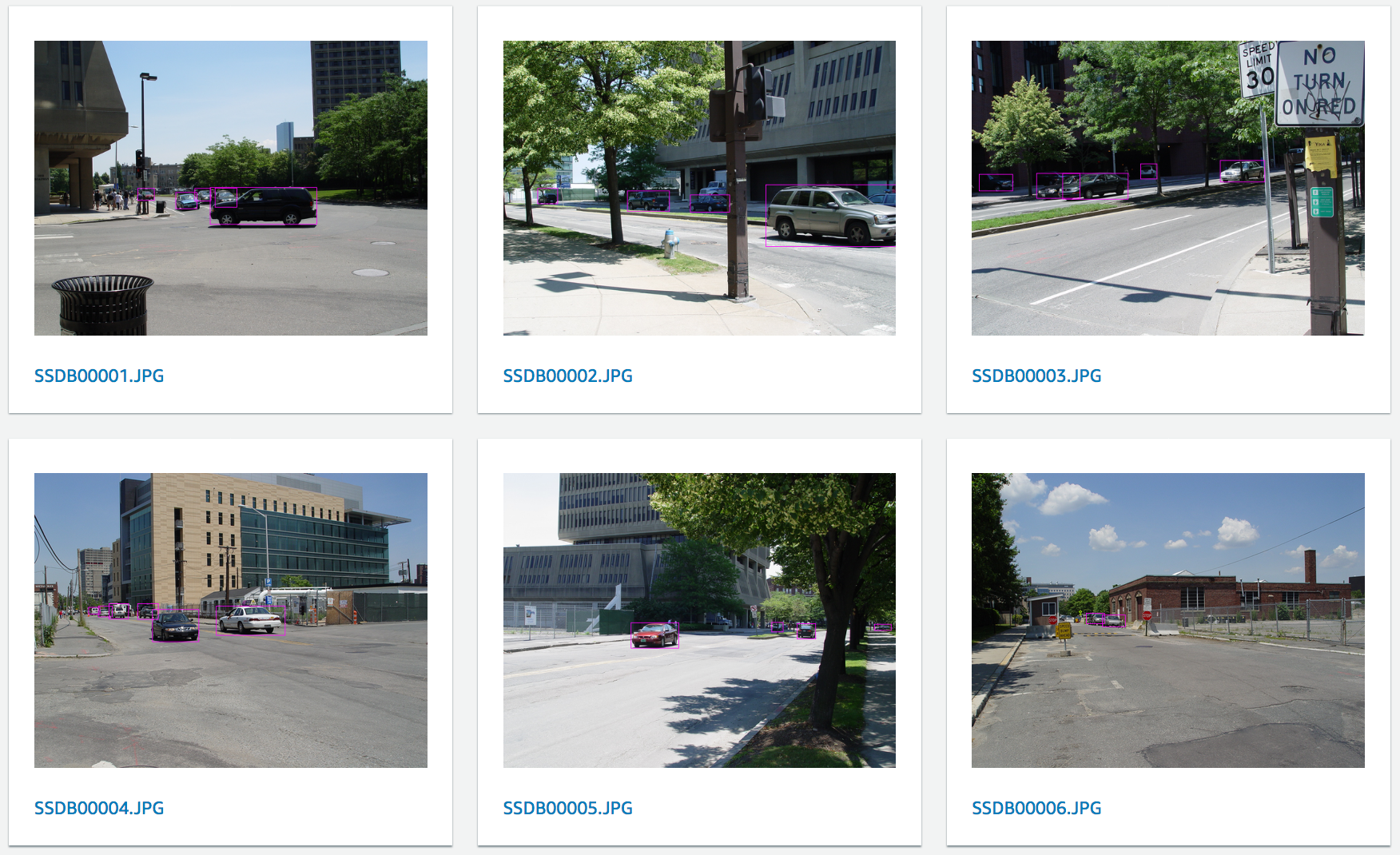
当然,我们的目的是使用此信息来训练机器学习模型:我们可以在存储桶中存储的增强 manifest 文件中找到它。例如,下面是 manifest 文件必须提供的有关第一张图像的信息,其中我添加了五辆汽车的标签。
{
"source-ref": "s3://jsimon-groundtruth-demo/SSDB00001.JPG",
"GroundTruthDemo": {
"annotations": [
{"class_id": 0, "width": 54, "top": 482, "height": 39, "left": 337},
{"class_id": 0, "width": 69, "top": 495, "height": 53, "left": 461},
{"class_id": 0, "width": 52, "top": 482, "height": 41, "left": 523},
{"class_id": 0, "width": 71, "top": 481, "height": 62, "left": 589},
{"class_id": 0, "width": 347, "top": 479, "height": 120, "left": 573}
],
"image_size": [{"width": 1280, "depth": 3, "height": 960}
]
},
"GroundTruthDemo-metadata": {
"job-name": "labeling-job/groundtruthdemo",
"class-map": {"0": "Car"},
"human-annotated": "yes",
"objects": [
{"confidence": 0.94},
{"confidence": 0.94},
{"confidence": 0.94},
{"confidence": 0.94},
{"confidence": 0.94}
],
"creation-date": "2018-11-26T04:01:09.038134",
"type": "groundtruth/object-detection"
}
}这样就拥有了训练对象检测模型所需的所有信息,例如 Amazon SageMaker 中内置的 Single-Shot Detector,但这是另一个主题!
现已推出!
我希望这篇博文提供了丰富的有用信息。我们刚刚介绍了 Amazon SageMaker Ground Truth 的强大功能。此服务现已在美国东部(弗吉尼亚)、美国中部(俄亥俄)、美国西部(俄勒冈)、欧洲(爱尔兰)和亚太地区(东京)等区域开放。您现在就可以体验一下,与我们分享您的想法!
— Julien;