一. 什么是数据血缘
数据血缘跟踪、记录、展示了数据来自何处,以及在数据流转过程中应用了哪些转换操作,它有助于追溯数据来源及处理过程。
数据血缘系统的核心功能:
- 数据资产的自动发现及创建
- 血缘关系的自动发现及创建
- 不同视角的血缘及资产分析展示
与数据血缘容易混淆的概念:数据起源。数据起源重点在于跟踪数据的原始来源,包括与数据相关的采集、规则、流程,以帮助数据工程师评估数据的质量。
二. Apache Atlas及其特性
Atlas 是一套可伸缩且可扩展的数据治理服务,使企业能够有效和高效地满足其在 Hadoop 生态中的合规要求,并允许与整个企业数据生态系统集成。
Atlas 为组织提供开放的元数据管理和治理能力,以建立其数据资产目录、对这些资产进行分类和管理,并为数据科学家、分析师和数据治理团队提供围绕这些数据资产的协作能力。
预定义的Hadoop及非Hadoop系统的元数据类型。
基于Rest API的类别及实体管理
类别及实体的自动捕获
血缘自动捕获
可探查的数据血缘展示
基于Rest API的数据血缘管理
可按数据资产类别,实体及属性的搜索
基于Rest API的复杂搜索
类SQL的搜索语言
元数据访问的细粒度管控。
与Apache Ranger集成,进行基于实体分类的授权及数据遮蔽。
类别自动发现
实体类别标签自动化
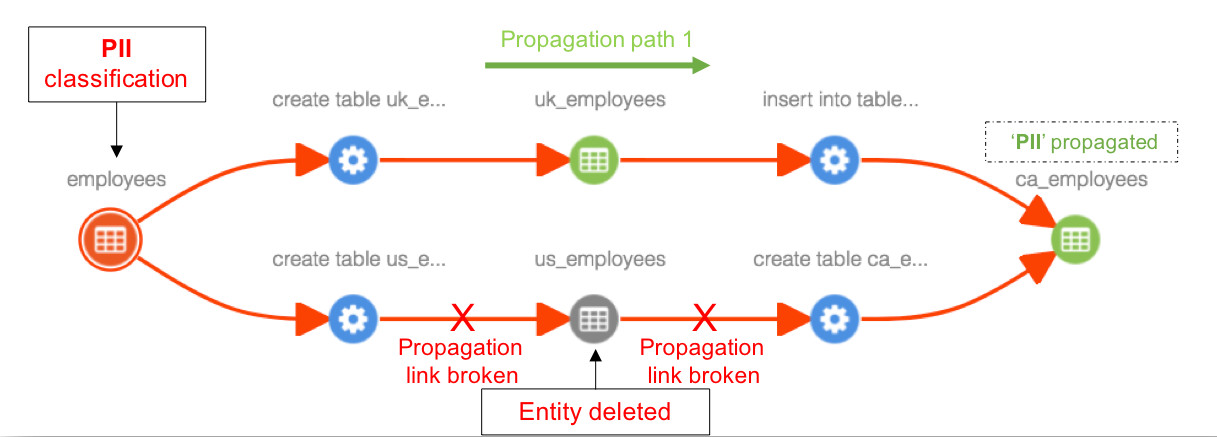
基于血缘分类传播
三. 数据血缘视角
(一)工程师视角
数据工程师通常希望看到数据处理细节的血缘,例如数据处理过程中的mapping,de-duplicate,data masking,merge,join, update, delete, insert等诸如此类的操作,这样便于在数据出现问题的时候方便他们进行回溯分析定位。

(二)业务用户视角
业务用户通常希望看到数据从哪里来,经过了那些关键的处理环节,每个处理环节是谁来负责,他们通常不关心诸如merge,join等非常技术细节的操作。例如:

在这个典型的用户视角内,最左侧的数据原始发源地,以及爬虫,ftp这些关键节点事实上很难被Apache Atlas自动发现和管理,在Apache Atlas内这部元数据通常需要手工捕获。
根据Apache Atlas版本特性来看,1.0并不支持实体类型的图标定制化功能。2.1的版本支持实体类型图标定制化功能,哥尼斯堡七桥问题成功阐释了一幅图胜过千言万语,同时也诞生了一个全新的学科:图论,选择符合业务实际场景的实体图标类型,往往能减少很多不必要的解释说明。
注意:Apache Atlas不是一个可以同时兼容两种血缘视角的软件。实际场景,手工捕获缺失的关键实体类别及实体信息,形成完整的数据血缘关系。
四. Apache Atlas编译部署
Apache Atlas提供了两种构建模式:
标准模式通常用于部署在生产环境中。
mvn clean -DskipTests package -Pdist
嵌入式构建模式提供了开箱即用的功能,通常用于PoC或者小规模场景。
mvn clean -DskipTests package -Pdist,embedded-hbase-solr
其中Hbase为Atlas图库提供存储,而Solr则负责为Atlas提供搜索。
mvn clean package -Pdist,embedded-cassandra-solr
其中Cassandra为Atlas图库提供存储,而Solr则负责为Atlas提供搜索。
不论选择哪种构建模式,避免配置阿里的Maven镜像仓库,因为缺少部分依赖包而无法完成构建,在构建过程中,至少保证有20GB的可用空间,构建会在少于2小时内完成。
以嵌入式embedded-hbase-solr为例部署一个快速原型的环境。
#!/bin/bash
# This script was tested in EMR 6.3 environment.
# The "embedded Apache HBase & Apache Solr" was tested.
# Create apache directory
sudo mkdir /apache
sudo chown hadoop.hadoop /apache
# Download JDK
cd /apache
wget https://corretto.aws/downloads/latest/amazon-corretto-11-x64-linux-jdk.tar.gz
tar xzf amazon-corretto-11-x64-linux-jdk.tar.gz
# Download Atlas-2.1.0
# ---------------start---------------
cd /apache
# Please upload your compiled distribution package into your bucket and grant read permission.
curl -O https://your-s3-bucketname.s3.amazonaws.com/apache-atlas-2.1.0-bin.tar.gz
tar xzf apache-atlas-2.1.0-bin.tar.gz
# Configuration
# atlas-env.sh
# 20 export JAVA_HOME=/apache/amazon-corretto-11.0.12.7.1-linux-x64
sed -i "s%.*export JAVA_HOME.*%export JAVA_HOME=/apache/amazon-corretto-11.0.12.7.1-linux-x64%" /apache/apache-atlas-2.1.0/conf/atlas-env.sh
sed -i "s%.*export JAVA_HOME.*%export JAVA_HOME=/apache/amazon-corretto-11.0.12.7.1-linux-x64%" /apache/apache-atlas-2.1.0/hbase/conf/hbase-env.sh
# atlas-application.properties
# 104 atlas.notification.embedded=false
# 106 atlas.kafka.zookeeper.connect=localhost:2181
# 107 atlas.kafka.bootstrap.servers=localhost:9092
sed -i "s/atlas.graph.index.search.solr.zookeeper-url.*/atlas.graph.index.search.solr.zookeeper-url=localhost:9983" /apache/apache-atlas-2.1.0/conf/atlas-application.properties
sed -i "s/atlas.notification.embedded=.*/atlas.notification.embedded=false/" /apache/apache-atlas-2.1.0/conf/atlas-application.properties
sed -i "s/atlas.kafka.zookeeper.connect=.*/atlas.kafka.zookeeper.connect=localhost:9983/" /apache/apache-atlas-2.1.0/conf/atlas-application.properties
sed -i "s/atlas.kafka.bootstrap.servers=.*/atlas.kafka.bootstrap.servers=localhost:9092/" /apache/apache-atlas-2.1.0/conf/atlas-application.properties
sed -i "s/atlas.audit.hbase.zookeeper.quorum=.*/atlas.audit.hbase.zookeeper.quorum=localhost/" /apache/apache-atlas-2.1.0/conf/atlas-application.properties
# ---------------end---------------
# Solr start
# ---------------start---------------
# Export environment variable
export JAVA_HOME=/apache/amazon-corretto-11.0.12.7.1-linux-x64
export SOLR_BIN=/apache/apache-atlas-2.1.0/solr/bin
export SOLR_CONF=/apache/apache-atlas-2.1.0/conf/solr
# Startup solr
$SOLR_BIN/solr start -c
# Initialize the index
$SOLR_BIN/solr create_collection -c vertex_index -d $SOLR_CONF
$SOLR_BIN/solr create_collection -c edge_index -d $SOLR_CONF
$SOLR_BIN/solr create_collection -c fulltext_index -d $SOLR_CONF
# ---------------end---------------
# Config the hive hook
# ---------------start---------------
sudo sed -i "s#</configuration># <property>\n <name>hive.exec.post.hooks</name>\n <value>org.apache.atlas.hive.hook.HiveHook</value>\n </property>\n\n</configuration>#" /etc/hive/conf/hive-site.xml
sudo cp /apache/apache-atlas-2.1.0/conf/atlas-application.properties /etc/hive/conf
sudo sed -i 's%export HIVE_AUX_JARS_PATH.*hcatalog%export HIVE_AUX_JARS_PATH=${HIVE_AUX_JARS_PATH}${HIVE_AUX_JARS_PATH:+:}/usr/lib/hive-hcatalog/share/hcatalog:/apache/apache-atlas-2.1.0/hook/hive%' /etc/hive/conf/hive-env.sh
sudo cp -r /apache/apache-atlas-2.1.0/hook/hive/* /usr/lib/hive/auxlib/
sudo systemctl stop hive-server2
sudo systemctl start hive-server2
# ---------------end---------------
# Start atlas
# ---------------start---------------
# Initialize will be completed in 15 mintues
export MANAGE_LOCAL_HBASE=true
export MANAGE_LOCAL_SOLR=true
python2 /apache/apache-atlas-2.1.0/bin/atlas_start.py
python2 /apache/apache-atlas-2.1.0/bin/atlas_stop.py
python2 /apache/apache-atlas-2.1.0/bin/atlas_start.py
# ---------------end---------------
# Download and startup kafka
# ---------------start---------------
cd /apache
curl -O https://mirrors.bfsu.edu.cn/apache/kafka/2.8.0/kafka_2.13-2.8.0.tgz
tar xzf kafka_2.13-2.8.0.tgz
sed -i "s/zookeeper.connect=.*/zookeeper.connect=localhost:9983/" /apache/kafka_2.13-2.8.0/config/server.properties
/apache/kafka_2.13-2.8.0/bin/kafka-server-start.sh -daemon /apache/kafka_2.13-2.8.0/config/server.properties
# ---------------end---------------
Apache Atlas虽然内嵌了Hive/Hbase/Sqoop/Storm/Falcon/Kafka的hook,但是除此之外的其他处理引擎的plugin极少,例如目前广泛使用的Spark/Flink,如果使用这两个计算引擎处理数据,则需要进行定制开发才能捕获相关的数据血缘。
五. 手工捕获数据
Apache Atlas是一个典型的类型继承系统,在追加无法通过Atlas hook或者plugin自动捕获的数据时,必须先了解其类型系统,及血缘的形成原理。然后根据业务需要创建必要的子类型及其实体。

其中绿色标记的为DataSet静态子类型,红色标记的为Process子类型,Process实体通过连接作为输入输出的DataSet子类型实体从而形成血缘关系。
本文业务用户视角血缘的demo由于涉及较多的代码,详细步骤及代码,请参见:https://github.com/picomy/manually-catch-data-for-atlas
六. Spark与Apache Atlas
捕获Spark数据血缘可以采用以下两大类的方式:
- Connector, 优点自动化数据捕获
- REST API,优点定制化程度高
是Hortonworks开源的Connector,最后一次代码更新是在2019年7月12日,从实际的代码编译结果来看,与Spark 3.1.1存在兼容性问题。该项目默认的配置(pom.xml):
- Spark 2.4.0
- Scala 2.11.12
- Atlas 2.0.0
如果是2.4.0本的Spark可以考虑采用该connector。
对于该项目使用文档的一些补充,如果使用rest api方式进行数据的自动填充,请配置以下参数:
- rest.address
- client.username
- client.password
这些配置选项来源于AtlasClientConf.scala文件。
是目前活跃度较高的捕获Spark数据血缘的开源项目,但是它与Atlas兼容性不好,而是自成一体,但是该项目对于Spark的兼容性非常好。
本篇作者