亚马逊AWS官方博客
使用 Apache SeaTunnel 快速集成数据到S3 Tables
业务技术背景
在当今数字化转型浪潮下,企业正面临着海量数据的爆炸式增长,尤其在构建数据湖业务、BI分析以及AI/ML数据准备等关键场景中,需要高效、可扩展的大规模大数据存储解决方案。这些场景往往要求数据存储系统不仅能处理PB级甚至EB级的数据规模,还必须支持事务性操作,以确保数据一致性、原子性和隔离性,从而避免数据混乱或丢失的风险。正因如此,Apache Iceberg作为一种先进的开源数据湖格式,应运而生并迅速崛起。它提供了可靠的元数据管理、快照隔离和模式演化功能,被众多科技巨头如Netflix、Apple和Adobe广泛采纳,已然确立了在数据湖领域的领导地位。根据行业报告,Iceberg的采用率在过去几年内持续攀升,成为构建现代数据基础设施的首选标准。
尽管Iceberg本身强大,但企业在实际部署中往往面临运维复杂性、扩展管理和资源开销的挑战,这就需要托管解决方案来简化操作。亚马逊云科技在2024年re:Invent推出的S3 Tables特性,进一步强化了Iceberg的托管能力。这一创新功能允许用户直接在Amazon S3上构建和管理Iceberg表,可以将Iceberg表直接构建和管理在云存储上,无需额外的基础设施投资,从而显著降低运维成本和复杂度,同时充分利用云平台的全球可用性、耐久性和无限扩展性,提升数据处理的弹性和性能。这种托管方式特别适用于需要高可用性和无缝集成的场景,为企业提供云原生数据湖体验,确保数据湖在高并发读写下的稳定性。
在众多业务场景中,数据同步尤其是CDC(Change Data Capture)扮演关键角色,它支持实时捕获源数据库的变化并同步到目标系统,如数据湖或仓库。实时数据同步适用于对时效性要求高的场景,例如金融交易平台的欺诈检测、零售库存实时更新或医疗系统的患者记录即时共享,确保决策基于最新数据;而离线(或批量)数据同步则更适合非实时需求,如日常备份、历史数据归档或定时报表生成,避免资源浪费并处理大批量数据。通过这些同步机制,企业能高效实现CDC数据摄入和批量同步,满足从实时分析到离线处理的多样化需求。本文将介绍,如何使用 Apache SeaTunnel ,一个高性能、分布式的大规模数据集成工具,通过兼容 Iceberg rest catalog 的实现对接 S3 Tables 实现实时和批量数据集成。
架构及核心组件
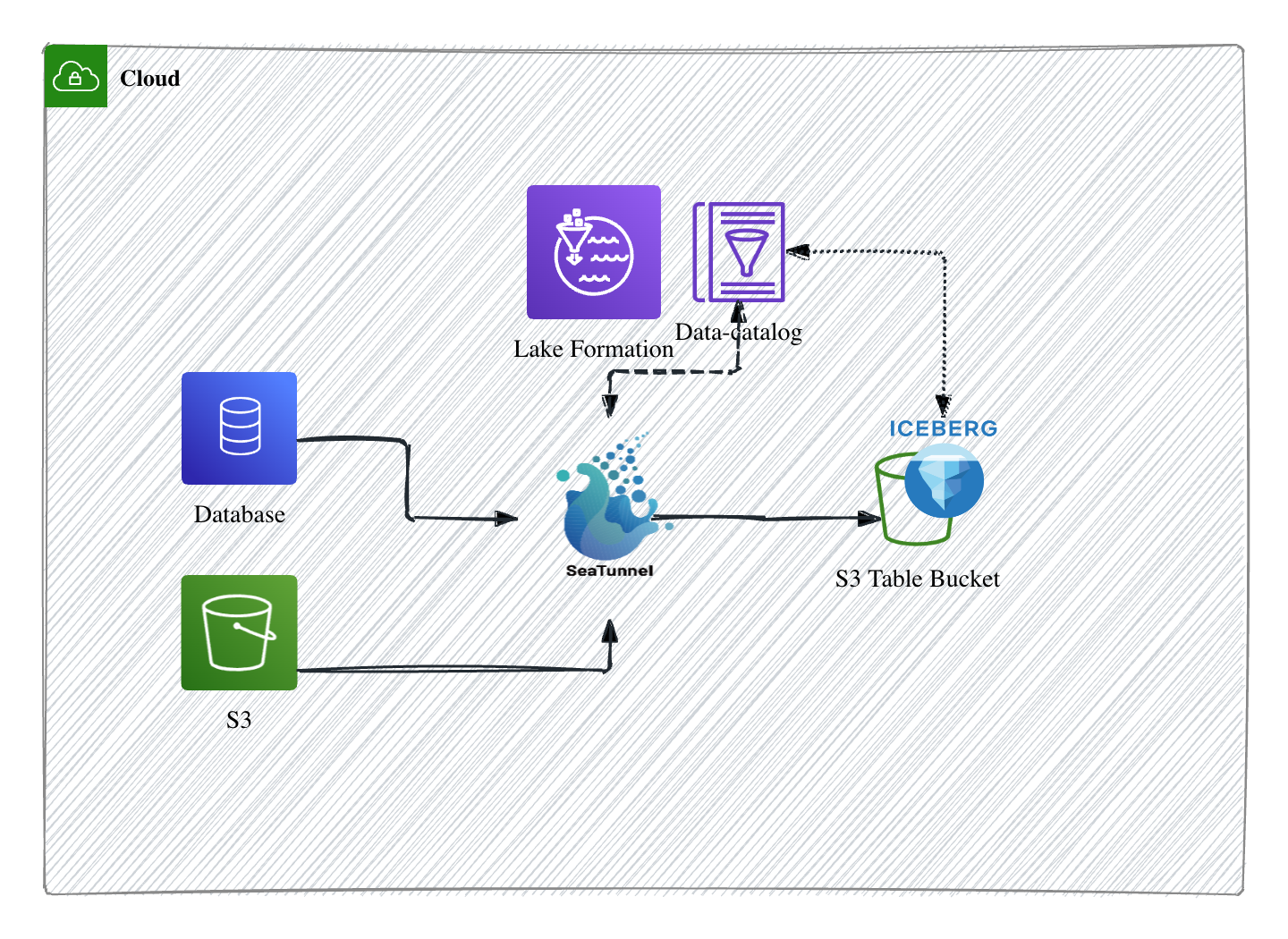 |
- 通过SeaTunnel 支持 Iceberg REST Catalog 对接,SeaTunnel 原生实现对 Apache Iceberg REST Catalog 的接入能力。Iceberg 的 REST Catalog 允许以标准化接口对元数据进行读写和管理,极大简化了客户端与 Catalog 交互的复杂度。通过对 REST Catalog 的兼容,SeaTunnel 可以直接、无缝地将作业产出的表元数据同步注册到 Iceberg Catalog,而无需研发自定义插件或手动维护元数据同步流程。这为数据湖的自动化运维和架构解耦创造了技术基础。
- 云原生数据湖能力:S3 Tables + REST Endpoint ,随着 S3 Tables的发布,S3 Tables 内置提供了 Iceberg REST Catalog Endpoint。SeaTunnel 能够直接对接S3 Tables,无需额外改造,即可将批量或流式数据流动写入到 S3 上的 Iceberg 表,并通过 S3 Tables 的 REST Endpoint 管理元数据和表结构。这种原生对接极大降低了云上数据湖落地和扩展成本,实现了云原生、Serverless 的数据湖架构,管理和查询端都变得标准化、敏捷和易于演化。
- 数据与 Catalog 的流转闭环,高效支持 CDC 及全量离线同步,如图所示,数据同步链路基于 SeaTunnel 完成整合:无论是数据库(如OLTP/OLAP)、S3 离线分区还是流式变更(CDC 数据),都先统一接入 SeaTunnel,通过 SeaTunnel Sink 能力实时或批量写入 S3 Table Bucket。与此同时,Iceberg 表的元数据通过 REST Catalog 即时注册到 Data Catalog 服务(如 Lake Formation),实现业务表、元数据、访问权限等一站式协同。CDC 实时场景下,数据库的变更可以低延迟同步,保证数据的鲜活性;而在批量同步或历史归档场景,也能稳定高效地将数据注入 S3 Table,并由统一 Catalog 发现和管理,适配数据湖/数据仓库混合查询模式。综上,该架构的核心创新在于,SeaTunnel 通过 Iceberg REST Catalog 标准化了数据与元数据的流转方式,AWS S3 Tables 的 REST Endpoint 实现云原生、托管化部署,而 CDC 与离线数据同步能力让大规模数据湖具备了高效、灵活、实时的一站式数据流通机制。
数据集成演示
- 离线数据集成
1. 以SeaTunnel 提供的fake 数据源测试批量数据写入 S3 Tables,首先编辑 SeaTunnel任务配置文件,Sink 配置为 Iceberg 连接器的 rest catalog,认证方式选择aws ,配置 rest uri 及 warehouse为 S3 Tables 的 endpoint 。如下示例:
2.启动SeaTunnel 任务
3.查看任务运行日志
 |
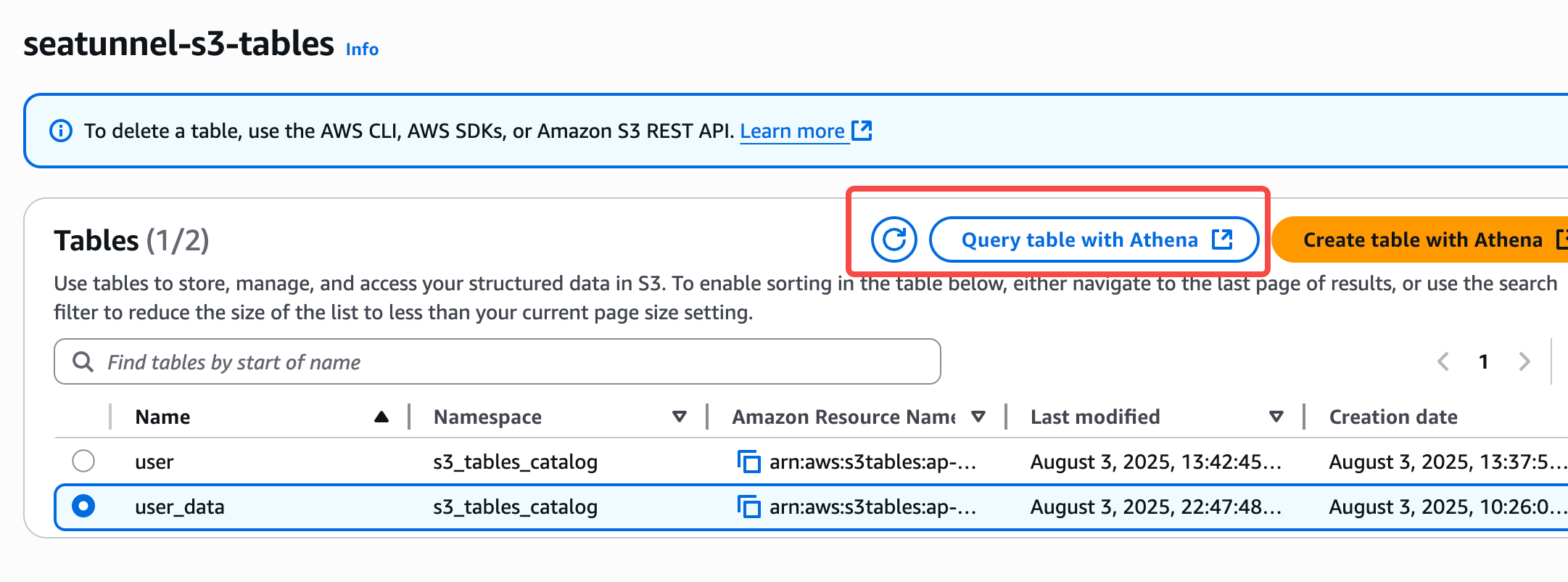
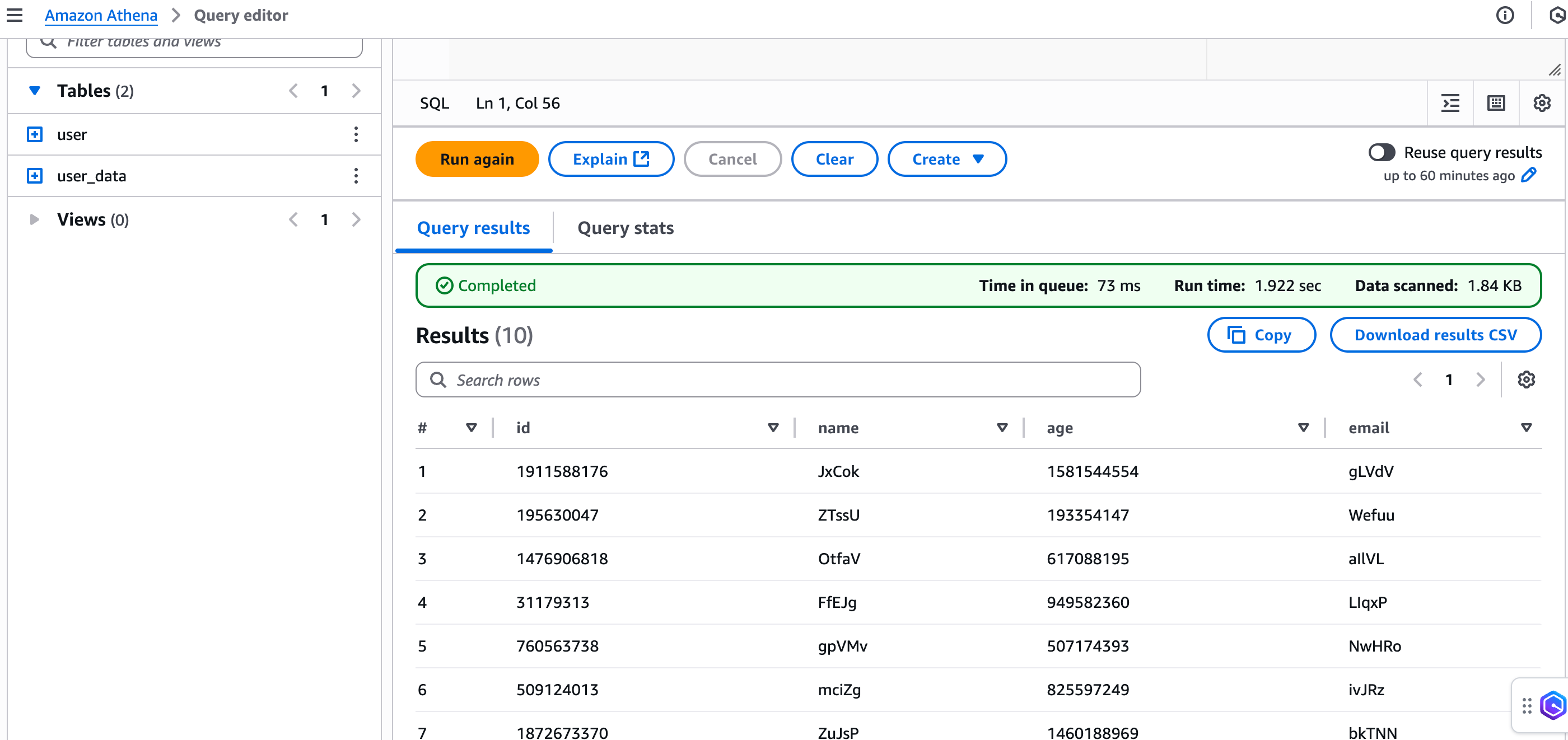
4.在 S3 Tables bucket 查看表,在 Athena 进行数据查询
 |
 |
 |
- 实时 CDC 数据集成
1.以MySQL cdc 数据源测试流式量数据写入 S3 Tables,首先编辑 SeaTunnel任务配置文件,Sink 配置为 Iceberg 连接器的 rest catalog,认证方式选择aws ,配置 rest uri 及 warehouse为 S3 Tables 的 endpoint 。如下示例:
2.启动SeaTunnel 任务
3.查看任务运行日志,可以看到 cdc 完成一次快照拉取数据后在监听数据并进行数据摄入
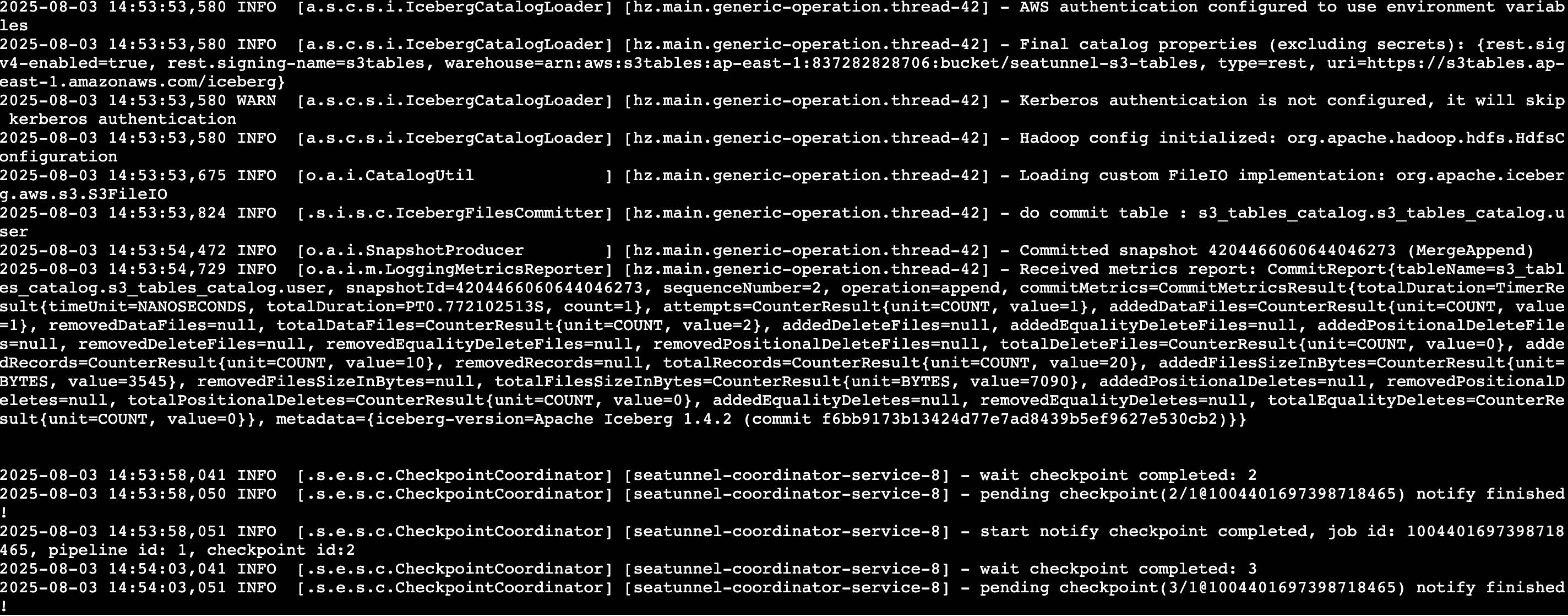 |
4.同样可以在 Athena 查看数据
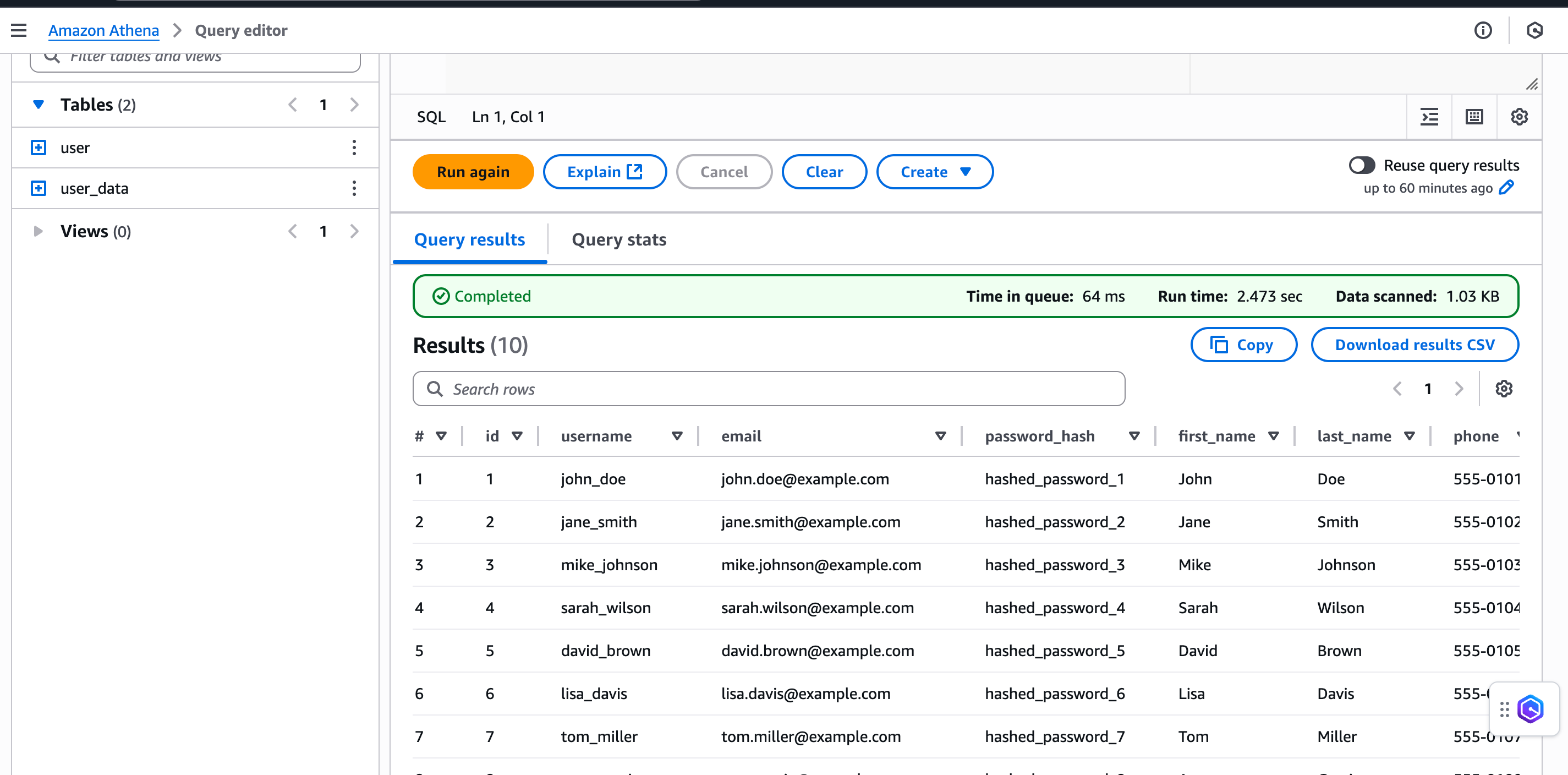 |
总结展望
随着Apache SeaTunnel对Iceberg和AWS S3 Tables的深度集成,企业数据湖架构将迎来更广阔的应用前景。未来,在数据湖构建过程中,生产环境可以引入SeaTunnel的监控措施,如集成Prometheus和Grafana进行实时指标监控(包括任务执行状态、数据吞吐率和错误日志),确保及时发现并响应潜在问题。同时,通过Kubernetes或Docker Swarm的弹性部署策略,实现SeaTunnel作业的自动缩放和故障转移,支持动态资源分配(如基于负载的Pod扩展),从而保证数据ETL流程的稳定性和高可用性。这不仅能减少手动干预,还能应对突发数据峰值,维持生产级别的可靠运行。此外,结合AWS的高级功能如Athena查询引擎或Glue Crawler的自动化发现,企业可以进一步优化Iceberg表的查询性能,例如启用S3的智能分层存储来降低成本,或集成Lake Formation的安全治理来强化数据访问控制。这些优化将使数据湖在BI分析和AI/ML准备中更具弹性,支持PB级数据的低延迟查询和模型训练。
*前述特定亚马逊云科技生成式人工智能相关的服务目前在亚马逊云科技海外区域可用。亚马逊云科技中国区域相关云服务由西云数据和光环新网运营,具体信息以中国区域官网为准。
本篇作者
AWS 架构师中心:云端创新的引领者探索 AWS 架构师中心,获取经实战验证的最佳实践与架构指南,助您高效构建安全、可靠的云上应用
|
 |
