亚马逊AWS官方博客
基于无服务器架构和事件驱动的 Data Lake 数据移动
摘要
本文探讨一种基于亚马逊云科技无服务器架构和事件驱动的数据移动方案(Replication Kit, Replikit),以满足数据在数据湖上特定场景下的数据发布需求。Replikit可以帮助实现:数据文件的多路定向输出、可跨AWS Partition分区的数据移动、数据移动同时的数据格式转换、多种网络环境以及长期或短期凭证授权下的数据移动。
方案
背景
进入数据湖(Data Lake)的数据在经过大数据处理后的重要使用场景是做数据服务,将数据通过微服务或者其他方式发布给B端或者C端的数据消费者。通常B端的数据消费者要求数据在产生后能够即时的提供到消费端,对文件格式的要求也多种多样。原有的依赖于ETL批次调度的数据移动方案就难以满足这样的数据发布需求,因此本文探讨一种基于亚马逊云科技无服务器架构和事件驱动的数据移动方案(Replication Kit, Replikit)。
架构
事件驱动的Data Lake数据移动方案(Replikit)使用无服务器化(Serverless)架构。数据湖上数据文件的异动触发Amazon Simple Storage Service(S3)的事件通知,通过Amazon Simple Notification Service (SNS) 将事件消息路由到Amazon Simple Queue Service (SQS)并触发AWS Lambda根据事件消息提供的文件元信息和预定义的代码逻辑处理数据文件并移动到目标桶的目录中。
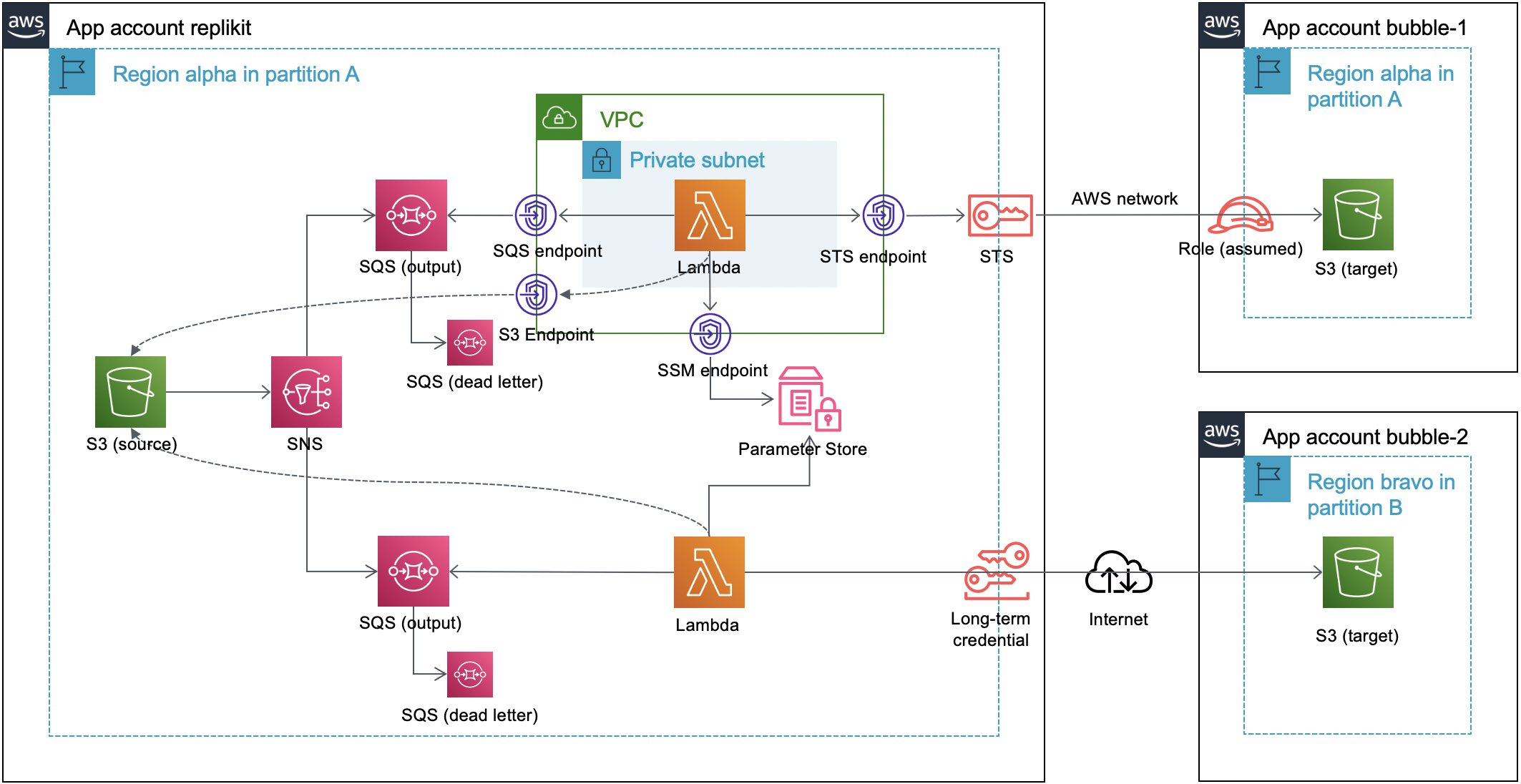
一)角色权限(Replikit pivot role)
数据移动的数据复制者(Replikit Account)使用约定的ReplikitPivotRole角色实现对数据消费者(Bubble Account)的有限数据操作,所有权限由数据消费者控制。
二)事件通知(Replikit event)
数据文件由大数据数据应用处理后输出到Amazon Simple Storage Service(S3)桶立即触发S3事件通知,通知经过预定义的规则筛选后汇集到Amazon Simple Notification Service (SNS)。本方案用例筛选的S3事件是 s3:ObjectCreated:*。
三)数据定向(Replikit output)
Amazon Simple Queue Service (SQS) 订阅SNS消息实现数据的输出定向,配合 SQS 实现数据定向的扇形扩展,将一个数据复制者的数据定向到多个数据消费者。
四)数据处理(Replikit handler)
数据处理使用Lambda 函数、Python 3.7 运行时以及 Boto3 库实现对 AWS 服务的操作。本方案提供两种网络环境下的样例:一种是严苛的网络环境,要求 Lambda 必须在 VPC 内运行,并且流量不到 Internet;另外一种是基础的网络环境,Lambda在安全网络中运行,并且流量可以出Internet。严苛的网络环境下,借助 VPC Endpoint 来实现流量的互通,通过 ReplikitPivotRole 获取消费者账号的短期凭证。基础的网络环境下,可以选择使用:1)通过 ReplikitPivotRole 获取短期凭证,2)轮换的 AKSK 长期凭证。本方案样例使用 AKSK 长期凭证实现跨 AWS Partition的数据移动。Lambda 处理逻辑中可以使用外部函数库实现对数据格式的转换。
五)定向配置
数据移动的定向目录在 AWS System Manager Parameter Store 中配置,定向配置参数路径为/Replikit/<output-name>,配置内容使用JSON格式存储,指定目标桶和桶目录。
六)凭证配置
数据移动的长期凭证在 AWS System Manager Parameter Store 中配置,使用Secure String 以及 KMS 加密保存。参数路径为/Replikit/<output-name>/<bubble-account-id>。
实现
Replikit 方案样例的部署使用 CloudFormation 模版,Lambda 函数代码使用Inline 方式嵌入CloudFormation 模版中。实现的技术要点如下:
一)创建角色 ReplikitPivotRole
在数据移动的消费者账户(Bubble Account)中创建约定的角色 ReplikitPivotRole,给予该角色必要的访问权限,包括:对特定的S3桶目录的写权限;授予数据移动复制者账户(Replikit Account)的AssumeRole的权限。
样例cfn-app-replikit-pivot.yaml
AWSTemplateFormatVersion: "2010-09-09"
Transform: AWS::Serverless-2016-10-31
Description: |
This template deploys a dedicated pivot role for replication kit (replikit) to assume.
Parameters:
ReplikitAccountId:
Type: String
Description: Replikit account id
BubbleBucketName:
Type: String
Description: Bubble bucket name
Default: '*'
Mappings:
PartitionMap:
aws:
domain: com.amazonaws
aws-cn:
domain: cn.com.amazonaws
Resources:
ReplikitPivotRole:
Type: AWS::IAM::Role
Properties:
RoleName: ReplikitPivotRole
AssumeRolePolicyDocument:
Version: '2012-10-17'
Statement:
- Effect: Allow
Action:
- sts:AssumeRole
Principal:
AWS:
- !Sub arn:${AWS::Partition}:iam::${ReplikitAccountId}:root
Policies:
- PolicyName: ReplikitPivotRoleAccess
PolicyDocument:
Version: '2012-10-17'
Statement:
- Effect: Allow
Action:
- s3:ListBucketMultipartUploads
Resource:
- !Sub arn:${AWS::Partition}:s3:::${BubbleBucketName}
- Effect: Allow
Action:
- s3:PutObject
- s3:AbortMultipartUpload
- s3:ListMultipartUploadParts
Resource:
- !Sub arn:${AWS::Partition}:s3:::${BubbleBucketName}/*
Outputs:
ReplikitPivotRoleArn:
Value: !GetAtt ReplikitPivotRole.Arn
二)注册桶事件通知
在数据移动复制账户(Replikit Account)的一个或多个数据源桶配置事件通知,选择s3:ObjectCreated:*事件通知定向到SNS。
样例代码cfn-app-replikit-event.yaml
AWSTemplateFormatVersion: "2010-09-09"
Transform: AWS::Serverless-2016-10-31
Description: |
This template deploys initial event register of replication kit (replikit).
Parameters:
ReplikitBucketName:
Type: String
Description: Replikit bucket name
Mappings:
PartitionMap:
aws:
domain: com.amazonaws
aws-cn:
domain: cn.com.amazonaws
Resources:
ReplikitBucket:
Type: AWS::S3::Bucket
DependsOn:
- ReplikitTopic
- ReplikitTopicPolicy
Properties:
BucketName: !Ref ReplikitBucketName
BucketEncryption:
ServerSideEncryptionConfiguration:
- ServerSideEncryptionByDefault:
SSEAlgorithm: AES256
PublicAccessBlockConfiguration:
BlockPublicAcls: True
BlockPublicPolicy: True
IgnorePublicAcls: True
RestrictPublicBuckets: True
NotificationConfiguration:
TopicConfigurations:
- Topic: !Ref ReplikitTopic
Event: s3:ObjectCreated:Put
- Topic: !Ref ReplikitTopic
Event: s3:ObjectCreated:Post
- Topic: !Ref ReplikitTopic
Event: s3:ObjectCreated:Copy
- Topic: !Ref ReplikitTopic
Event: s3:ObjectCreated:CompleteMultipartUpload
ReplikitTopic:
Type: AWS::SNS::Topic
Properties:
TopicName: Replikit
ReplikitTopicPolicy:
Type: AWS::SNS::TopicPolicy
DependsOn:
- ReplikitTopic
Properties:
Topics:
- !Ref ReplikitTopic
PolicyDocument:
Statement:
- Effect: Allow
Action:
- sns:Publish
Resource: !Ref ReplikitTopic
Principal:
Service: s3.amazonaws.com
Condition:
StringEquals:
AWS:SourceAccount: !Ref AWS::AccountId
Outputs:
ReplikitTopicArn:
Value: !Ref ReplikitTopic
三)严苛的网络环境中订阅并处理数据移动
严苛的网络环境中可能要求Lambda必须在VPC中执行,并且VPC流量不能出Internet。这时候需要借助AWS VPC Endpoint来实现。
样例代码cfn-app-replikit-output-a.yaml
AWSTemplateFormatVersion: "2010-09-09"
Transform: AWS::Serverless-2016-10-31
Description: |
This template deploys a VPC-restricted output of replication kit (replikit).
Parameters:
VpcId:
Type: String
Description: Vpc id
VpcEndpointCidr:
Type: String
Description: Vpc endpoint cidr
PrivateSubnetIds:
Type: String
Description: Comma delimited list of private subnet ids
ReplikitTopicArn:
Type: String
Description: Replikit topic arn
ReplikitOutputName:
Type: String
Description: Replikit output name
BubbleAccountId:
Type: String
Description: Bubble account id
BubbleRegionName:
Type: String
Description: Bubble region name
Mappings:
PartitionMap:
aws:
domain: com.amazonaws
aws-cn:
domain: cn.com.amazonaws
Resources:
SqsVpcEndpoint:
Type: AWS::EC2::VPCEndpoint
DependsOn:
- SqsVpcEndpointSecurityGroup
Properties:
PrivateDnsEnabled: True
SecurityGroupIds:
- !GetAtt SqsVpcEndpointSecurityGroup.GroupId
ServiceName:
!Join
- "."
- - !FindInMap [PartitionMap, !Ref 'AWS::Partition', domain]
- !Sub ${AWS::Region}.sqs
SubnetIds: !Split [',', !Ref PrivateSubnetIds]
VpcEndpointType: Interface
VpcId: !Ref VpcId
SqsVpcEndpointSecurityGroup:
Type: AWS::EC2::SecurityGroup
Properties:
VpcId: !Ref VpcId
GroupDescription: Sqs vpc endpoint security group
SecurityGroupIngress:
- IpProtocol: -1
CidrIp: !Ref VpcEndpointCidr
SsmVpcEndpoint:
Type: AWS::EC2::VPCEndpoint
DependsOn:
- SsmVpcEndpointSecurityGroup
Properties:
PrivateDnsEnabled: True
SecurityGroupIds:
- !GetAtt SsmVpcEndpointSecurityGroup.GroupId
ServiceName: !Sub com.amazonaws.${AWS::Region}.ssm
SubnetIds: !Split [',', !Ref PrivateSubnetIds]
VpcEndpointType: Interface
VpcId: !Ref VpcId
SsmVpcEndpointSecurityGroup:
Type: AWS::EC2::SecurityGroup
Properties:
VpcId: !Ref VpcId
GroupDescription: Ssm vpc endpoint security group
SecurityGroupIngress:
- IpProtocol: -1
CidrIp: !Ref VpcEndpointCidr
StsVpcEndpoint:
Type: AWS::EC2::VPCEndpoint
DependsOn:
- StsVpcEndpointSecurityGroup
Properties:
PrivateDnsEnabled: True
SecurityGroupIds:
- !GetAtt StsVpcEndpointSecurityGroup.GroupId
ServiceName: !Sub com.amazonaws.${AWS::Region}.sts
SubnetIds: !Split [',', !Ref PrivateSubnetIds]
VpcEndpointType: Interface
VpcId: !Ref VpcId
StsVpcEndpointSecurityGroup:
Type: AWS::EC2::SecurityGroup
Properties:
VpcId: !Ref VpcId
GroupDescription: Sts vpc endpoint security group
SecurityGroupIngress:
- IpProtocol: -1
CidrIp: !Ref VpcEndpointCidr
ReplikitTopicSubscription:
Type: AWS::SNS::Subscription
DependsOn:
- ReplikitQueue
Properties:
TopicArn: !Ref ReplikitTopicArn
Protocol: sqs
Endpoint: !GetAtt ReplikitQueue.Arn
RawMessageDelivery: True
ReplikitQueue:
Type: AWS::SQS::Queue
DependsOn:
- ReplikitDeadLetterQueue
Properties:
QueueName: !Sub Replikit-${ReplikitOutputName}
VisibilityTimeout: 960
RedrivePolicy:
deadLetterTargetArn: !GetAtt ReplikitDeadLetterQueue.Arn
maxReceiveCount: 8
ReplikitQueuePolicy:
Type: AWS::SQS::QueuePolicy
DependsOn:
- ReplikitQueue
Properties:
Queues:
- !Ref ReplikitQueue
PolicyDocument:
Statement:
- Effect: Allow
Action:
- SQS:GetQueueAttributes
- SQS:SendMessage
- SQS:ReceiveMessage
- SQS:GetQueueUrl
Resource: !GetAtt ReplikitQueue.Arn
Principal:
Service: sns.amazonaws.com
Condition:
StringEquals:
AWS:SourceAccount: !Ref AWS::AccountId
ReplikitDeadLetterQueue:
Type: AWS::SQS::Queue
Properties:
QueueName: !Sub ReplikitDeadLetter-${ReplikitOutputName}
ReplikitFunction:
Type: AWS::Serverless::Function
DependsOn:
- ReplikitFunctionLogGroup
- ReplikitFunctionSecurityGroup
- ReplikitQueue
Properties:
FunctionName: !Sub Replikit-${ReplikitOutputName}
Description: Replikit function
InlineCode: |
import io
import os
import boto3
import json
import base64
import hashlib
import logging
# Logger (change log level to your env stage)
logger = logging.getLogger()
logger.setLevel(logging.INFO)
# Handler
def lambda_handler(event, context):
# Get sessions
kitSession = boto3.session.Session()
srcSession = None
desSession = None
# Get environments and params
desOutput = os.environ['env_output']
desRegion = os.environ['env_region']
desBubble = os.environ['env_bubble']
desParams = json.loads(
kitSession.client('ssm').get_parameter(Name = '/Replikit/{0}'.format(desOutput))['Parameter']['Value']
)
desBucket = desParams['des_bucket']
desPrefix = desParams['des_prefix']
try:
pivotRole = 'arn:{0}:iam::{1}:role/{2}'.format(
'aws-cn' if (desRegion.lower() == 'cn-north-1' or desRegion.lower() == 'cn-northwest-1') else 'aws', desBubble, 'ReplikitPivotRole'
)
pivotResp = kitSession.client("sts", endpoint_url = "https://sts.{0}.amazonaws.com".format(kitSession.region_name)).assume_role(
RoleArn = pivotRole, RoleSessionName = 'ReplikitPivotRole'
)
desSession = boto3.Session(
aws_access_key_id = pivotResp["Credentials"]["AccessKeyId"],
aws_secret_access_key = pivotResp["Credentials"]["SecretAccessKey"],
aws_session_token = pivotResp["Credentials"]["SessionToken"]
)
logger.info(
"Session is created with short-term credentials for bubble account {0}.".format(desBubble)
)
except:
desAccess = json.loads(
kitSession.client('ssm').get_parameter(Name = '/Replikit/{0}/{1}'.format(desOutput, desBubble), WithDecryption = True)['Parameter']['Value']
)
desSession = boto3.Session(
aws_access_key_id = desAccess['aws_access_key_id'],
aws_secret_access_key = desAccess['aws_secret_access_key'],
region_name = desRegion
)
logger.info(
"Session is created with long-term credentials for bubble account {0}.".format(desBubble)
)
finally:
if not srcSession:
srcSession = boto3.session.Session()
# Loop messages for replication
for message in event['Records']:
msgId = message['messageId']
msgReceives = message['attributes']['ApproximateReceiveCount']
logger.info(
"Message {0} is in process upon #{1} receives.".format(msgId, msgReceives)
)
msgBody = json.loads(message['body'])
for record in msgBody['Records']:
srcEvent = record['eventName']
if 'ObjectCreated:' in srcEvent: # Filter event name
srcBucket = record['s3']['bucket']['name']
srcKey = record['s3']['object']['key']
if srcKey.endswith('/'): # No need to process a folder
continue
logger.info(
"S3 event configuration {0} enables replication from object {1} in bucket {2}.".format(record['s3']['configurationId'], srcKey, srcBucket)
)
# Example: replicate object
# TO-DO: add more condition checks
desKey = ("{0}{1}" if desPrefix.endswith('/') else "{0}/{1}").format(desPrefix, srcKey)
upsert_multipart(
srcClient = srcSession.client('s3'), srcBucket = srcBucket, srcKey = srcKey, desClient = desSession.client('s3'), desBucket = desBucket, desKey = desKey
)
# Description: upsert S3 object in multipart.
def upsert_multipart(srcClient, srcBucket, srcKey, desClient, desBucket, desKey):
logger.info(
"Function upsert_multipart is triggered. (src bucket = {0}, src key = {1}, des bucket = {2}, des key = {3})".format(srcBucket, srcKey, desBucket, desKey)
)
# S1: get source S3 object header
hdrResp = lookup_s3_header(
client = srcClient, bucket = srcBucket, key = srcKey
)
# S2: calculate the multipart chunks
const_multipart_size_mb = 8 # The predefined chunk size = 8 MB
chunkOffsetList, chunkLengthList = create_multipart_chunks(
totalSize = int(hdrResp['ContentLength']), chunkSize = int(1024 * 1024 * const_multipart_size_mb)
)
logger.info(
"Chunk offset list and length list are populated. (offset list = {0}, length list = {1})".format(str(chunkOffsetList), str(chunkLengthList))
)
# S3: lookup the latest ongoing upload id from destination or create a new upload id for new multipart upload
updResp = lookup_multipart_upload(
client = desClient, bucket = desBucket, key = desKey
)
logger.info(
"Multipart latest ongoing upload is determined. (upload id = {0}, initiated = {1})".format(updResp['UploadId'], updResp['Initiated'])
)
uploadId = updResp['UploadId'] if 'UploadId' in updResp else None
if not uploadId: # New upload
uploadId = create_multipart_upload(
client = desClient, bucket = desBucket, key = desKey, storageClass = hdrResp['StorageClass']
)['UploadId']
logger.info(
"Multipart new upload is created. (upload id = {0})".format(uploadId)
)
else: # Naive check on timestamp
if hdrResp['LastModified'] > updResp['Initiated']:
cancel_multipart_upload(
client = desClient, bucket = desBucket, key = desKey, uploadId = uploadId
)
logger.error(
"Multipart initiated vs modified is not harmonized. (src on modified = {0}, des on initiated = {1})".format(hdrResp['LastModified'], updResp['Initiated'])
)
raise Exception("InconsistentMultipartUpload")
# S4: lookup in-process uploaded multiparts, return empty list for new upload
partNumberList = lookup_multipart_numbers(
client = desClient, bucket = desBucket, key = desKey, uploadId = uploadId
)
logger.info(
"Multipart uploaded number list is determined. (part number list = {0})".format(str(partNumberList))
)
# S5: Loop chunks to upload new part by comparing part number
for partId in range(0,len(chunkOffsetList)):
partNo = partId + 1
if partNo in partNumberList: # Pass uploaded part
logger.info(
"Multipart #{0} exists and is passed.".format(partNo)
)
continue
objBytes = select_s3_bytes_range(
client = srcClient, bucket = srcBucket, key = srcKey, versionId = hdrResp['VersionId'], rangeOffset = chunkOffsetList[partId], rangeLength = chunkLengthList[partId]
)
objTag = upload_multipart_bytes(
client = desClient, bucket = desBucket, key = desKey, body = objBytes, uploadId = uploadId, partNumber = partNo
)
logger.info(
"Multipart #{0} is uploaded. (upload id = {1}, etag = {2})".format(partNo, uploadId, objTag['ETag'])
)
# S6: complete multipart upload
objResponse = finish_multipart_upload(
client = desClient, bucket = desBucket, key = desKey, uploadId = uploadId
)
logger.info(
"Function upsert_multipart is resolved. (version id = {0}, etag = {1}).".format(objResponse['VersionId'], objResponse['ETag'])
)
return {}
# Description: lookup s3 object header for size, version, storage class and last modified
def lookup_s3_header(*, client, bucket, key, versionId=None):
objectHead = client.head_object(
Bucket = bucket, Key = key, VersionId = versionId
) if versionId else client.head_object(
Bucket = bucket, Key = key
)
contentLength = objectHead['ContentLength'] if 'ContentLength' in objectHead else None
versionId = objectHead['VersionId'] if 'VersionId' in objectHead else None
lastModified = objectHead['LastModified'] if 'LastModified' in objectHead else None
storageClass = objectHead['StorageClass'] if 'StorageClass' in objectHead else None
if not storageClass:
storageClass = 'STANDARD'
return {'ContentLength':contentLength, 'VersionId': versionId, 'StorageClass': storageClass, 'LastModified': lastModified}
# Description: select S3 object data range in bytes
def select_s3_bytes_range (*, client, bucket, key, versionId=None, rangeOffset=0, rangeLength=0):
if rangeOffset < 0 or rangeLength < 0:
raise Exception('InvalidRangeSize')
rangeStr = 'bytes=' + str(rangeOffset) + '-' + str(rangeOffset + rangeLength -1)
objectGet = client.get_object(
Bucket = bucket, Key = key, VersionId = versionId, Range = rangeStr
) if versionId else client.get_object(
Bucket = bucket, Key = key, Range = rangeStr
)
objectBytes = objectGet['Body'].read()
return objectBytes
# Description: create multipart chunks
def create_multipart_chunks(*, totalSize, chunkSize):
if totalSize <= 0 or chunkSize <= 0:
raise Exception('InvalidChunkSize')
const_multipart_part_no = 10000 # The predefined max part number
offsetList, lengthList = [], []
for nbr in range (0, const_multipart_part_no):
offsetList.append(chunkSize * nbr)
lengthList.append(
(totalSize - chunkSize * nbr) if (chunkSize * (nbr + 1) >= totalSize or (nbr + 1) == const_multipart_part_no) else chunkSize
)
if(chunkSize * (nbr + 1)) >= totalSize:
break
return (offsetList, lengthList)
# Description: create a new multipart upload
def create_multipart_upload(*, client, bucket, key, storageClass):
response = client.create_multipart_upload(
Bucket = bucket, Key = key, StorageClass = storageClass
)
uploadId = response['UploadId'] if 'UploadId' in response else None
return {'UploadId': uploadId}
# Description: finish multipart upload by consolidating multiparts
def finish_multipart_upload(*, client, bucket, key, uploadId):
partResults = []
paginator = client.get_paginator('list_parts')
iterator = paginator.paginate(
Bucket = bucket, Key = key, UploadId = uploadId
)
for it in iterator:
if 'Parts' in it:
for part in it['Parts']:
partResults.append(
{'ETag': part['ETag'], 'PartNumber': part['PartNumber']}
)
response = client.complete_multipart_upload(
Bucket = bucket,
Key = key,
UploadId = uploadId,
MultipartUpload = {'Parts': partResults}
)
versionId = response['VersionId'] if 'VersionId' in response else None
eTag = response['ETag'] if 'ETag' in response else None
return {'VersionId': versionId, 'ETag': eTag}
# Description: cancel multipart upload
def cancel_multipart_upload(*, client, bucket, key, uploadId):
response = client.abort_multipart_upload(
Bucket = bucket, Key = key, UploadId = uploadId
)
return {}
# Description: lookup latest multipart upload
def lookup_multipart_upload(*, client, bucket, key):
uploadId, initiated = None, None
paginator = client.get_paginator('list_multipart_uploads')
iterator = paginator.paginate(
Bucket = bucket,
Prefix = key
)
for it in iterator:
if 'Uploads' in it:
for upload in it['Uploads']:
if upload['Key'] == key:
if (initiated == None) or (upload['Initiated'] > initiated):
uploadId, initiated = upload['UploadId'], upload['Initiated']
return {'UploadId': uploadId, 'Initiated': initiated}
# Description: lookup uploaded multipart number list
def lookup_multipart_numbers(*, client, bucket, key, uploadId):
partNumberList = []
paginator = client.get_paginator('list_parts')
iterator = paginator.paginate(
Bucket = bucket,
Key = key,
UploadId = uploadId
)
for it in iterator:
if 'Parts' in it:
for part in it['Parts']:
partNumberList.append(part['PartNumber'])
return partNumberList
# Description: upload multipart data in bytes
def upload_multipart_bytes(*, client, bucket, key, body, uploadId, partNumber):
response = client.upload_part(
Body = body, Bucket = bucket, Key = key, PartNumber = partNumber, UploadId = uploadId, ContentMD5 = base64.b64encode(hashlib.md5(body).digest()).decode('utf-8')
)
eTag = response['ETag'] if 'ETag' in response else None
return {'ETag': eTag}
Handler: index.lambda_handler
Runtime: python3.7
MemorySize: 256
Timeout: 720
Environment:
Variables:
env_output: !Ref ReplikitOutputName
env_bubble: !Ref BubbleAccountId
env_region: !Ref BubbleRegionName
VpcConfig:
SecurityGroupIds:
- !GetAtt ReplikitFunctionSecurityGroup.GroupId
SubnetIds: !Split [',', !Ref PrivateSubnetIds]
Events:
SQSEvent:
Type: SQS
Properties:
Queue: !GetAtt ReplikitQueue.Arn
BatchSize: 1
Enabled: true
Policies:
- AWSLambdaBasicExecutionRole
- AWSXrayWriteOnlyAccess
- AWSLambdaVPCAccessExecutionRole
- Version: '2012-10-17'
Statement:
- Effect: Allow
Action:
- sts:AssumeRole
Resource: '*'
- Effect: Allow
Action:
- kms:Decrypt
- kms:Encrypt
- kms:GenerateDataKey
Resource: '*'
- Effect: Allow
Action:
- ssm:DescribeParameters
- ssm:GetParameter
- ssm:GetParameterHistory
- ssm:GetParameters
- ssm:GetParametersByPath
Resource:
- !Sub arn:${AWS::Partition}:ssm:${AWS::Region}:${AWS::AccountId}:parameter/*
- Effect: Allow
Action:
- SQS:GetQueueAttributes
- SQS:SendMessage
- SQS:ReceiveMessage
- SQS:GetQueueUrl
Resource:
- !Sub arn:${AWS::Partition}:sqs:${AWS::Region}:${AWS::AccountId}:*
- Effect: Allow
Action:
- s3:GetObject
- s3:GetObjectVersion
Resource:
- !Sub arn:${AWS::Partition}:s3:::*/*
ReplikitFunctionSecurityGroup:
Type: AWS::EC2::SecurityGroup
Properties:
GroupDescription: Replikit function security group
VpcId: !Ref VpcId
ReplikitFunctionLogGroup:
Type: AWS::Logs::LogGroup
Properties:
LogGroupName: !Sub /aws/lambda/Replikit-${ReplikitOutputName}
Outputs:
ReplikitQueueArn:
Value: !GetAtt ReplikitQueue.Arn
ReplikitDeadLetterQueueArn:
Value: !GetAtt ReplikitDeadLetterQueue.Arn
四)基础的网络环境中订阅并处理数据移动
一般情况下,可以借助非 VPC 内的Lambda 在 AWS 的安全网络环境中执行数据移动。本文样例代码在数据移动过程中还根据配置执行文件格式的转换和跨AWS Partition的数据移动。格式转换使用了pandas和pyarrow库支持,需要提前在Lambda Layer中创建对应的pandas和pyarrow层,方便在 Lambda 函数中引用。
样例代码 cfn-app-replikit-output-b.yaml
AWSTemplateFormatVersion: "2010-09-09"
Transform: AWS::Serverless-2016-10-31
Description: |
This template deploys a normal output of replication kit (replikit).
Parameters:
ReplikitTopicArn:
Type: String
Description: Replikit topic arn
ReplikitOutputName:
Type: String
Description: Replikit output name
BubbleAccountId:
Type: String
Description: Bubble account id
BubbleRegionName:
Type: String
Description: Bubble region name
Mappings:
PartitionMap:
aws:
domain: com.amazonaws
aws-cn:
domain: cn.com.amazonaws
Resources:
ReplikitTopicSubscription:
Type: AWS::SNS::Subscription
DependsOn:
- ReplikitQueue
Properties:
TopicArn: !Ref ReplikitTopicArn
Protocol: sqs
Endpoint: !GetAtt ReplikitQueue.Arn
RawMessageDelivery: True
ReplikitQueue:
Type: AWS::SQS::Queue
DependsOn:
- ReplikitDeadLetterQueue
Properties:
QueueName: !Sub Replikit-${ReplikitOutputName}
VisibilityTimeout: 960
RedrivePolicy:
deadLetterTargetArn: !GetAtt ReplikitDeadLetterQueue.Arn
maxReceiveCount: 8
ReplikitQueuePolicy:
Type: AWS::SQS::QueuePolicy
DependsOn:
- ReplikitQueue
Properties:
Queues:
- !Ref ReplikitQueue
PolicyDocument:
Statement:
- Effect: Allow
Action:
- SQS:GetQueueAttributes
- SQS:SendMessage
- SQS:ReceiveMessage
- SQS:GetQueueUrl
Resource: !GetAtt ReplikitQueue.Arn
Principal:
Service: sns.amazonaws.com
Condition:
StringEquals:
AWS:SourceAccount: !Ref AWS::AccountId
ReplikitDeadLetterQueue:
Type: AWS::SQS::Queue
Properties:
QueueName: !Sub ReplikitDeadLetter-${ReplikitOutputName}
ReplikitFunction:
Type: AWS::Serverless::Function
DependsOn:
- ReplikitFunctionLogGroup
- ReplikitQueue
Properties:
FunctionName: !Sub Replikit-${ReplikitOutputName}
Description: Replikit function
Layers:
- !Sub arn:${AWS::Partition}:lambda:${AWS::Region}:${AWS::AccountId}:layer:pandas:1
- !Sub arn:${AWS::Partition}:lambda:${AWS::Region}:${AWS::AccountId}:layer:pyarrow:1
InlineCode: |
import io
import os
import boto3
import json
import logging
import pandas
# Logger (change log level to your env stage)
logger = logging.getLogger()
logger.setLevel(logging.INFO)
# Handler
def lambda_handler(event, context):
# Get sessions
kitSession = boto3.session.Session()
srcSession = None
desSession = None
# Get environments and params
desOutput = os.environ['env_output']
desRegion = os.environ['env_region']
desBubble = os.environ['env_bubble']
desParams = json.loads(
kitSession.client('ssm').get_parameter(Name = '/Replikit/{0}'.format(desOutput))['Parameter']['Value']
)
desBucket = desParams['des_bucket']
desPrefix = desParams['des_prefix']
try:
pivotRole = 'arn:{0}:iam::{1}:role/{2}'.format(
'aws-cn' if (desRegion.lower() == 'cn-north-1' or desRegion.lower() == 'cn-northwest-1') else 'aws', desBubble, 'ReplikitPivotRole'
)
pivotResp = kitSession.client("sts", endpoint_url = "https://sts.{0}.amazonaws.com".format(kitSession.region_name)).assume_role(
RoleArn = pivotRole, RoleSessionName = 'ReplikitPivotRole'
)
desSession = boto3.Session(
aws_access_key_id = pivotResp["Credentials"]["AccessKeyId"],
aws_secret_access_key = pivotResp["Credentials"]["SecretAccessKey"],
aws_session_token = pivotResp["Credentials"]["SessionToken"]
)
logger.info(
"Session is created with short-term credentials for bubble account {0}.".format(desBubble)
)
except:
desAccess = json.loads(
kitSession.client('ssm').get_parameter(Name = '/Replikit/{0}/{1}'.format(desOutput, desBubble), WithDecryption = True)['Parameter']['Value']
)
desSession = boto3.Session(
aws_access_key_id = desAccess['aws_access_key_id'],
aws_secret_access_key = desAccess['aws_secret_access_key'],
region_name = desRegion
)
logger.info(
"Session is created with long-term credentials for bubble account {0}.".format(desBubble)
)
finally:
if not srcSession:
srcSession = boto3.session.Session()
# Loop messages for replication
for message in event['Records']:
msgId = message['messageId']
msgReceives = message['attributes']['ApproximateReceiveCount']
logger.info(
"Message {0} is in process upon #{1} receives.".format(msgId, msgReceives)
)
msgBody = json.loads(message['body'])
for record in msgBody['Records']:
srcEvent = record['eventName']
if 'ObjectCreated:' in srcEvent: # Filter event name
srcBucket = record['s3']['bucket']['name']
srcKey = record['s3']['object']['key']
if srcKey.endswith('/'): # No need to process a folder
continue
logger.info(
"S3 event configuration {0} enables replication from object {1} in bucket {2}.".format(record['s3']['configurationId'], srcKey, srcBucket)
)
# Example: Replicate object with parquet2csv formatting.
# TO-DO: add more condition checks
desKey = ("{0}{1}.csv" if desPrefix.endswith('/') else "{0}/{1}.csv").format(desPrefix, srcKey)
upsert_parquet2csv(
srcClient = srcSession.client('s3'), srcBucket = srcBucket, srcKey = srcKey, desClient = desSession.client('s3'), desBucket = desBucket, desKey = desKey
)
# Description: upsert S3 object in putobject with parquet2csv transformation.
def upsert_parquet2csv(srcClient, srcBucket, srcKey, desClient, desBucket, desKey):
logger.info(
"Function upsert_parquet2csv is triggered. (src bucket = {0}, src key = {1}, des bucket = {2}, des key = {3})".format(srcBucket, srcKey, desBucket, desKey)
)
# Naive check on file format
if not srcKey.lower().endswith('.parquet'):
raise Exception("InvalidParquetSuffix")
if not desKey.lower().endswith('.csv'):
raise Exception("InvalidCSVSuffix")
# S1: read parquet file
objFrame = pandas.read_parquet(
io.BytesIO(srcClient.get_object(Bucket = srcBucket, Key = srcKey).get('Body').read())
)
# S2: write csv file
with io.BytesIO() as desBuffer:
objFrame.to_csv(desBuffer, index = False)
putResp = desClient.put_object(
Bucket = desBucket, Key = desKey, Body = desBuffer.getvalue()
)
return {}
Handler: index.lambda_handler
Runtime: python3.7
MemorySize: 256
Timeout: 720
Environment:
Variables:
env_output: !Ref ReplikitOutputName
env_bubble: !Ref BubbleAccountId
env_region: !Ref BubbleRegionName
Events:
SQSEvent:
Type: SQS
Properties:
Queue: !GetAtt ReplikitQueue.Arn
BatchSize: 1
Enabled: true
Policies:
- AWSLambdaBasicExecutionRole
- AWSXrayWriteOnlyAccess
- AWSLambdaVPCAccessExecutionRole
- Version: '2012-10-17'
Statement:
- Effect: Allow
Action:
- sts:AssumeRole
Resource: '*'
- Effect: Allow
Action:
- kms:Decrypt
- kms:Encrypt
- kms:GenerateDataKey
Resource: '*'
- Effect: Allow
Action:
- ssm:DescribeParameters
- ssm:GetParameter
- ssm:GetParameterHistory
- ssm:GetParameters
- ssm:GetParametersByPath
Resource:
- !Sub arn:${AWS::Partition}:ssm:${AWS::Region}:${AWS::AccountId}:parameter/*
- Effect: Allow
Action:
- SQS:GetQueueAttributes
- SQS:SendMessage
- SQS:ReceiveMessage
- SQS:GetQueueUrl
Resource:
- !Sub arn:${AWS::Partition}:sqs:${AWS::Region}:${AWS::AccountId}:*
- Effect: Allow
Action:
- s3:GetObject
- s3:GetObjectVersion
Resource:
- !Sub arn:${AWS::Partition}:s3:::*/*
ReplikitFunctionLogGroup:
Type: AWS::Logs::LogGroup
Properties:
LogGroupName: !Sub /aws/lambda/Replikit-${ReplikitOutputName}
Outputs:
ReplikitQueueArn:
Value: !GetAtt ReplikitQueue.Arn
ReplikitDeadLetterQueueArn:
Value: !GetAtt ReplikitDeadLetterQueue.Arn
五)定向配置
数据移动依据Amazon System Manager Parameter Store中的/Replikit/<output-name>参数配置进行输出。
{
"des_bucket":"test-bucket-in-your-bubble",
"des_prefix":"test-prefix-in-your-bucket"
}
六)凭证配置
数据移动依据 Amazon System Manager Parameter Store中的/Replikit/<output-name>/<bubble-account-id>参数获取长期凭证,参数务必使用KMS 加密的 Secure String 保存。
{
"aws_access_key_id":"test-access-key-of-your-bubble-user",
"aws_secret_access_key":"test-secret-key-of-your-bubble-user"
}
讨论
一)静态加密
请根据安全合规的要求修改部署模板,使用客户CMK进行KMS加密,需要对数据加密的对象包括:S3、SNS、SQS、Parameter Store。
二)传输加密
请根据安全合规的要求审查和修改Inline代码,确保出Internet的流量使用SSL/TLS加密。
三)ReplikitPivotRole权限
请根据安全合规的要求审查和修改部署模板,控制ReplikitPivotRole对消费者账号的资源访问权限。
四)长期凭证的定期轮换
请根据安全合规的要求定期轮换AKSK,并在Parameter Store中更新。