亚马逊AWS官方博客
利用CloudEndure进行On-Prem到AWS云上灾备的最佳实践
在面对潜在灾难时,企业需确保其关键业务系统的韧性和故障恢复能力。为了应对灾难事件,作为一名容灾老兵,CloudEndure仍然在为AWS中国区域用户提供弹性灾难恢复服务来执行故障转移,确保业务的连续性。CloudEndure用于执行托管在数据中心本地或任何其他云平台上的服务器的灾难恢复,它允许使用经济实惠的存储、最少的计算资源和持续性数据复制等技术将停机时间和数据丢失降至最低,同时提供了非干扰性故障回退测试的优势,使得企业能够在不影响现有业务的情况下进行灾难恢复演练,从而实现本地和基于云的应用程序的快速、可靠恢复。
在众多迁移/容灾工具中, CloudEndure主要优势体现在以下几个方面:
- 操作流程简化,自动化水平高,大幅降低了迁移和容灾的复杂度,提高了用户体验。
- 适用范围广泛,只要操作系统满足Agent安装条件,且Agent可访问CE服务器,即可支持物理主机、虚拟机和云主机的迁移/容灾。
- 采用基于操作系统的连续数据块级复制技术,实现了毫秒级的恢复点目标(RPO),分钟级的恢复时间目标(RTO),确保了数据复制的高效与实时性。
- 数据复制过程对云端资源占用少,有效降低了容灾的运行成本,提高了经济性。
在这篇博客文章中,将重点关注在利用CloudEndure进行On-prem至AWS中国区域进行平稳故障转移和故障回退时可以遵循的最佳实践。
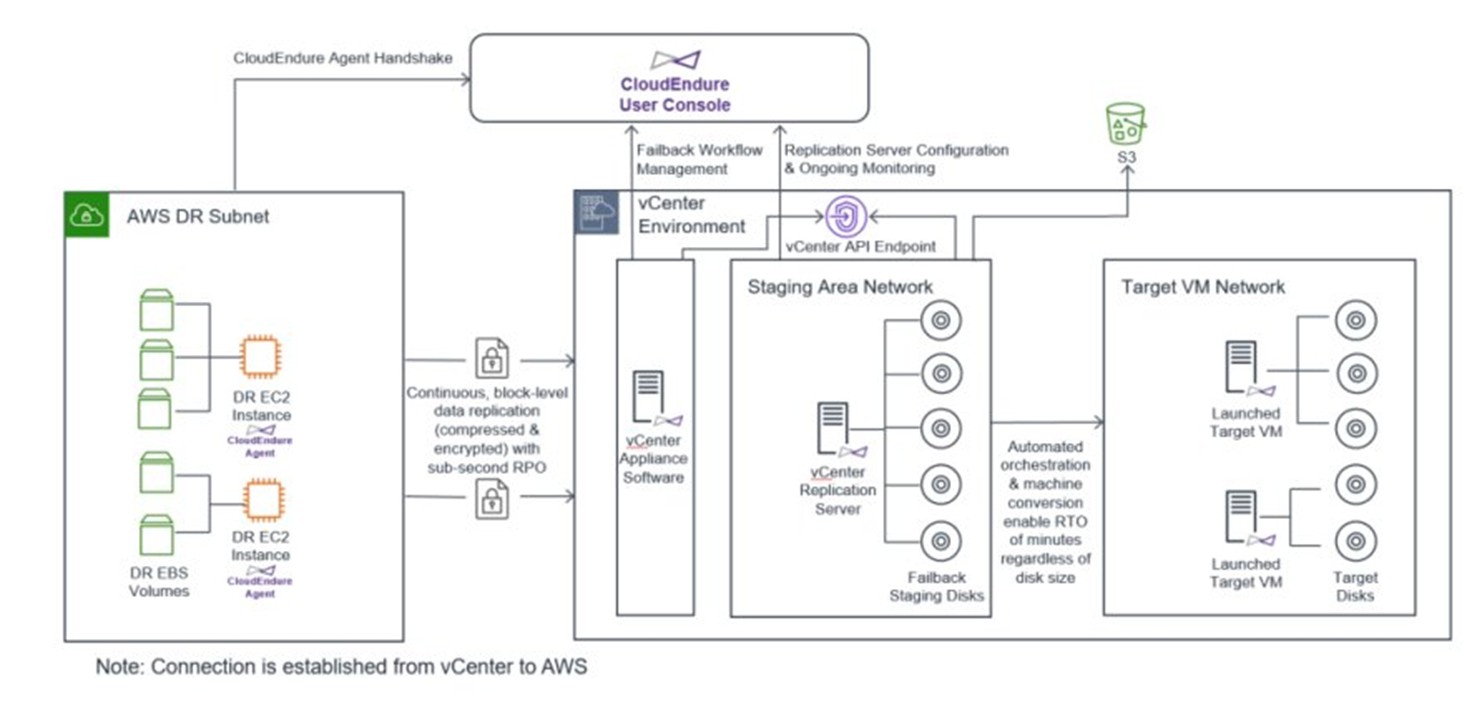
CloudEndure Disaster Recovery 核心组件
我们可以按照功能角色将CloudEndure 分为三个主要组件,它们组合起来形成数据复制流。
第一个区域是源区域,这是 CloudEndure 代理运行的位置,CloudEndure的代理安装在源操作系统,支持数据中心物理机器、任何Hypervisor的虚拟机和云主机,同样支持在AWS的区域或可用性区之间进行复制和容灾。CloudEndure代理执行两项任务,第一个是对连接到源系统任何卷的内容进行初始块级读取,并将内容一次性复制到目标云位置,可能需要几分钟到几天的时间,具体取决于要复制的数据量以及源和目标之间的可用网络带宽;第二个是实时监控对源系统任何卷的所有块级修改,在初始复制完成后,位于目标AWS区域的 CloudEndure 复制实例将持续同步到最新的块级修改,从而提供接近于零的 RPO(恢复点目标)。
第二个区域是暂存区,参考守夜灯的设计,负责承载复制需求和容灾数据存储。在初始化配置完成后,CloudEndure会在该区域生成复制实例,并会为要保护的每个源系统的硬盘创建一个 EBS 卷,并挂载给复制实例。复制实例从源接收数据并将块数据写入相应的 EBS 卷,其中EBS卷的数量和源系统的物理或虚拟硬盘的数量1:1对应,EBS 卷的大小按照源系统硬盘的裸容量大小而非实际使用容量大小进行分配。每个复制实例最多挂载15个EBS卷,超过该数量即再生成一个复制实例,这里EBS卷可以支持选择低成本的存储类型;若单个源系统的硬盘数量超过15个,则可为该源配置一台专用的复制实例。
第三个组成区域是容灾恢复区域,用于承载容灾业务的恢复,在启动故障转移或演练测试后,已复制到暂存区域的数据将编排并转换为生产级实例或测试实例。
 |
持续数据保护
CloudEndure复制技术核心是CDP持续数据保护引擎,可提供实时的、异步的、基于块级别的复制。CDP 会保留系统的所有更改,直到发生故障之前的最后一次写入,将增量即数据的任何更改从源复制到目标,从而允许恢复到该故障点发生之前的最新状态。在CDP状态下可达到亚秒级别的RPO,另外使用连续同步还消除了基于快照的复制引起的潜在性能问题。在网络、IO性能等条件较差时,数据复制会脱离CDP连续数据保护模式,此时则需要关注以下三个信息:
- LAG延迟:自服务器上次处于 CDP 模式以来的时间量。延迟取决于多个因素,例如复制速度、可用网络带宽、总体磁盘存储、复制数据时磁盘的变化以及存储的 I/O 速度。
- Backlog积压:已写入磁盘但仍需要复制才能达到 CDP 模式的数据量。
- ETA:返回 CDP状态 的预计剩余时间。
CloudEndure复制规划和策略
复制代理应安装在我们需要复制到 AWS 的每个源系统上,需要设置复制设置参数,包括暂存区域子网、要复制到 AWS 的服务器实例类型、EBS 卷类型、EBS 加密设置等。
最佳实践是使用用户的 AWS 账户为所有恢复实例创建一个专用、单独的子网,在执行数千台服务器的恢复时,可以使用多个子网。 使用多个暂存区域子网可能会导致更高的消耗,因为需要更多的复制服务器。当服务器写入量很大时,将数据从其磁盘复制到共享复制服务器可能会干扰其他服务器的数据复制,因此建议使用专用复制服务器,当然使用专用复制服务器可能会增加在复制过程中的 EC2 成本。
自动卷类型选择根据磁盘写入吞吐量在性能/成本优化类型之间动态切换,选择动态切换时需要给IAM用户添加额外的EBS管理权限, 最佳实践是使用默认值,除非业务需要更改。 对于安全组,建议使用默认的CloudEndure恢复安全组。
目标启动蓝图设置
目标启动设置决定如何在 AWS 中启动恢复实例。 启动设置包括 CloudEndure 启动设置和 EC2 启动模板。
对于启动设置,以下设置是最需要考虑的。
- 实例类型正确调整大小
- 启动时实例
- 复制私有IP
- 传输服务器标签
- 操作系统许可
在代理安装期间由 CloudEndure 创建的原始启动模板可以作为默认设置。 另外还可以根据需求通过 CloudEndure 控制台进行更改。根据以下准则在 Amazon EC2 控制台中调整 IOPS(每秒输入/输出操作数):
- 预配置 IOPS SSD (io1):每 GiB 存储 50 IOPS
- 预配置 IOPS SSD (io2):每 GiB 存储 500 IOPS
- 通用 SSD (gp3):每 GiB 存储 500 IOPS
复制网络
建议提供专线链路的专用带宽以提供稳定的连接。CloudEndure支持调整或限制复制带宽, 调整带宽大小时应考虑的因素包括必须传输的数据总量、源服务器的磁盘写入速度、源磁盘 I/O,为了确保达到CDP状态,CloudEndure默认情况下会尽量激进的占用最大带宽。如果源的硬盘性能高于云上存储性能,则会产生滞后CDP状态的情况。由于硬盘的所有写入量都将转化成数据复制的网络流量,考虑到专线价格较高,因此建议过滤掉没有必要进行灾备的写流量比如归档、备份与某些追踪日志等以优化复制网络带宽占用。
除了专线外复制链路也支持VPN,但如果计划使用 VPN 通过共享连接进行复制,用于复制服务器的可用网络带宽将会有所不同。 这可能会导致 CloudEndure 复制代理进入停滞、不健康或滞后状态,并可能给容灾计划带来风险。
CloudEndure 复制速度同样取决于复制服务器接收数据块并将块写入附加 Amazon EBS 卷的能力。 除了默认 I/O 和文件系统缓冲之外,CloudEndure 在复制实例端没有任何形式的队列或缓存。 这意味着直到前一个数据块已写入暂存区,否则要复制的下一个数据块将不会离开源系统。 如果复制实例由于网络瓶颈、CPU 利用率问题或磁盘 I/O 瓶颈而无法跟上更改速度,则复制将开始滞后,RPO 将增长。
实现On-prem至AWS中国区的云上灾备的具体步骤
CloudEndure可以支持多种源机器向云端进行备份, 本文以Windows Hyper V虚拟机向AWS中国区进行云上灾备为例说明具体步骤:
CloudEndure账号申请及相关软件的下载及安装
- 账号注册: https://console.awscloudendure.cn/#/register/register
- Console: https://console.awscloudendure.cn/
- Failback客户端下载: https://console.awscloudendure.cn/api/v5/failback_livecd.iso
配置准备
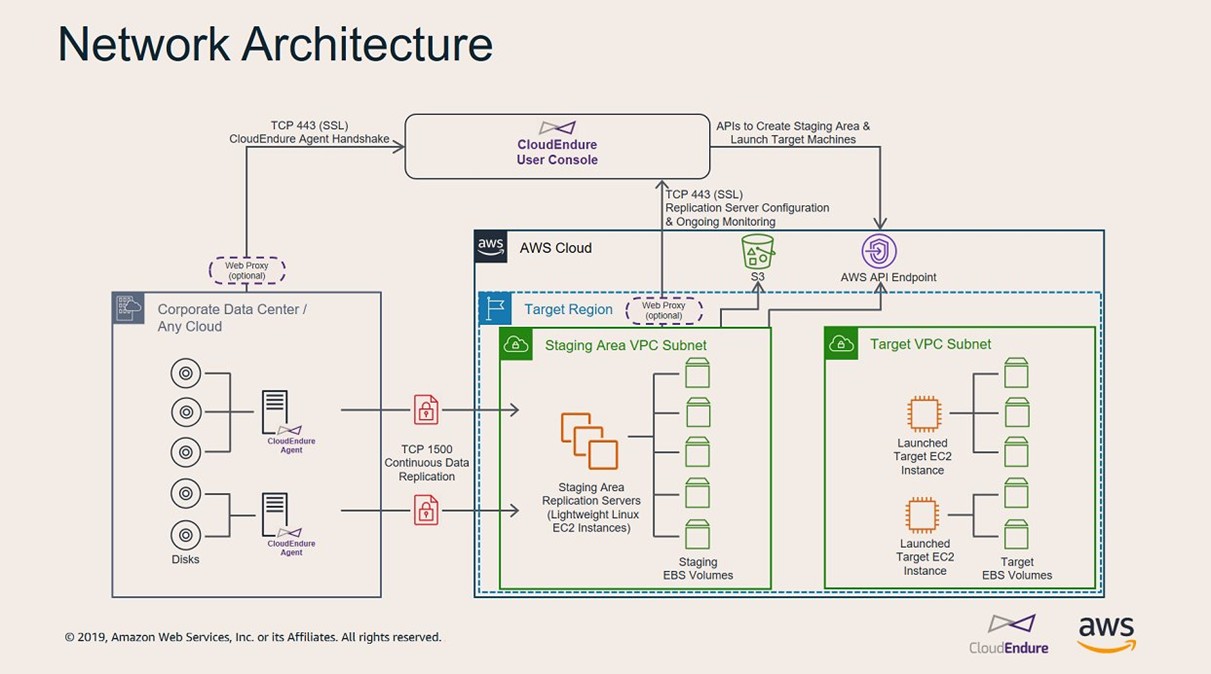 |
- 端口要求:为了进行连接,应打开以下 TCP 端口:
- 端口 443 用于源服务器和 CloudEndure Console 之间的通信。
- 端口 443 用于暂存区域子网和 CloudEndure 之间通信。
- 在每个源服务器上应允许出站 443 端口。
- 暂存区域子网和 CloudEndure 之间通过 TCP 端口 443 进行通信。
- 源服务器和暂存区域子网之间通过 TCP 端口 1500 进行通信。
- 外网访问设置
防火墙需要允许本地服务器访问https://console.awscloudendure.cn/ (ip = 54.223.37.239, port = 443)
- S3访问需求:
下载 CloudEndure 复制软件需要Failback client启动后可以访问 Amazon S3 存储桶,因此 AWS Replication Agent 应能够访问与 CloudEndure 结合使用的 AWS 区域的 S3 存储桶 URL 和暂存区域子网。
CloudEndure项目创建及初始配置
- 在AWS控制台创建CloudEndure需要的IAM user
可参考如下json创建 IAM 角色, 并且记录Access KeyID和Secret access key,后续需要使用。
- 登录CloudEndure Console: https://console.cloudendure.com。在左上角,点击Create New Project,输入项目名称,选择项目类型(容灾),目标端只能是AWS,下面会显示License信息。
- 在Setup & Info → AWS Credentials中输入上一步获取的IAM User的 Access Key ID /Secret Access Key
- 在Setup & Info → Replication Setting中,选择源和目标的AWS区域。
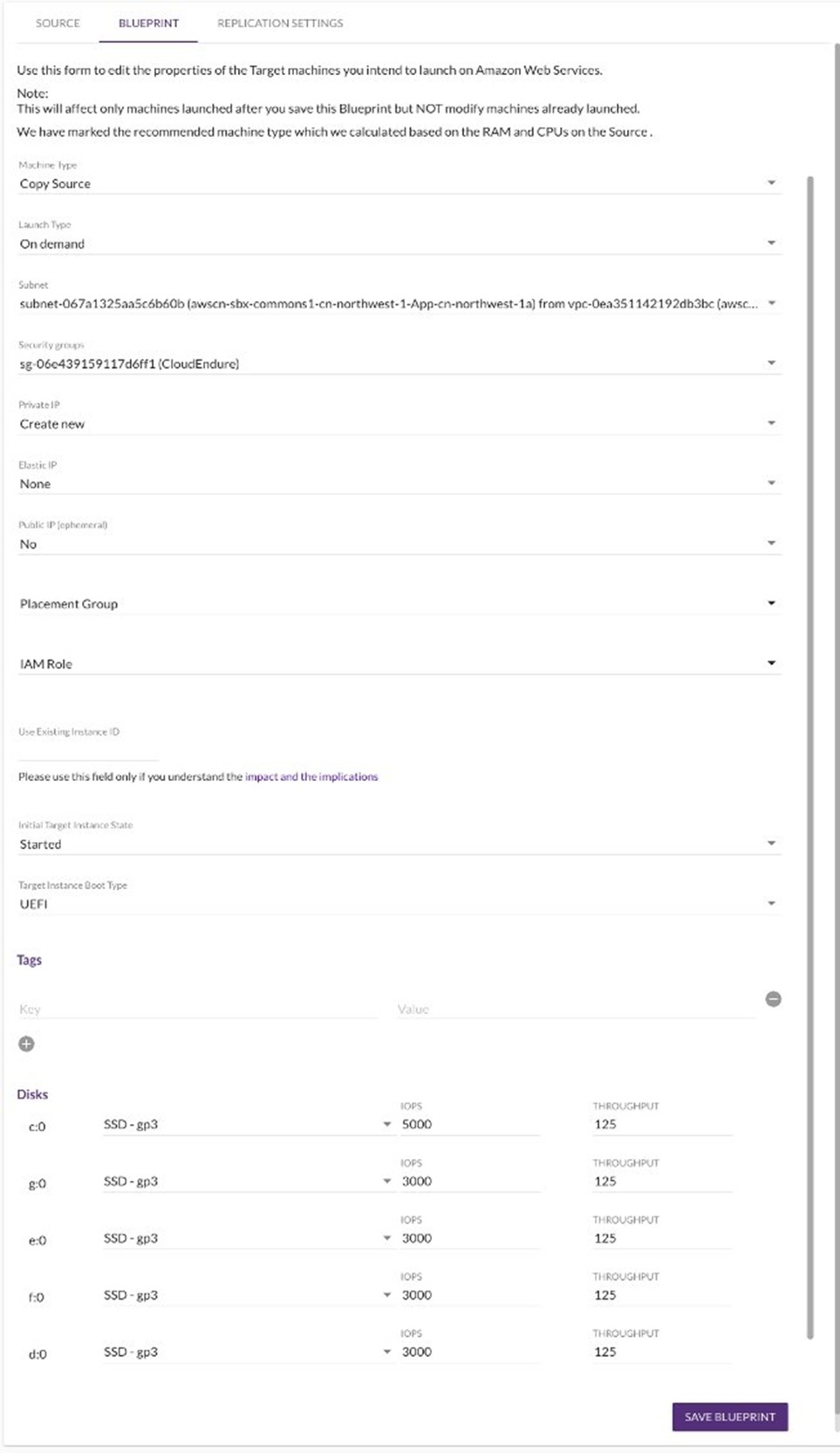
- 在Replication Servers中,对复制服务器进行配置
a. 选择复制服务器实例类型为“Default”,缺省为small;
b. 如勾选Dedicated Replication Servers,则每台源服务器会配置一个xlarge的复制服务器,缺省为“空”表示系统会根据每15块源数据盘配置一个复制服务器;
c. 输入复制服务器所在的子网段和安全组;
d. 在Network Bandwidth Throttling选项中,选择Disabled,如果需要让复制不占用太多网络带宽,可以取消Disabled并设置允许的最大复制带宽。
- 在Setup & Info tab → OTHER SETTINGS → Installation Token 中点击 GENERATE NEW TOKEN 来获取在源机器中安装agent时所需要的installation token
- 参考下图进行replication设置
 |
源服务器(Windows HyperV)配置
- Agent下载: https://console.awscloudendure.cn/installer_win.exe
- 在源机器(windows Hyper-V)上进行安装
- 输入之前步骤中获取的installation token
初次数据全量复制
- 在源机器安装完Agent后,会发起初次全同步,可以在Console主界面的Machines里面查看数据同步的进程。
- CE服务会自动在AWS账户中创建复制实例, 每个复制实例最多可以承载15个盘的复制。复制实例默认为small规格, 根据复制数据量可以进行调整。
- 最终会显示Continuous Data Protection的状态。同时,在AWS Seoul区里会出现一台复制服务器实例。
故障切换 (FailOver)
切换是指在AWS目标区域生成容灾服务器的过程。CE服务器会通过API将复制服务器上存储的时间点快照生成EBS卷,并根据用户定义的Blueprint 启动Target Instances 。切换方式可以分为Test Mode (测试模式)和Recovery Mode(恢复模式)。测试模式可以多次启动。恢复模式切换是指灾难发生或者进行灾难演练,将应用切换到AWS云端服务器。此时,应用已不在本地源服务器运行,源端(HyperV)和目标端(AWS)的连续数据复制会停止。
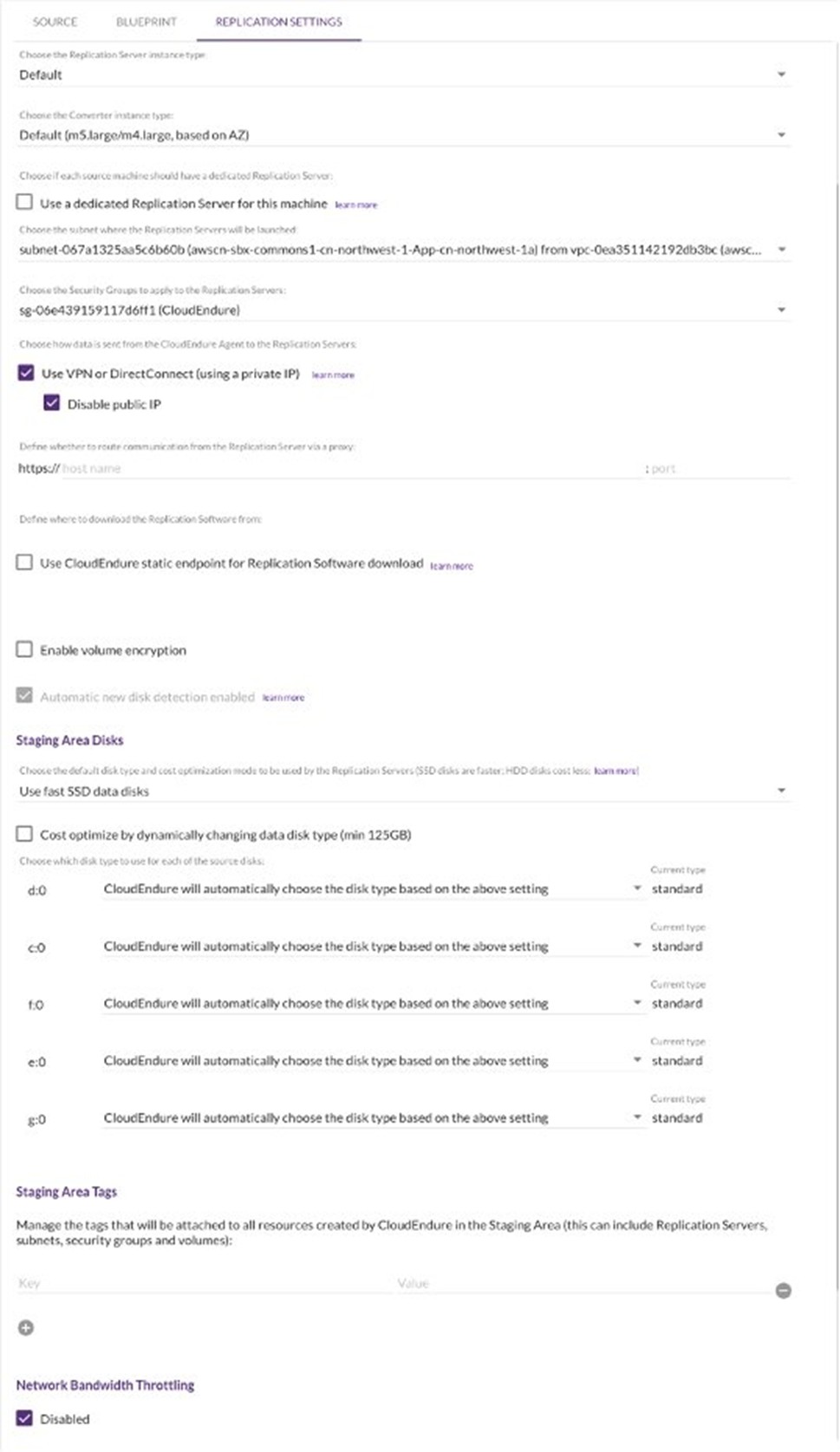
- 参考下图进行blueprint设置。其中Blueprint的IP设置,取决于failover后aws上的机器是否需要用到public ip。如果都是内网,不需要public ip。假定需要public IP的话,可以设定使用elastic IP或者public IP(ephemeral)。
 |
- 在Console右上角,选择Initiate Recovery Plan → Test Mode开始进行测试模式切换。
- 系统会跳出一个菜单让你选择恢复时间点。通常选择“latest”时间点恢复容灾实例。当发生数据误删除、服务器中病毒等情况,你可能会需要选择某一个时间点恢复服务器。
故障回切 (FailOver)
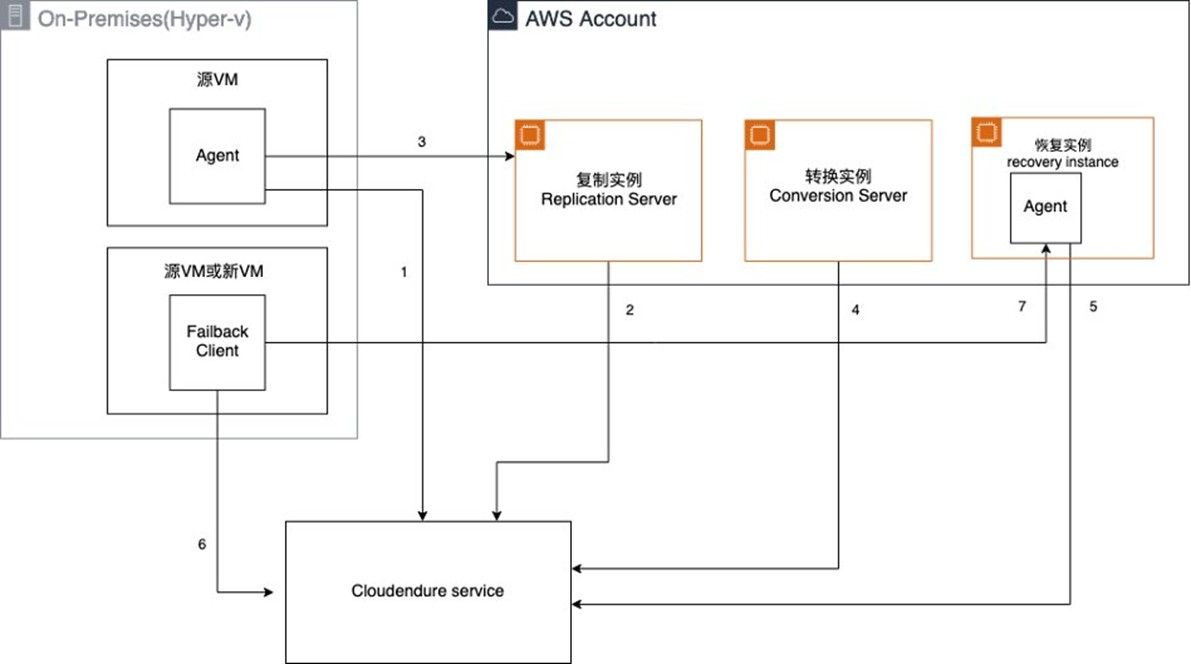 |
Failback指的是在故障切换后将操作恢复到原始源基础架构的过程。此过程涉及将数据复制的方向从目标基础架构(灾难恢复站点)恢复到原始源基础架构。在达到CDP(持续数据复制)状态后,用户可以执行Failover故障切换。可以选择一个时间点(PIT)的快照进行启动,CloudEndure服务随后将启动一个转换实例,在所选时间点的快照上执行卷的转换,并将转换后的快照作为输出。
- 准备Failback:
- 确保CloudEndure项目中的所有源机器都已经在测试或恢复模式下启动了目标机器(即Failover成功)。
- 在CloudEndure用户控制台的PROJECT ACTIONS菜单下启动“准备Failback”操作。
- Project将显示“准备恢复到原始源”,机器将在DATA REPLICATION PROGRESS列下显示“启动数据复制”。
- Failback客户端下载和设置:
- 从CloudEndure用户控制台的Replication Settings部分下载Failback客户端。
- 在Hyper-V中将目标机器(VM)引导到CloudEndure Failback客户端镜像(iso)。
- 在提示时输入CloudEndure安装令牌。
- Failback客户端流程:
- Failback客户端将经历多个步骤:
- 认证Failback客户端和确定要恢复的EC2实例。
- 在机器上映射卷,如果需要,可以自动或手动进行。
- 下载CloudEndure Replication Software并进行配置。
- 验证EC2实例与CloudEndure Service Manager的连接。
- 与运行在EC2实例上的CloudEndure Agent配对。
- 通过端口1500与CloudEndure Agent建立连接。
- 初始数据复制开始。
- Failback客户端将经历多个步骤:
- 启动目标机器:
- 一旦初始复制完成,为失败的机器启动新的目标机器。
- 选择最新的恢复点,然后点击“CONTINUE WITH LAUNCH”。
- Failback完成:
- 在测试或恢复完成后,Failback客户端将指示Failback已完成,并将重新启动机器。
- 目标机器将弹出Failback客户端并重新引导到新的操作系统。
- 返回正常运行:
- 在所有机器都恢复后,选择Project Actions并点击“Return to Normal Operation”。
- Failback项目已配置为再次复制到目标基础架构,从原始源复制到原始目标。
注意事项
- Failback启动新的机器时,CloudEndure不会删除源VM,旧的源VM需要手动清理。
- 如果使用源VM,failback时会进行block level的校验,只回传delta变量数据,速度较快,建议对源VM先在Hypervisor做快照;相反若使用一台新VM引导failback client,则会failback全部recovery instance的数据。
- 如果在Other Infrastructure(非AWS)源上启动Failback客户端,暂不支持Failback自动化。
停机时间考虑
- Failback期间的停机时间受多种因素的影响,例如完成Failback客户端过程、启动新目标机器以及恢复正常操作的时间。
- 为了最小化停机时间,关键是确保每个Failback过程步骤的顺利执行,包括在没有中断的情况下运行Failback客户端。
- 为了减小停机时间,请确保在Failback过程中的每个步骤中都能够平稳无阻地执行,包括在不同步之间运行Failback客户端。
小结
本文介绍了CloudEndure的功能和特点,并着重介绍了如何对本地源服务器进行云上灾备的步骤和注意事项
参考资料
CloudEndure官方文档: https://docs.cloudendure.com
*前述特定亚马逊云科技生成式人工智能相关的服务目前在亚马逊云科技海外区域可用。亚马逊云科技中国区域相关云服务由西云数据和光环新网运营,具体信息以中国区域官网为准。
本篇作者
AWS 架构师中心:云端创新的引领者探索 AWS 架构师中心,获取经实战验证的最佳实践与架构指南,助您高效构建安全、可靠的云上应用
|
 |
