亚马逊AWS官方博客
使用大模型技术构建机票分销领域人工智能客服助手
 |
一. 需求背景
1.1 行业痛点
在机票分销领域,大型票务代理是供应链的中转枢纽,他们上游对接各大航空公司,下游对接各中小型票务代理、OTA(Online Travel Agency在线旅行社)或者旅行社等。大型票务代理通常会部署虚拟客服系统,来应对其下游生态圈企业的机票查询、预定和退改签等咨询业务。然而由于传统虚拟客服在技术上的局限性,用户经常遭遇“听不懂”、“答不准”或者“答非所问”等尴尬。
随着人工智能技术的飞速发展,利用大语言模型等技术,实现更准确更聪明的人工智能客服助手成为了可能。然而,对于大型票务代理来说,这件事并不简单。
构建机票分销领域人工智能客服助手的难点主要体现在以下几个方面:
- 知识分散且零散:文档种类多样,且分散在不同地方保存;
- 知识专业性强:机票销售领域知识,与通用知识存在很大的差异性;
- 提问方式较随意:客户提问时口语化、随意化,且经常夹杂行业“黑话”;
- 常规方案准确率低:具体表现在不能正确理解问题,回答错误或者胡编乱造(幻觉)。
1.2 项目目标
本项目的目标是构建一套机票分销领域人工智能客服助手,主要实现以下功能:
- 集中存储行业知识:零散分布的行业领域文档,如机票分销基础知识、航司近期活动、运营政策等,经过预处理后,将向量化知识分块集中存储和管理;
- 准确理解用户意图:从自然语言中准确识别用户的意图,例如询问的是运营政策、退改签政策,还是近期某航司是否有活动等;
- 精准检索行业知识:能够从知识库中准确找到指定信息,例如某航司团队票是否可以按散客票出票;
- 生成标准答案:能够从检索到的知识中加工并处理成大型票务代理预期的正确答案;
- 高容错性:能够处理不同的口语化表达,并识别行业内才能听懂的“黑话”,例如“出配置”、“打配置”、“本地没牌”等。
二. 方案概述
2.1 系统架构
系统总体架构如下图所示,与标准RAG(Retrieval-Augmented Generation检索增强生成)架构基本一致但稍有区别。由数据预处理、知识库存储、查询解析、检索、文本生成、用户交互界面等模块组成。各个模块分别执行独立的任务,并与其他模块进行配合,形成完成的处理流程。
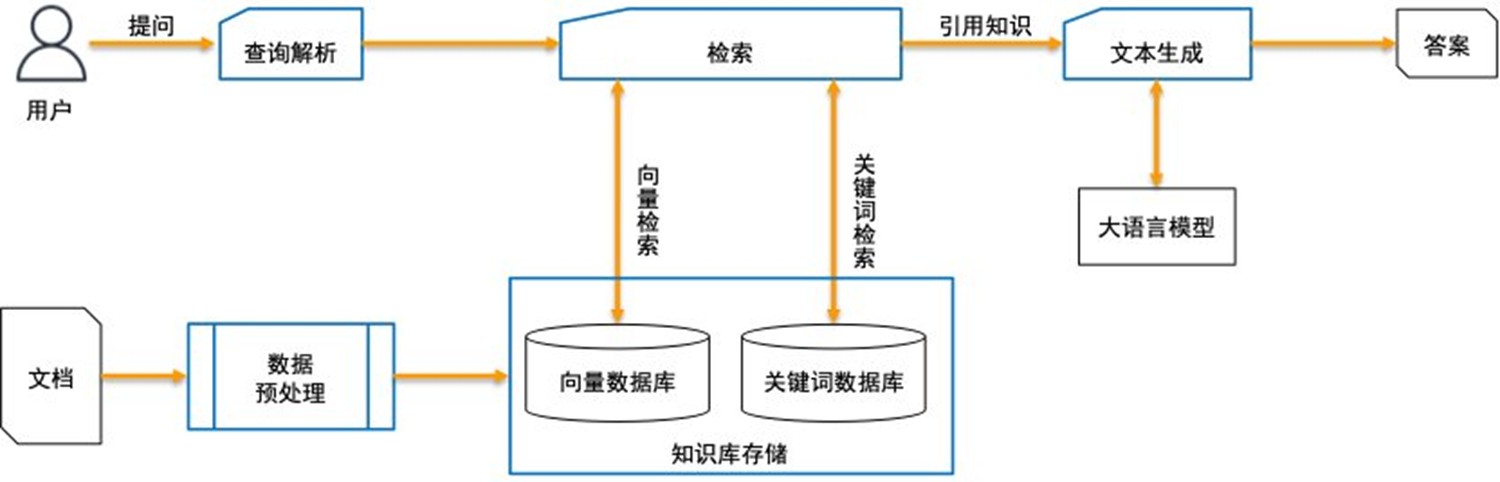 |
2.2 系统核心模块
2.2.1 数据预处理
数据预处理是构建高质量问答系统的关键环节,主要目的是将原始知识内容转换成适合检索和生成使用的格式,其主要功能包括:
- 文本清洗与格式统一:例如去除无用符号、空格、换行、标点符号、无用信息,将文本格式整理为统一格式等;
- 分段与结构化拆分:将长文本按照段落或语义切分为不同分段(Chunk)或问答对等;
- 词嵌入(Embedding)向量化准备:去除不适合向量化的内容。
2.2.2 知识库存储
知识库存储提供了各类文档存储和管理的功能,其主要功能包括:
- 知识内容管理:支持存储各种类型的文本,并对内容进行管理;
- 向量化索引支持:将文本内容进行词嵌入(Embedding)向量化,并构建向量索引;
- 关键词索引支持:支持关键词级别的高效查询;
- 提供检索接口:提供支持多种检索方式的接口,供RAG框架调用。
2.2.3 查询解析
查询解析模块借助大语言模型,对用户输入进行解析,精准识别用于意图。主要功能包括:
- 意图识别:识别用户提问的意图,如询问退改签政策、运营政策、航司活动等不同诉求;
- 关键词提取:提取用户提问中的关键实体、词汇,例如X航、XX航空等;
- 上下文理解:多轮对话场景中,当前问题结合历史上下文(聊天记录)进行解析;
- 行业“黑话”:对只在机票分销领域出现的专有名词进行识别和解析,例如“出配置”、“大配置”、“本地没牌”等。
2.2.4 混合检索
- 向量检索
向量检索模块是构建知识库系统的核心技术之一,它通过将文本信息编码成向量,再进行相似度计算,实现用户提问与知识库内容的匹配,其主要功能包括:
- 文本向量化:通过词嵌入(Embedding)模型将文档转换为向量,便于计算机处理;
- 相似度计算:通过算法找到与用户输入最相似的知识库内容;
- 支持模糊表达:用户表达可能是口语化、不完整,或者同义词,向量检索可以支持这种模糊表达,识别其含义。
- 关键词检索
关键词检索通过匹配用户查询中的关键词,实现高效、精准的内容定位和快速召回,其主要功能为:
- 快速定位精确匹配内容:精准命中包含关键词的文本片段、标题或字段;
- 补充向量检索盲点:对专有名词难以向量化的关键词进行补充检索,提升召回率;
- 实现混合检索:在向量检索后,可能出现多段内容相似,此时通过关键词检索再次进行过滤,更精准的找到所需知识库内容。
- 混合检索
本项目中,我们将向量检索和关键词检索结合使用,这么做的优势有如下几点:
- 先广后精,保证召回质量 + 补充覆盖率;
- 提升重要关键词的召回优先级;
- 增加参考信息的多样性,利于生成更完整回答。
2.2.5 文本生成
文本生成模块通过调用大语言模型回答用户提问,实现智能问答,其主要功能包括:
- 基于检索内容生成自然语言回答:将检索到的知识,结合用户提问,生成语句通顺、语义完整、有针对性的回答;
- 补全知识内容中的语义空白:当检索或表达不完整时,大模型可以通过推理来构建完整的逻辑链条,以此来提高问答的完整性;
- 提升多轮对话的上下文连贯性:在用户多轮提问的场景下,结合上下文形成连贯自然的回答。
2.2.6 用户交互界面
用户交互界面提供简单易用的人机交互方式,用户输入自然语言提问,系统可以检索知识并返回自动生成的答案。其主要功能包括:
- 用户输入处理:提供交互窗口,接受用户的自然语言输入,为后续处理做准备。
- 结果展示:直观展示生成的答案(文本内容),供用户查看并等待用户下一步指令;
- 错误处理:如果系统运行中报错,将错误信息直观展示给用户供其故障排查;
- 用户反馈:如果用户对系统生成的答案不满意,可以在界面上进行反馈。
三. 技术实现
3.1 数据处理
根据经验,将数据按照不同组织形式进行针对性处理,会有效提高知识库问答准确率。数据预处理这一步骤主要的作用是将原始文档按照不同文本形式拆分并转换后,再合并成新的处理后的文档,之后将其内容注入向量数据库,并提取关键词注入关键词数据库,如下图所示:
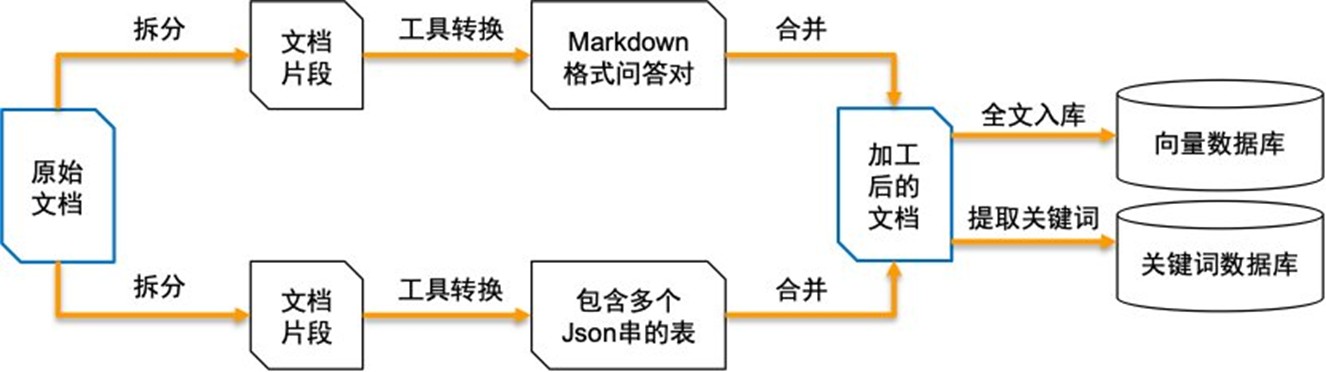 |
以下是原始文档处理后的Markdown格式问答对:
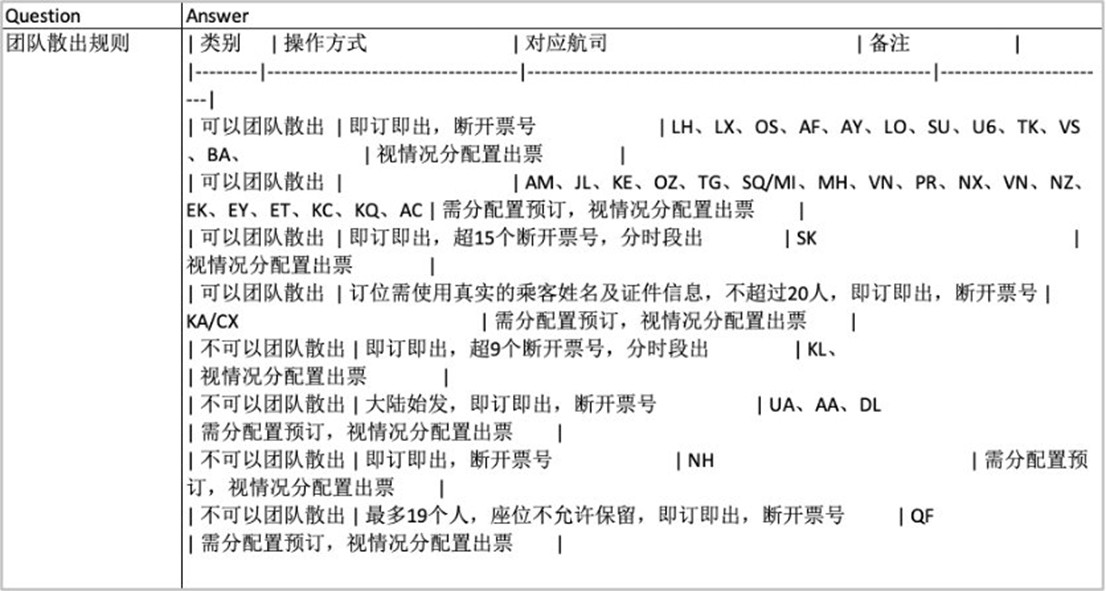 |
以下是原始文档处理后的包含多个Json串的表:
 |
3.2 知识库存储
知识库存储由向量数据库和关键词数据库两部分组成,分别用于向量检索和关键词检索。
3.2.1 向量数据库
经过评估,我们选择了DocArrayInMemorySearch作为向量数据库,其作为内存型向量数据库,有以下优势:
- 开箱即用、无需部署数据库:直接使用Python引入即可使用,不需要额外部署;
- 支持多模态数据结构:支持多模态数据的表示与检索;内置DocArray文档结构,字段灵活,支持带元数据、标签的检索;
- 支持嵌套结构与批量操作:支持嵌套文档结构(如带上下文的QA对),方便组织复杂文档;提供批量插入、批量检索等常用API,简单易用。
向量数据库创建的部分代码如下:
3.2.2 关键词数据库
关键词数据库,我们选择了defaultdict,它具有以下优势:
- 自动为关键词初始化:defaultdict 可以自动为每个关键词初始化一个空列表,避免手动判断关键词是否存在;
- 结构简单、访问速度快:本质是哈希表,适合快速匹配关键词,速度快、延时低;
- 方便与RAG系统结合使用:可以作为向量检索的补充;支持一对多映射。
关键词数据库创建的部分代码如下:
3.3 查询解析
查询解析模块,我们调用大语言模型来理解用户输入,识别用户意图并提取关键信息。
3.3.1 大语言模型选型
大语言模型的选择直接影响到知识库系统的整体性能和用户体验。Amazon Bedrock Claude非常适合作为知识库系统的大语言模型底座来使用,其主要有三大优势:
- 强大的长文本理解能力:Claude 3系列支持长上下文窗口(最高128 K Tokens),非常适合处理大型文档和多段引用内容;
- 出色的语言理解和推理能力:Claude 3在多轮对话理解、模糊提问解析和知识归纳方面表现优秀,尤其适合复杂问句和多轮对话式问答;
- 企业级托管+合规性保障:Amazon Bedrock提供无需部署模型的全托管服务,按需调用,免维护;同时满足数据私有、本地加密、权限管控等企业级合规保障。
3.3.2 系统提示词设计
在本项目中,用户提问时,可能使用航司名称,也可能会使用航司代码(AA、BB);系统要自动识别这些代码并转换为知识库中对应的航司名称,可以外挂一个航司代码列表来实现,但这种做法后续维护不便;更好的做法是使用Amazon Bedrock Claude大模型来自动识别。
以下是查询解析模块对应的代码:
3.4 混合检索
3.4.1 Embedding模型选型
经过评估,我们选择了BAAI/bge-large-zh-v1.5作为Embedding模型,主要基于以下考虑:
- 成熟且应用广泛:开源中最稳定、社区应用最多的中文Embedding模型;
- 为中文优化,语义理解能力强:专为中文语义检索任务训练,更好地理解中文表达;
- 支持查询增强:原生支持带指令的查询嵌入(Embedding),能显著提升模型对检索场景的理解力和效果。
3.4.2 Embedding模型配置
Embedding模型配置的部分代码如下:
from langchain.docstore.document import Document
from langchain_community.vectorstores import DocArrayInMemorySearch
from langchain_community.embeddings.huggingface import HuggingFaceBgeEmbeddings
# 设置词嵌入(Embedding)模型
modelPath = "BAAI/bge-large-zh-v1.5"
model_kwargs = {'device':'cuda'}
encode_kwargs = {'normalize_embeddings': True}
embeddings = HuggingFaceBgeEmbeddings(
model_name=modelPath,
model_kwargs=model_kwargs,
encode_kwargs=encode_kwargs,
query_instruction="为这个句子生成表示以用于检索相关文章:"
)
embeddings.query_instruction = "为这个句子生成表示以用于检索相关文章:"
# 创建向量数据库
vector_db = DocArrayInMemorySearch.from_documents(db_documents, embeddings)3.4.3 混合检索实现
混合检索的优势我们前文已经描述,这部分实现的代码如下:
3.5 指令生成
使用Amazon Bedrock Claude回答用户问题,除了用户Query外,还需要提供三部分信息:航司代码对照表、相关知识片段、客户业务知识。客户业务知识是基于客户提供的补充语料整理出的内容,主要对其中出票相关的规则再次进行了梳理,使这部分规则更明确清楚,目的是让大模型可以识别行业“黑话”。指令生成我们主要使用标准大语言模型,通过附加定制的提示词的方式来实现。
以下是提示词部分的参考代码:
3.6 用户交互
Gradio 是一个快速构建和分享机器学习 Web 应用的 Python 工具,支持一行代码创建交互式界面。本项目中我们使用Gradio来搭建用户交互界面。以下是部分代码:
四、实现效果
经过前期多轮沟通与调优后,最终版本在客户测试后,问答准确率达到了91.9%,此结果已超过客户测试前的预期(此前客户要求准确率在80%以上)。测试结果统计如下:
| A | B | C | D | |
| 1 | 问题总数 | 完全正确 | 部分正确 | 准确率 |
| 2 | 37 | 34 | 3 | 91.90% |
部分测试用例和测试结果如下:
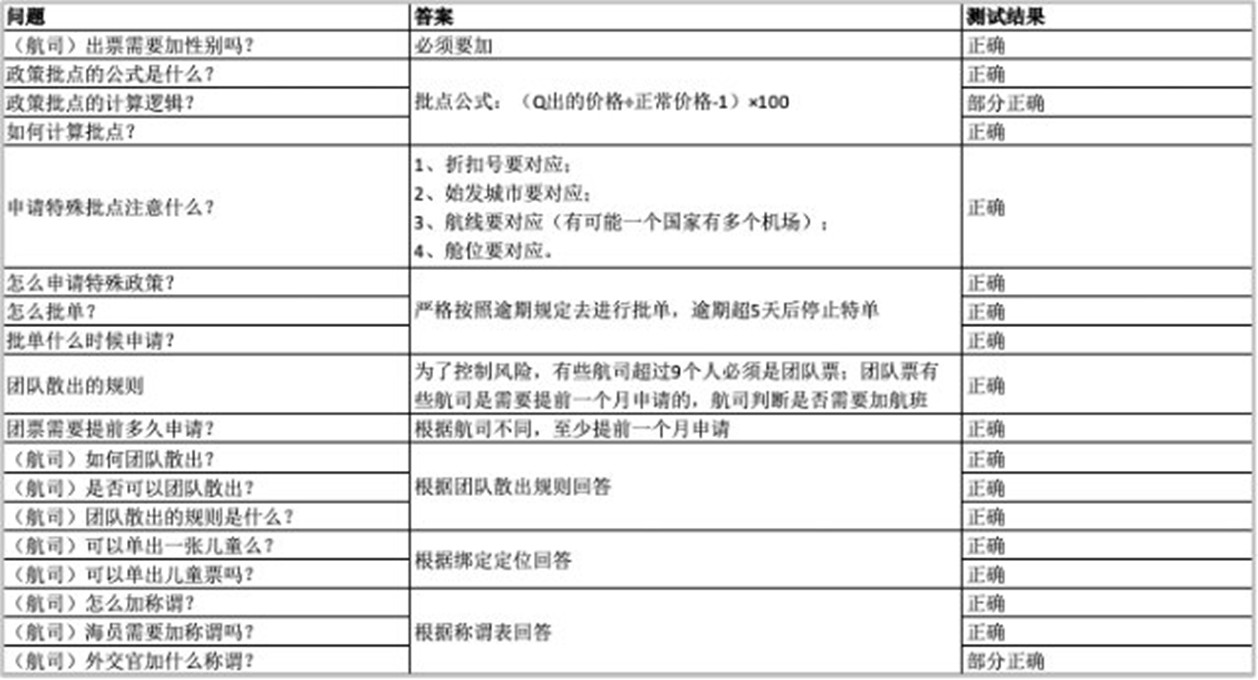 |
五、总结与展望
本项目我们成功使用大模型和RAG技术构建了一套机票分销领域人工智能客服助手,该系统可以接收并准确理解用户输入的自然语言提问,自动从知识库中查找与提问相关的行业知识,并生成与之匹配的回答。
5.1 目前成果
- 听得懂:系统能够准确理解各种复杂的自然语言提问,包括口语化表达、行业“黑话”;
- 找得准:通过大语言模型和RAG技术构建行业知识库,基于向量检索+关键词检索实现混合检索策略,系统能够准确找到存储在知识库中的知识;
- 答得对:对大语言模型进行精确调教,系统能够按照客户预期进行答案生成。
5.2 未来展望
- 提升问答准确率:持续优化迭代,在更多的知识、更复杂的场景下,保持并持续提高问答准确率;
- 与企业在线聊天工具集成:将系统集成到在线聊天工具,以提升人工客服工作效率,释放更多的生产力;
- 与运营系统集成:通过海量数据训练和场景覆盖,未来期望这套系统更深入的理解机票分销业务,集成到运营系统后,成为机票分销产品运营的左膀右臂。
通过这个项目,我们展示了大模型技术在机票分销量领域的应用潜力。随着生成式AI等技术的不断发展,我们期待与大型票务代理继续深入合作,让人工智能在航线规划、动态定价、运营专家系统等方面发挥更大的作用,共同为最终用户提供更优质、更高效的服务。
*前述特定亚马逊云科技生成式人工智能相关的服务目前在亚马逊云科技海外区域可用。亚马逊云科技中国区域相关云服务由西云数据和光环新网运营,具体信息以中国区域官网为准。