亚马逊AWS官方博客
基于 Amazon DynamoDB 流对 Amazon DynamoDB 表进行跨区复制实践
摘要
目前在中国境内区域(北京区域和宁夏区域),Amazon DynamoDB 暂不支持全局表。因此无法通过较便捷的方法实现 DynamoDB 表的跨区复制。另一方面,在许多应用场景以及客户具体实践中,对数据跨区复制的需求是旺盛和迫切的。最直观的一个好处是,跨区复制可以有效提高数据的高可用性,使得当某一区域隔离或者降级时,可以及时快速切换至备份区域,确保系统平稳运行,把干扰降至最低。因此至少在全局表功能推出以前,本文探索的复制技术可以在某种程度上弥补缺失。
简介
Amazon DynamoDB 流(以下简称流)是Amazon DynamoDB 表(以下简称表)项目变更信息的有序记录。一条流记录则包含表的单个项目的数据变更信息。流是表的附加特性,可以开启和关闭。开启后,流会按序捕获表数据项的每一次变更。变更信息会储存在日志中最多二十四小时。对于每一次变更,都可以近乎实时地知晓变更前后的新旧数据内容。流有以下两个基本特性:
- 每条流记录在流中出现且仅出现一次;
- 对表项目的每一次变更,其对应的流记录出现的顺序与实际变更顺序一致。
应用场景
基于流的基本特性,可以搭建许多有趣的应用,例如:
- 在社交场景下,一个好友发布朋友圈后,他的其他好友即时得到该发布对通知。
- 表的跨区复制:应用一在甲区域更改某表,应用二在乙区域读取这些更改并写入另一个表。如此,即构建了一个跨区域表复制的机制。本文会就此在中国区域进行探索实践。
上述表的跨区复制技术,进一步推广,可以应用到更多实用场景。例如数据的实时备份。当数据在甲区域更改时,近乎实时地备份到乙区域,提高系统的容灾和高可用能力。譬如当甲区域隔离或降级的时候,方便快速切换到乙区域,确保系统服务不受干扰。
目前(2019年10月)Amazon DynamoDB 在中国区尚不支持全局表。故本文探索的跨区域表复制实践,可以在一定程度上,弥补不足。
技术背景
本文主要使用 Java 进行跨区域复制的开发,用 Go 进行测试开发进行技术实践。但是其他语言和平台也可以搭建同样的实践,达到同样的效果。
本文探索的跨区域表复制实践仅用于中国境内北京区域和宁夏区域之间。如果用于境内区域和境外区域的数据复制,请确保满足网络安全法针对数据跨境传输的要求。
复制机制总览
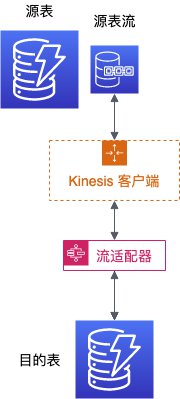
表和流有不同的终端节点,所以一个典型的复制场景大体上是这样的:
- 产生数据的应用连接源表的节点,进行更改;
- 复制器连接源表的流节点读取更改信息;
- 复制器同时连接目的表的节点,进行更改。
当这两张表在不同的区域时,就可以进行跨区域的表复制了。当然,这两张表也可以位于同一个区域,进行同区域的表复制。需要注意的是,改复制是异步的。

在上面的架构图中,更改源表的数据产生应用即可以在云端,也可以在云下。进行数据复制的复制器,因为承担复制之责,故建议置于云端较好,以便降低网络延迟。此处,复制器即可以选择置于源表,也可以置于目的表的区域。这两种选择在性能上应该是差不多的。
复制架构
AWS在中国境内有两个区,分别是北京区域和宁夏区域。假定复制路径是从北京到宁夏,那么根据复制应用所处区的不同,至少有三种配置方式,罗列如下:

- 左图是复制应用与源表在同一区域的情况
- 中图是复制应用与目标表在同一区域的情况
- 右图是复制应用在云下的情况
建议是采用复制应用在云端的配置,以降低网络延迟。故在后面的测试环节,不对第三种架构进行测试。
实现详述
表终端节点与流终端节点是相互独立的。要实现表复制,除需要开启表的流功能外,还需要进行必要的设置。有四种写入流的信息类型可以设置:
- 键值:仅传输更改表项的键值信息
- 新印象:传输更改表项的键值和更改后的信息
- 旧印象:传输更改表项的键值和更改前的信息
- 新旧印象:传输更改表项的键值和更改前后的信息
如果流功能关闭后再次开启,其终端节点会变动。
流结构
流由流记录构成。一条流记录包含该流所属表的一个数据项的更改。按组来组织流记录,又称为分区。分区类似于容器,包含多条流记录以及读取和遍历这些记录的必要信息。分区中的流记录会在二十四小时后删除。
流结构不是简单的线性结构。分区会按需被自动创建、拆分和删除。一个分区有可能有一个或者数个子分区,形成父子结构。访问时,必须按先父后子的顺序来处理流,以保证其正确性。在此,推荐使用 DynamoDB 流 Kinesis 适配器(以下简称流适配器)来简化流处理的复杂性。该适配器还可以正确处理新的或者过期的分区。本文不讨论如何使用更初级的流函数接口来处理流。
流函数接口的设计与 Kinesis 的函数接口很相似,例如下述四个关键函数: ListStreams, DescribeStream, GetShards 和 GetShardIterator。因此,在使用了流适配器后, Kinesis 客户端(以下简称流客户端)就可以匹配及处理流信息。该客户端就顺理成章的可以用来进一步简化流处理操作,如下图所示。
示例代码
本节基于 Java 语言和 Dagger 依赖注入机制,罗列相关源代码片段,构建一个跨区域 DynamoDB 表复制的应用程序。请注意,现阶段只支持单表的复制,未来可以拓展至多表的复制,其实现核心与机制是类似的。此外,囿于篇幅,以下仅罗列关键代码片段,省略了譬如异常处理、日志记录等代码片段。具体来说,主要依赖关系如下:
| 组件 | 版本 |
| Java | 8 |
| Dagger | 2.x |
| Amazon Kinesis Client Library For Java | 1.11.x |
| DynamoDB Streams Adapter For Java | 1.5.x |
| DynamoDBLocal | 1.11.x |
首先注册 AWS 账号,拿到相应用户的访问密钥。然后构建密钥供应器 AWSCredentialsProvider。
表结构
关于数据模型,由于DynamoDB表是无结构的存储,为了简化测试,假定该表只有一个字符串类型的主键 id 。用户可以根据实际表结构及主键信息,对代码做相应修改。事实上,这个表可以存储任意数据。
源表部分
本文构造的复制器基于 Kinesis 流复制工作器进行复制,即具体的复制工作,是有该工作器完成的。具体实现类是:
-
amazonaws.services.kinesis.clientlibrary.lib.worker.Worker
需要在源表部分准备数个不同的组件,用以创建该复制工作器,包括:
- 目的 DynamoDB 客户端
- 目的 CloudWatch 客户端
- 流记录处理器
- Kinesis 客户端配置信息
- DynamoDB 流适配器客户端
前两项是常规的客户端,指定区域和密钥后即可创建。
以下创建流记录处理器。这里对于 DynamoDB 流的处理方法和对于 Kinesis 流的处理方法是一样的。当修改和删除信息事件发生时,调用目的表客户端对目的表进行相应修改,以达到复制的目的。注意这里只列出关键功能代码。
以下创建源表的流适配器。
以下创建流客户端配置信息。
至此,所有创建流复制工作器所需要的组件都准备好了。
目的表部分
以下创建目的表流复制工作器。
开始复制
以上准备好各个工作组件,现在将其装配起来,开始表复制工作。
对于表的跨区域复制,测试侧重复制延迟及复制器性能。本节测试在预置模式下,采用不同写容单位(WCU, Write Capacity Unit)时延迟的变化情况,同时监控复制器的性能指标。一个写容单位表示对大小最多为 1 KB 的项目每秒执行一次写入。而事务写入请求需要 2 个写容单位才能对大小最多为 1 KB 的项目每秒执行一次写入。考虑到各种不稳定因素可能会对测试产生影响,如网络异常等,测试程序并不会就单个表项目的复制计算延迟,而是在固定写容单位下随机测试部分表项目的延迟,以尽可能接近真实情况。
以下编写两个测试程序,分别运行在源端和目的端。
- 运行在源端的测试程序负责按照指定的写容单位向源表中写入测试数据,以确保相应的写压力;
- 运行在目的端的测试程序向源端写入测试数据,写入后开始计时直至从目的端读出数据作为复制延迟。
测试分两大部分,即北京复制到宁夏,及宁夏复制到北京。测试数据复制延迟的情况。按照不同的写容单位共进行五次复制测试,设置其分别为 30, 90, 180, 300 和 7000,前四个每次都只运行十分钟,最后一个运行一小时。
从北京区域复制到宁夏区域
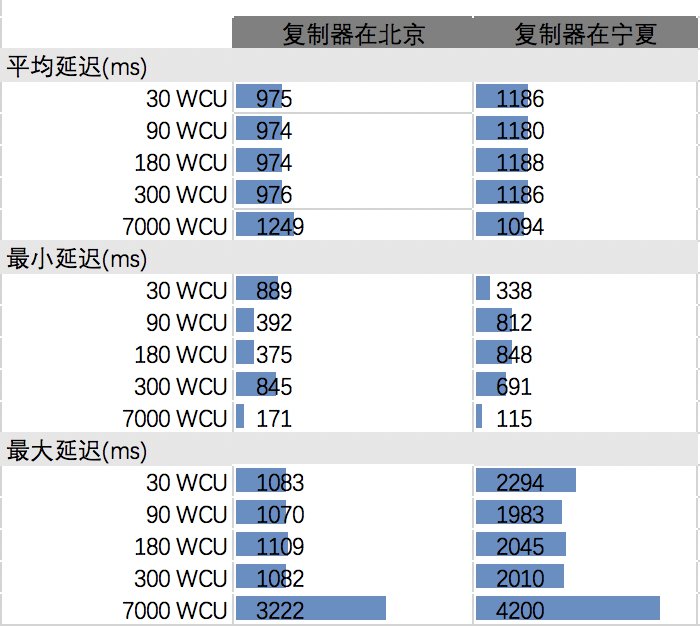
本节测试数据从北京复制到宁夏的情况。下表计算了在不同写容单位下复制器在不同区域的平均、最大及最小延迟时间,单位是毫秒。从表中可以看出,就最大延迟而言,大部分情况下是小于3000毫秒的。

测试延迟和数据复制完成度的关系。给定一定的延迟,计算完成数据复制的百分比。横轴是延迟时间,单位是毫秒,纵轴是数据复制完成百分比。如下面两图所示,无论复制器在源端(北京)还是在目的端(宁夏),当延迟时间为1200毫秒时,70%以上的表项目都已复制完成。当延迟时间为2000毫秒时,90%以上的表项目都已复制完成。当延迟为3000毫秒时,几乎所有的数据(99%)都复制完成了。总体来看,复制器在源端(北京)对复制延迟影响最小,受写容单位影响也较小。同时对复制器运行环境的监控未发现明显异常。


从宁夏区域复制到北京区域
本节测试数据从宁夏复制到北京的情况,和上面相反。和上面数据类似的是,绝大多数最大延迟都在3000毫秒以内。有趣的是,对于从宁夏复制到北京的情况,和从北京复制到宁夏一样,还是复制器在北京的时候,延迟情况比较好。
测试延迟和数据复制完成度的关系。和上面的测试类似,在1200毫秒之后,约70%的数据项都复制完成。在3000毫秒之后,绝大部分(99%)数据项都复制完成。所以可以推论,无论数据从北京到宁夏,还是反之,性能上未见明显差异。说明在中国区利用流对表进行复制的性能是非常稳定和可靠的。


结论及展望
本文探讨了利用 DynamoDB 的流对其表在中国区进行跨区域复制的实践,并对相关实践进行了具体测试。数据复制的核心思想是,当数据更改信息按序出现在流中以后,复制器读取该更改信息并施行在目的表。从测试结果来看,跨区域的复制延迟非常小,基本上都在秒级。在 DynamoDB 全局表尚未在中国区就绪之前,可以考虑使用该方式进行跨区域数据同步,作为一项有益补充。
需要指出的是,本文所罗列的代码仅针对单表的复制,尚不支持多张表的并发复制。但是对多表的复制,其原理是一样的。只不过需要对多线程的并发操作做出相应正确和有效的管理。笔者未来可以针对多表复制构建并发机制,提高复制的效率与可扩展性。另一个发展方向是通过自动化工具,对复制的各方面进行高效管理,包括前期的配置过程,复制中间的监控预警等事务。
参考资料
- Amazon DynamoDB 文档:https://docs.aws.amazon.com/dynamodb/index.html
附录
通过用户密钥构建密钥供应器。
上述代码中使用到的工具类。