简介
Amazon EMR是业界领先的原生云大数据平台,它极大地简化了在AWS上运行各种大数据框架进行大数据的处理和分析工作。通过使用这些框架和相关的开源项目(如Apache Spark、Apache Hive和Apache HBase等),并结合 Amazon EC2 的Auto Scaling动态弹性和 Amazon S3 的可扩展高可靠存储,您可以轻松、快速、经济高效地处理大规模海量数据。通过EMR ,您可以在数分钟内启动大数据集群,并且无需担心基础设施管理的任务,EMR会帮助完成这些工作,您只需要集中精力进行数据分析即可。
Apache Kylin是一个开源的分布式大数据分析引擎,也是第一个由中国人主导的Apache顶级开源项目,在国际开源社区具有极大的影响力。Apache Kylin提供Hadoop/Spark之上的SQL查询接口及联机分析处理(OLAP)引擎以支持超大规模数据,其设计旨在减少上百亿规模数据查询的延迟,可实现超大数据集上的亚秒级查询。
Apache Kylin的核心是数据分析中经典的多维立方体(MOLAP Cube)理论,将百亿以上规模数据集通过不同的维度组合变换聚合成数据魔方一般的Cube立方体,帮助用户实现超快的数据分析。使用Apache Kylin其实非常简单,和把大象(Hadoop生态的形象代表)装进冰箱(Cube立方体)一样,拢共需要三步:
- 把冰箱门打开:定义数据集上的数据模型(如星形模型或雪花模型)
- 把大象放进去:在定义的数据表上构建Cube
- 把冰箱门关上:使用标准SQL进行查询,在亚秒级响应时间内获得结果
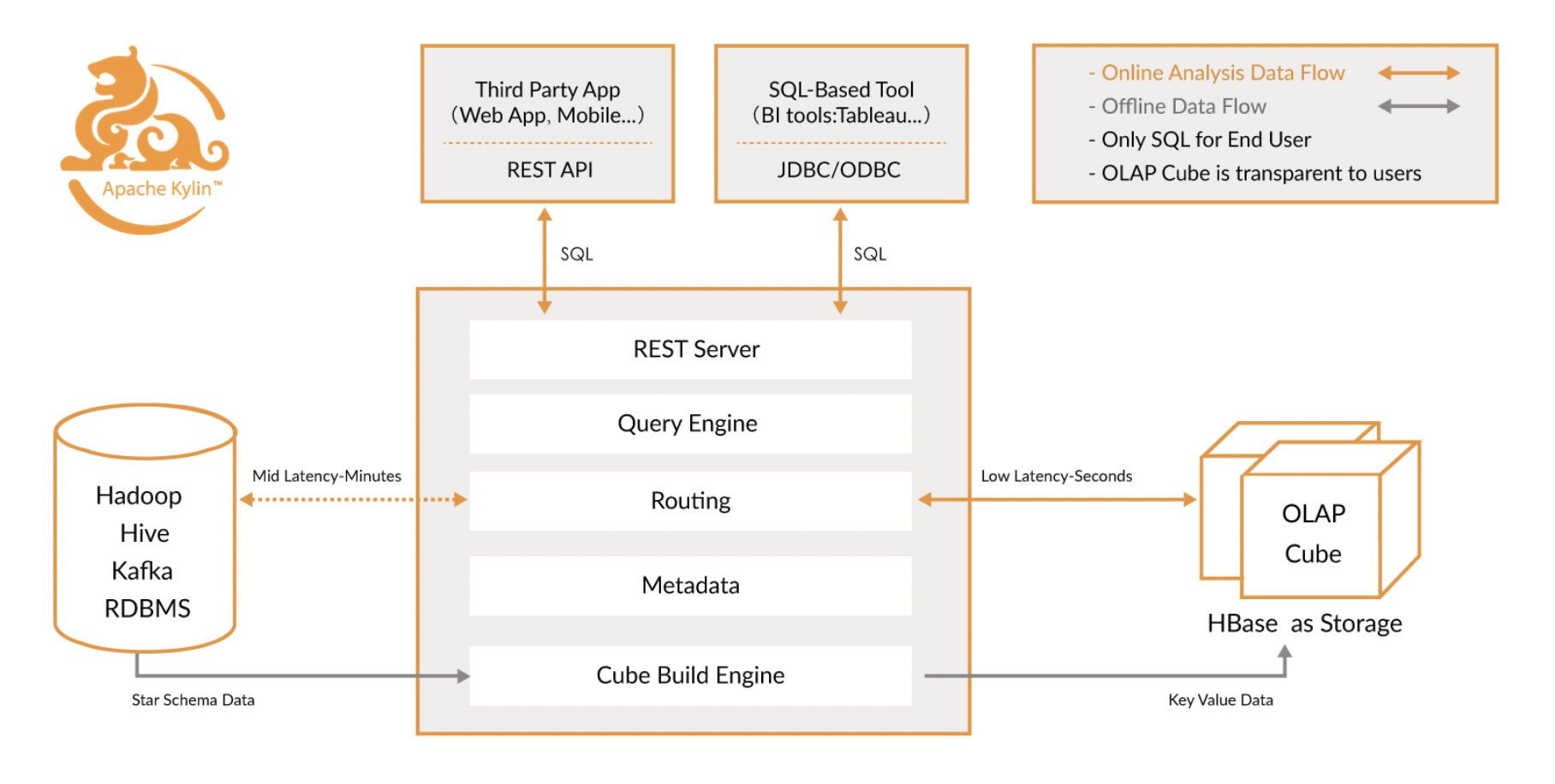
接下来看一下Apache Kylin的技术架构。如下图所示,首先Kylin从数据源(如Hadoop和Hive)中抽取数据,然后根据数据模型定义使用Hadoop或者Spark构建Cube,最后将数据存储到HBase中。

上述组件都可以使用Amazon EMR一键轻松创建出来,减少众多繁重的部署和配置工作,这样就可以让Apache Kylin充分结合EMR的特性进行使用。根据Apache Kylin官方文档说明,现阶段Apache Kylin v3.*支持EMR 5.27及更高的版本,本文将使用emr-5.29.0版本的EMR和Apache Kylin v3.0.0进行演示。
在Amazon EMR集群上部署Apache Kylin
在开始设置 Amazon EMR 集群之前,请确保您已完成Amazon EMR入门指南中步骤 1设置示例集群的先决条件,这里需要注意的是如果之前没有创建过默认 Amazon EMR 服务角色和 EC2 实例配置文件,请先使用以下命令创建它们。
aws emr create-default-roles
我们使用集群的步骤(Step)以运行脚本的方式来部署Apache Kylin,我们会在创建集群时指定运行部署脚本的步骤,您也可以在集群处于 WAITING 状态时添加步骤,有关添加步骤的更多信息,请参阅 Amazon EMR 管理指南中的向集群提交工作。
如果熟悉Amazon EMR,可能会考虑使用引导操作(Bootstrap actions)来进行部署Apache Kylin,但是根据EMR集群的生命周期,EMR 引导操作的集群状态是 BOOTSTRAPPING,这时EMR在每个实例上运行指定的引导操作(也可以通过运行条件引导操作控制脚本只在主节点上执行),在这之后的下一个阶段EMR 才会安装在创建集群时指定的应用程序,例如Hive、HBase和 Spark 等,而部署脚本中需要使用到这些应用程序的相关信息和文件,因此暂时无法采用引导操作的方式来部署。
首先,你可以在GitHub上查看并下载Kylin在EMR的步骤脚本,也可以创建kylin-on-emr.sh文件并复制以下内容到文件中,并将脚本文件上传至S3中。
#!/bin/bash
set -e
# Get script args
VERSION=$1
LOCATION=$2
# Set basic variables used in this script
KYLIN_HOME=/usr/local/kylin/apache-kylin-$VERSION-bin-hbase1x
HIVE_HOME=/usr/lib/hive
SPARK_HOME=/usr/lib/spark
HBASE_HOME=/usr/lib/hbase
HOSTNAME=`hostname`
# Download and install Kylin
sudo mkdir -p /usr/local/kylin
sudo chown hadoop /usr/local/kylin
cd /usr/local/kylin
# Choose software URL based on the version and location
if [ $LOCATION = "cn" ];then
KYLIN_TAR=http://mirror.bit.edu.cn/apache/kylin/apache-kylin-$VERSION/apache-kylin-$VERSION-bin-hbase1x.tar.gz
elif [ $LOCATION = "global" ];then
KYLIN_TAR=http://us.mirrors.quenda.co/apache/kylin/apache-kylin-$VERSION/apache-kylin-$VERSION-bin-hbase1x.tar.gz
fi
if [ $VERSION = "3.1.0-SNAPSHOT" ];then
KYLIN_TAR=http://d6zijbkibsp09.cloudfront.net/shtian/apache-kylin-3.1.0-SNAPSHOT-bin-hbase1x.tar.gz
fi
wget $KYLIN_TAR
# Unarchive the tarball
tar -zxvf apache-kylin-$VERSION-bin-hbase1x.tar.gz
# Modify Kylin HBase configuration
sed -i "/<configuration>/a\<property>\n <name>hbase.zookeeper.quorum</name>\n <value>$HOSTNAME</value>\n</property>" $KYLIN_HOME/conf/kylin_job_conf.xml
# Create the working-dir folder if it doesn’t exist
hadoop fs -mkdir -p /kylin/package/
# Solve jar conflict - Configure the environment
cat >> ~/.bashrc << EOF
# Kylin environment
export HIVE_HOME=/usr/lib/hive
export HADOOP_HOME=/usr/lib/hadoop
export HBASE_HOME=/usr/lib/hbase
export SPARK_HOME=/usr/lib/spark
export KYLIN_HOME=/usr/local/kylin/apache-kylin-$VERSION-bin-hbase1x
export HCAT_HOME=/usr/lib/hive-hcatalog
export KYLIN_CONF_HOME=$KYLIN_HOME/conf
export tomcat_root=$KYLIN_HOME/tomcat
export hive_dependency=$HIVE_HOME/conf:$HIVE_HOME/lib/:$HIVE_HOME/lib/hive-hcatalog-core*.jar:$SPARK_HOME/jars/
export PATH=$KYLIN_HOME/bin:$PATH
export hive_dependency=$HIVE_HOME/conf:$HIVE_HOME/lib/*:$HIVE_HOME/lib/hive-hcatalog-core*.jar:/usr/share/aws/hmclient/lib/*:$SPARK_HOME/jars/*:$HBASE_HOME/lib/*.jar:$HBASE_HOME/*.jar
EOF
# Source the env
source ~/.bashrc
# Solve jar conflict - Remove joda.jar
if [ -f "$HIVE_HOME/lib/jackson-datatype-joda-2.4.6.jar" ];then
sudo mv $HIVE_HOME/lib/jackson-datatype-joda-2.4.6.jar $HIVE_HOME/lib/jackson-datatype-joda-2.4.6.jar.backup
fi
# Solve jar conflict - Add following content on the top of bin/kylin.sh
sed -i '2i export HBASE_CLASSPATH_PREFIX=${tomcat_root}/bin/bootstrap.jar:${tomcat_root}/bin/tomcat-juli.jar:${tomcat_root}/lib/*:$hive_dependency:$HBASE_CLASSPATH_PREFIX' $KYLIN_HOME/bin/kylin.sh
# Build a Spark’s flat jar
rm -rf $KYLIN_HOME/spark_jars
mkdir $KYLIN_HOME/spark_jars
cp /usr/lib/spark/jars/*.jar $KYLIN_HOME/spark_jars
cp -f /usr/lib/hbase/lib/*.jar $KYLIN_HOME/spark_jars
rm -f $KYLIN_HOME/spark_jars/netty-[0-9]*.jar
jar cv0f spark-libs.jar -C $KYLIN_HOME/spark_jars .
hadoop fs -put -f spark-libs.jar /kylin/package/
cat >> $KYLIN_HOME/conf/kylin.properties << EOF
kylin.engine.spark-conf.spark.yarn.archive=hdfs://$HOSTNAME:8020/kylin/package/spark-libs.jar
EOF
# Copy Spark jar to tomcat lib
cp /usr/lib/spark/jars/spark-core_* $KYLIN_HOME/tomcat/lib/
cp /usr/lib/spark/jars/scala-library-* $KYLIN_HOME/tomcat/lib/
# Configure if Glue is used as Hive Metadata store
if [ $3 = "glue" ];then
cp /usr/share/aws/hmclient/lib/aws-glue-datacatalog-client-common-*.jar $KYLIN_HOME/lib
cp /usr/share/aws/hmclient/lib/aws-glue-datacatalog-hive2-client-*.jar $KYLIN_HOME/lib
cp /usr/share/aws/hmclient/lib/aws-glue-datacatalog-spark-client-*.jar $KYLIN_HOME/lib
cat >> $KYLIN_HOME/conf/kylin.properties << EOF
kylin.source.hive.metadata-type=gluecatalog
EOF
fi
# Fix for China regions
if [ $LOCATION = "cn" ];then
cp -d /usr/share/aws/hmclient/lib/aws-glue-datacatalog-*.jar $KYLIN_HOME/lib
fi
# Start Kylin
$KYLIN_HOME/bin/sample.sh
$KYLIN_HOME/bin/kylin.sh start
*注:以上脚本使用基于HBase1x 的Apache Kylin v3.0.0和v2.6.5在AWS美国东部 (弗吉尼亚北部) us-east-1和AWS中国宁夏区域的EMR 5.29.0版本中测试通过,如果使用其他Apache Kylin在EMR 版本根据实际情况可能需要微调。
目前脚本接收3个参数。第一个参数是Kylin的版本如”3.0.0″。第二个参数是所在的区域,可以填写”cn”或者是”global”,脚本会根据不同区域选择不同的Kylin下载源。第三个参数是是否使用AWS Glue作为Hive和Spark的数据目录,可以设置的值为”glue”或者留空,如果使用Glue,第一个参数需要修改为”3.1.0-SNAPSHOT”。
AWS Glue 是一种完全托管的服务,提供数据目录以使数据湖中的数据可被发现,并且能够执行提取、转换和加载 (ETL) 以准备数据进行分析。数据目录会自动创建为所有数据资产的持久元数据存储,支持在一个视图中搜索和查询所有数据。数据湖是一个集中式存储库,允许以任意规模存储所有结构化和非结构化数据,数据可以按原样进行存储(无需将其转换为预先定义的数据结构)。在数据湖之上可以运行不同类型的分析 – 从控制面板和可视化到大数据处理、实时分析和机器学习,以指导做出更好的决策。
*注:基于HBase1x 的Apache Kylin 3.1.0-SNAPSHOT版本在AWS美国东部 (弗吉尼亚北部) us-east-1和AWS中国宁夏区域的EMR 5.29.0版本中测试通过。该版本是根据Apache Kylin目前GitHub源码进行修改后进行编译打包的版本(目前这部分内容也已经Fix),仅供测试使用,官方版本需要等待3.1.0版本的正式发布。
根据实际情况,使用以下AWS CLI命令来创建集群:
aws emr create-cluster \
--name <replace with your cluster name> \
--release-label emr-5.29.0 \
--applications Name=Hadoop Name=Hive Name=HBase Name=Spark \
--use-default-roles \
--auto-scaling-role EMR_AutoScaling_DefaultRole \
--ec2-attributes KeyName=<replace with your ssh key> \
--instance-type m5.xlarge \
--instance-count 3 \
--enable-debugging \
--log-uri <replace with s3 bucket for cluster logging> \
--configurations '[{"Classification":"hive-site","Properties":{"hive.metastore.client.factory.class":"com.amazonaws.glue.catalog.metastore.AWSGlueDataCatalogHiveClientFactory"}},{"Classification":"spark-hive-site","Properties":{"hive.metastore.client.factory.class":"com.amazonaws.glue.catalog.metastore.AWSGlueDataCatalogHiveClientFactory"}}]' \
--steps Type=CUSTOM_JAR,Name=CustomJAR,ActionOnFailure=CONTINUE,Jar=s3:// <replace with your region>.elasticmapreduce/libs/script-runner/script-runner.jar,Args=["<replace with your script kylin-on-emr.sh s3 location>","<Kylin version>","<location>","<whether use Glue as Hive metastore>"]
请根据实际情况依次替换<>括号内的信息,例如集群信息、SSH密钥名称、用于存储集群日志信息的S3存储桶和kylin-on-emr.sh脚本所在的S3位置及参数信息。这里没有使用–instance-groups 参数指定实例计数,所以集群将启动1个主节点,其余2个实例将作为核心节点启动,所有节点都使用该命令中指定的实例类型m5.xlarge。配置参数–configurations是为设置Glue作为Hive和Spark的数据目录使用。
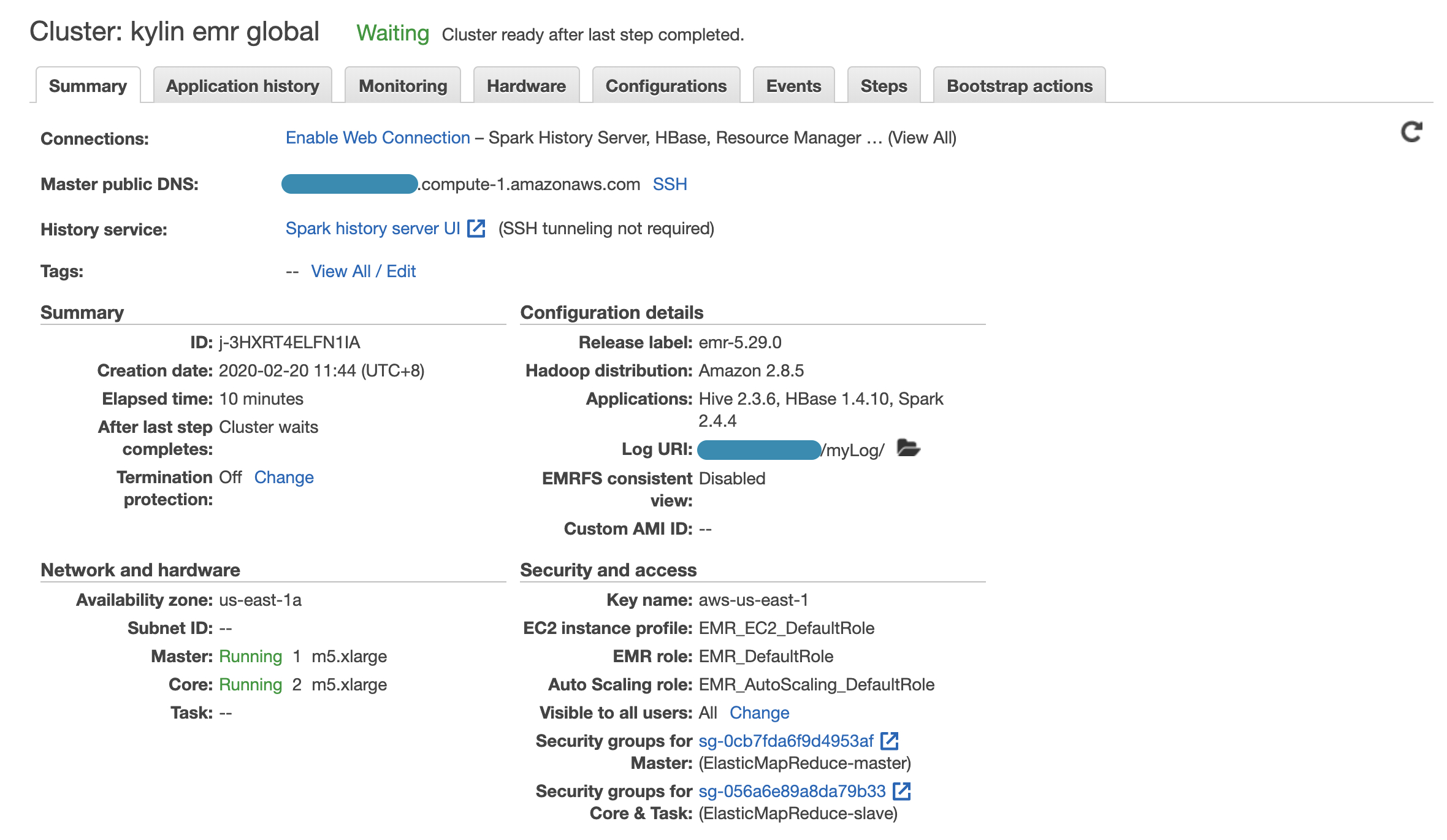
集群启动后可以在AWS控制台界面查看详细信息。
 查看步骤的执行情况,如果一切正常,最终步骤的状态将显示为Completed。如果发现执行状态为Failed,可以在点击日志链接查看详细信息。
查看步骤的执行情况,如果一切正常,最终步骤的状态将显示为Completed。如果发现执行状态为Failed,可以在点击日志链接查看详细信息。
 这里,演示的步骤执行成功,Apache Kylin已经部署完成。接下来,将介绍Apache Kylin的基本使用。
这里,演示的步骤执行成功,Apache Kylin已经部署完成。接下来,将介绍Apache Kylin的基本使用。
使用示例数据进行分析
首先,我们需要连到Kylin的Web UI界面。请参考查看 Amazon EMR 集群上托管的 Web 界面中的说明,可以选择使用本地端口转发设置到主节点的 SSH 隧道或者是使用动态端口转发设置到主节点的 SSH 隧道的方式进行连接。SSH隧道建立之后,我们访问主节点的7070端口,输入用户名ADMIN和密码KYLIN进行登录。
 如果使用AWS Glue作为Hive的metastore,在数据源(Data Source)中也可以看到Glue数据目录中的数据库和数据表。
如果使用AWS Glue作为Hive的metastore,在数据源(Data Source)中也可以看到Glue数据目录中的数据库和数据表。
 因为在部署脚本中我们已经执行了Kylin 提供的样例 Cube 的脚本$KYLIN_HOME/bin/sample.sh,因此可以在界面中看到已经创建好的项目learn_kylin,两个模型kylin_streaming_model和kylin_sales_model,以及两个kylin_streaming_cube和kylin_sales_cube,可以点击查看模型或者Cube的详细信息,比如Kylin在模型中提供了数据表的可视化关系展示。
因为在部署脚本中我们已经执行了Kylin 提供的样例 Cube 的脚本$KYLIN_HOME/bin/sample.sh,因此可以在界面中看到已经创建好的项目learn_kylin,两个模型kylin_streaming_model和kylin_sales_model,以及两个kylin_streaming_cube和kylin_sales_cube,可以点击查看模型或者Cube的详细信息,比如Kylin在模型中提供了数据表的可视化关系展示。
 接下来,需要对Cube进行构建。在构建之前,我们对Cube的构建引擎进行修改。目前Kylin提供的默认计算引擎是MapReduce,但是MapReduce使用和优化都有很大的局限性,构建和预计算作为Kylin的核心,需要一个更高效的计算引擎。因此,建议将Cube的构建引擎修改为Spark(在Kylin 2.*版本中引入),可以获得更多的收益。
接下来,需要对Cube进行构建。在构建之前,我们对Cube的构建引擎进行修改。目前Kylin提供的默认计算引擎是MapReduce,但是MapReduce使用和优化都有很大的局限性,构建和预计算作为Kylin的核心,需要一个更高效的计算引擎。因此,建议将Cube的构建引擎修改为Spark(在Kylin 2.*版本中引入),可以获得更多的收益。
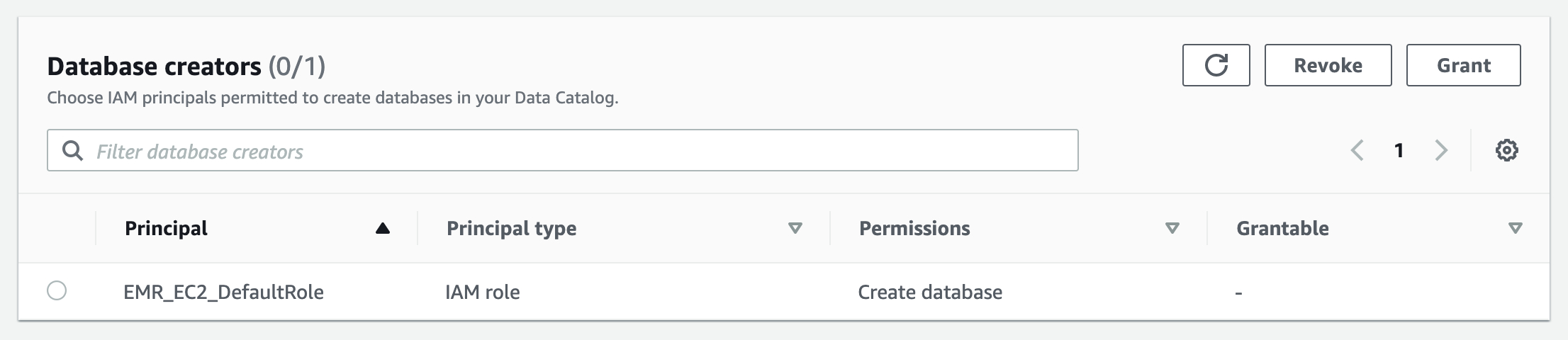
*注:如果使用Glue作为Spark的数据目录,需要在AWS Lake Formation给EMR集群节点角色(示例是EMR_EC2_DefaultRole)授权可以创建数据库(Database creators)如下图所示,否则在使用Spark构建Cube或者使用Spark SQL时都会报以下错误。
org.apache.hadoop.hive.ql.metadata.HiveException: MetaException(message:Insufficient Lake Formation permission(s) on global_temp (Service: AWSGlue; Status Code: 400; Error Code: AccessDeniedException; Request ID: ***))

选择kylin_sales_cube,点击右侧Actions->Edit,然后选择Advanced Setting。


在页面下方找到Cube Engine,然后修改Engine Type为Spark,然后保存配置。

接下来就可以开始使用Spark进行构建了。选择kylin_sales_cube,点击右侧Actions->Build,建议选择一个在 2014-01-01 之后的日期,这样可以覆盖所有的 10000 样例记录。任务创建成功后,点击页面上方Monitor 标签,查看构建进度。

对比了使用MapReduce(如下图所示)和Spark的构建任务,在未经任何优化的前提下,可以看到Spark的执行速度有明显的优势。

使用以下SQL语句进行查询,并查看结果。
select part_dt, sum(price) as total_sold, count(distinct seller_id) as sellers from kylin_sales group by part_dt order by part_dt

可以看到查询以非常快的速度返回了结果,然后通过Hive进行同样的查询,如下所示。

可以看出,直接在Hive中查询的速度不够稳定,但是平均执行时间为5秒左右,而Kylin会在亚秒级时间内返回结果,这种差异会在上百亿规模数的并发查询下显得更加突出。
总结
本文演示了如何在Amazon EMR集群中部署单节点Apache Kylin并使用示例数据进行了基本的数据分析说明。借助Amazon EMR,您可以非常轻松、便捷地部署Apache Kylin并完成大数据分析任务,还可以通过AWS Glue实现集中的数据目录管理,充分地利用云中的资源进行优化。
您也可以考虑使用Amazon EC2实例在EMR集群外单独部署Apache Kylin,这样可以避免Kylin和EMR节点的资源抢占。此外,Apache Kylin属于无状态服务,运行时信息共享在HBase中,因此在大数据规模较大、单节点负载较高的情况下,可以考虑使用集群模式进行部署。
参考文档
Apache Kylin Official Site
Install Kylin on AWS EMR
Cube Build and Job Monitoring
使用 AWS Glue Data Catalog作为 Spark SQL 的元存储
《Apache Kylin权威指南(第2版)》
本篇作者
 查看步骤的执行情况,如果一切正常,最终步骤的状态将显示为Completed。如果发现执行状态为Failed,可以在点击日志链接查看详细信息。
查看步骤的执行情况,如果一切正常,最终步骤的状态将显示为Completed。如果发现执行状态为Failed,可以在点击日志链接查看详细信息。 这里,演示的步骤执行成功,Apache Kylin已经部署完成。接下来,将介绍Apache Kylin的基本使用。
这里,演示的步骤执行成功,Apache Kylin已经部署完成。接下来,将介绍Apache Kylin的基本使用。 如果使用AWS Glue作为Hive的metastore,在数据源(Data Source)中也可以看到Glue数据目录中的数据库和数据表。
如果使用AWS Glue作为Hive的metastore,在数据源(Data Source)中也可以看到Glue数据目录中的数据库和数据表。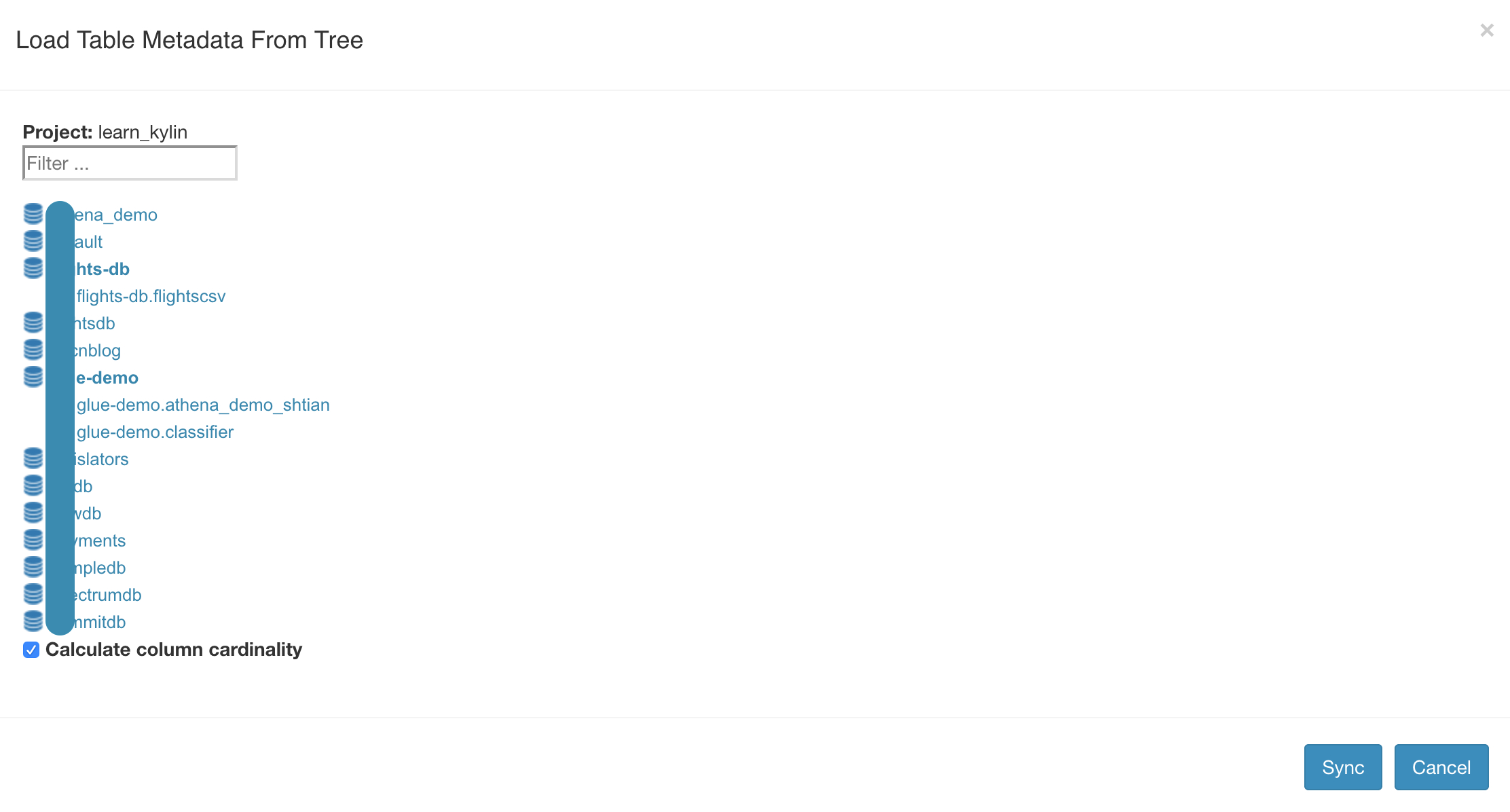 因为在部署脚本中我们已经执行了Kylin 提供的样例 Cube 的脚本$KYLIN_HOME/bin/sample.sh,因此可以在界面中看到已经创建好的项目learn_kylin,两个模型kylin_streaming_model和kylin_sales_model,以及两个kylin_streaming_cube和kylin_sales_cube,可以点击查看模型或者Cube的详细信息,比如Kylin在模型中提供了数据表的可视化关系展示。
因为在部署脚本中我们已经执行了Kylin 提供的样例 Cube 的脚本$KYLIN_HOME/bin/sample.sh,因此可以在界面中看到已经创建好的项目learn_kylin,两个模型kylin_streaming_model和kylin_sales_model,以及两个kylin_streaming_cube和kylin_sales_cube,可以点击查看模型或者Cube的详细信息,比如Kylin在模型中提供了数据表的可视化关系展示。 接下来,需要对Cube进行构建。在构建之前,我们对Cube的构建引擎进行修改。目前Kylin提供的默认计算引擎是MapReduce,但是MapReduce使用和优化都有很大的局限性,构建和预计算作为Kylin的核心,需要一个更高效的计算引擎。因此,建议将Cube的构建引擎修改为Spark(在Kylin 2.*版本中引入),可以获得更多的收益。
接下来,需要对Cube进行构建。在构建之前,我们对Cube的构建引擎进行修改。目前Kylin提供的默认计算引擎是MapReduce,但是MapReduce使用和优化都有很大的局限性,构建和预计算作为Kylin的核心,需要一个更高效的计算引擎。因此,建议将Cube的构建引擎修改为Spark(在Kylin 2.*版本中引入),可以获得更多的收益。