AWS 上的分析
适用于所有分析工作负载的全套功能,已针对性价比和规模进行优化
概览
AWS 为每种分析工作负载提供了一套全面的功能。从数据处理和 SQL 分析到流式传输、搜索和商业智能,AWS 通过内置治理功能提供无与伦比的性价比和可扩展性。选择针对特定工作负载进行了优化的专门服务,或者使用 Amazon SageMaker 简化和管理您的数据和人工智能工作流程。 无论您是开始数据之旅还是寻求综合体验,AWS 都能为您提供合适的分析功能,帮助您利用数据重塑业务。
通过 AWS 上的分析推动切实的业务成果
通过一体式体验加快数据、分析和人工智能
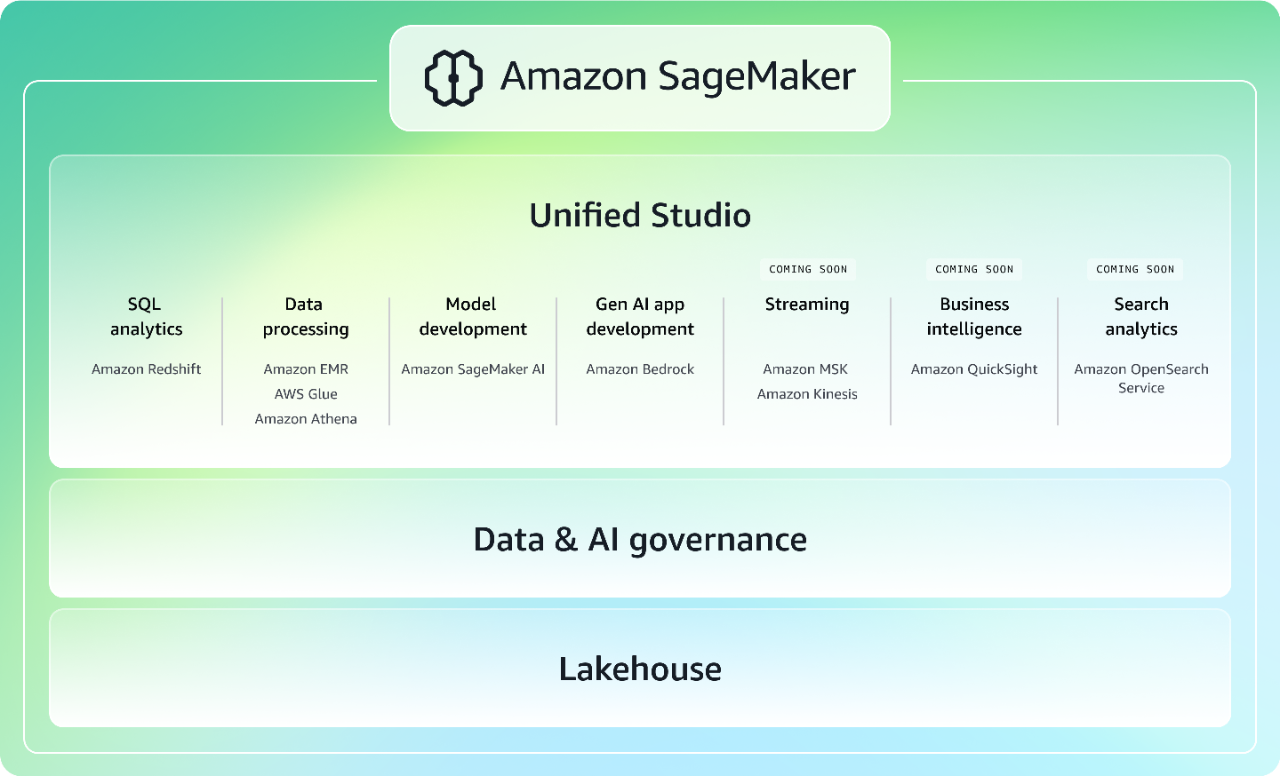
下一代 Amazon SageMaker 汇集了广泛采用的 AWS 机器学习(ML)和分析功能,可统一访问您的所有数据,为分析和人工智能提供一体式体验。使用熟悉的 AWS 工具进行模型开发、生成式人工智能应用程序开发、数据处理和 SQL 分析,在 Unified Studio 中加快协作和构建,并借助最强大的生成式人工智能软件开发助手 Amazon Q 开发者版提升效率。无论数据存储在数据湖、数据仓库,还是第三方或联合数据来源中,均可访问所有数据,同时内置治理功能可解决企业安全需求。了解有关 SageMaker 的更多信息。
利用 AWS 启用多云策略
AWS 提供了一系列强大的分析服务,这些服务能够实现跨多云和混合环境的无缝数据访问和处理。您可以通过联合查询、数据集成、安全的数据传输以及与开放标准的兼容性来实现这种灵活性,从而让您能够从所有数据中获取见解,无论这些数据存放在何处。
Amazon Athena 使您能够查询存储在各种外部数据来源中的数据并从中获得见解,这些数据来源包括 Azure 数据湖存储、Google Cloud Storage、Microsoft SQL Server 等,而无需复制或转换数据。
下一代 Amazon SageMaker 基于开放的数据湖仓架构构建,提供对 AWS 上的数据湖和数据仓库的统一访问能力,同时也支持对 Google BigQuery 和 Snowflake 等联合数据来源的统一访问。这种智能湖仓架构与 Apache Iceberg 完全兼容,使您能够使用任何与 Iceberg 兼容的工具和引擎,在原地灵活地访问和查询数据。
利用分析技术服务于人类和人工智能
通过专为数据存储、查询、流式传输、处理及治理而设计的服务大规模支持分析。从开放表格格式(OTF)到代理式基础设施,AWS 正在不断改进分析引擎和相关应用程序,以适应不断变化的分析领域需求。在本次研讨会中,了解 AWS 是如何为人类用户和代理式工作流打造优化解决方案的。

服务
|
分析类别
|
说明
|
AWS 服务和功能
|
|---|---|---|
|
流式传输
|
构建、扩展和操作实时数据管道和应用程序,而无需承担基础设施管理的负担。 |
|
|
数据湖屋、数据仓库、数据湖
|
访问和分析数据湖仓、数据仓库和数据湖中的所有数据。 |
|
|
数据处理
|
使用开源框架分析、准备和集成用于分析和人工智能的数据。 |
|
|
商业智能
|
通过现代交互式控制面板、像素级完美报告、自然语言查询和嵌入式分析,构建、发现和分享有意义的见解。 |
|
|
搜索分析
|
安全地实时搜索、监控和分析业务和运营数据。 |
|
|
数据和人工智能治理
|
对存储在 AWS、本地和第三方来源的数据进行分类、发现、共享和管理。 |
AWS 现代数据战略的总体经济影响
据 Forrester 报道,Amazon Web Services 现代数据策略可以节省成本并带来业务优势。
统计数据
找到今天要查找的内容了吗?
请提供您的意见,以便我们改进网页内容的质量