AWS Big Data Blog
Harness the power of your data with AWS Analytics
2020 has reminded us of the need to be agile in the face of constant and sudden change. Every customer I’ve spoken to this year has had to do things differently because of the pandemic. Some are focusing on driving greater efficiency in their operations and others are experiencing a massive amount of growth. Across the board, I see organizations looking to use their data to make better decisions quickly as changes occur. Such agility requires that they integrate terabytes to petabytes and sometimes exabytes of data that were previously siloed in order to get a complete view of their customers and business operations. Traditional on-premises data analytics solutions can’t handle this approach because they don’t scale well enough and are too expensive. As a result, we’re seeing an acceleration in customers looking to modernize their data and analytics infrastructure by moving to the cloud.
Customer data in the real world
To analyze these vast amounts of data, many companies are moving all their data from various silos into a single location, often called a data lake, to perform analytics and machine learning (ML). These same companies also store data in purpose-built data stores for the performance, scale, and cost advantages they provide for specific use cases. Examples of such data stores include data warehouses—to get quick results for complex queries on structured data—and technologies like Elasticsearch and OpenSearch—to quickly search and analyze log data to monitor the health of production systems. A one-size-fits-all approach to data analytics no longer works because it inevitably leads to compromises.
To get the most from their data lakes and these purpose-built stores, customers need to move data between these systems easily. For instance, clickstream data from web applications can be collected directly in a data lake and a portion of that data can be moved out to a data warehouse for daily reporting. We think of this concept as inside-out data movement.

Similarly, customers also move data in the other direction: from the outside-in. For example, they copy query results for sales of products in a given region from their data warehouse into their data lake to run product recommendation algorithms against a larger data set using ML.

Finally, in other situations, customers want to move data from one purpose-built data store to another: around-the-perimeter. For example, they may copy the product catalog data stored in their database to their search service in order to make it easier to look through their product catalog and offload the search queries from the database.
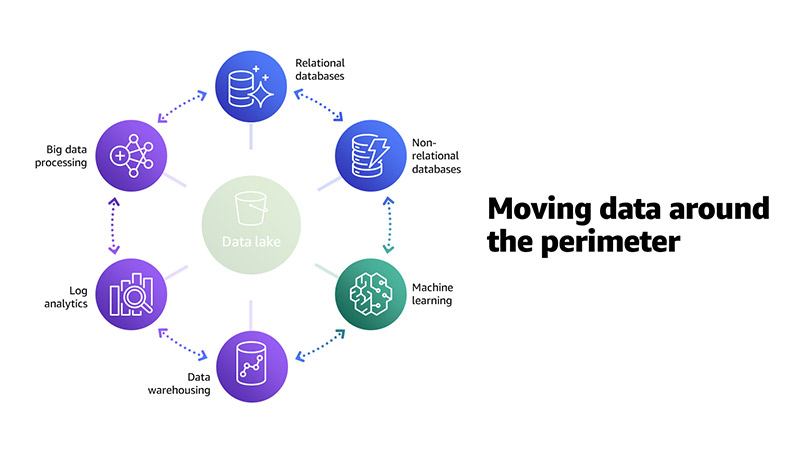
As data in these data lakes and purpose-built stores continues to grow, it becomes harder to move all this data around. We call this data gravity.
To make decisions with speed and agility, customers need to be able to use a central data lake and a ring of purpose-built data services around that data lake. They also need to acknowledge data gravity by easily moving the data they need between these data stores in a secure and governed way.
To meet these needs, customers require a data architecture that supports the following:
- Building a scalable data lake rapidly.
- Using a broad and deep collection of purpose-built data services that provide the performance required for use-cases like interactive dashboards and log analytics.
- Moving data seamlessly between the data lake and purpose-built data services and between those purpose-built data services.
- Ensuring compliance via a unified way to secure, monitor, and manage access to data.
- Scaling systems at low cost without compromising on performance.
We call this modern approach to analytics the Lake House Architecture.
Lake House Architecture on AWS
A Lake House Architecture acknowledges the idea that taking a one-size-fits-all approach to analytics eventually leads to compromises. It is not simply about integrating a data lake with a data warehouse, but rather about integrating a data lake, a data warehouse, and purpose-built stores and enabling unified governance and easy data movement. The diagram below shows the Lake House Architecture on AWS.
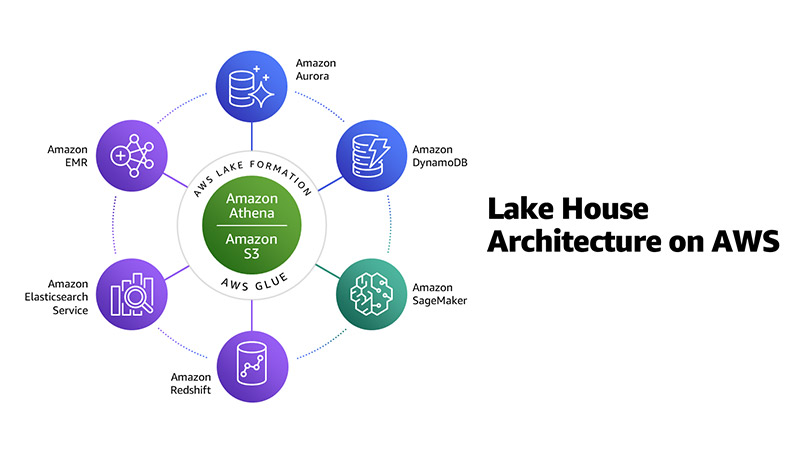
Let’s take a look at how the Lake House Architecture on AWS and some of the new capabilities we announced at re:Invent 2020 help our customers meet each of the requirements above..
Scalable data lakes
Amazon Simple Storage Service (Amazon S3) is the best place to build a data lake because it has unmatched durability, availability, and scalability; the best security, compliance, and audit capabilities; the fastest performance at the lowest cost; the most ways to bring data in; and the most partner integrations.
However, setting up and managing data lakes involves a lot of manual and time-consuming tasks such as loading data from diverse sources, monitoring data flows, setting up partitions, turning on encryption and managing keys, reorganizing data into columnar format, and granting and auditing access. To help make this easier, we built AWS Lake Formation. Lake Formation helps our customers build secure data lakes in the cloud in days instead of months. Lake Formation collects and catalogs data from databases and object storage, moves the data into an Amazon S3 data lake, cleans and classifies data using ML algorithms, and secures access to sensitive data.
In addition, we just announced three new capabilities for AWS Lake Formation in preview: ACID transactions and governed tables for concurrent updates and consistent query results and query acceleration through automatic file compaction. The preview introduces new APIs that support atomic, consistent, isolated, and durable (ACID) transactions using a new data lake table type, called a governed table. Governed tables allow multiple users to concurrently insert, delete, and modify rows across tables, while still allowing other users to simultaneously run analytical queries and ML models on the same data sets. Automatic file compaction combines small files into larger files to make queries by up to seven times faster.
Purpose-built analytics services
AWS offers the broadest and deepest portfolio of purpose-built analytics services, including Amazon Athena, Amazon EMR, Amazon OpenSearch Service, Amazon Kinesis, and Amazon Redshift. These services are all built to be best-of-breed, which means you never have to compromise on performance, scale, or cost when using them. For example, Amazon Redshift delivers up to three times better price performance than other cloud data warehouses, and Apache Spark on EMR runs 1.7 times faster than standard Apache Spark 3.0, which means petabyte-scale analysis can be run at less than half of the cost of traditional on-premises solutions.

We’re always innovating to meet our customer’s needs with new capabilities and features in these purpose-built services. For example, to help with additional cost savings and deployment flexibility, today we announced the general availability of Amazon EMR on Amazon Elastic Kubernetes Service (EKS). This offers a new deployment option of fully managed Amazon EMR on Amazon EKS. Until now, customers had to choose between running managed Amazon EMR on EC2 and self-managing their own Apache Spark on Amazon EKS. Now, analytical workloads can be consolidated with microservices and other Kubernetes-based applications on the same Amazon EKS cluster, enabling improved resource utilization, simpler infrastructure management, and the ability to use a single set of tools for monitoring.
For faster data warehousing performance, we announced the general availability of Automatic Table Optimizations (ATO) for Amazon Redshift. ATO simplifies performance tuning of Amazon Redshift data warehouses by using ML to automate optimization tasks such as setting distribution and sort keys to give you the best possible performance without the overhead of manual performance tuning.
We also announced the preview of Amazon QuickSight Q to make it even easier and faster for your business users to get insights from your data. QuickSight Q uses ML to generate a data model that automatically understands the meaning and relationships of business data. It enables users to ask ad hoc questions about their business data in human-readable language and get accurate answers in seconds. As a result, business users can now get answers to their questions instantly without having to wait for modeling by thinly-staffed business intelligence (BI) teams.
Seamless data movement
With data stored in a number of different systems, customers need to be able to easily move that data between all of their services and data stores: inside-out, outside-in, and around-the-perimeter. No other analytics provider makes it as easy to move data at scale to where it’s needed most. AWS Glue is a serverless data integration service that allows you to easily prepare data for analytics, machine learning, and application development. AWS Glue provides all the capabilities needed for data integration, so insights can be gained in minutes instead of months. Amazon Redshift and Athena both support federated queries, the ability to run queries across data stored in operational databases, data warehouses, and data lakes to provide insights across multiple data sources with no data movement and no need to set up and maintain complex extract, transform, and load (ETL) pipelines.
We also announced the preview of Amazon Redshift data sharing. Data sharing provides a secure and easy way to share live data across multiple Amazon Redshift clusters inside the organization and externally without the need to make copies or the complexity of moving around data. Customers can use data sharing to run analytics workloads that use the same data in separate compute clusters in order to meet the performance requirements of each workload and track usage by each business group. For example, customers can set up a central ETL cluster and share data with multiple BI clusters to provide workload isolation and chargeback.
Unified governance
One of the most important pieces of a modern analytics architecture is the ability to authorize, manage, and audit access to data. Enabling such a capability can be challenging because managing security, access control, and audit trails across all the data stores in an organization is complex and time-consuming. It’s also error-prone because it requires manually maintaining access control lists and audit policies across all storage systems, each with different security, data access, and audit mechanisms.
With capabilities like centralized access control and policies combined with column and row-level filtering, AWS gives customers the fine-grained access control and governance to manage access to data across a data lake and purpose-built data stores from a single point of control.
Today, we also announced the preview of row-level security for AWS Lake Formation, which makes it even easier to control access for all the people and applications that need to share data. Row-level security allows for filtering and setting data access policies at the row level. For example, you can now set a policy that gives a regional sales manager access to only the sales data for their region. This level of filtering eliminates the need to maintain different copies of data lake tables for different user groups, saving you operational overhead and unnecessary storage costs.
Performance and cost-effectiveness
At AWS, we’re committed to providing the best performance at the lowest cost across all analytics services and we continue to innovate to improve the price-performance of our services. In addition to industry-leading price performance for services like Amazon Redshift and Amazon EMR, Amazon S3 intelligent tiering saves customers up to 40% on storage costs for data stored in a data lake, and Amazon EC2 provides access to over 350 instance types, up to 400Gbps ethernet networking, and the ability to choose between On-Demand, Reserved, and Spot instances. We announced Amazon EMR support for Amazon EC2 M6g instances powered by AWS Graviton2 processors in October, providing up to 35% lower cost and up to 15% improved performance. Our customers can also take advantage of AWS Savings Plans, a flexible pricing model that provides savings of up to 72% on AWS compute usage.
To set the foundation for the new scale of data, we also shared last week that the AQUA (Advanced Query Accelerator) for Amazon Redshift preview is now open to all customers and will be generally available in January 2021. AQUA is a new distributed and hardware-accelerated cache that brings compute to the storage layer, and delivers up to ten times faster query performance than other cloud data warehouses. AQUA is available on Amazon Redshift RA3 instances at no additional cost, and customers can take advantage of the AQUA performance improvements without any code changes.
Learn More and Get Started Today
Whatever a customer is looking to do with data, AWS Analytics can offer a solution. We provide the broadest and deepest portfolio of purpose-built analytics services to realize a Lake House Architecture. Our portfolio includes the most scalable data lakes, purpose-built analytics services, seamless data movement, and unified governance – all delivered with the best performance at the lowest cost.
Read all the Analytics announcements from AWS re:Invent 2020 at What’s New at AWS re:Invent? and apply for the analytics previews using the links below. Also dive deeper by watching the more than 40 analytics sessions that were part of AWS re:Invent 2020. Simply visit the session catalog and choose the Analytics track to review past sessions and add upcoming ones to your calendar.
Finally, take advantage of the AWS Data Lab. The AWS Data Lab offers opportunities for customers and AWS technical resources to engage and accelerate data and analytics modernization initiatives.
Announcement and Preview Links
- AWS Lake Formation transactions, row-level security, and acceleration preview
- Amazon EMR on Amazon EKS
- Automatic Table Optimizations for Amazon Redshift
- Amazon QuickSight Q preview
- Amazon Redshift data sharing preview
- AQUA for Amazon Redshift preview
- Amazon EMR Studio preview
About the Author
 Rahul Pathak is Vice President of Analytics at AWS and is responsible for Amazon Athena, Amazon OpenSearch Service, EMR, Glue, Lake Formation, and Redshift. Over his nine years at AWS, he has focused on managed database, analytics, and database services. Rahul has over twenty years of experience in technology and has co-founded two companies, one focused on digital media analytics and the other on IP-geolocation. He holds a degree in Computer Science from MIT and an Executive MBA from the University of Washington.
Rahul Pathak is Vice President of Analytics at AWS and is responsible for Amazon Athena, Amazon OpenSearch Service, EMR, Glue, Lake Formation, and Redshift. Over his nine years at AWS, he has focused on managed database, analytics, and database services. Rahul has over twenty years of experience in technology and has co-founded two companies, one focused on digital media analytics and the other on IP-geolocation. He holds a degree in Computer Science from MIT and an Executive MBA from the University of Washington.