Блог Amazon Web Services

Надёжность, шаблон постоянной работы и чашка хорошего кофе
Оригинал статьи: Reliability, constant work, and a good cup of coffee, By Colm MacCárthaigh Кофе и масштабируемость Одна из моих любимых картин – «Ночные ястребы» Эдварда Хоппера. Несколько лет назад мне повезло увидеть её в Чикагском институте искусств. Поздняя ночь. Витрина открывает вид на трех посетителей. На одном углу барной стойки мужчина, сидящий спиной, на […]

Генерация инсайтов безопасности с помощью машинного обучения на данных Amazon Security Lake используя Amazon SageMaker
В этой статье мы расскажем о том, как генерировать информационно-значимые инсайты безопасности по данным Amazon Security Lake с помощью Amazon SageMaker Studio — веб-интегрированной среды разработки (IDE) для машинного обучения. Предлагаемое в этой статье решение, содержит базовый набор блокнотов Python, ориентированных на данные AWS Security Hub findings в Amazon Security Lake, которые при необходимости могут быть обогащены событиями и из других источников AWS или пользовательских источников данных.

Amazon Personalize запускает новые рецепты, поддерживающие более крупные каталоги товаров с меньшей задержкой
Amazon Personalize позволяет легко персонализировать ваш веб-сайт, приложение, электронные письма и многое другое, используя ту же технологию машинного обучения (ML), которую использует Amazon, при этом не требуя специальных знаний в области ML. Сегодня мы рады сообщить об общедоступности двух усовершенствованных рецептов в Amazon Personalize, User-Personalization-v2 и Personalized-Ranking-v2 (рецепты v2), которые построены на передовой Трансформерной архитектуре и поддерживают большие каталоги товаров с меньшей задержкой.

AWS Security Day в Алматы
16 июня состоялся AWS Security Day в городе Алматы, Казахстан. Эксперты из qCloudy, KPMG, AWS и КИБ МЦРИАП РК поделились своим опытом и знаниями о лучших практиках и инструментах для защиты инфраструктуры и приложений в облаке AWS. В посте мы выложили ссылки на все доклады мероприятия.

Что такое AWS Outposts и как заказать его в Казахстане
AWS Outposts – полностью управляемое решение, которое позволяет пользователям вынести инфраструктуру AWS, включая сервисы, API и инструменты в собственный центр обработки данных. Оно позволяет создавать и выполнять в датацентре приложения, используя те же средства и подходы, которые предоставляет облако AWS. Outpost предоставляет вычислительные ресурсы и хранилище для локальной обработки данных с низкой задержкой. Для развертывания […]
Как получить помощь по облаку Amazon Web Services?
Облаком Amazon Web Services (AWS Cloud) можно воспользоваться без обращения в отдел продаж и подписания контракта на бумаге. Для того, чтобы запустить приложение в облаке, достаточно создать аккаунт, кликнув на «Создание аккаунта AWS» в правом верхнем углу сайта aws.amazon.com. AWS старается, чтобы сервисами было пользоваться легко, удобно, а главное быстро. Самообслуживание, доступ к любому сервису […]

6 стратегий миграции приложений в облако
«Какой бывает эмиграция? Что ж, это зависит от многих факторов: образования, экономического положения, языка, нового места и того, какую поддержку там можно найти.» — Даниэль Аларкон В первом посте серии представлена концепция массовой миграции, которую мы будем называть просто «миграцией» в каждом из материалов. Во втором посте серии описан процесс массовой миграции в облако, а […]

Создание кластеров с помощью EKS Blueprints
Оригинал статьи: ссылка (Kevin Coleman, Principal Container Specialist; Apoorva Kulkarni, Sr. Specialist Solutions Architect; Mikhail Shapirov, Senior Partner Solutions Architect; Vara Bonthu, Senior Open Source Engineer) Сегодня мы представляем новый проект с открытым исходным кодом под названием EKS Blueprints, который упрощает и ускоряет внедрение Amazon Elastic Kubernetes Service (Amazon EKS). EKS Blueprints — это набор модулей Infrastructure […]
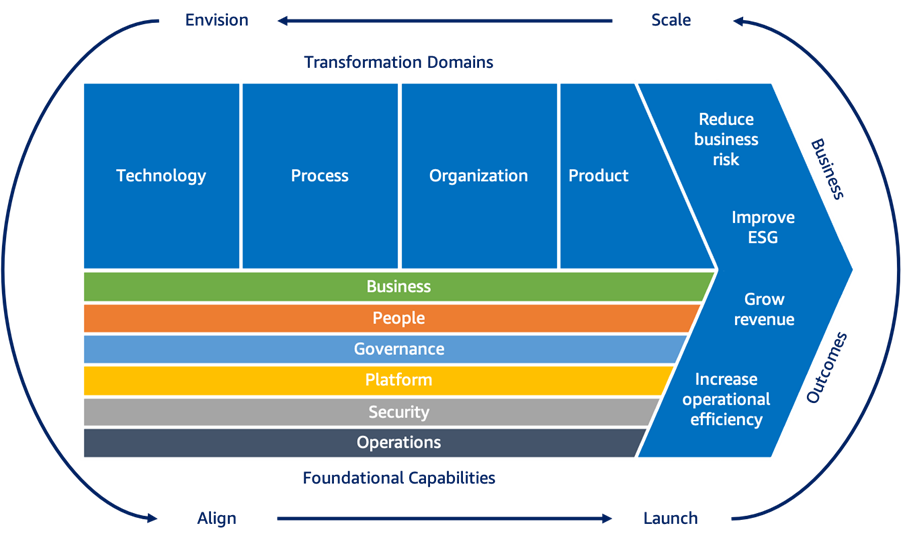
AWS Cloud Adoption Framework (CAF) 3.0 уже доступен
AWS Cloud Adoption Framework (AWS CAF) предназначен для того, чтобы помочь вам построить и затем реализовать комплексный план цифровой трансформации. Используя лучшие практики AWS и опыт, извлеченный из тысяч клиентских проектов, AWS CAF поможет вам определить возможности трансформации и расставить приоритеты, оценить и улучшить вашу готовность к облаку, а также итеративно развивать дорожные карты, по […]

Тонкая настройка и хостинг Hugging Face BERT моделей на Amazon SageMaker
Ранее в этом году было объявлено о сотрудничестве между Hugging Face и AWS, чтобы компаниям было проще использовать модели машинного обучения (ML) и быстрее получать модели с современными возможностями обработки текстов. В этом посте мы покажем вам, как использовать DLC SageMaker Hugging Face, сделать тонкую настройку предварительно обученной модели BERT и развернуть её в SageMaker как управляемую конечную точку HTTP для инференса.