Блог Amazon Web Services
Тонкая настройка и хостинг Hugging Face BERT моделей на Amazon SageMaker
Оригинал статьи: ссылка (Eddie Pick, Senior Startup Solutions Architect и Dhawalkumar Patel, Startup Senior Solutions Architect)
Несколько лет назад начала расти популярность архитектуры deep-learning нейронных сетей «трансформер» для построения моделей обработки естественных языков (NLP). Адаптация архитектуры «трансформер» в таких моделях, как BERT, RoBERTa, T5, GPT-2 и DistilBERT, превосходит предыдущие модели NLP в широком круге задач, таких как классификация текста, ответы на вопросы, обобщение и генерация текста. Эти модели экспоненциально увеличивались в размерах от нескольких миллионов параметров до нескольких сотен миллиардов параметров. По мере увеличения числа параметров модели увеличивается и вычислительная инфраструктура, необходимая для обучения этих моделей.
Для обучения и оптимизации подобных моделей требуется значительное количество времени, навыков и вычислительных ресурсов.
К сожалению, эта сложность не позволяет большинству организаций эффективно использовать эти модели, либо они не используют их вообще. Не было бы продуктивнее, если бы вы могли начать с предварительно обученной версии и сразу же приступить к работе? Это бы также позволило вам тратить больше времени на решение бизнес-задач.
В этом посте показано, как использовать Amazon SageMaker и Hugging Face для тонкой настройки предварительно обученной модели BERT и развертывания ее в качестве конечной точки управляемого вывода в SageMaker.
Общие сведения
Hugging Face — это технологический стартап с активным open source сообществом, который способствовал внедрению моделей на основе трансформеров во всем мире. Ранее в этом году было объявлено о сотрудничестве между Hugging Face и AWS, чтобы компаниям было проще использовать модели машинного обучения (ML) и быстрее получать модели с современными возможностями обработки текстов. В рамках этого сотрудничества Hugging Face использует AWS в качестве предпочтительного поставщика облачных сервисов для предоставления сервисов своим клиентам. В числе готовых моделей в репозитории Hugging Face есть и большое количество моделей на русском языке.
Чтобы помочь нашим общим клиентам начать работу, Hugging Face и AWS представили новые контейнеры глубокого обучения Hugging Face (DLC), которые упрощают обучение и развертывание моделей с использованием трансформеров Hugging Face на SageMaker. DLC полностью интегрированы с библиотеками распределенного обучения SageMaker для более быстрого обучения моделей с использованием Accelerated Computing инстансов последнего поколения, доступных в Amazon Elastic Compute Cloud (Amazon EC2). С SageMaker Python SDK вы можете обучать и развертывать свои модели с помощью одной строчки кода, что позволяет вашим командам быстрее перейти от идеи к работающему решению. Чтобы развернуть модели Hugging Face в SageMaker, вы можете использовать DLC Hugging Face с новым Hugging Face Inference Toolkit. С новыми Hugging Face Inference DLC вы можете развернуть свои модели для инференса с помощью еще одной строчки кода или выбрать из более чем 10 000 предварительно обученных моделей, включая модели с поддержкой русского языка, доступных в Hugging Face Hub, и развернуть их с помощью SageMaker, чтобы легко создавать готовые к использованию конечные точки, которые легко масштабируются с помощью встроенных средств мониторинга и безопасности корпоративного уровня.
Одной из самых больших проблем, с которыми сталкиваются специалисты по обработке данных в проектах NLP, является нехватка обучающих данных; для обучения модели часто используется всего несколько тысяч примеров текстовых данных с проставленными людьми метками. Однако современные задачи NLP с глубоким обучением требуют большого количества размеченных данных. Одним из способов решения этой проблемы является использование трансферного обучения. Трансферное обучение — это метод машинного обучения, при котором предварительно обученная модель, например, предварительно обученная модель ResNet для классификации изображений, используется повторно в качестве отправной точки для другой, но связанной проблемы. Повторное использование параметров из предварительно обученных моделей позволяет значительно сэкономить время и затраты на обучение. Модель BERT была обучена на данных BookCorpus и английской Википедии, которые содержат 800 млн слов и 2500 млн слов соответственно. Обучение BERT с нуля было бы непомерно дорого. Воспользовавшись преимуществами трансферного обучения, вы можете быстро настроить BERT для другого варианта использования с относительно небольшим объемом обучающих данных, чтобы получить самые продвинутые результаты для типичных задач NLP, таких, как классификация текстов и ответы на вопросы.
В этом посте мы покажем вам, как использовать DLC SageMaker Hugging Face, сделать тонкую настройку предварительно обученной модели BERT и развернуть её в SageMaker как управляемую конечную точку HTTP для инференса.
Работа с моделями Hugging Face в SageMaker
В этом примере используются трансформеры и датасеты от Hugging Face вместе с SageMaker для тонкой настройки предварительно обученной модели на базе трансформеров для бинарной классификации текста и развертывание этой модели для инференса.
Для демонстрации здесь используется модель DistilBERT — небольшая, быстрая, дешевая и легкая модель на основе трансформеров и архитектуре BERT. Дистилляция знаний в ней была сделана на этапе предварительного обучения, чтобы уменьшить размер модели BERT на 40%. Заранее обученная модель доступна в библиотеке transformers из Hugging Face.
Вы доработаете эту предварительно обученную модель с помощью датасета Amazon Reviews Polarity, который содержит около 35 миллионов отзывов от клиентов Amazon, и сможете классифицировать отзыв как положительный или отрицательный. Отзывы были собраны в 1995—2013 годах и включают информацию о продукте и пользователях, рейтинги и текстовые комментарии. Он доступен как датасет amazon_polarity на Hugging Face.
Подготовка данных
В этом примере подготовка данных проста, поскольку непосредственно из Hugging Face вы используете библиотеку datasets для загрузки и предварительной обработки датасета amazon_polarity.
Ниже приведен пример данных:
Метка 1 означает положительный отзыв, а 0 — отрицательный отзыв. Ниже приведен пример положительного отзыва:
Ниже приведен пример негативного отзыва:
Как показано на следующей визуализации, набор данных уже хорошо сбалансирован и дальнейшая предварительная обработка не требуется.

Модели на основе трансформеров в целом, и BERT и DistilBERT в частности, используют токенизацию. Это означает, что слово может быть разбито на одно или несколько подслов, на которые ссылается словарь модели. Например, предложение «Меня зовут Мария» обозначается как [CLS] Меня зовут Мари # #я [SEP], которое представлено вектором [101, 1422, 1271, 1110, 27859, 2328, 102]. Hugging Face предоставляет серию предварительно обученных токенизаторов для разных моделей.
Чтобы импортировать токенизатор для DistilBERT, используйте следующий код:
Этот токенизатор используется для токенизации тренировочного и тестового датасетов, а затем конвертирует их в формат PyTorch, используемый во время обучения. См. следующий код:
После обработки данных вы загружаете их в Amazon Simple Storage Service (Amazon S3) для обучения:
Обучение с помощью Hugging Face Estimator
Вам нужен Hugging Face Estimtor, чтобы создать Training Job в SageMaker. Estimator полностью берет на себя процесс обучения в SageMaker. В Estimator вы определяете, какой скрипт тонкой настройки следует использовать как entry_point, какой instance_type следует использовать и какие гиперпараметры нужно передать.
Гиперпараметры могут быть следующими:
- Количество эпох
- Размер пакета
- Название модели
- Название токенизатора
- Выходной каталог
Скрипт обучения использует имя модели и название токенизатора для загрузки предварительно обученной модели и токенизатора из Hugging Face:
Когда вы создаете Training Job в SageMaker, SageMaker позаботится о следующем:
- Запуск и управление всеми необходимыми вычислительными инстансами с помощью контейнера
huggingface - Загрузка предоставленного скрипта тонкой настройки
train.py - Загрузка данных из
sagemaker_session_bucketв контейнер в каталог/opt/ml/input/data
Затем он запускает Training Job, выполнив следующую команду:
Гиперпараметры, заданные в Estimator, передаются как именованные аргументы.
SageMaker предоставляет полезные возможности по настройке среды обучения с помощью различных переменных среды, включая следующие:
- SM_MODEL_DIR — Строка, представляющая путь, по которому обучающее задание записывает артефакты модели. После обучения артефакты из этого каталога загружаются в Amazon S3, для того чтобы после модель можно было где-то разместить.
- SM_NUM_GPUS — Целое число, представляющее количество графических процессоров, доступных для хоста.
- SM_CHANNEL_XXXX — Строка, представляющая путь к каталогу, содержащему входные данные для указанного канала. Например, если в вызове функции
fitобъекта Estimator указать два входных канала, называемыхtrainиtest, будут установлены переменные окруженияSM_CHANNEL_TRAINиSM_CHANNEL_TEST.
Начните тренировку с помощью функции fit:
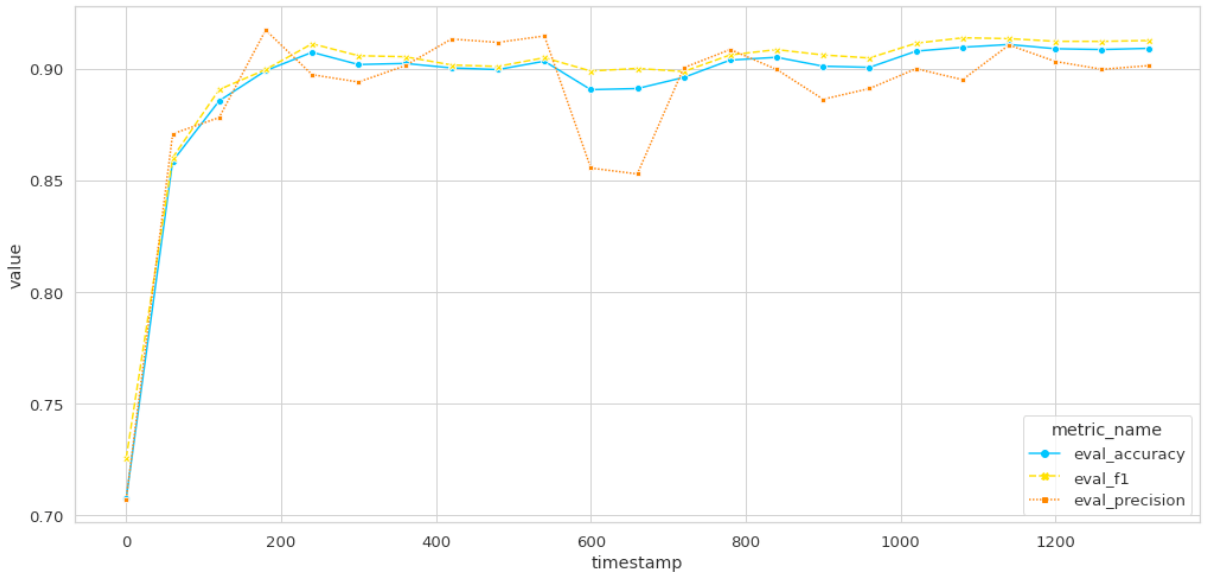
По завершении обучения метрики можно нарисовать на графике.
Архитектура для разворачивания модели Hugging Face на SageMaker для инференса
Hugging Face Inference Toolkit for SageMaker — это библиотека с открытым исходным кодом для разворачивания моделей Hugging Face на основе трансформеров на SageMaker. В нем используется SageMaker Inference Toolkit для запуска сервера с моделью, который отвечает за обработку запросов на инференс. SageMaker Inference Toolkit использует Multi Model Server (MMS) для разворачивания ML. Он загружает MMS с конфигурацией и настройками, которые делают его совместимым с SageMaker и позволяют вам настраивать важные параметры производительности, такие как количество обработчиков на модель, в зависимости от потребностей вашего сценария.
MMS — это фреймворк с открытым исходным кодом для разворачивания ML моделей с гибким и простым в использовании инструментом для разворачивания моделей глубокого обучения, обученных с использованием любого фреймворка ML/DL. Вы можете использовать CLI для сервера MMS или предварительно настроенные образы Docker для запуска службы, которая настраивает конечные точки HTTP для обработки запросов на инференс моделей. Он также предоставляет подключаемый бэкэнд, который поддерживает подключаемый пользовательский бэкенд-обработчик, в котором вы можете реализовать свой собственный алгоритм.
Вы можете развернуть тонко настроенные или предварительно обученные модели с DLC Hugging Face на SageMaker, используя Hugging Face Inference Toolkit для SageMaker без необходимости написания каких-либо пользовательских функций инференса. Вы также можете настроить инференс, предоставив свой собственный скрипт для инференса и переопределяя методы по умолчанию в HuggingFaceHandlerService. Это можно сделать, переопределяя методы input_fun (), output_fn (), predict_fn (), model_fn () или transform_fn ().
На следующей диаграмме показана анатомия конечной точки инференса SageMaker Hugging Face.

Как показано в архитектуре, MMS слушает порт, принимает входящий запрос на инференс и перенаправляет его процессу Python для дальнейшей обработки. В MMS используется фронтенд сервер на базе Java, который использует инфраструктуру клиентского сервера NIO под названием Netty. Платформа Netty обеспечивает лучшую пропускную способность, меньшую задержку и меньшее потребление ресурсов, минимизирует ненужные копии в памяти и позволяет использовать гибко настраиваемую модель потоков — один поток или один или несколько пулов потоков. Можно точно настроить конфигурацию MMS, включая количество потоков Netty, количество рабочих процессов на модель, размер очереди заданий, время ожидания ответа, конфигурацию JVM и т. д., изменив файл конфигурации MMS. Дополнительные сведения см. в разделе Расширенная настройка.
MMS перенаправляет запрос на инференс в обработчик по умолчанию, предоставленный SageMaker Hugging Face, или в пользовательский скрипт. Обработчик по умолчанию SageMaker Hugging Face использует Hugging Face pipeline abstraction API для выполнения предсказаний для моделей с использованием соответствующей базовой платформы глубокого обучения, а именно PyTorch или TensorFlow. В зависимости от типа настроенного инстанса EC2, конвейер использует устройства CPU или GPU для выполнения инференса и возврата ответа клиенту через фронтенд сервер MMS. Вы можете настроить переменные среды для точной настройки SageMaker Hugging Face Inference Toolkit. Кроме того, вы можете точно настроить стандартную конфигурацию Hugging Face.
Разворачивание тонко настроенной модели BERT для инференса
Чтобы развернуть вашу тонко настроенную модель для инференса, выполните следующие шаги:
1. Определите модель Hugging Face, используя следующий код:
2. Разверните конечную точку инференса для этой тонко настроенной модели:
3. После развертывания, проверьте модель с помощью следующего кода:
Результатом является положительный (LABEL_1) для 99.88%.
Полностью решение доступно в репозитории GitHub.
Очистка
После завершения экспериментов с этим проектом запустите predictor.delete_endpoint(), чтобы удалить конечную точку.
Заключение
В этом посте показано, как тонко настроить предварительно обученную модель на базе трансформеров посредством датасета с помощью SageMaker Hugging Face Estimator, а затем разместить ее на SageMaker с помощью инструментария SageMaker Hugging Face Inference Toolkit для инференса в реальном времени. Мы надеемся, что этот пост позволит вам быстро настроить модель на базе трансформеров с собственным датасетом и внедрить современные методы NLP в свои продукты. Полное решение доступно в репозитории на GitHub. Попробуйте и сообщите нам, что вы думаете в комментариях!