亚马逊AWS官方博客
Derby容器化之路(一) EKS的搭建与核心组件的生命周期管理
相比较自建Kubernetes,AWS EKS是一项托管的Kubernetes服务,与社区保持一致。EKS也可以实现自动管理安排容器,管理应用程序可用性,存储集群数据和其他关键性任务的Kubernetes控制平面节点的可用性和可扩展性。从云原生角度出发,也大量节省了运维成本。
针对搭建EKS集群的任务,我们做了阶段性分解,并且针对每个阶段来结合自身业务特征和应用特征做出判断。第一部分是底层网络,第二部分是workernode 节点镜像的构建,而最后一部分就是EKS服务。同时,结合多年的AWS服务应用,我们也遵循了infrastructure as code的最佳实践原则,在构建服务之初,就将所有的基础设施代码化,并形成标准,便于今后的运维,管控和重用。
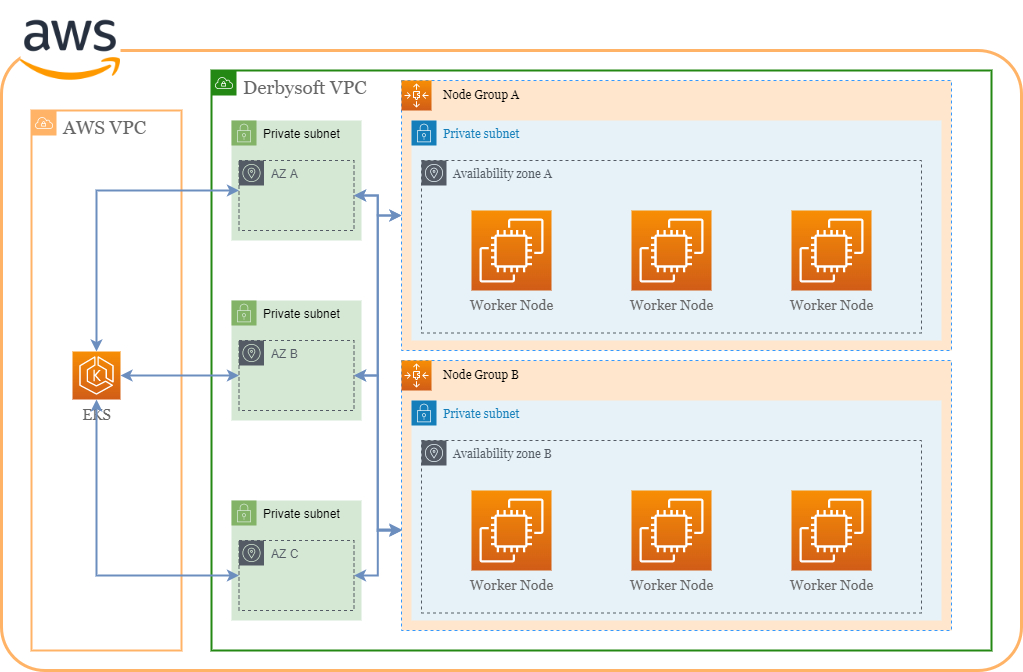
首先我们需要考虑网络层面的构建。EKS的 workernode 节点仍然依赖 AWS VPC 作为底层基础的网络环境。在AWS VPC中,默认情况下私有子网中的 pod 发起主动访问 Internet 或AWS公有服务的请求仍然需要通过NAT Gateway来执行NAT操作。由于德比软件的业务特征,大量客户请求会落在相同的客户服务器上,而随着业务的不断增长,我们希望当NAT Gateway达到转发瓶颈,比如当一个NAT Gateway的所处理的会话超过65536个时,可以及时做出调整。
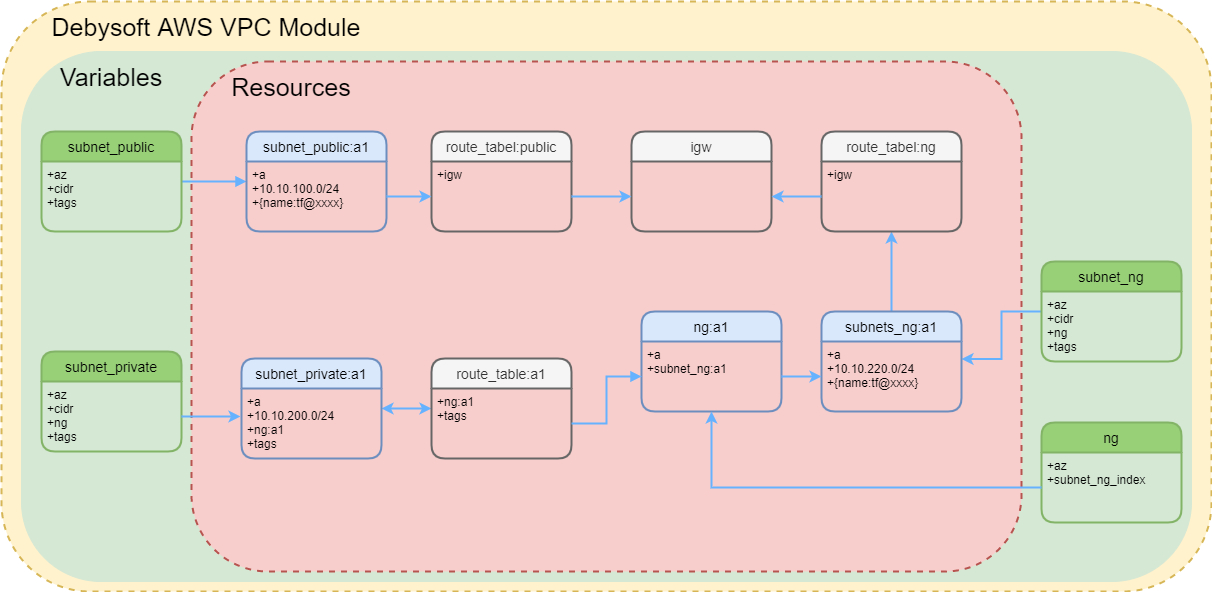
基于这些原因,我们并没有使用eksctl来创建网络环境,而是选择terraform来创建和管理VPC。基于terraform,我们封装了一个自己的VPC module,通过它,可以灵活组建各种子网与出口网关的结构,而运维人员只需通过VPC module 提供的variables就可以创建VPC,后期只需要更改入参,并且应用到云上即可。除此之外,通过 IaC 的方式来创建和管理 VPC 的另一个好处,在网络情况比较复杂的时候,如果通过console去查看网络之间的关系会非常的麻烦,需要频繁的切换页面,而通过 IaC 的代码则可以一目了然的看出所有的网络之间的关系。
第二部分是有关EKS wokernode ami。AWS在2020年8月时发布了可使用自定义 AMI 和 EC2 启动模板的托管节点组,德比软件也选择这种方式来构建自己的 EKS workernode 节点。使用自定义ami的原因主要有二点,首先是德比软件对于基础设施的安全非常注重,所以我们通过Packer,基于官方的eks worker node ami进行打包,并且通过CISA hardening guide来加固镜像。打包过程非常便捷,并且可以满足我们的合规性要求。其次是我们想把系统卷和容器卷分开,这样可以保证系统不会因为磁盘被异常使用占满而导致 wokernode 节点不可用。
第三部分就是配置eksctl文件并创建集群,这里有两个配置比较需要额外注意,一个是Subnet,另一个就是前面所提及的节点组,NodeGroup。示例的eksctl 配置如下:
Subnet 在 eksctl 中的作用主要用于EKS托管控制平面与自建 VPC 之间关联, 也就是说, 主要的意义在于 EKS控制平面可以通过该子网来对 workernode 节点形成网络上的通信,进而可以对workernode节点进行管理和操作。基于EKS管理平台的特征,此处我们将子网数量设置成3个即可。
EKS NodeGroup 是 AWS 一个特有的概念,它通过 AutoScaling 服务提供了一个可按需动态扩缩容的 workernode 集群组。德比软件基于自身的应用特征对 NodeGroup 做了一些特殊配置。首先我们将 NodeGroup 设置仅在一个可用区下进行扩缩容操作,这样的好处之一,是从成本角度考虑,相同可用区之间的通信可以避免跨可用区流量费用的产生。其二是避免了当时曾经遇到的 pvc 所在的 workernode 出现异常时,Cluster Autoscaler无法在故障 pvc 所在可用区进行指定可用区扩的问题。基于跨可用区高可用的设计原则, Cluster Autoscaler无法保证 NodeGroup 新开出来的worker node会在所指定的可用区当中,这种情况可能导致该 pvc 的 pod 长时间不可用而造成业务超时。其三,是我们自定了一个特殊label,label key为support,所有发到集群中的应用需要设定support类型,这样可以把业务类的应用和基础设施类的应用放置在不同的NodeGroup中,一是可以在更新维护时优先更新基础设施的 NodeGroup,从而不影响业务应用;二是基础设施的NodeGroup可以使用更小的实例尺寸从而减少基础设施成本,对于部分不要求高可用性的应用,则基于这个 label,置放到 Sopt Instance 的特定 NodeGroup 中进一步达成成本优化的目标。
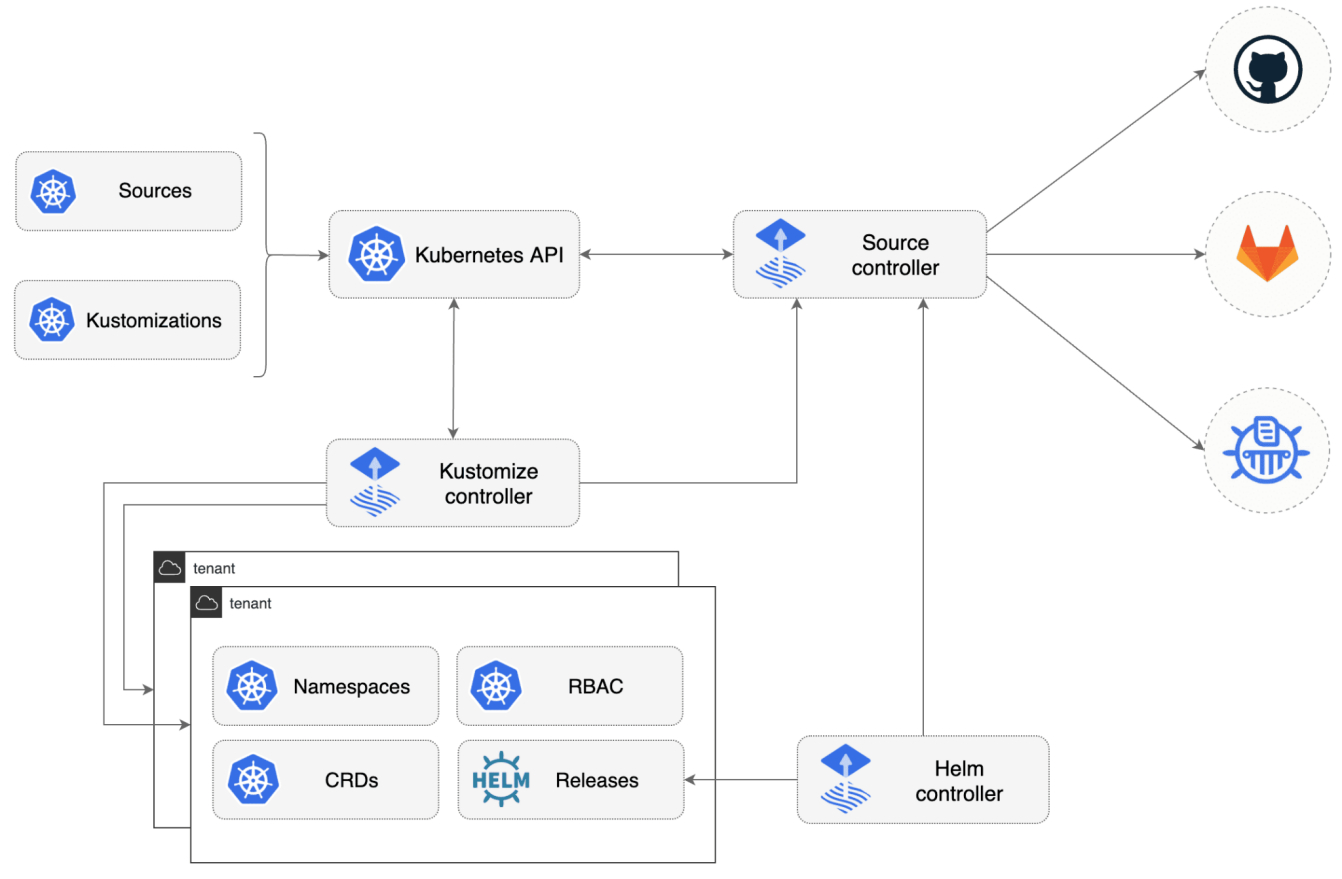
GitOps核心组件的生命周期管理
在传统的DevOps运维体系当中,围绕着Kubernetes集群工作的核心组件非常繁杂,如何有效运维维这些组件也成为运维团队重要而头痛的工作之一。AWS EKS 为解决这些痛点提供了add-on的功能,该功能可以一键维护如kube proxy,core-dns,vpc-cni这些重要的组件,但其他的组件比如监控,日志,Application LoadBalancer,Cluster Autosacler等等,也需要运维团队自身去管理和维护。
最初我们都是通过 kubectl apply 命令应用到集群中,但这种操作方式存在着一些问题,比如如何保证一个安全可控的流程。因为任何一个有权限的运维工程师都可以直接把一个组件更新到集群中,从而可能引发一些意外故障的注入。基于卓越运维的原则,我们希望能尽可能减少人为的操作和干预,从而实现可控的流程。此外,考虑到其他的配置,比如Service Account。一般新建一个 Service Account 也会创建新的的 Role 和 Role Binding 配置,但随着 sa 越来越多,管理成本也会越来越高。在结合应用场景,并结合最佳实践后,我们决定使用GitOps来解决这一问题。
GitOps是一种基于云原生应用实施持续部署的方法。其核心思想是通过创建 Git 仓库管理环境中所期望的基础设施声明描述文件,随后集群中的 GitOps 系统会定期更新这些文件,从而保证环境中的配置与代码描述的一致。这里有个很重要的一点就是虽然配置文件本身可以用git管理,但是如果不经过 GitOps 系统,就无法确认是否与当前集群中的配置一致。目前我们用的是 Fluxcd 系统,主要管理了servcie account,ingress和所有非业务应用的核心组件,其流程是系统工程师提交新的代码到仓库中,由审核人审核代码,标注 comments 并 merge 到主分支中,而GitOps系统只check主分支的代码,随后然后应用到集群中。如果新创建一个 EKS 集群,只需要修改部分配置,利用 GitOps,创建的新集群可以快速安装完所有的组件,并且与其他集群保持一致。
过去的2年中,在保障业务稳定性的大前提之下,德比软件逐步完善容器化的迁移过程。从而顺利的将构建在 EC2 上的应用迁移至由 EKS 管理的容器化集群。在下一篇中,我们将分享应用迁移过程中的一些经验与心得。