亚马逊AWS官方博客
AWS DeepLens Lambda 函数与新 Model Optimizer 详解
今天我们推出了面向 AWS DeepLens 的新 Model Optimizer,优化深度学习模型,只需一行 Python 代码即可在 DeepLens GPU 上高效运行。Model Optimizer 已在 AWS DeepLens 软件版本 1.2.0 中提供。
AWS DeepLens 使用深度神经网络计算库 (Cl-DNN) 来访问推断 GPU。模型必须转换为 Cl-DNN 格式后才能在 AWS DeepLens 上运行。根据具体模型的大小,只需输入如下一行代码,Model Optimizer 可在 2-10 秒内完成这一转换:
将此代码行放入推断 Lambda 函数,即可访问 Model Optimizer。推断 Lambda 函数可让 AWS DeepLens 访问您刚刚部署的模型。在本贴中,我们演示了如何创建推断 Lambda 函数,并提供了一个模板,您可以根据自己的需要对此模板进行自定义。
推断 Lambda 函数执行三个关键功能:预处理、推断和后处理。
如要创建推断 Lambda 函数,请使用 AWS Lamda 控制台并执行如下步骤
- 选择创建函数。对此函数进行自定义,以运行深度学习模型的推断。
- 选择蓝图
- 搜索 greengrass-hello-world 蓝图。
- Lambda 函数名必须与模型名相同。
- 选择现有的 IAM 角色:AWSDeepLensLambdaRole。 此决策必须在注册过程中事先创建。
- 选择创建函数。
- 函数代码中的句柄必须是 greengrassHelloWorld.function_handler。
- 在 GreengrassHello 文件中,应清除所有代码。您将在此文件中写入推断 Lambda 函数的代码。
首先导入要求的文件包:
导入 os 可让您访问 AWS DeepLens 的操作系统。导入 awscam 可让您访问 AWS DeepLens 推断 API。 mo 可让您访问 Model Optimizer。 cv2 可让您访问开放 CV 库,该库包含额图像预处理和导入的常用工具。 thread 可让您访问 Python 的多线程库。请使用单独的线程向 mplayer 发送推断结果,并可在那里查看模型的输出。
然后创建 Greengrass Core SDK 客户端,从而可以使用 MQTT 通过 AWS IoT 向云发送消息。Greengrass core SDK 已经加载到设备行,因此无需导入。
然后为 Lambda 函数创建向其发送消息 AWS IoT 主题。您可以在 AWS IoT 控制台上访问此主题。
如要启用通过 mplayer 在本地查看输出的功能,请声明一个全局变量,其中包含要输入到 FIFO 文件中的 jpeg 图像 results.mjpeg。此外,您还可以将 Write_To_FIFO 修改为 False,从而关闭指向 FIFO 文件的流。这将终止该线程,因此您将无法通过 mplayer 访问图像以查看输出。
然后创建一个在自有线程上运行的简单类,从而让您可以将输出图像发布到 FIFO 文件并使用 mplayer 查看。这是通过 mplayer 查看输出的标准代码,对所有推断 Lambda 函数通用。对于您自己的项目,您可以将此代码复制到自己的推断 Lambda 函数中。
然后在 Lambda 函数中定义推断类。 首先定义一个 Greengrass 推断函数。
input_width 和 input_height 参数定义了模型的输入参数。如要执行推断,模型要求帧的大小相同。对于您部署到 AWS DeepLens 的模型,您可以自定义这些参数。
在下一行定义模型名。模型名的前缀必须与经受训练的模型的 params 文件和 json 文件前缀一致。例如,如果 params 文件和 json 文件分别为 squeezenet_v1.1-0000.params 和 squeezenet_v1.1-symbol.json,则模型名的前缀必须为 squeezenet_v1.1。这一点十分重要。如果模型名的前缀与这两个文件不一致,推断将无法进行,将会发生错误。
然后启动 Model Optimizer。这将把所部署的模型转换为 Cl-DNN 格式,从而可以在 AWS DeepLens GPU 中访问。这将返回指向优化后内容的路径。
将模型加载到推断引擎中。这是您提供代码以访问 GPU 的地方。如要访问 CPU,只需输入代码 “GPU” = 0。但对于深度学习模型,我们建议您访问 GPU 以提高效率和速度。
您可以向 AWS IoT 发送一条消息,告诉它模型已经加载。
然后定义您要运行的模型类型。例如,中性传输的模型类型为 segmentation,对象本地化的模型类型为 ssd (单次多重检测器)。对于图像分类,模型类型为 classification。由于您部署的是对图像进行分类的 squeezenet 模型,因此模型类型应定义为 classification。
由于 squeezenet_v1.1 有多达 1,000 个分类符,编写 python 列表来定义数字标签与人类刻度标签的映射表是不实际的。为此我们将添加一个文本文件,按顺序列出索引和所代表的标签。您可以在此处找到有关此示例的文本文件。
如要为 Lambda 函数添加该文本文件:
- 在函数代码部分,选择文件。然后选择新建文件
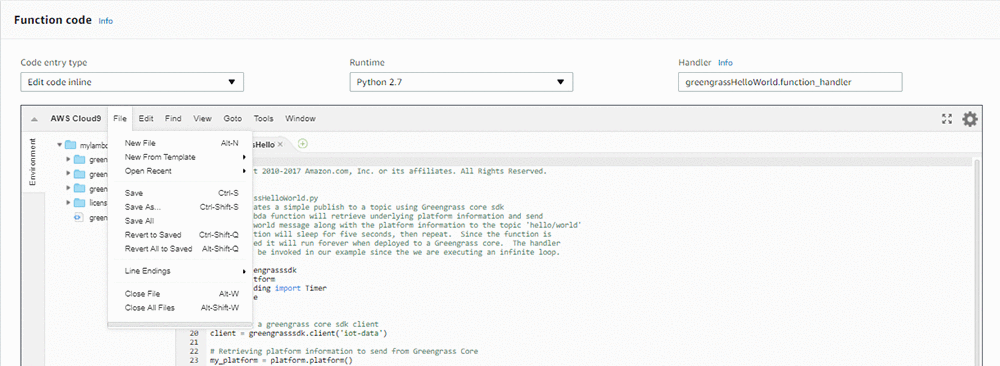
- 将文本文件中的数据粘贴到您刚刚创建的新文件中
- 选择文件,然后选择保存
- 输入文件名 sysnet.txt,然后选择保存
含有相关索引和标签的文件将被添加到 Lambda 函数包中。
现在从左侧菜单中选择 greengrassHelloWorld.py,将返回您的 python 代码。下一步是打开我们刚刚添加的“sysnet.txt”。
定义您希望在输出中看到的分类符数量。输入 5,输出结果将按降序返回概率最高的 5 个值。您可以指定模型支持的任何数量。
现在启动 FIFO 线程,以使用 mplayer 在本地查看输出。
将 Inference is starting 消息发布到 AWS IoT 控制台。在接下来的几行中,您将编写推断循环的代码。
以下代码可让 AWS DeepLens 访问 mjpeg 流的最新帧。这是来自 AWS DeepLens 摄像头的输入流。 awscam.getLastFrame 将捕获来自该流的最后一个或最新一个帧,以剖析和执行推断。 raise Exception 允许函数在未能从流中获取帧时生成异常。
然后是图像的预处理。来自摄像头的输入帧不同于用于模型训练的输入维度。您之前已经定义了模型的输入参数。在这一步,调整来自摄像头的输入帧大小,使其与模型的输入维度相同。在本例中,您只需要降低帧的采样大小,使其与模型输入参数一致。根据您所训练的模型不同,您可能需要执行其他预处理步骤,例如图像正态化。
现在经过预处理的帧已经可以用于推断。之前的代码会将模型的结果以词典的形式输出,词典名为最后一层的名称。输出数据不会被解析为人类刻度的格式。如果您照原样使用此输出,您必须执行自己的解析算法。AWS DeepLens 提供了为所支持模型类型解析网络输出的方便接口。 以下方法将返回作为其键的 model_type 词典以及作为其值的第二个词典。第二个词典的 label 和 probability 键可让您检索非人类可读的标签以及相关概率。
您可以自定义该代码以仅显示输出中的前“n”个结果。在本例中,我们自定义该代码以显示前 5 个条目。条目按降序显示,概率最高的条目排在首位。
现在您获得了结果,将其发送到云。请注意结果的格式为 json 格式,因此云上的其他 Lambda 函数可能会订阅此 IoT 主题,并在它们检测到感兴趣的具体事件时执行操作。例如,在 re:Invent 研讨会上,我们在云上部署了一个将在每次检测到热狗时发送短信的 Lambda 函数。此外还应注意您在进入将网络所输出标签转换为人类可读标签的循环前所创建标签列表的使用方式。
现在消息是 json 格式的,通过 AWS IoT 将其发送到云。
现在数据已经在云中,对图像进行后处理以在 mplayer 中查看。在本例中,只需进行简单的后处理,使用 openCV向原始 400 万像素的图像添加标签。您可以根据自己的需求自定义此步骤。
完成后处理后,更新 global jpeg 变量即可使用 mplayer 查看结果。
此外也可添加一条代码,在发生错误时获取异常消息并将之发送到云。为此请使用如下代码。
现在运行函数并查看结果!
不要忘记保存并发布代码。如果忘记发布函数,您将无法在 AWS DeepLens 控制台查看推断 Lambda 函数。
恭喜您!您已经创建了一个 Lambda 函数,您可以使用进行 squeezenet 模型推断。并且您也使用了 Model Optimizer。
您可以在此处访问 squeezenet 模型。
如果您遇到任何问题或需要帮助,请参阅 AWS DeepLens 论坛。
作者简介
 Jyothi Nookula 是一名 AWS DeepLens 高级产品经理。她热爱创造客户满意的产品,在空余时间,她热爱绘画和主持自己作品的慈善义卖。
Jyothi Nookula 是一名 AWS DeepLens 高级产品经理。她热爱创造客户满意的产品,在空余时间,她热爱绘画和主持自己作品的慈善义卖。
 Eddie Calleja 是一名 AWS 深度学习软件开发工程师。他是 DeepLens 设备的开发人员之一。他以前是一名物理学家,他经常利用空闲时间思考如何运用人工智能技术来解决现代物理学问题。
Eddie Calleja 是一名 AWS 深度学习软件开发工程师。他是 DeepLens 设备的开发人员之一。他以前是一名物理学家,他经常利用空闲时间思考如何运用人工智能技术来解决现代物理学问题。