亚马逊AWS官方博客
使用 Amazon MSK Connect 与 Iceberg Kafka Connect 轻松构建数据实时入湖
 |
1. 介绍
数据湖作为大数据时代的关键基础设施,其建设和管理一直是业界关注的重点话题。在这个场景下,Apache Iceberg 凭借其出色的数据管理能力、跨存储引擎的兼容性、事务处理支持、性能优化手段以及与大数据生态的良好集成等优势,正成为数据湖建设中备受关注的技术方案。Iceberg 提供了表格式的数据管理,使得数据更加结构化和易于管理,同时支持复杂的数据类型和分区管理。此外,Iceberg 还可以兼容多种存储引擎,保证了数据湖的异构性和扩展性,并提供了事务处理、版本控制和回滚等功能,确保了数据的一致性和安全性。凭借这些出色的特性,越来越多的用户开始选择 Iceberg 正在构建高效、可靠数据湖的关键引擎。
另外,随着分析业务场景的发展,用户对数据分析的时效性要求也越来越高,希望业务数据在产生之后就立刻可以进入数据湖中被后续分析业务使用。在数据实时入湖场景,我们也探索了很多种方法,例如可以通过 AWS Glue/Amazon EMR Servlerss 来实现 CDC 数据的实时入湖,参考博文《使用 Serverless 架构快速构建基于 Iceberg 的事务型实时数据湖》。而 Tabular 在近期发布了 Iceberg kafka connect,通过它可以更加便捷的帮助用户实现数据实时入湖的流程,本文将介绍如何利用 Iceberg kafka connect ,通过 Amazon MSK Connect(托管 Kafka connect)来加速构建数据实时入湖的流程,简化从数据库到数据湖繁杂的同步过程。
2. 数据流程
 |
我们总结了两种实时摄入到 Iceberg 表的流程,基本能涵盖大部份的业务场景。一种是将数据库的事务性日志通过实时的流程写入到 Iceberg 表,这种类型的数据在摄入时需要考虑数据的变更,例如 Update、Delete 操作,因此需要通过 CDC 的技术将数据事务性的变更日志写入到 Kafka 中,下游的消费工具对这些变更记录进行还原处理,再写入到 Iceberg 表;另一种场景是将事件类日志实时摄入 Iceberg 表,这种场景的数据不会存在变更的情况,所以会以追加的方式写入 Iceberg 表。
在该方案中,我们将使用 Iceberg Kafka Connector 来实现 Sink 端的业务,而 Iceberg Kafka Connector 具有以下特性:
- 支持 Exactly-once
- 支持多表同步
- 支持行记录的变更(Update/Delete),Upsert 模式。
- 支持 Schema 的变更
- 通过 Iceberg 的列映射功能进行字段名称映射
3. 环境准备
使用 Amazon MSK Connect 来做数据的实时同步,我们需要先创建 Custom Plugin,这里会使用两个 Plugin,一个负责将 mysql binlog 数据同步到 Amazon MSK,使用的是 Debezium MySQL Connector(下载);另一个是负责将 Amazon MSK 中的数据同步到 Iceberg,这里需要使用 Iceberg Kafka Connect。(如果选择使用Amazon MSK Connect 的 2.7 版本,我们针对 Amazon MSK Connect 版本做了兼容性的修改可以从这里下载适配后的版本)。
创建配置 Custom Plugin
1. 将下载的 Plugin 上传到 S3 中。
2. 在 MSK 控制台的 Amazon MSK Connect 菜单下点击 Custom plugins,点击 Create custom plugin。
 |
4. 配置 MSK Connect
4.1 数据源接入
1. 创建一个 Topic 用于存储 MSK Connect 记录 offset。(注意,如果不设置,每次 Amazon MSK Connect 重新创建时都会自动创建一个新的 Topic,这样会导致重新全量采集一遍。 参考 Kafka connect all config)这个 Topic 建议遵循 kafka connect 的规范:25 或者 50 个分区、压缩(cleanup.policy=compact)、更多副本(3 倍或更多)。
2. 创建一个 Work configuration,点击 MSK Connect 下的 Worker configurations,点击 Create worker configuration,复制下面的配置,offset.storage.topic 设置为上一步骤创建的 Topic。
3. 在 Amazon MSK 控制台中,点击 Amazon MSK Connect 下的 connectors,点击 Create connector,在引导页面中,选择上一步骤创建的 Debezium MySQL Connector Plugin,填写 Connector 名称,选择同步目标的 MSK 集群。在配置中填入如下内容:
 |
需要注意的是,在配置中,使用了 Route 来实现将多表数据写入到同一个 Topic 中,在参数 transforms.Reroute.topic.regex 中配置通过正则表达式来过滤需要写入同一个 Topic 的表名。如下例,将会匹配表名中包含 <tablename-prifx>字符串的数据都被写入到同一个 Topic 中。
例如,将 transforms.Reroute.topic.replacement 指定为 $1all_records 之后,在 MSK 中创建的 Topic 名称为 <database.server.name>.all_records。
4. 点击创建之后,MSK Connect 会为我们创建同步任务。
4.2 数据同步(单表模式)
接下来,就可以创建 Iceberg 表的实时同步任务了,我们先创建一个单表的实时同步作业。
1. 在同步之前,需要在 Glue Data Catalog 中创建一个数据库,由于 Iceberg Connector 会将同步源的数据库名作为目标库名直接使用,因此创建的数据库名称也需要与源端保持一致。
2. 为 Connector 创建 work configuration:
3. 在 MSK 控制台中,点击 MSK Connect 下的 connectors,点击 Create connector,在引导页面中,选择之前已经创建的 Iceberg Kafka Connect Plugin,填写 Connector 名称,选择同步目标的 MSK 集群。在配置中填入如下内容:
主要配置说明:
| 参数名 | 参数说明 |
| iceberg.tables.cdc-field | 用于指定,包含 CDC 操作的字段名称,例如 I、U 或 D,默认为 none,对于通过 Debezium 输出的数据结构,这里配置为 _cdc.op |
| iceberg.tables.default-id-columns | 用于配置行记录可以用于更新/删除的主键字段。 |
4. 开启任务之后,就可以通过 Athena 来查询同步的数据结果。从同步到 Athena 中的表中,可以看到除了源表字段以外,另外增加了一个 _cdc 字段,用于存放 CDC 的元数据内容。
 |
5. Iceberg Kafka Connect 同时也支持对于数据的 Update/Delete,从 MySQL 源修改一条记录的值。如下例,将 ID 为 2,unit 字段从 44 修改为 1000
从 Athena 通过时间旅行的查询方式来查看 ID = 2 的这条记录变化情况。
 |
6. Schema 变更
通过 Iceberg Kafka Connect 也可以自适应 Schema,在源端发生的字段变更,也会同步到目标段。下面来测试 RDS 对一张表,以下是原有字段信息。
然后,我们添加一个字段 phone,并且写入一条新的数据。
在 Athena 观察这张表的变化,可以看到 phone 字段已经添加到最后一列,并且新的记录也已经写入进来。
 |
4.3 数据同步(多表模式)
大部份时候,我们还是会有多表同步,例如通过 CDC 采集工具将多张表的数据写入到一个 Topic 中,然后通过消费端将一个 Topic 中的数据写入到多张 Iceberg 表。在 4.1 章节中,配置的 MySQL 同步 Connector,通过 Route 的方式,将指定规则的表同步到了一个 Topic,下面我们来尝试如何将这一个 Topic 中的数据再分发到多张 Iceberg 表。
1. 同样需要创建一个新的 Topic 用于存储 MSK Connect 记录 offset(步骤参考2)。
2. 创建一个 Work configuration(步骤参考 2)。
3. 在 MSK 控制台中,再创建一个 Connector,使用以下配置。
在这个配置中,增加了两个参数:
iceberg.tables.route-field |
指定区分不同表的路由字段,对于通过 Debezium 解析的 CDC 数据指定为 _cdc.source |
iceberg.tables.dynamic-enabled |
如果没有设置 iceberg.tables 参数,这里必须指定为 true。 |
4. 点击创建之后,MSK Connect 会为我们创建同步任务。
5. 创建成功后,即可通过 Athena 查看创建出来的新表。
5. 其他小贴士
5.1 MSK Connect
1. 弹性扩缩
MSK Connect 托管的是 Kafka Connect(2.7.1/3.7.x),因此所有的同步任务是运行在 Worker 中,Worker 的工作进程是一个 JVM 进程,每个工作进程都会创建一组并行运行的任务,负责完成数据复制的工作。任务不存储状态,因此可以随时启动、停止或者重新启动,从而提供了一个具有弹性和可扩展的数据管道。MSK Connect 也是基于这个特性实现了自动扩缩。可以通过 group.id,来启动多个 worker, 并且 Amazon MSK Connect 可以自动恢复失败的任务以减少生产中断。(任务失败可能是由临时错误引起的,例如超出 Kafka 的 TCP 连接限制,以及当新 Worker 加入接收器连接器的消费者组时重新平衡任务)
 |
在 MSK Connect 资源配置中有两种模式:
(1)Provisioned :由用户指定固定的 Worker 数量以及 Worker 使用的资源大小。Connect 启动之后,如果想调整使用的资源(Worker 数量/Worker 使用的资源),需要通过手动调用 UpdateConnector API 的方式。
 |
(2)Autoscaled:在创建时指定 Worker 的最大值与最小值,以及每个 Worker 使用的资源,这样在 Connect 启动之后会根据 CPU 的利用率大小在设定的范围内动态的扩缩,这种方式的资源利用率也会更高。
 |
如下图,我们设置了每个 Woker 2 个 MCU,最小 Woker 数量为 1,最大为 4。在处理的数量增加时,CPU 利用率增长到了 90% 以上,在当 Woker 的数量和 Task 的数量会自动的扩展,直到最大值。
 |
 |
当然不是所有的场景,都需要自动扩缩,例如通过 Debezium CDC 采集 MySQL Binlog 数据时,为了保证数据的有序性,只会开启一个 Task 任务,这个时候配置再多的 Worker 也不会增加任务数量。
2. Offset
- 对于 MySQL CDC 任务,当我们想修改一个正在运行的 MSK Connect 作业配置时,需要删除它再重启,这样就需要将 MSK Connect 删除前消费/读取数据的 offset 记录下来,MSK Connect 默认会创建一个前缀名为 xxxx 的 topic,用于存放同步数据的 offset,如果在下次启动时,没有指定这个 topic,MSK Connect 会再创建一个新的 Topic 出来,因此如果要从上一次中断的位置读取数据,需要指定参数
offset.storage.topic=<topic-name>。当然,也可以提前创建这个记录 offset 的 topic,需要遵循它的规则:具有多个分区和压缩清理策略,以避免丢失数据,建议使用 25 个分区 3 个副本。注意:将
snapshot.mode设置为when_needed时,如果之前已经执行过快照,并且 binlog 位置信息(offset)仍然有效,连接器会从上次记录的位置继续读取 binlog。但是如果 binlog 位置信息无效(例如,因为 binlog 已被清理),连接器会执行一个新的快照,这样就可能出现数据被重复采集。
- 对于 Iceberg Connector,它会默认创建一个名为
control-iceberg的 Topic 用于记录 offset,当然我们也可以指定这个 topic 名称,只要设置参数iceberg.control.topic = <offset-topic>即可。
5.2 Iceberg Kafka Connector
1. 指定表同步
在 4.3 数据同步(多表模式)章节中,指定了 iceberg.tables.route-field =_cdc.source 和 iceberg.tables.dynamic-enabled=true,这两个参数设置可以将存放在同一个 topic 中的多张表写入到个字的 Iceberg 表中。我们希望只同步其中的指定的表,可以通过设置 iceberg.tables.dynamic-enabled = false,然后设置 iceberg.tables 参数来指定我们希望同步的表名。例如:
2. 性能
我们使用 sysbench 工具,向 mysql 数据库中写入 25 张表,每张表 2000 千万条数据,写入的同时,通过 MSK Connect 将数据实时的同步到 MSK 中。然后启动 Kafka Iceberg Connect,设置 Worker 数量最小 1 个,最大 8 个,每个 worker 2 个 MCU,测试每个 MCU 写入的峰值约 10000 条/秒。
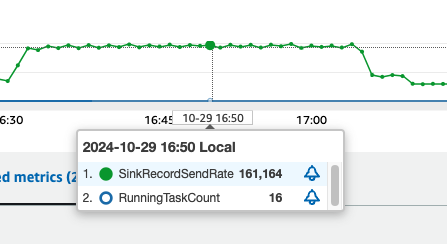 |
6. 总结
本文介绍了基于 Amazon MSK Connect 和 Iceberg Kafka Connect 的解决方案,通过 Iceberg Kafka Connect 技术,我们可以轻松实现从数据源到数据湖的实时、高效同步,为企业级大数据分析提供了一个低成本、高效率的数据同步范式。无论是电商交易、金融交易还是 IoT 设备日志,都可以通过这套方案实现秒级入湖,使分析型业务能够快速获取最新的业务数据。