亚马逊AWS官方博客
从误判到精准:游戏社区 AI 审核的工程化实践
引言
游戏社区作为典型的 UGC(用户生成内容)场景,用户遍布全球,涉及中、英、日、韩、俄、西班牙语、阿拉伯语、法语等多种语言。讨论氛围活跃,但其中不可避免会夹杂 辱骂、仇恨、色情、暴力、涉政 等违规言论。
平台需要在不伤害社区氛围的前提下,做到 及时、准确的内容审核。但传统规则引擎容易出现“误杀”或“漏判”,直接依赖大语言模型审核又存在 准确率不高、分类不稳定 的问题。
我们遇到的客户需求还有一些额外挑战:
- 审核对象是长文本(动辄上千字符);
- 无法通过向量检索或 RAG 切片,因为长文本拆分后上下文丢失,相关度很差;
- 模型需要一次性给出 判定结果(Pass/Reject),并在 Reject 时指定 10 种违规分类之一。
在这样的背景下,我们为一家游戏公司落地了一套 提示词工程 + ReAct 框架 + 工程化架构 的 AI 审核方案。最终整体准确率提升到了 81%。需要说明的是,对比基准是客户的人工审核数据,而人工标注过程存在“多人多日、缺乏复核”的情况,口径并不完全统一。因此,我们只能说模型的 81% 一致性大体上达到了人工审核的水平,具体效果还需结合更严格的标注体系进一步验证。
整体方案架构
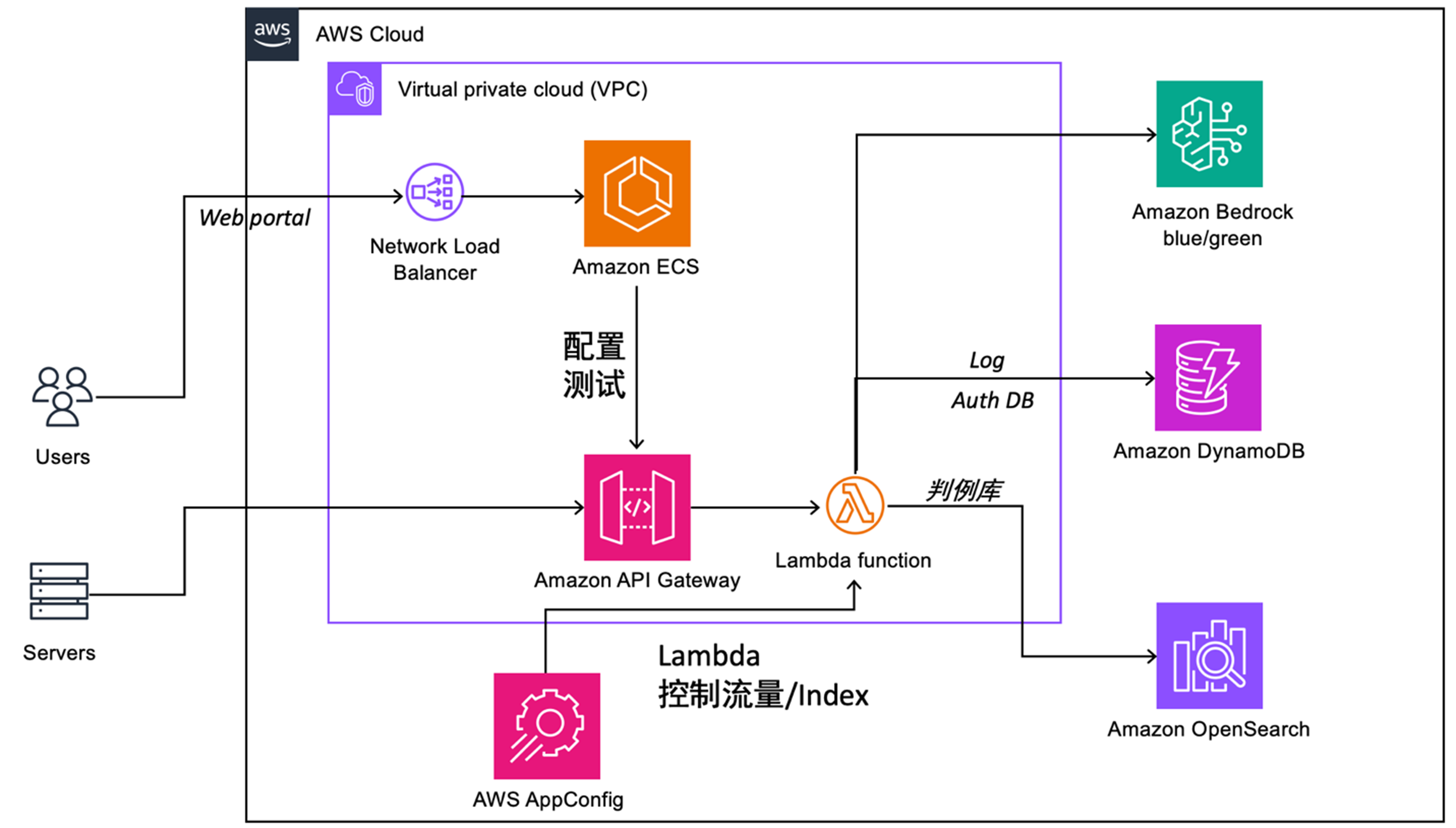 |
工程化落地能力
在文本审核项目中,提示词优化只是其中一步。真正支撑业务落地的,是一整套 可观测、可回滚、可扩展 的工程架构:
- 蓝绿部署:通过 Amazon Bedrock 的多版本部署机制,提示词优化和模型更新可以安全上线,支持灰度/回滚。
- 日志与判例库:所有审核请求和结果写入 DynamoDB / OpenSearch,用于后续的回溯分析与提示词再训练。
- 配置与流控:AWS AppConfig + 控制 Lambda,保证在高并发/大流量场景下系统稳定。
- 端到端可监控:从请求入口到最终存储都有日志链路,方便快速排查问题。
提示词冷启动阶段:提示词从 0 到 1
在没有任何“黄金提示词”的前提下,拿到可用的提示词方法有很多种,甚至可以直接让AI生成一个。
但我们这里采用冷启动的办法,先让模型把客户给的几千条样本过一遍。每跑一条,就拿它的结果和人工标注比对,把提示词里有问题的地方修掉。这样循环一轮,等于帮我们凑出了一个“能跑”的初始版本,后面再慢慢打磨。
我们的做法是:
- 让大模型逐条读取客户提供的数千条人工审核样本(每条都包含文本、判定结果以及违规分类)。
- 在阅读过程中,模型会尝试基于已有样本生成提示词。
- 每读取一条样本,就对提示词做一次微调,逐步修正不合理的部分。
- 完成一轮全量样本后,就得到一个 初始提示词,作为进一步优化的基线。
例如,最初我们生成的提示词大致如下:
在冷启动阶段,这个提示词的准确率并不算高,容易出现 灰色语境误判(例如把二次元梗误判成色情内容),或者 多语言覆盖不足(对阿拉伯语、西班牙语等的判定不稳定)。但它为后续优化奠定了基础。
ReAct 框架引入:让模型“先思考,再行动”
 |
冷启动阶段得到的提示词虽然能跑通流程,但在一些关键问题上仍然存在不足:
- 灰色语境:例如二次元梗、讽刺语气,容易被误判为违规。
- 多语言一致性:某些语言(如阿拉伯语、西班牙语)分类不稳定。
- 输出随机性:相同输入多次测试,结果可能不同。
为了解决这些问题,我们在提示词中引入了 ReAct(Reason + Act)框架。
ReAct 的核心思想是让大模型先进行显式的“推理”步骤,再做最终的“行动”输出。这样可以减少随机性,并提高可解释性。
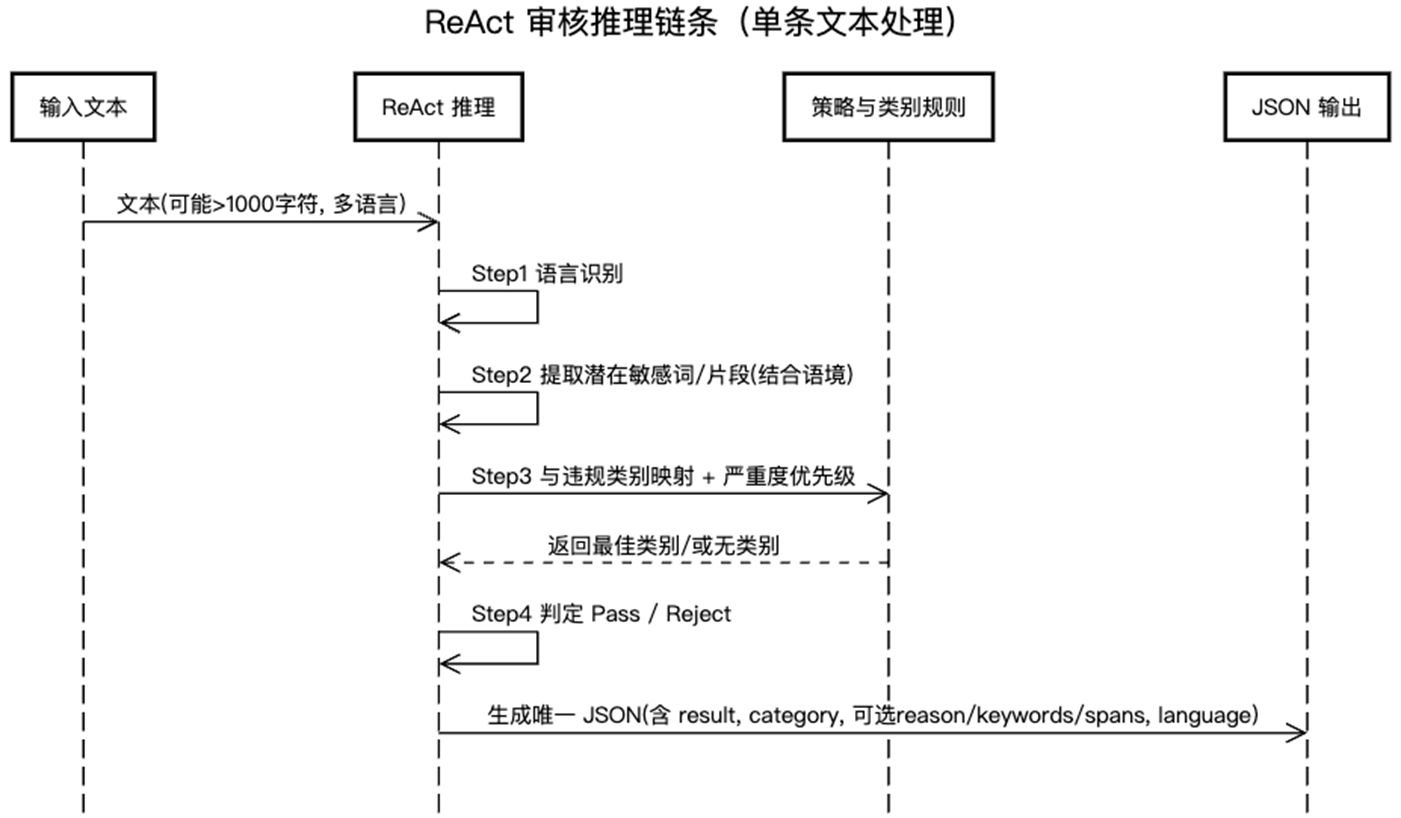
ReAct 框架在审核场景中的拆解
- Reasoning(思考):
- Step 1: 确定文本语言
- Step 2: 提取潜在违规关键词或短语
- Step 3: 将关键词与违规类别进行匹配
- Step 4: 根据上下文和类别,决定 Pass / Reject
- Action(行动):
- 输出最终 JSON 结果(判定 + 类别)。
示例提示词片段
下面是我们在 ReAct 框架下的一部分提示词(简化版):
这样设计后,准确率虽不高,容易把二次元梗当成色情,或对小语种判定不稳。但它给我们提供了一个起点。
ReAct 框架下的实现示例(Python 伪代码)
在工程落地中,我们通过 Agent 框架调用大模型,来执行上述 ReAct 推理:
在 ReAct 机制下,我们观察到模型的表现明显更加稳定:
- 对多语言输入的分类一致性增强;
- 对灰色语境(如“玩梗”)的误判显著减少;
- 审核理由透明,可以复盘和解释。
多轮循环优化:从 3 轮到 10+ 轮,我们如何选定 5 轮
在引入 ReAct 之后,我们对“每轮:全量跑样本 → 纠错 → 修提示词”的闭环进行了系统化实验,对比不同轮数的收益与成本:
- 3 轮:欠拟合
- 典型问题:仍然存在多语言一致性不足、灰色语境误判偏多。
- 现象:指标提升明显低于 5 轮,呈“上升未饱和”状态。
- 5 轮:效果-成本最优点
- 进入收益递减区间的起点,准确率与稳定性基本收敛。
- 与 10 轮相比,增益不明显,但计算/时间成本显著更低。
- 10 轮:与 5 轮接近
- 指标接近 5 轮,差异在统计误差范围内。
- 成本约为 5 轮的 2 倍(推理费用、时间占用、并发管理)。
- 10 轮以上:可能出现负面影响
- 过拟合于“特定审核员口径/特定样本簇”,提示词变窄。
- 对跨天、跨审核员、跨语种的泛化能力略有下降。
结论:在成本—收益的综合考量下,我们选择 5 轮 作为生产建议,并给出实践区间 5–8 轮(8 轮用于更严格的场景/关键上线前的稳健性校验)。
版本对比
| 版本 | 轮次 | 核心改动 | 效果观察 | 主要问题 | |
| 1 | v1 | 1 | 冷启动提示词,直接分类 | 基线 72% | 灰色语境误判、多语言不稳 |
| 2 | v2 | 3 | 加语言识别、关键词提取 | ~77–79% | 仍有欠拟合迹象 |
| 3 | v3 | 5 | ReAct 推理链条收敛、分类边界精炼 | 81% | 标注噪声成为主限因素 |
| 4 | v4 | 8 | 规则精修、输出一致性增强 | ~81%± | 提升接近噪声天花板 |
| 5 | v5 | 10+ | 更细粒度规则 | 收益不增反降 | 过拟合风险上升,提示词会过于具象化 |
Temperature 调参经验
在我们反复调提示词的过程中,发现 temperature 参数 对结果影响较大。
- 在调试和实验阶段
我们会把 temperature 开得比较高,大概在 8–1.0。这样模型会更“活跃”,能从不同角度去理解文本。比如:- 二次元梗、讽刺话语、跨语种甚至夹杂 emoji 的内容,高 temperature 下模型能给出更多解释;
- 这对我们来说很有帮助,可以暴露提示词里没考虑到的边角情况,方便我们快速改进。
- 在真正上线的时候
我们把 temperature 拉到 0–0.1。- 这样模型输出会尽量固定,不会同一条内容前后给出不一样的结果;
- 对审核业务来说,稳定和可解释比“有创造力”要重要得多。
所以我们的做法是:调试阶段高 temperature,生产环境低 temperature,既能探索问题,也能保证上线稳定。
实验结果(口径与噪声说明)
- 整体准确率:81%
- 正向召回准确率(合规判定):76%
- 负向召回准确率(违规判定):90%
评估口径与数据噪声:
- 基准为客户提供的人工审核数据;多人、分多日完成,未建立双盲复核,口径存在天然不一致。
- 因此 81% 的一致性,已经接近甚至可能超过多人人工的稳定水平。
- 在多语言与灰色语境(玩梗、反讽)上,ReAct 提示词显著降低了随机误判,并提升了跨语言一致性。
代表性案例(模拟真实数据)
| 文本(节选) | 人工标注 | 基线模型 | ReAct 提示词 | |
| 1 | “You are stupid, I hate you.” | 仇恨言论 | Pass ❌ | Reject ✅(Hate Speech) |
| 2 | “This waifu is so hot omg ?” | 合规(二次元语境) | Reject ❌ | Pass ✅ |
| 3 | “The devs are scammers, I hope they burn.” | 仇恨言论 | Reject ✅ | Reject ✅(Hate Speech) |
| 4 | “Hello” | Pass✅ |
工程实现要点
核心代码
1) 日志与可追溯性
- 目的:记录每个文件、每条样本的判定与指标,支撑问题回溯。
- 实践要点:
- 文件 + 控制台双通道日志;
- 关键信息结构化输出(accuracy、pass/reject、category 指标);
- 每轮/每版本生成独立 log 文件,便于对比。
2) 数据装载与多文件批处理
- Excel 列位处理:文本、标签列提取。
- 要点:
- 统一 label 口径:
Pass → 1 / Reject → 0; - 类别精度:对
Reject的类别进行单独统计,便于发现“弱类”。
- 统一 label 口径:
3) 大模型调用与推理参数(使用botocore调用Bedrock)
- 默认参数:
temperature=0.0、max_tokens=1000,确保可重复与稳定输出,max_tokens过大对效果影响有限; - 超时/重试:
botocore.config.Config中设置connect_timeout/read_timeout/retries;
4) 提示词模板与占位
- 通过
prompt_template.format(text=...)注入样本正文。 - 建议:模板内统一约束唯一 JSON 输出,便于解析;输出前置 ReAct 步骤(语言识别、关键词提取、类别匹配、最终判定)。
5) 并发验证与节流
- 多文件并行:
ThreadPoolExecutor按文件粒度并发; - 速率控制:
time.sleep(0.5)做基础节流,避免限流,注意您Amazon Web Service账号内Quota;
6) 评估与报表
- 输出四个 Sheet:
Results / Overall Metrics / File Metrics / Category Metrics+Prompt。 - 好处:
Category Metrics能快速定位薄弱类别;Prompt留存使版本可复现;- 结合日志快速回放异常样本。
评估口径:统一使用“与人工标注的一致性”为主指标(Overall/Pass/Reject accuracy + Category accuracy),并在文中显式声明标注噪声与“多审核员/多日/未复核”的现实约束。
经验总结(针对轮数选择与成本)
- 建议轮数:5–8 轮;5 轮用于大多数生产场景,8 轮用于上线前稳健性校验。
- 避免过拟合:10 轮以上容易对某些审核员口径或小样本簇过拟合,泛化变差。
- 成本优化:
- 串并结合:文件级并行 + 样本级节流;
- 固定
temperature,保证一致性,减少“返工轮”; - 对类别分层抽样做小集评估,优先修“弱类”,再全量回归。
- 在最终工程化实施时,可以将提示词放到system prompt中,同时开启cache,以降低成本。
- JSON 仅输出与解析健壮性
- 强调输出格式的规范化,降低对输出结果的不统一增加生产系统的不确定性。
- 部分提示词
 |
- 输出
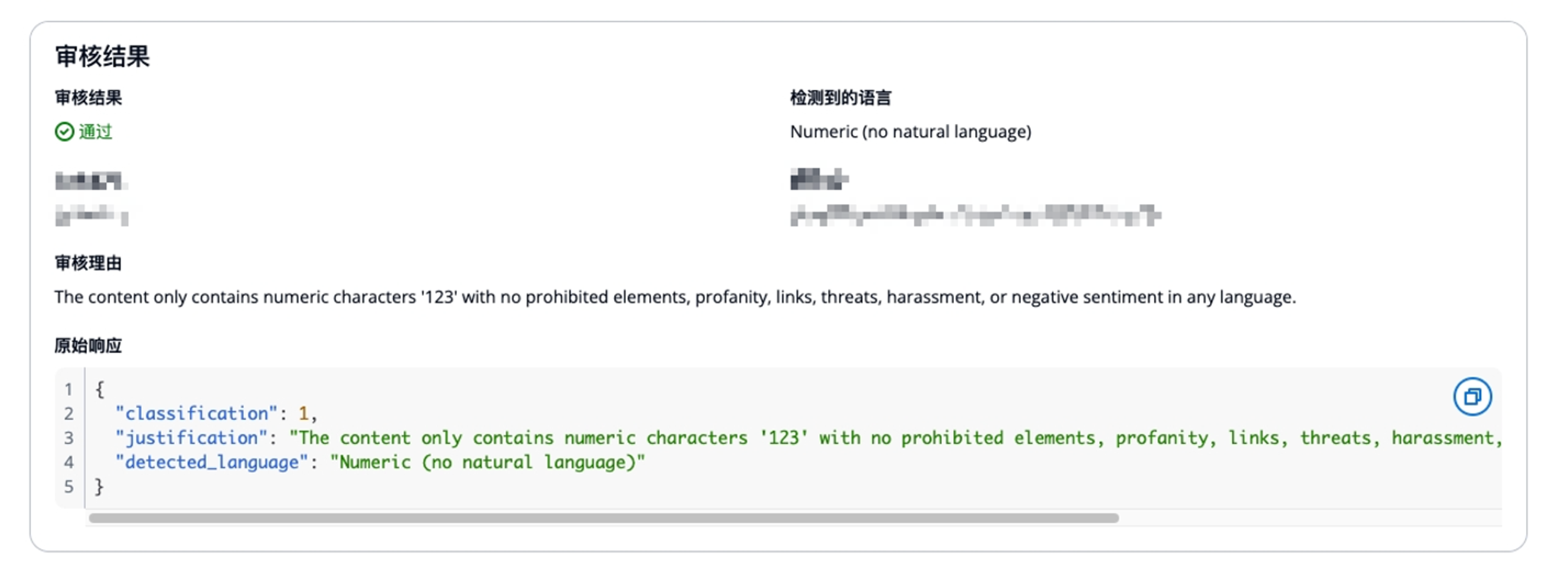 |
落地经验
在整个项目落地的过程中,我们积累了几条关键经验:
- 提示词必须贴合业务标注体系: 通用的“内容安全”提示词远远不够。只有结合客户的 10 类违规分类,并不断对照人工审核样本修正,才能让模型输出结果和业务口径保持一致。
- ReAct 框架带来了可解释性: 模型先进行“思考”,再给出“行动”,让每一步逻辑更加透明。我们可以展示模型的推理逻辑(语言识别、关键词提取、类别匹配),增强了审核结论的可信度。
- 数据质量是上限,提示词优化是下限: 我们使用的人工审核数据存在多人、分多日完成、缺乏复核等问题,导致标注结果本身带有噪声。在这种情况下,模型的准确率“天花板”就会受到影响。换句话说,提示词优化能逼近人工水平,但要进一步突破,还需要客户改善数据标注流程。
- 成本与效果的权衡: 我们在实验中验证了 3、5、10 轮迭代的差异,最终选择 5 轮作为最优点。同样地,temperature 参数在调优阶段设置高值,在上线阶段锁定低值,也是平衡创造性与稳定性的工程实践。
未来优化方向
- 自动化提示词优化
- 引入 AutoPrompt、RLHF 等方法,让提示词进化不再完全依赖人工试错。
- 在更多语言、更多语境下持续收敛。
- 更细粒度的分类与标签
- 客户的 10 类违规类别是第一层级。
- 后续可以扩展子类别(如“仇恨言论 → 针对性别 / 种族 / 职业”),满足更精细化的内容治理需求。
- 成本优化
- 会结合Bedrock的cache特性,增加对system prompt、user prompt的cache,在保证审核效果的情况下,尽可能优化成本。
- 成本详情请参阅Amazon Bedrock成本页面(https://aws.amazon.com/cn/bedrock/pricing/)与Claude模型成本页面(https://docs.claude.com/zh-CN/docs/about-claude/pricing)
结语
从最初的“误判频发”,到最终实现 81% 的整体准确率,我们通过 提示词工程 + ReAct 框架 + 工程化架构,帮助客户构建了一套 稳定、可观测、可扩展 的游戏社区审核系统。
这个过程的价值在于:
- 它不仅是一次模型调优尝试,而是一套 可工程化复制的方法论;
- 在 UGC 社区、社交平台、直播审核 等场景,都可以直接复用这套 提示词优化 + 架构闭环 的方案;
- 通过 日志、判例库、蓝绿部署 等工程实践,我们让审核系统具备了 一致性、可追溯性和快速迭代能力。
最终,这个项目让我们看到了 大语言模型 + 工程化落地 在内容审核领域的潜力:
- 提示词调优 让模型快速逼近甚至超越人工审核的一致性;
- 工程化架构 确保系统在 高并发、大规模多语言 审核场景下依旧稳定运行;
- 端到端闭环 使审核系统不仅能解决当下问题,还能通过数据回流不断自我进化。
*前述特定亚马逊云科技生成式人工智能相关的服务目前在亚马逊云科技海外区域可用。亚马逊云科技中国区域相关云服务由西云数据和光环新网运营,具体信息以中国区域官网为准。
本篇作者
AWS 架构师中心:云端创新的引领者探索 AWS 架构师中心,获取经实战验证的最佳实践与架构指南,助您高效构建安全、可靠的云上应用
|
 |
