亚马逊AWS官方博客
使用PROMETHEUS监控AMAZON TIMESTREAM FOR INFLUXDB:构建企业级时序数据库监控解决方案
概述
随着物联网、DevOps监控和实时分析需求的快速增长,时序数据库已成为现代应用架构中不可或缺的组件。Amazon Timestream for influxDB作为AMAZON提供的完全托管时序数据库服务,基于开源influxDB构建,为客户提供高性能、高可用的时序数据存储和分析能力。
influxDB 2.x 内置 Prometheus 监控支持,通过 /metrics 端点(默认8086端口)自动暴露关键性能指标,包括:
- 系统资源:CPU、内存、Goroutine 使用情况
- 查询性能:请求延迟、并发查询数、队列堆积
- 写入吞吐:写入速率、批处理效率
- 存储状态:分片数量、压缩操作、磁盘占用
这些标准化指标可直接被 Prometheus 采集,并集成到 Grafana 或 Amazon云监控服务(如 CloudWatch 和 Amazon Managed Prometheus)。开箱即用的设计让运维人员能够快速建立数据库性能监控体系,及时发现资源瓶颈和异常情况。
为了确保Amazon Timestream for InfluxDB实例的稳定运行和最佳性能,建立一套完善的监控体系至关重要。本文将手把手教您如何使用Prometheus和Grafana构建一个企业级的监控解决方案,实现对Amazon托管influxDB的全方位监控。
通过本文的实践,您将能够:
– 实时监控influxDB实例的健康状态和关键性能指标
– 建立智能告警机制,主动发现和预防潜在问题
– 通过丰富的可视化仪表板深入了解数据库运行状况
– 优化资源配置,提升系统性能和成本效益
监控架构设计
我们的监控解决方案采用以下架构设计:
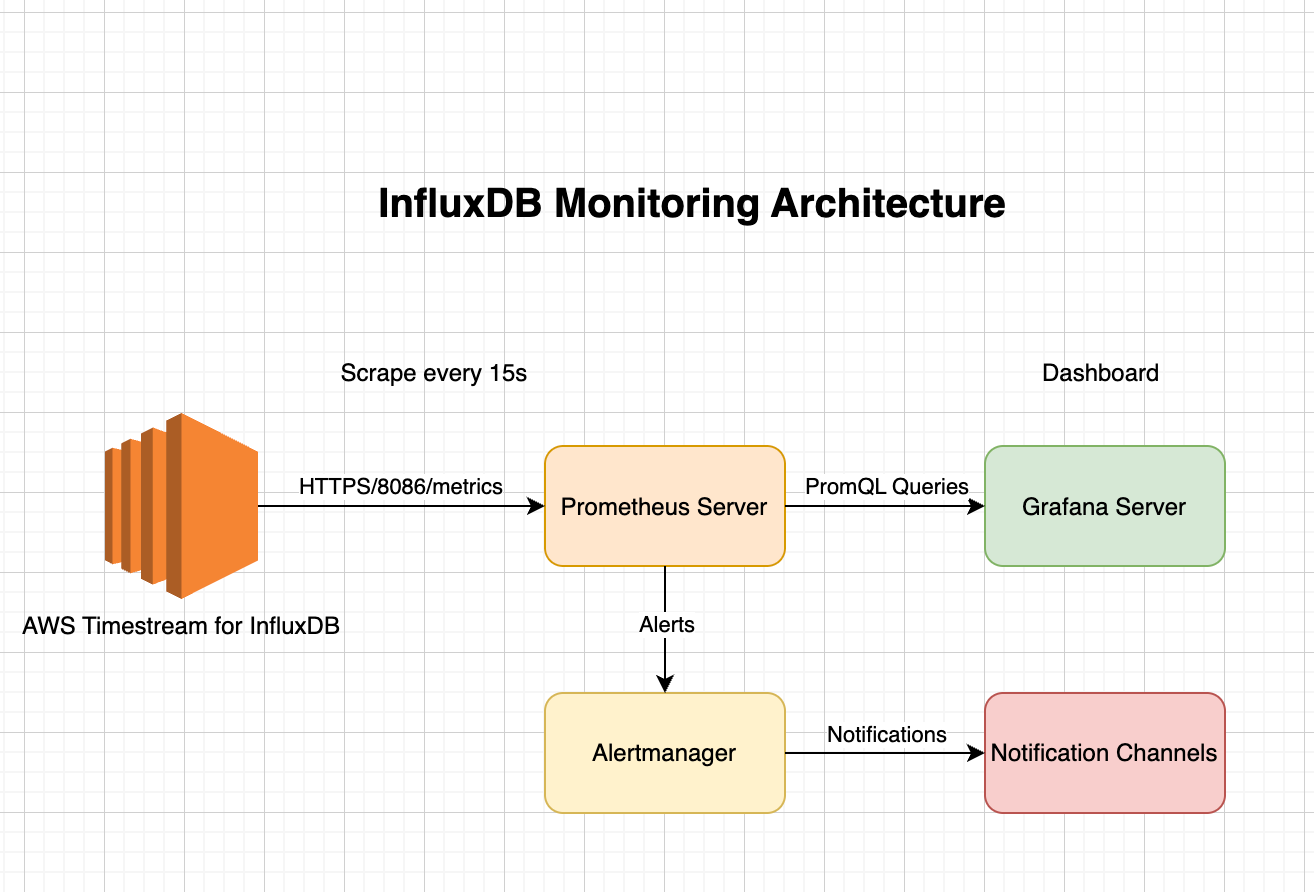 |
架构核心组件:
– Amazon Timestream for influxDB: 被监控的目标托管时序数据库
– Prometheus: 负责指标收集、存储和告警规则处理
– Grafana: 提供丰富的数据可视化和仪表板功能
环境准备和解决方案介绍
创建EC2监控实例
首先,我们需要创建一个EC2实例来部署Prometheus和Grafana:
访问EC2控制台(区域选择us-east-1):
https://us-east-1.console.aws.amazon.com/ec2/home?region=us-east-1#LaunchInstances:
实例配置建议:
– 操作系统: Amazon Linux
– 安全组: 确保与influxDB实例在同一安全组或配置适当的访问规则
– 存储: 至少20GB,用于存储监控数据
基础环境配置
登录EC2实例后,执行以下初始化配置:
bash
# 设置时区
TZ='Asia/Shanghai'; export TZ
# 更新系统包
sudo yum update -y
步骤1:部署和配置Prometheus
Prometheus安装
下载并安装Prometheus最新版本:
bash
# 下载Prometheus
wget https://github.com/prometheus/prometheus/releases/download/v3.3.1/prometheus-3.3.1.linux-amd64.tar.gz
# 解压并安装
tar -xvf prometheus-3.3.1.linux-amd64.tar.gz
sudo mv prometheus-3.3.1.linux-amd64 /usr/local/prometheus
cd /usr/local/prometheus
系统用户和权限配置
为安全考虑,创建专用的系统用户:
# 创建Prometheus用户
sudo useradd --no-create-home --shell /bin/false prometheus
# 设置目录权限
sudo chown -R prometheus:prometheus /usr/local/prometheus
系统服务配置
创建systemd服务文件实现服务管理:
sudo vi /etc/systemd/system/prometheus.service服务配置内容:
[Unit]
Description=Prometheus Monitoring
Wants=network-online.target
After=network-online.target
[Service]
User=prometheus
Group=prometheus
Type=simple
ExecStart=/usr/local/prometheus/prometheus --config.file=/usr/local/prometheus/prometheus.yml --storage.tsdb.path=/usr/local/prometheus/data
[Install]
WantedBy=multi-user.target
启动Prometheus服务:
bash
# 重新加载systemd配置
sudo systemctl daemon-reload
# 启动Prometheus
sudo systemctl start prometheus
# 设置开机自启动
sudo systemctl enable prometheus
# 验证服务状态
sudo systemctl status prometheus
配置influxDB监控目标
编辑Prometheus配置文件,添加Amazon Timestream for influxDB监控配置:
bash
sudo vi /usr/local/prometheus/prometheus.yml
在`scrape_configs`部分添加以下配置:
yaml
scrape_configs:
- job_name: 'Amazon-timestream-influxDB'
scheme: https # 使用HTTPS协议
scrape_interval: 15s # 每15秒抓取一次指标
metrics_path: '/metrics' # 指标端点路径
static_configs:
- targets: ['your-influxDB-endpoint.us-east-1.timestream-influxDB.amazonaws.com:8086']
重启Prometheus服务应用配置:
bash
sudo systemctl restart prometheus
sudo systemctl status prometheus
验证监控连接
通过Prometheus Web界面验证与influxDB的连接:
- 在浏览器中访问:`http://your-ec2-public-ip:9090`
- 在查询框中输入:`up{job=”Amazon-timestream-influxDB”}`
- 执行查询,返回值为1表示连接成功
步骤2:配置智能告警系统
创建告警规则
创建告警规则目录和配置文件:
bash
sudo mkdir -p /etc/prometheus/rules
sudo vi /etc/prometheus/rules/influxDB_alerts.yml
定义关键告警规则示例:
yaml
groups:
- name: influxDB_alerts
rules:
# influxDB instance down alert
- alert: influxDBDown
expr: up{job="Amazon-timestream-influxDB"} == 0
for: 1m
labels:
severity: critical
annotations:
summary: "influxDB instance unavailable"
description: "influxDB instance has been down for more than 1 minute, please check immediately."
# High memory usage alert
- alert: influxDBHighMemoryUsage
expr: go_memstats_alloc_bytes{job="Amazon-timestream-influxDB"}/go_memstats_sys_bytes{job="Amazon-timestream-influxDB"} > 0.8
for: 5m
labels:
severity: warning
annotations:
summary: "influxDB memory usage too high"
description: "influxDB memory usage exceeds 80%."
# Cache usage alert
- alert: influxDBHighCacheUsage
expr: sum(storage_cache_inuse_bytes{job="Amazon-timestream-influxDB"}) > 800000000
for: 5m
labels:
severity: warning
annotations:
summary: "influxDB cache usage approaching limit"
description: "influxDB cache usage approaching 1GB limit."
# HTTP API error rate alert
- alert: influxDBHighErrorRate
expr: rate(http_api_request_duration_seconds_count{job="Amazon-timestream-influxDB",response_code!~"2.."}[5m])/rate(http_api_request_duration_seconds_count{job="Amazon-timestream-influxDB"}[5m]) > 0.1
for: 3m
labels:
severity: warning
annotations:
summary: "influxDB API error rate too high"
description: "influxDB API error rate exceeds 10%, please check application and database status."
更新Prometheus配置以包含告警规则:
bash
sudo vi /usr/local/prometheus/prometheus.yml
在配置文件中添加:
yaml
rule_files:
- "/etc/prometheus/rules/influxDB_alerts.yml"
重启Prometheus服务:
bash
sudo systemctl restart prometheus
步骤3:部署Grafana可视化平台 Grafana安装配置 创建Grafana软件源:
bash
sudo vi /etc/yum.repos.d/grafana.repo
添加以下内容:
ini
[grafana]
name=grafana
baseurl=https://packages.grafana.com/oss/rpm
repo_gpgcheck=1
enabled=1
gpgcheck=1
gpgkey=https://packages.grafana.com/gpg.key
sslverify=1
sslcacert=/etc/pki/tls/certs/ca-bundle.crt
安装并启动Grafana:
bash
# 安装Grafana
sudo yum install -y grafana
# 启动Grafana服务
sudo service grafana-server start
sudo service grafana-server status
# 设置开机自启动
sudo /sbin/chkconfig --add grafana-server
配置Prometheus数据源
- 在浏览器中访问:`http://your-ec2-public-ip:3000`
- 使用默认凭据登录(admin/admin),首次登录需要修改密码
- 添加Prometheus数据源:
– 导航到:Configuration → Data sources
– 点击”Add data source”
– 选择”Prometheus”
– 配置连接信息:
– **Name**: Prometheus-influxDB
– **URL**: `http://< Prometheus Server Private address:9090>`
– 其他设置保持默认
– 点击”Save & Test”验证连接
步骤4:创建企业级监控仪表板
主要监控仪表板设计
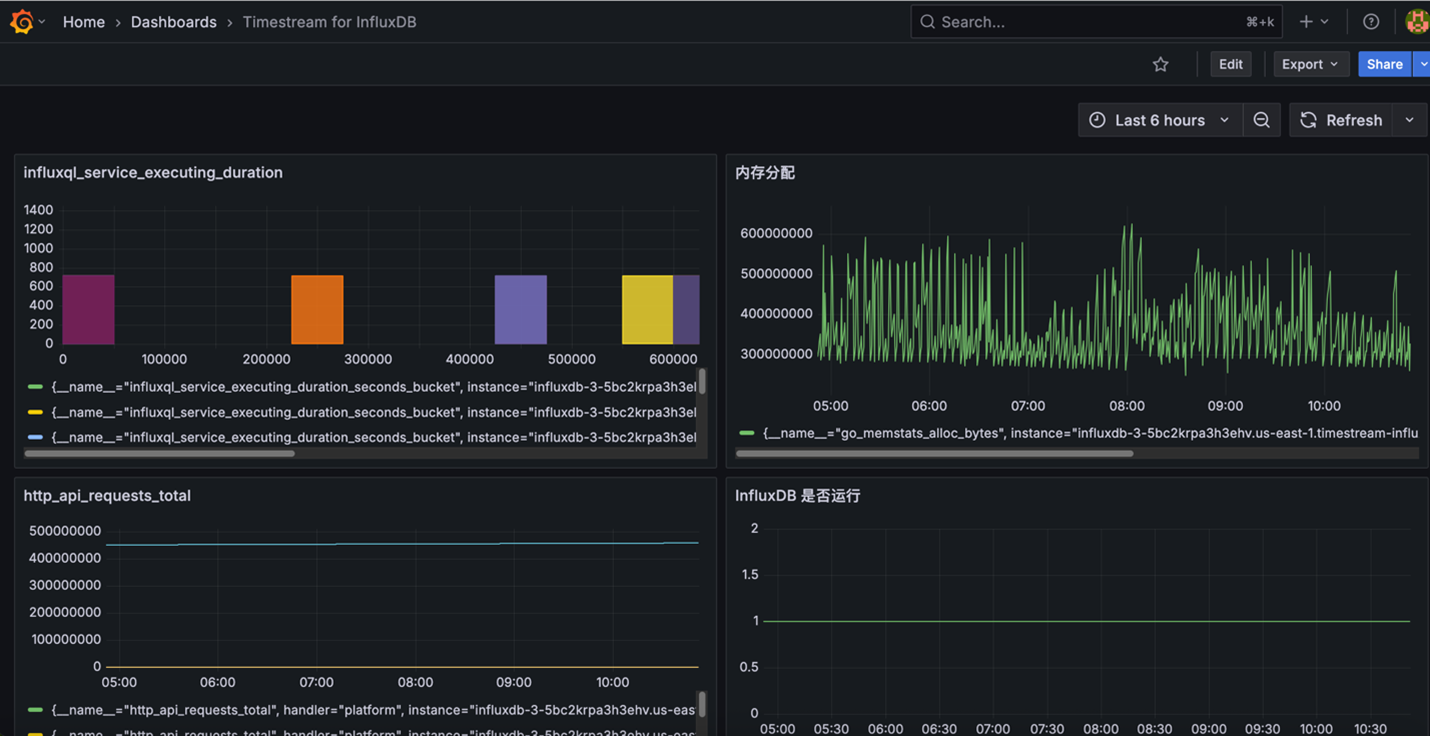
在Grafana中创建综合监控仪表板,包含以下关键面板:
- 系统概览面板
创建stat图表监控influxDB是否启动:
– **检查influxDB是否启动**:PromQL query 输入:up{job=”Amazon-timestream-influxDB”}
创建stat图表监控influxDB启动时间:
– **检查influxDB启动时间 输入id为influxDB instance id 可以从influxDB metrics输出中获取**:
PromQL query 输入 influxdb_uptime_seconds{id=”your influxDB instance id”}
- 性能监控面板
创建时间序列图表监控关键性能指标:
– **内存使用趋势**:PromQL query 输入:go_memstats_alloc_bytes{job=”Amazon-timestream-influxDB”}
– **存储引擎缓存使用情况**:PromQL query 输入:sum(storage_cache_inuse_bytes{job=”Amazon-timestream-influxDB”})
– **API请求速率**:PromQL query 输入:rate(http_api_requests_total{job=”Amazon-timestream-influxDB”}[5m])
– **查询执行时间**:PromQL query 输入:rate(influxql_service_executing_duration_seconds_sum{job=”Amazon-timestream-influxDB”}[5m])
监控Dashboard 如下图示例:
 |
步骤5:关键监控指标详解
核心性能指标体系
基于Amazon Timestream for influxDB的特性,我们重点关注以下指标类别:
| 类别 | 监控指标 | PromQL | 注释 |
| 系统健康状态指标 | influxDB实例运行状态 | up{job=”Amazon-timestream-influxDB”} | |
| influxDB运行时间 | influxdb_uptime_seconds{id=”your influxDB instance id”} | ||
| influxDB 远程连接总数 | influxdb_remotes_total{job=”Amazon-timestream-influxDB “} | ||
| 系统中的用户总数 | influxdb_users_total{job=”Amazon-timestream-influxDB “} | ||
| 缓存资源使用指标 | 当前内存分配量 | go_memstats_alloc_bytes{job=”Amazon-timestream-influxDB”} | |
| 存储缓存分配量 | sum(storage_cache_inuse_bytes{job=”Amazon-timestream-influxDB”}) | 默认上限1GB | |
| 堆内存分配量 | go_memstats_heap_alloc_bytes{job=”Amazon-timestream-influxDB”} | ||
| 垃圾回收统计 | go_gc_duration_seconds_sum{job=”Amazon-timestream-influxDB”} | ||
| HTTP API性能指标 | API请求总数 | http_api_requests_total{job=”Amazon-timestream-influxDB”} | |
| 按响应代码分组的请求统计 | sum(http_api_request_duration_seconds_count{job=”Amazon-timestream-influxDB”}) by (response_code) | ||
| API请求延迟 | http_api_request_duration_seconds_sum{job=”Amazon-timestream-influxDB”} | ||
| 查询执行性能指标 | 当前正在执行的查询数量 | qc_executing_active{job=”Amazon-timestream-influxDB”} | |
| 正在编译的查询数量 | qc_compiling_active{job=”Amazon-timestream-influxDB”} | ||
| 队列中的查询数量 | qc_queueing_active{job=”Amazon-timestream-influxDB”} | ||
| 存储和数据库指标 | Bucket数量 | influxdb_buckets_total{job=”aws-timestream-influxdb”} | |
| 每个Bucket时间序列数量 | storage_bucket_series_num{job=”Amazon-timestream-influxDB”} | ||
| BoltDB元数据库读 | boltdb_reads_total{job=”Amazon-timestream-influxDB”} | ||
| BoltDB元数据库写 | boltdb_writes_total{job=”Amazon-timestream-influxDB”} | ||
| 任务调度器指标 | 当前运行的任务数量 | task_executor_total_runs_active{job=”Amazon-timestream-influxDB”} | |
| 忙碌的工作线程数量 | task_executor_workers_busy{job=”Amazon-timestream-influxDB”} | ||
| 任务执行成功次数 | task_scheduler_total_execution_calls{job=”Amazon-timestream-influxDB”} | ||
| 任务执行失败次数 | task_scheduler_total_execute_failure{job=”Amazon-timestream-influxDB”} |
总结与展望
通过本文的详细指导,您已经成功部署了基于Amazon Timestream for influxDB的监控解决方案。该方案提供了四个关键功能:建立了涵盖系统指标、性能指标和资源利用率的完整监控体系;配置了基于阈值和异常检测的告警机制,实现故障的快速发现和响应;通过历史数据分析支持容量规划和性能调优;利用资源使用率监控数据进行成本分析和优化。这套监控架构为生产环境提供了可靠的可观测性基础设施,有助于提升系统稳定性和运维效率。
参考文献及相关链接
Amazon 托管influxDB中文在线文档:
InfluxDB OSS V2 管理指标在线文档:
InfluxDB Grafana 监控仪表板:
相关博客推荐
手把手教你玩转 Timestream For influxDB 实现时序数据存储和分析
采用无服务架构归档 Amazon Timestream for InfluxDB 数据到 Amazon S3
其他产品和服务推荐
S-BGP 是我们在由光环新网运营的亚马逊云科技中国(北京)区域和由西云数据运营的亚马逊云科技中国(宁夏)区域推出的一项成本优化型网络服务,旨在帮助我们的客户降低经过互联网传输数据出云(Data Transfer Out)的费用。 如果您想申请亚马逊云科技中国区域的 S-BGP 服务,请联系您的客户经理获取进一步帮助。