亚马逊AWS官方博客
如何宅在家里构建一个分图利器? – 利用 Amazon SageMaker 快速构建一个基于深度学习端到端的图像分类器
基于深度学习 (Deep Learning) 的图像分类的研究与应用已经进行的如火如荼,对大部分的业务场景来说,更是有着深刻的现实意义 – 基于图片的互联网分享社交应用,如何借助 Deep Learning 在第一时间对用户分享的图片进行实时监测,分类是一个比较典型的应用场景;又例如,电商运营可能希望对所有的产品照片按照产品属性进行自动化分类,减少人工分类的工作;另外,在工业生产线的良品率基于产品图片的自动筛检,以及辅助医疗领域对病理图片的分类等等场景都有着十分广泛的应用前景和实用价值。
当然,利用神经网络 (Neural Networks)构建的深度学习,因为其非线性的特性以及堆叠网络架构使其具备了数以百万计的模型参数在图片分类利用越来越成熟。但是,对于不具备深度学习研发能力的用户,从零构建这样的应用无疑是一种挑战。Amazon SageMaker 是一个完全托管的机器学习服务,它使一般的开发人员和数据科学家可以快速轻松地构建以任何规模的机器学习训练任务,并且提供基于API的端到端的模型部署方案以及 10 多类 Amazon 自带的典型算法,让用户无障碍地轻松构建各种典型的机器学习应用。
好了,我们今天给大家准备了一个有趣的任务 – 构建一个猫狗图片的分类器。
一. 所需材料
- AWS Account , 如果你还没有的话,请花两分钟时间注册一下。
- 一台电脑 – 操作系统不限。
- 一杯茶或者咖啡
二. 进一步细化我们的任务
我们希望对应的图片分类器可以达到90%以上的准确度来区分猫和狗的图片(图片不限但是建议以猫和狗作为图片的要素)。 另外,我们希望这个分类的系统可以直接接受API的调用,做到线上部署,并且,随着这个模型后续进一步的优化,新的模型可以用来优化线上分类的结果。
嗯!是的,上面也是典型的线上图片分类或者判断系统的基本实现要素。 要不,我们先看看两张图片如何?

Result: label – dog, probability – 0.9999990463256836

Result: label – cat, probability – 0.9972941279411316
很显然,如果可以真确的区分例如上图中的“喵星人”和“汪星人”,我们这个分类器的效果应该值得期待。
Amazon SageMaker 针对图片分类这种监督学习的场景,构建了一个自带的 Image Classification 算法。算法的实现是基于 ResNet 的典型深度神经网络结构进行封装,用户主需要按照格式准备好训练数据并配置对应的训练参数 (Hyper Parameter),就可以进行直接的模型训练。另外,从零开始训练模型,不仅意味着用户需要做图片数据的收集(训练数据的多少直接决定训练精度),而且需要一定的时间与训练成本。因此,Image Classification 算法本身提供了基于ImageNet 数据集 的训练模型,用户可以直接在此基础上利用 Transfer Learning 对模型进行微调 (fine-tune) 来达到较少的数据集而实现比较高的训练精度 (transfer learning)。
三. 操作步骤
首先,对训练的数据进行预处理。
为了使训练数据更加高效,Image Classification 支持 MXNet 的 RecordIO数据格式。同时,MXNet 社区也提供了一个很好的图片转换工具 im2rec.py 进行快速图像转换。具体的数据集与转换过程可以参考这里(感谢 yaricom 的贡献)。 需要指出的是,因为数据集是在美国,可以直接利用美国的 AWS EC2 计算实例下载到 EC2 本地,进行必要的 Record 格式转换之后,上传到美东地区 (Virginia Region) AWS的 S3 桶中。 在具体的格式转换中,您也可以直接利用这个EC2(启动 AWS Deep Learning AMI – AMI 中已经预装了MXNet 等 Deep Learning 框架和工具)主要利用的是 MXNet im2rec.py 工具生成 list 和 record 文件,并且按照validation 的数据和 training 数据的比例进行自动的数据拆分。 具体命令如下图,首先生成标签为 0 和 1 的 list 文件(Cat – 0, Dog – 1) 。之后,按照 48 个并发线程的方式进行 record 格式转换,并存在定义的目录内。

有了上面的数据,我们可以直接上传到 S3 数据桶中为 SageMaker 的训练做准备。下图马赛克部分是你的 S3 桶名

在准备好数据之后,我们可以进入 AWS 的控制台并找到 SageMaker 服务。
点击进入:

进入 SageMaker 的控制台之后,按照文档步骤直接启动一个 Notebook Instance. 顾名思义,Notebook Instance 是SageMaker 的 Notebook 的运行实例,上面预装有对应的 Jupyter Notebook 环境,并且集成了多种的机器学习环境 – Python, MXNet, Tensorflow 等等。

之后,我们在 Notebook Instance 启动完毕时,直接在 Notebook 上面点击对应的 “Open” 就可以启动 Jupyter Notebook 运行环境。

好了,最后就是 Notebook 的实际运行的代码部分
我们创建一个 conda-mxnet_p36 的文件。 具体的代码实例如下
- 利用 SageMaker 的 Image Classification 的容器来实现具体的训练算法 – 其中 bucket 是你在之前准备好的训练数据的 S3 桶。Role 用来指定你在启动 Notebook Instance 过程中所指定的 AWS Role,用于指定对应的权限。具体的配置过程可以参考 AWS 官方文档, 必要的 S3,CloudWatch Logs 以及 SageMaker 服务的权限都是需要的。
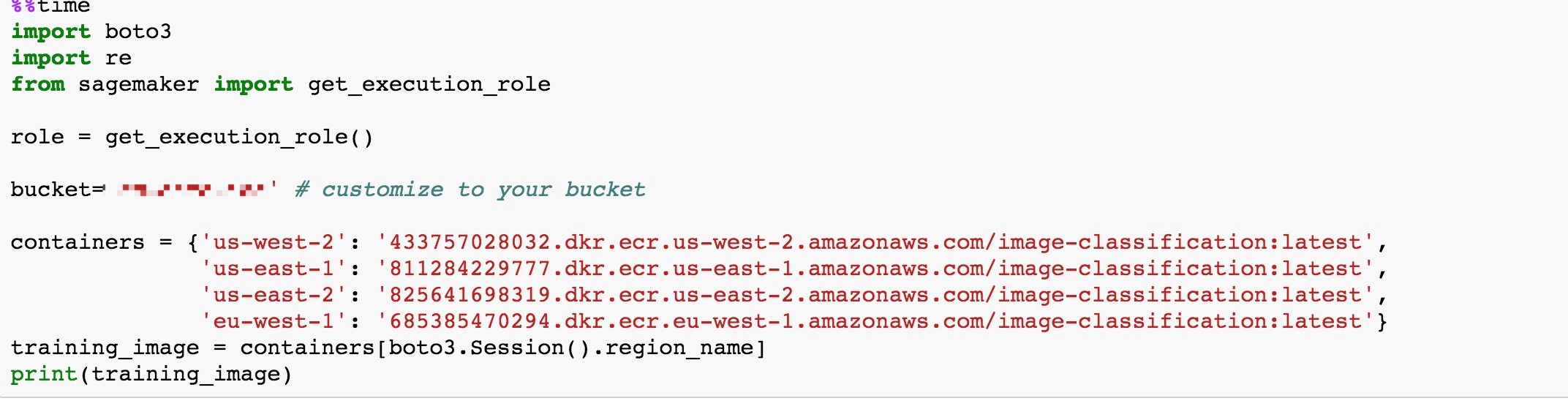
- 接着,我们配置对应的网络结构 (ResNet 的层数),训练图片的数据(图像转换中我们使用了32*32的像素,你可以选择更高像素来提高训练精度)像素和个数,以及分类的个数(我们这里只有猫和狗的2个分类),训练的 Hyber Parameter 例如 – batch 的大小,learning rate 以及非常重要的,我们需要指定使用 Image Classification 算法自带的模型进行 fine-tune。

- 之后,我们进行必要的 SageMaker API 的创建,构建对应的训练任务 – 其中有指定训练的输入与输出(主要是训练之后得到的模型数据),训练的计算实例配置(这里,我们使用的是 ml.p2.xlarge GPU 实例)

- 到这里,我们就可以直接调用 SageMaker API 来启动训练任务。需要注意的是,我们只是用一个简单的 API- sagemaker.create_training_job 并且根据第三步中的参数配置,就直接可以进行轻松的训练了! 中间没有任何的环境构建,部署,甚至是神经网络模型设计的过程。

整个训练的过程大概持续15分钟,具体的训练准确度可以参考 CloudWatch Logs,并且训练结束之后,我们在 S3 的 Output 目录中得到了训练好的模型数据,这样,我们可以直接进行线上的部署工作了。
- 下载模型数据,并且配置具体的部署设置。下面代码中我们使用了 ml.m4.xlarge 计算实例进行线上部署的应用。这个计算实例是用来做线上预测的,可以直接接受来自客户端的 Restful API 请求,预测服务支持自动伸缩 (Auto Scaling)。
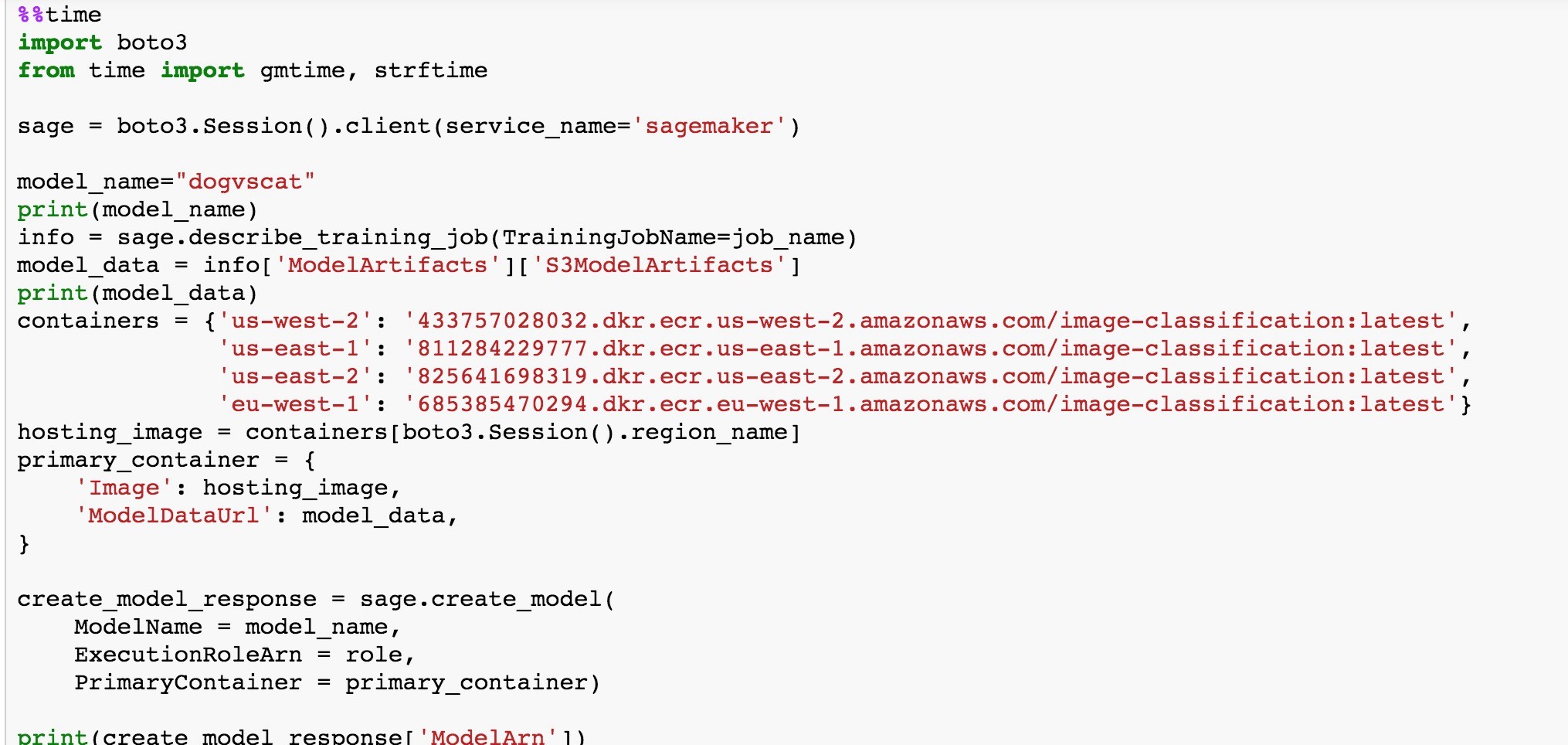

- 下面我们调用 SageMaker 的 API 实现线上预测服务 (Inference Service)的部署。是不是很方便?只要一个 API 实现了直接的模型部署。SageMaker 也支持基于权重的多模型部署,用于实际的生产环境测试。

- 好了,我们来测试一下吧

我在网上找了一个 puppy 的照片并且利用上的代码在 notebook 里面显示:

利用下面的代码直接给 SageMaker 发送判断的请求,准确率是 0.99 。效果很不错,建议多测试一下其他的图片

最后,因为上述的训练数据的准备,我们只是选择了32*32的图片输入,显然数据压缩率很高,并且有大部分的数据信息的丢失。如果你发现测试的效果不满意,建议增加图片输入的像素 (im2rec.py 的转换阶段)。
好了,开始你的深度学习之旅吧。
参考资料
- Jupyter Notebook 源代码
- AWS SageMaker 开发者文档
- ResNet for Image Recognition
- Transfer Learning
- MXNet im2rec.py tool
- 基于 MXNet 的猫狗分类器以及数据集
- SageMaker Tutorial