亚马逊AWS官方博客
如何用 Glue ETL 输出分区数据
简介
在使用Glue处理数据的时候,如果输入源是分区数据,通常都希望输出的数据也是分区数据,这样可以保持和源数据分区保持一致,以保障数据的完整性和一致性。但默认Glue的操作会把分区转换为一列处理。具体情形如下:
源数据目录按照年月日时分级为以下:
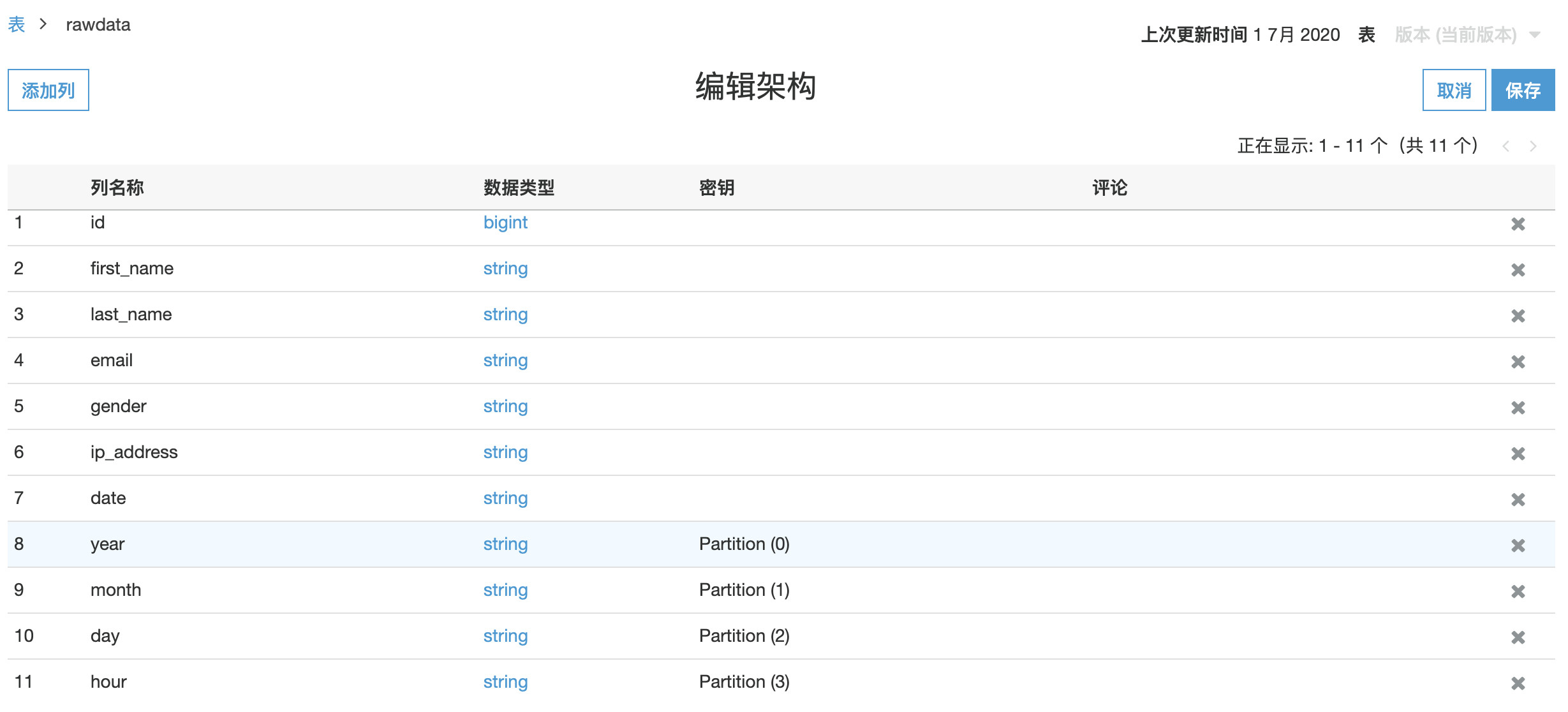
使用Glue爬虫,创建表,会自动识别分区,如下

将partition_0,partition_1,partition_2,partition_3,改为常规的分区year,month,day,hour,如下
此时如果我们对源数据进行行转列的操作,在字段mapping的阶段,会是这样的,Glue会把源数据的分区,转换为一列来处理,ETL后的数据会没有分级结构


为实现输出数据的分区,通常的做法有两种:
- 利用Glue自带的Dynamic Frame实现分区
- 转换为Spark的DataFrame实现
方法1:
直接在Glue的ETL代码里改,在output部分,加入paritionKeys,取之前定义的year,month,day,hour为值
datasink4 = glueContext.write_dynamic_frame.from_options(frame = dropnullfields3, connection_type = "s3", connection_options = {"path": "s3://glue-sample-data-us2/etl/","partitionKeys": ["year","month","day","hour"]}, format = "parquet", transformation_ctx = "datasink4")
运行ETL任务,结果如下,可以看到输出的数据已经根据源日志进行了分区.

方法2:
转换为SparkSql的DataFrame进行输出分区,具体代码如下:
datasink4 = dropnullfields3.toDF().write.partitionBy("year","month","day","hour").parquet("s3://glue-sample-data-us2/etl-sparksql/")
结果如下:
总结
在常规的大数据ETL场景中,都是需要做分区处理,以降低扫描数据量大小,利用Glue Serverless ETL功能实现分区数据输出,简单快捷,极大的降低了ETL的操作难度,Serverless又不会带来额外的运维成本,是数据工程师的利器