Spot实例是一种使用备用 EC2 容量的实例,以低于按需价格提供。由于Spot实例允许用户以极低的折扣请求未使用的 EC2 实例,这可能会显著降低用户的 Amazon EC2 成本。Spot实例的每小时价格称为 Spot 价格。每个可用区中的每种实例类型的 Spot 价格是由 Amazon EC2 设置的,并根据Spot实例的长期供求趋势逐步调整。只要容量可用,并且请求的每小时最高价超过 Spot 价格,Spot实例就会运行。如果 Amazon EC2 需要收回容量,或者 Spot 价格超过用户的请求的最高价,Amazon EC2 中断用户的Spot实例。
正常处理Spot实例中断的最佳方法是,设计应用程序以提供容错能力。为此,用户可以利用 EC2 实例rebalance recommendation和Spot实例interruption notification。其中,EC2 实例 rebalance recommendation 是一个新的信号,可在Spot实例处于较高的中断风险时通知用户。该信号可能比该两分钟的Spot实例interruption notification更早到达,从而让用户有机会主动管理Spot实例。
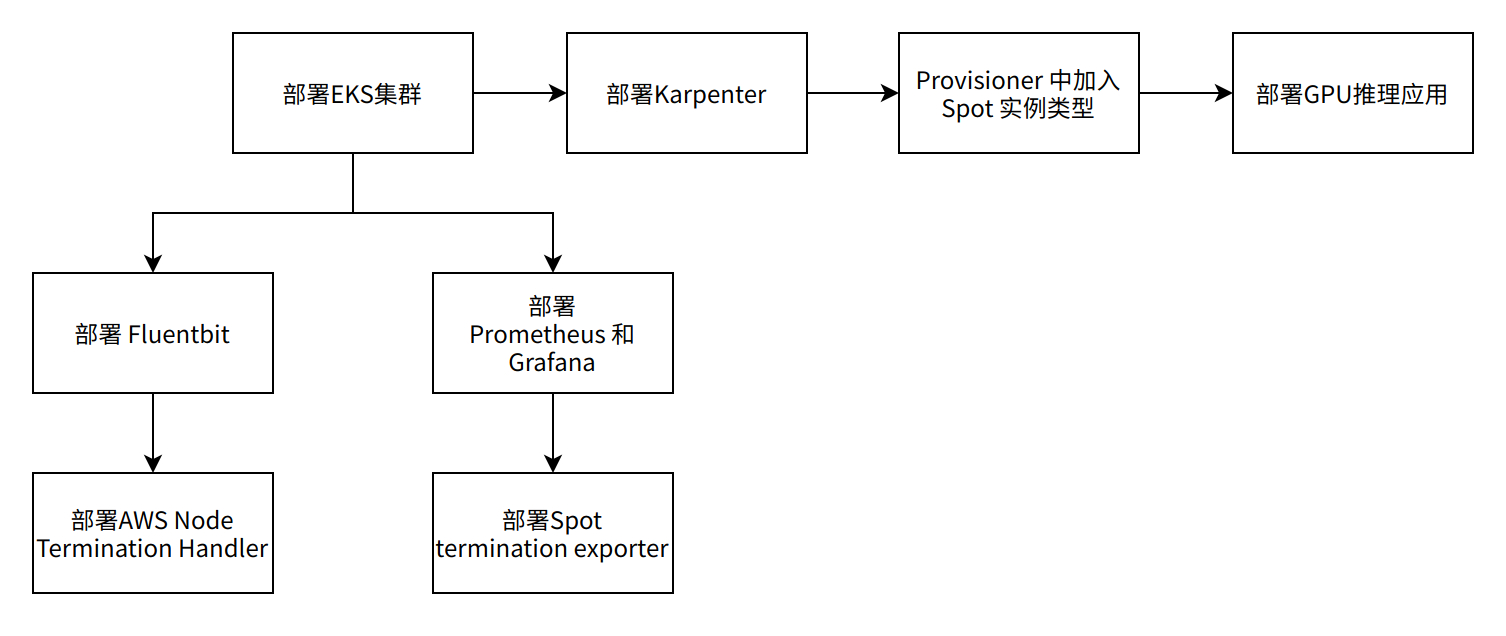
在上一篇博客中,我们设置了一个默认的On-demand Provisioner,并扩展了一个GPU推理应用程序。接下来我们修改启动实例类型为Spot和On-demand。
在使用了Spot实例后,会面临实例回收的情况(或者现货价格超过用户请求的最高价格)。在这种情况下,可以利用Spot实例重平衡的特性来处理中断。在EC2发出重平衡信号后,会通知用户Spot实例存在较高的中断风险。此信号使用户有机会在现有或新的Spot实例之间,主动地重新平衡工作负载,而不必等待两分钟的Spot实例中断通知。
为了捕获这些信号并优雅的处理中断,我们将部署一个名为AWS Node Termination Handler。Node Termination Handler以两种不同的模式运行:队列模式和实例元数据模式。我们将使用实例元数据模式。在这种模式下,Node Termination Handler实例元数据服务监视器将运行一个非常小的Pod (DaemonSet) ,在每台主机上监控IMDS路径(如/spot或/events),并对相应节点的drain或cordon作出反应。
由于Karpenter本身不对Spot的rebalance recommendation和interruption notification信号进行额外处理,因此需要安装 Node Termination Handler 配合使用。通过下面命令可以利用 helm 来安装 AWS Node Termination Handler:
可以让 node interruption handler 同时监控 rebalance recommendation和 interruption notification信号
可以让 node interruption handler 收到 rebalance recommendation信号的时候 drain 实例而不仅仅 cordon 实例(其中 cordon 是默认的操作)
我们可以配置 Fluentbit 将 AWS Node Termination Handler的日志发送到Cloudwatch Logs 中,以便后续测试过程中可以看到该Handler的具体处理细节,配置 Fluentbit 的详细步骤如下:
/aws/containerinsights/Cluster_Name/dataplane 的 CloudWatch log group 中看到 AWS Node Termination Handler 的日志
为了监控 spot 实例的的中断情况,我们部署一个第三方的插件 Spot termination exporter 以便在 Prometheus 和 Grafana dashboard 中查看到集群中 spot 实例的中断情况。
export ELB=$(kubectl get svc -n grafana grafana -o jsonpath='{.status.loadBalancer.ingress[0].hostname}')
echo "http://$ELB"
- 将上述 URL 复制粘贴到浏览器中即可出现登陆页面,登录时,使用用户名 admin 并通过运行以下命令获取密码:
kubectl get secret --namespace grafana grafana -o jsonpath="{.data.admin-password}" | base64 --decode ; echo
- 创建一个 dashboard,选择 Prometheus 作为数据源
接下来我们使用 helm 安装 Prometheus Spot termination exporter创建一个 dashboard,选择 Prometheus 作为数据源
helm install banzaicloud-stable/spot-termination-exporter --generate-name
等待 Spot termination exporter pods 创建完成,刷新 Grafana Prometheus dashboard, 查找 aws_instance_termination_imminent 指标即可监控 spot 实例的中断情况,更多关于 Spot termination exporter 的 Prometheus 指标,可以参考文档
2.5 部署示例应用与测试
参考之前的博客以部署示例的推理应用。增加 Pod 的数量为6个(kubectl scale deployment resnet –replicas 6),以便触发 Karpenter 进行扩容。通过如下命令查看 Karpenter Controller 日志:
kubectl logs -f -n karpenter -l app.kubernetes.io/name=karpenter -c controller

在 karpenter 的日志中发现在执行了Pod扩容后,karpenter会优先使用Spot,并且选择价格合适的实例类型。
另外,再来看看当Spot 实例容量不足时的情况。如下日志所示在尝试遍历所有可用区的 g4dn.8xlarge Spot 实例(为了验证效果,修改请求类型为g4dn.8xlarge)依然没有容量之后,karpenter会切换为启动 On-demand 实例。这也侧面印证了前面所说的,建议广泛的添加可选的实例类型以提高获得 Spot 实例的几率。

当有 Spot 实例需要被回收的时候,AWS node terminate handler 会接收到 rbr 信号并且开始 cordon&drain 相应的 Spot 实例。可以通过 fluent Bit 将 AWS node terminate handler 的日志推送到 cloudwatch log 上观察相应的日志
{ "log": "2022/04/12 07:03:13 INF Adding new event to the event store event={\"AutoScalingGroupName\":\"\",\"Description\":\"Rebalance recommendation received. Instance will be cordoned at 2022-04-12T07:03:12Z \\n\",\"EndTime\":\"0001-01-01T00:00:00Z\",\"EventID\":\"rebalance-recommendation-d487975a7f68b05f264cf06941208a5a76b1c2717ed99ee0f912122ee44406b2\",\"InProgress\":false,\"InstanceID\":\"\",\"IsManaged\":false,\"Kind\":\"REBALANCE_RECOMMENDATION\",\"NodeLabels\":null,\"NodeName\":\"ip-192-168-154-203.ap-southeast-1.compute.internal\",\"NodeProcessed\":false,\"Pods\":null,\"StartTime\":\"2022-04-12T07:03:12Z\",\"State\":\"\"}\n", "stream": "stderr", "az": "ap-southeast-1a", "ec2_instance_id":"i-00727e5dd268f477c" }
{ "log": "2022/04/12 07:03:14 INF Requesting instance drain event-id=rebalance-recommendation-d487975a7f68b05f264cf06941208a5a76b1c2717ed99ee0f912122ee44406b2 instance-id= kind=REBALANCE_RECOMMENDATION node-name=ip-192-168-154-203.ap-southeast-1.compute.internal\n", "stream": "stderr", "az": "ap-southeast-1a", "ec2_instance_id": "i-00727e5dd268f477c" }
{ "log": "2022/04/12 07:03:14 INF Pods on node node_name=ip-192-168-154-203.ap-southeast-1.compute.internal pod_names=[\"fluent-bit-nzwrh\",\"resnet-deployment-cdf59b549-h5qsk\",\"spot-termination-exporter-1642989993-spot-termination-expo9brtf\",\"aws-node-99txh\",\"aws-node-termination-handler-tg8kz\",\"kube-proxy-6965k\",\"prometheus-node-exporter-8dfqk\"]\n", "stream":"stderr", "az": "ap-southeast-1a", "ec2_instance_id": "i-00727e5dd268f477c" }
{ "log": "2022/04/12 07:03:14 INF Draining the node\n", "stream": "stderr", "az": "ap-southeast-1a", "ec2_instance_id": "i-00727e5dd268f477c" }
{ "log": "2022/04/12 07:03:14 ??? WARNING: ignoring DaemonSet-managed Pods: amazon-cloudwatch/fluent-bit-nzwrh, default/spot-termination-exporter-1642989993-spot-termination-expo9brtf, kube-system/aws-node-99txh, kube-system/aws-node-termination-handler-tg8kz, kube-system/kube-proxy-6965k, prometheus/prometheus-node-exporter-8dfqk\n", "stream": "stderr", "az":"ap-southeast-1a", "ec2_instance_id": "i-00727e5dd268f477c" }
{ "log": "2022/04/12 07:03:14 ??? evicting pod default/resnet-deployment-cdf59b549-h5qsk\n", "stream": "stderr", "az": "ap-southeast-1a", "ec2_instance_id": "i-00727e5dd268f477c" }
{ "log": "2022/04/12 07:03:40 INF event store statistics drainable-events=0 size=1\n", "stream":"stderr", "az": "ap-southeast-1a", "ec2_instance_id": "i-00727e5dd268f477c" }
{ "log": "2022/04/12 07:03:52 INF Node successfully cordoned and drained node_name=ip-192-168-154-203.ap-southeast-1.compute.internal reason=\"Rebalance recommendation received. Instance will be cordoned at 2022-04-12T07:03:12Z \\n\"\n", "stream": "stderr", "az": "ap-southeast-1a", "ec2_instance_id": "i-00727e5dd268f477c" }
更详细的信息可以参考:https://github.com/aws/aws-node-termination-handler
除此之外,也可以通过 Grafana dashboard 查看Prometheus Spot termination exporter 发布的 Prometheus 的指标来监控 Spot 实例被回收的情况

2.6 异常处理
异常情况1:On-demand实例不足
这时候karpenter 会一直尝试请求 On-demand实例,从karpenter的日志中可以看到如下信息:
2022-04-14T10:57:52.339Z INFO controller.provisioning Waiting for unschedulable pods {"commit": "7e79a67", "provisioner": "default"}
2022-04-14T10:57:58.340Z INFO controller.provisioning Batched 1 pods in 1.000378197s {"commit": "7e79a67", "provisioner": "default"}
2022-04-14T10:57:58.365Z INFO controller.provisioning Computed packing of 1 node(s) for 1 pod(s) with instance type option(s) [g4dn.xlarge] {"commit": "7e79a67", "provisioner": "default"}
2022-04-14T10:57:58.366Z DEBUG controller.provisioning Discovered caBundle, length 1066 {"commit": "7e79a67", "provisioner": "default"}
2022-04-14T10:57:59.643Z DEBUG controller.provisioning InsufficientInstanceCapacity for offering { instanceType: g4dn.xlarge, zone: ap-southeast-1b, capacityType: spot }, avoiding for 45s {"commit": "7e79a67", "provisioner": "default"}
2022-04-14T10:57:59.643Z ERROR controller.provisioning Could not launch node, launching instances, with fleet error(s), InsufficientInstanceCapacity: There is no Spot capacity available that matches your request.; UnfulfillableCapacity: Unable to fulfill capacity due to your request configuration. Please adjust your request and try again. {"commit": "7e79a67", "provisioner": "default"}
2022-04-14T10:57:59.643Z INFO controller.provisioning Waiting for unschedulable pods {"commit": "7e79a67", "provisioner": "default"}
2022-04-14T10:58:05.644Z INFO controller.provisioning Batched 1 pods in 1.000626178s {"commit": "7e79a67", "provisioner": "default"}
2022-04-14T10:58:05.683Z DEBUG controller.provisioning Discovered subnets: [subnet-09be8e66a41d0f87a (ap-southeast-1a) subnet-037edf176cf52dcbf (ap-southeast-1c) subnet-0b31edb266e73b5e6 (ap-southeast-1b)] {"commit": "7e79a67", "provisioner": "default"}
2022-04-14T10:58:05.688Z INFO controller.provisioning Computed packing of 1 node(s) for 1 pod(s) with instance type option(s) [g4dn.xlarge] {"commit": "7e79a67", "provisioner": "default"}
2022-04-14T10:58:05.722Z DEBUG controller.provisioning Discovered security groups: [sg-0a13d8c5b0b02f968 sg-0b7a098f22845cab3] {"commit": "7e79a67", "provisioner": "default"}
2022-04-14T10:58:05.724Z DEBUG controller.provisioning Discovered kubernetes version 1.21 {"commit": "7e79a67", "provisioner": "default"}
2022-04-14T10:58:05.776Z DEBUG controller.provisioning Discovered ami ami-026f68ad2a2513c76 for query /aws/service/eks/optimized-ami/1.21/amazon-linux-2-gpu/recommended/image_id {"commit": "7e79a67", "provisioner": "default"}
2022-04-14T10:58:05.776Z DEBUG controller.provisioning Discovered caBundle, length 1066 {"commit": "7e79a67", "provisioner": "default"}
2022-04-14T10:58:05.816Z DEBUG controller.provisioning Discovered launch template Karpenter-karpenter-gpu-2332944817898789368 {"commit": "7e79a67", "provisioner": "default"}
2022-04-14T10:58:06.093Z ERROR controller.provisioning Could not launch node, launching instances, with fleet error(s), UnfulfillableCapacity: Unable to fulfill capacity due to your request configuration. Please adjust your request and try again. {"commit": "7e79a67", "provisioner": "default"}
我们发现当 On-demand 实例没有容量的时候,会报如下错误
2022-04-14T10:58:06.093Z ERROR controller.provisioning Could not launch node, launching instances, with fleet error(s), UnfulfillableCapacity: Unable to fulfill capacity due to your request configuration. Please adjust your request and try again.
异常情况2:Spot 实例达到了账户的限制
从 karpenter的日志中可以看到诸如MaxSpotInstanceCountExceeded的报错信息,这时候需要请求提高Spot实例限制,详细参考文档[1]
2022-04-14T10:18:48.555Z INFO controller.provisioning Waiting for unschedulable pods {"commit": "7e79a67", "provisioner": "default"}
2022-04-14T10:18:54.557Z INFO controller.provisioning Batched 2 pods in 1.000516471s {"commit": "7e79a67", "provisioner": "default"}
2022-04-14T10:18:54.562Z INFO controller.provisioning Computed packing of 2 node(s) for 2 pod(s) with instance type option(s) [g4dn.xlarge g4dn.2xlarge g4dn.4xlarge] {"commit": "7e79a67", "provisioner": "default"}
2022-04-14T10:18:58.487Z ERROR controller.provisioning Could not launch node, launching instances, with fleet error(s), MaxSpotInstanceCountExceeded: Max spot instance count exceeded; UnfulfillableCapacity: Unable to fulfill capacity due to your request configuration. Please adjust your request and try again. {"commit": "7e79a67", "provisioner": "default"}
2022-04-14T10:18:58.487Z INFO controller.provisioning Waiting for unschedulable pods {"commit": "7e79a67", "provisioner": "default"}
2022-04-14T10:19:04.489Z INFO controller.provisioning Batched 2 pods in 1.000242566s {"commit": "7e79a67", "provisioner": "default"}
2022-04-14T10:19:04.553Z INFO controller.provisioning Computed packing of 2 node(s) for 2 pod(s) with instance type option(s) [g4dn.xlarge g4dn.2xlarge g4dn.4xlarge] {"commit": "7e79a67", "provisioner": "default"}
2022-04-14T10:19:10.700Z ERROR controller.provisioning Could not launch node, launching instances, with fleet error(s), MaxSpotInstanceCountExceeded: Max spot instance count exceeded; UnfulfillableCapacity: Unable to fulfill capacity due to your request configuration. Please adjust your request and try again. {"commit": "7e79a67", "provisioner": "default"}
2022-04-14T10:19:10.700Z INFO controller.provisioning Waiting for unschedulable pods {"commit": "7e79a67", "provisioner": "default"}
2022-04-14T10:19:16.701Z INFO controller.provisioning Batched 2 pods in 1.000765374s {"commit": "7e79a67", "provisioner": "default"}
2022-04-14T10:19:16.709Z INFO controller.provisioning Computed packing of 2 node(s) for 2 pod(s) with instance type option(s) [g4dn.xlarge g4dn.2xlarge g4dn.4xlarge] {"commit": "7e79a67", "provisioner": "default"}
2022-04-14T10:19:22.535Z ERROR controller.provisioning Could not launch node, launching instances, with fleet error(s), MaxSpotInstanceCountExceeded: Max spot instance count exceeded; InsufficientInstanceCapacity: We currently do not have sufficient g4dn.xlarge capacity in the Availability Zone you requested (ap-southeast-1a). Our system will be working on provisioning additional capacity. You can currently get g4dn.xlarge capacity by not specifying an Availability Zone in your request or choosing ap-southeast-1b, ap-southeast-1c.; UnfulfillableCapacity: Unable to fulfill capacity due to your request configuration. Please adjust your request and try again. {"commit": "7e79a67", "provisioner": "default"}
2022-04-14T10:19:22.535Z INFO controller.provisioning Waiting for unschedulable pods {"commit": "7e79a67", "provisioner": "default"}
2022-04-14T10:19:28.536Z INFO controller.provisioning Batched 2 pods in 1.000634995s {"commit": "7e79a67", "provisioner": "default"}
2022-04-14T10:19:28.542Z INFO controller.provisioning Computed packing of 2 node(s) for 2 pod(s) with instance type option(s) [g4dn.xlarge g4dn.2xlarge g4dn.4xlarge] {"commit": "7e79a67", "provisioner": "default"}
2022-04-14T10:19:33.182Z ERROR controller.provisioning Could not launch node, launching instances, with fleet error(s), MaxSpotInstanceCountExceeded: Max spot instance count exceeded; InsufficientInstanceCapacity: We currently do not have sufficient g4dn.xlarge capacity in the Availability Zone you requested (ap-southeast-1b). Our system will be working on provisioning additional capacity. You can currently get g4dn.xlarge capacity by not specifying an Availability Zone in your request or choosing ap-southeast-1a, ap-southeast-1c.; UnfulfillableCapacity: Unable to fulfill capacity due to your request configuration. Please adjust your request and try again. {"commit": "7e79a67", "provisioner": "default"}
3.小结
在这个博客里我们承接上一篇博客,继续以 Karpenter 0.6.3为例,介绍如何在Karpenter中进行Spot实例的管理。Spot实例允许用户以极低的折扣请求未使用的 EC2 实例,显著降低用户的 Amazon EC2 成本。Karpenter 默认使用 capacity optimized prioritized 策略, 调用EC2 Fleet API优先选择底层可用容量最多的实例类型。配合 AWS Node Termination Handler 处理 Spot 实例的中断,再部署 Prometheus 以及 Fluentbit 处理 Spot 实例中断的相关指标和日志。
本篇作者