亚马逊AWS官方博客
使用 Amazon Redshift 中的查询监控规则管理查询工作负载
本文主要介绍了如何利用Amazon Redshift的WLM(工作负载管理)功能,监控数据仓库的查询性能,从而优化队列优先级并保障关键任务的执行。本文还列出了三个常见场景,给出了简单的配置过程。
众所周知,数据仓库的工作负载由于周期性、潜在高开销的数据探索查询以及SQL开发人员不同的技能水平等会出现比较大的性能变化。
为了在面临高度变化的工作负载下仍然能使Redshift集群获得较高的性能,Amazon Redshift工作负载管理(WLM)使您能够灵活地管理任务优先级和资源使用情况。通过配置WLM,短时间,快速运行的查询不会停留在需要较长时间运行的查询之后的队列中。 但尽管如此,某些查询有时可能会陷入不相称的资源分配,并影响系统中的其他查询。 这种查询通常被称为流氓查询或失控查询。
虽然WLM提供了一种限制内存使用并将超时查询移动到其他队列的方法,但多重精细控制依然很需要。您现在可以使用query monitoring rules查询监视规则为查询创建资源使用规则,监视查询的资源使用情况,然后在查询违反规则时执行操作。
工作负载管理并发和查询监控规则
在Amazon Redshift环境中,单个集群最多可以同时连接500个连接。 吞吐量(Throughput)通常表示为每小时的查询量以最大化性能,但像MySQL这样的行数据库使用并发连接数进行衡量。 在Amazon Redshift中,工作负载管理(WLM)可以最大限度地提高吞吐量,而不太考虑并发性。 WLM有两个主要部分:队列和并发。 队列允许您在用户组或查询组级别分配内存。 并发或内存是如何进一步细分和分配内存到一个查询。
例如,假设您有一个并发度为10的队列(100%内存分配)。这意味着每个查询最多可以获得10%的内存。 如果大部分查询需要20%的内存,那么这些查询将交换到磁盘,导致较低的吞吐量。 但是,如果将并发度降低到5,则每个查询分配20%的内存,并且最终结果是更高的吞吐量和更快的SQL客户端响应时间。 当从行数据库切换到基于列的数据库的时候,常见的错误认知是认为更高的并发性将产生更好的性能。
现在你了解了并发性,这里有更多关于查询监控规则的细节。 您可以基于资源使用情况定义规则,如果查询违反了该规则,则会执行相应的操作。 可以使用十二种不同的资源使用指标,例如查询使用CPU,查询执行时间,扫描行数,返回行数,嵌套循环连接等。
每个规则包括最多三个条件,或谓词,和一个动作。谓词由一个指标,比较条件(=、<、>),和一个值组成。如果所有的谓词满足任何规则,该规则的行动被触发。可能的规则操作包括日志记录、跳过任务和中止任务。
这样就可以在导致严重问题前捕获流氓或失控查询。该规则触发一个动作来释放队列,从而提高吞吐量和响应速度。
例如,对于专用于短时运行查询的队列,您可能会创建一个规则来中止超过60秒的查询。 要跟踪设计不当的查询,您可能会有另一个规则记录包含嵌套循环的查询。 在Amazon Redshift控制台中有预定义的规则模板让您使用。
使用场景
使用查询监控规则来执行查询级别的操作,从简单地记录查询到中止查询,以下所有采取的操作都记录在STL_WLM_RULE_ACTION表中:
- 日志记录(log):记录信息并继续监视查询。
- 跳出(hog):终止查询,并重新启动下一个匹配队列。 如果没有其他匹配队列,查询将被取消。
- 中止(abort):中止违反规则的查询。
以下三个示例场景显示如何使用查询监视规则。
场景1:如何管理您临时查询队列中的未优化查询?
连接两个大表的失控查询可能返回十亿行或更多行。 您可以通过创建规则来中止返回超过十亿行的任何查询来保护您的临时队列。 在逻辑上如下所示:
IF return_row_count > 1B rows then ABORT.
在以下截图中,任何返回BI_USER组中超过十亿行的查询都将中止。

场景2:如何管理和控制未调优的CPU密集型查询?
偶尔引起CPU飙升的查询不一定有问题。 然而,持续的高CPU使用率可能会导致其他并发运行查询的延迟时间增加。 例如,在较长时间内使用高百分比CPU的未调优查询可能是由于不正确的嵌套连接引起的。
您可以通过创建规则来中止超过10分钟使用80%或更多CPU的任何查询来提高群集吞吐量和响应能力。 在逻辑上如下所示:
IF cpu_usage > 80% AND query_exec_time > 10m then ABORT
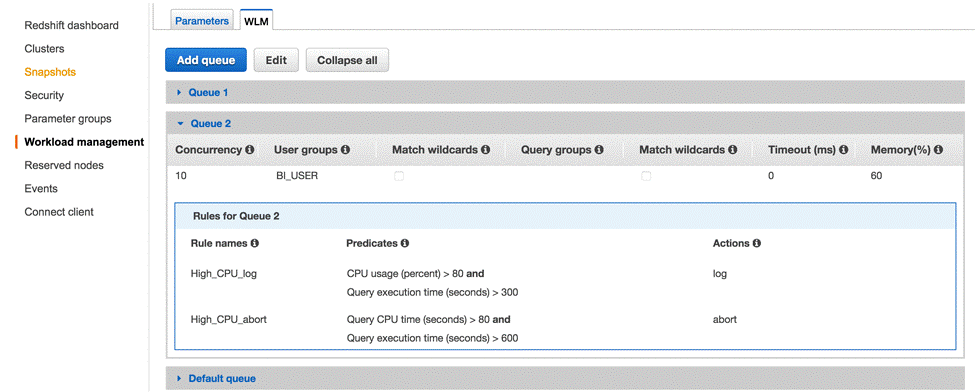
以下屏幕截图显示,任何使用超过80%CPU超过10分钟的查询都将中止。

您可以通过使用80%CPU记录查询超过5分钟进一步扩展此规则,并终止使用了80%CPU超过10分钟的查询。 在逻辑上如下所示:
IF cpu_usage > 80% AND query_exec_time > 5m then LOG and IF cpu_usage > 80% AND query_exec_time > 10m then ABORT
以下屏幕截图显示,系统将记录使用了80%CPU并运行5分钟以上的查询,并且中止使用了80%CPU并运行超过10分钟的查询。
场景3:如何监视和记录没有任何进展的查询?
例如,在混合工作负载环境中,ETL作业可能会将S3中的大量数据从大量的数据传输到Amazon Redshift中。 在数据摄取过程中,您可能会发现一个COPY命令被卡在队列中而没有进行任何进展。 这样的查询可能会增加数据吞吐延迟并影响业务SLA。
您可以通过创建跟踪和记录查询的规则来查找此类查询。 创建一个规则来查找具有低CPU利用率和过长执行时间的查询,例如,使用1%CPU记录查询超过10分钟的规则。 在逻辑上如下所示:
IF cpu_usage < 1% AND query_exec_time > 10m then LOG
以下屏幕截图显示,系统将记录使用1%CPU并运行10分钟以上的查询。

总结
Amazon Redshift是一个功能强大,全托管的数据仓库,可以在云计算框架中显著提升性能并降低成本。 但是,查询集群资源(流氓查询)可能会影响您的体验。
在这篇文章中,我们讨论了如何使用查询监视规则帮助过滤和中止不符合要求的任务。 这反过来也可以帮助您在支持混合工作负载时顺利地进行业务操作,以最大限度地提高集群性能和吞吐量。
如果您有任何问题或建议,请在下面留言。
关于作者

Gaurav Saxena是Amazon Redshift查询处理团队的软件工程师。 他负责Amazon Redshift工作负载管理和性能改进的几个方面。 在业余时间,他喜欢在他的PlayStation上玩游戏。

Suresh Akena是AWS专业服务的高级大数据/ IT转型架构师。 他与企业客户合作,为大型数据战略提供领导,包括迁移到AWS平台,大数据和分析项目,并帮助他们在使用AWS时优化和改进数据驱动应用的上市时间。 在业余时间,他喜欢和他8岁和3岁的女儿一起玩,看电影。
译者:

屈铭,AWS中国专业服务团队大数据咨询顾问
曾供职于亚马逊电商和澳大利亚智能交通研究机构,拥有多年电商平台和智慧供应链的数据分析经验。现任职于AWS中国专业服务团队,主要为客户提供云上大数据平台设计,数据仓库解决方案和优化,数据建模等咨询服务。