1.概述
目前,单一、通用的数据处理引擎已经不能满足客户不断变化的业务需求,因此,为了构建现代化的、为特定目的打造的数据架构,越来越多的客户将Snowflake、Iceberg等解决方案与亚马逊云科技的服务体系相结合,以实现无缝的数据互操作性和开放且高效的数据湖平台。在管理这一生态系统中,Amazon Glue扮演着统一的控制平面角色。用户可以通过Crawler、ETL jobs或 API,轻松地在Glue Data Catalog中注册与治理Iceberg表的元数据。
当这些表投入使用后,特别是流式或频繁小批量写入的场景,数据湖中的Iceberg表会产生大量的小文件。在处理这些小文件时,查询引擎(如Amazon Athena、Spark等)需要读取成千上万个文件的元数据并打开它们,带来巨大的I/O开销,进而导致查询性能严重下降。所以,优化这部分性能至关重要。Amazon Glue的合并(Compaction)功能就成为了关键。借助合并功能,用户可以方便地实现自动优化存储、提升查询速度,通过将小文件合并为优化后的大文件,有效减少了查询引擎所需扫描的数据量,从而直接降低成本,并提高表的读取性能。Amazon Glue提供了多种合并策略,其中Binpack为默认合并策略,实现将小文件合并为大文件以优化表性能。
2023年11月,亚马逊云科技国际区域发布了Amazon Glue的合并功能更新,但目前该功能在中国区域还未正式上线。而随着Snowflake在2024年9月发布中国区域版本上线,越来越多中国区域客户开始使用Snowflake和Iceberg表构建其数据湖平台,Amazon Glue的合并优化功能也随之被更多客户所需要。本篇博客旨在提供一个解决方案,以实现Amazon Glue的Iceberg表合并相同的功能,并利用Amazon Cloudformation的模板功能,提供方便快捷的一键式部署方案。
2.解决方案概述
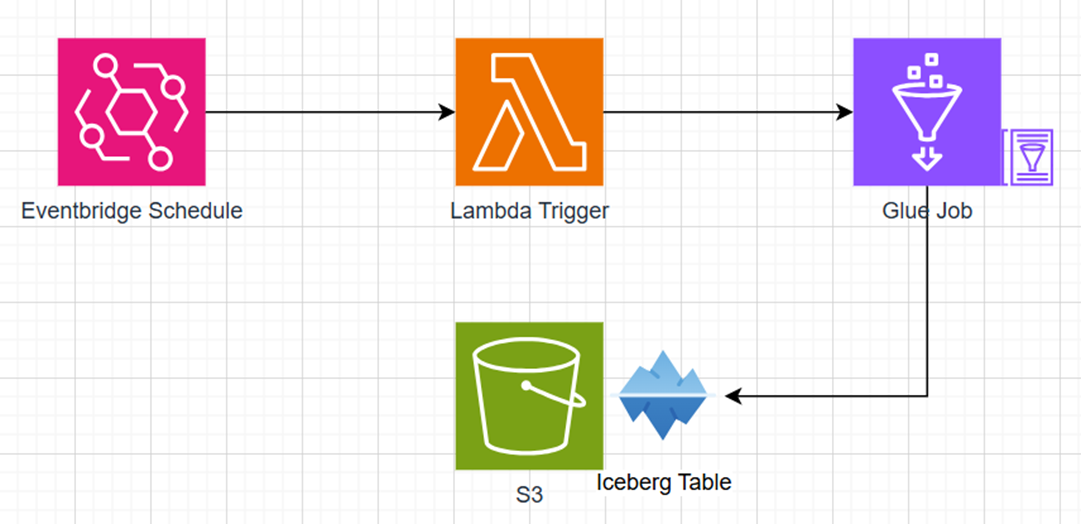
该解决方案旨在实现Amazon Glue合并(Compaction)功能(Binpack)。
Pic 1: Compaction优化器示意图
3.方案部署
3.1.方案部署
该方案中需要创建3个文件:分别为:
- iceberg-compaction-template-minimal.yaml:该方案的Cloudformation模板文件。示例文件请参照本文1章节。
- deploy-minimal.sh:该方案的部署脚本,在脚本中会使用Amazon cloudformation deploy命令进行自动化资源创建。需要执行chmod +x deploy-minimal.sh命令以添加脚本执行权限后,执行./deploy-minimal.sh命令以执行脚本。脚本执行成功后,会输出S3存储桶的名称。需要将Glue脚本上传到这个桶的scripts/目录下,例如:aws s3 cp iceberg_compaction.py s3://<WarehouseBucketName>/scripts/。示例文件请参照本文2章节。
- py:该python脚本为本解决方案整个流程的核心,来执行实际的合并逻辑。它接收Glue Job传入的参数(数据库和表名),然后调用Spark SQL中专门为Iceberg设计的rewrite_data_files存储过程来执行文件合并。示例文件请参照本文4.3章节。
3.2.方案执行结果
下面是执行deploy-minimal.sh后的结果:
Pic 2: deploy-minimal.sh部署成功后输出结果
3.3.方案测试
为了测试Compaction功能,首先需要模拟一个“包含大量小文件问题”的场景。我们将创建一个临时的 Glue Job 来生成一个包含大量小文件的 Iceberg 表,然后对该方案进行执行测试,最终达到小文件通过该方案提供的Compaction功能合并为一个大文件。
1),创建测试数据
首先需要确保您已经成功部署了上面提到的CloudFormation堆栈,即使用之前提供的 deploy-minimal.sh和iceberg-compaction-template-minimal.yaml成功创建了CloudFormation堆栈,如在宁夏区域部署了“my-iceberg-compaction-stack”。从CloudFormation堆栈的输出中,记录好WarehouseBucketName的值,如“my-iceberg-app-warehouse-<accountID>-northwest-1”。
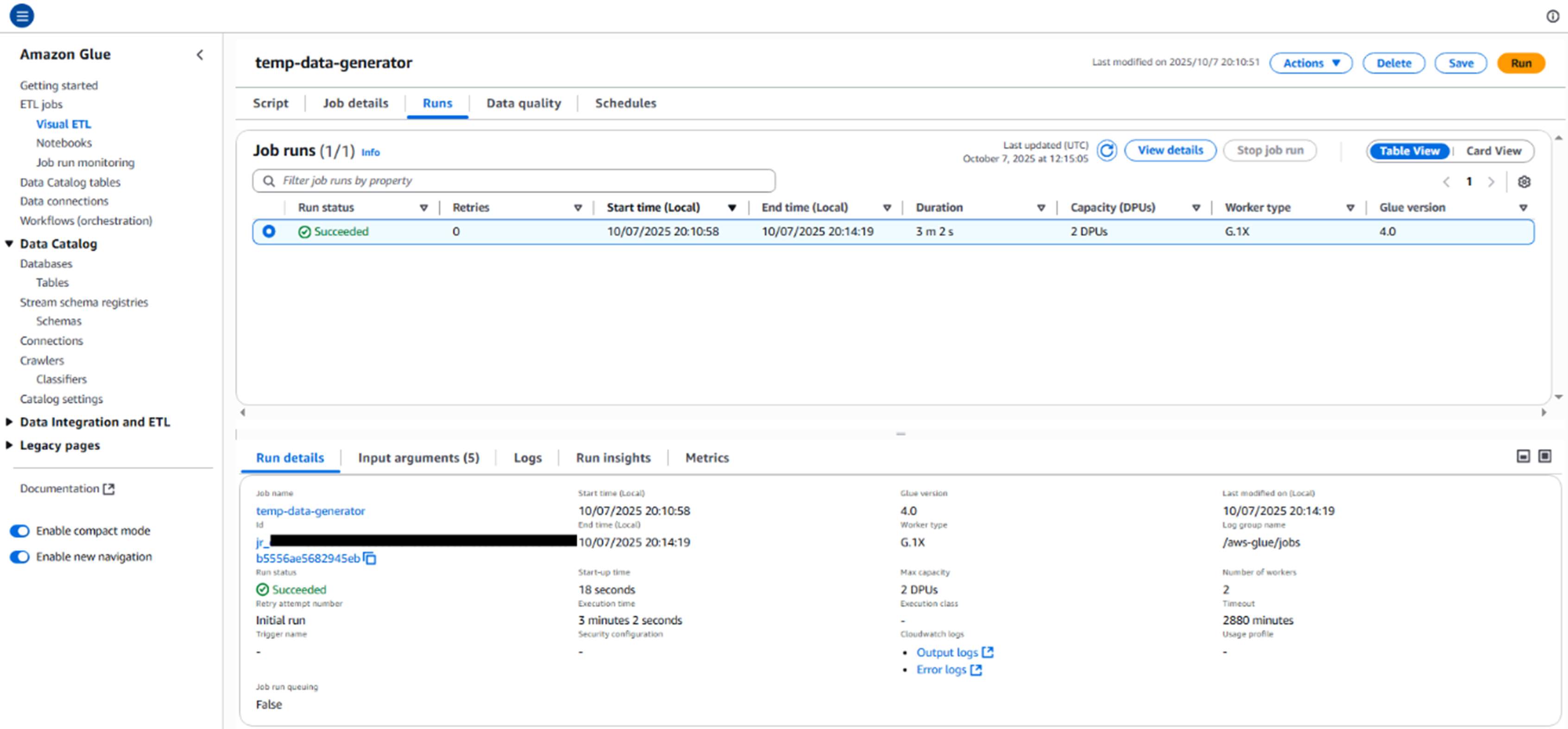
之后便可以开始创建测试数据,来模拟小文件问题的场景了。创建一个名为create_small_files.py的文件,作为数据生成的Glue脚本。示例文件请参照本文4.4章节。这个脚本将创建一个 Iceberg 表,并循环写入100次(您可以通过修改脚本以自定义循环次数),每次只写一条数据,从而在S3桶中模拟生成100个小文件。将该脚本上传到s3桶的scripts目录下。然后使用如下Amazon CLI命令创建Glue job,并替换您的角色 ARN 和 S3 桶名。执行完成后,该命令会启动一个名为temp-data-generator的Glue Job,用来生成大量小文件。
aws glue create-job \
--name "temp-data-generator" \
--role "<Your-Glue-Job-Role-Arn>" \
--command '{ "Name": "glueetl", "ScriptLocation": "s3://<Your-Warehouse-Bucket-Name>/scripts/create_small_files.py", "PythonVersion": "3" }' \
--glue-version "4.0" \
--worker-type "G.1X" \
--number-of-workers 2 \
--default-arguments '{
"--datalake-formats": "iceberg",
"--conf": "spark.sql.catalog.glue_catalog=org.apache.iceberg.spark.SparkCatalog --conf spark.sql.catalog.glue_catalog.warehouse=s3://<Your-Warehouse-Bucket-Name>/warehouse/ --conf spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions --conf spark.sql.catalog.glue_catalog.catalog-impl=org.apache.iceberg.aws.glue.GlueCatalog --conf spark.sql.catalog.glue_catalog.io-impl=org.apache.iceberg.aws.s3.S3FileIO",
"--database_name": "sales_db",
"--table_name": "transactions",
"--s3_warehouse_path": "s3://<Your-Warehouse-Bucket-Name>/warehouse/"
}'
请注意,在–conf中需要添加catalog-impl和io-impl两个参数,告诉Iceberg在执行Glue job时不要连接默认的Hive Metastore服务来管理表的元数据,而使用Amazon Glue Data Catalog作为元数据存储。即catalog-impl参数指定元数据目录为Amazon Glue Data Catalog,io-impl指定读写数据文件时使用专门为 S3 优化的I/O实现。然后使用如下命令执行Glue Job。这个命令会返回一个JobRunId,表示任务已经开始执行。用户可以进入Amazon Glue控制台监控该任务的运行状态,等待它成功完成。
aws glue start-job-run --job-name "temp-data-generator"
Pic 3: 模拟创建大量小文件的Glue Job成功执行
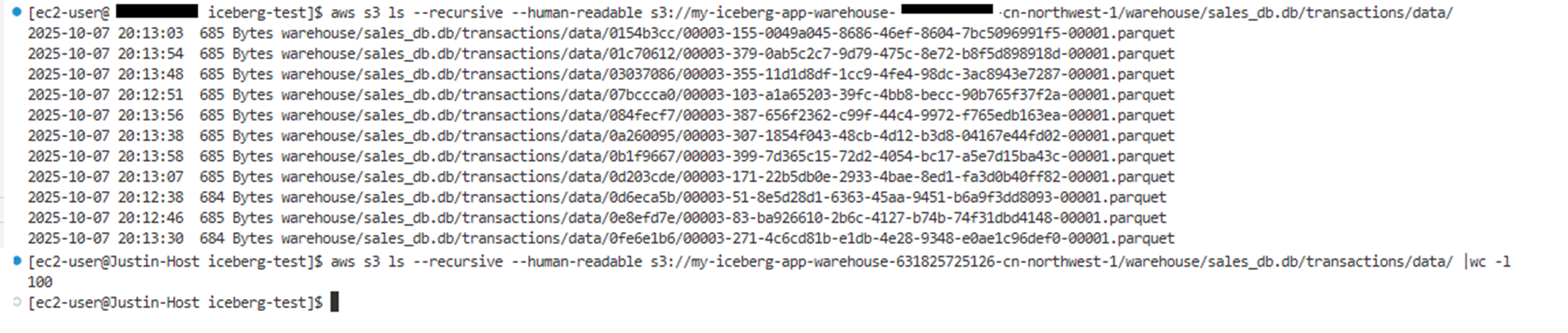
然后使用s3命令可以看到S3桶中已经生成了100个parquet格式的小文件。
Pic 4: 模拟创建大量小文件已经在S3桶中生成
每个parquet文件里面的内容如下图。
Pic 5: 模拟创建的小文件内容
如果用Athena来查询,会得到类似结果。
Pic 6: 用Athena查询模拟创建出来的小文件
至此,已经完成了测试环境准备工作,之后我们继续测试将这些小文件使用该方案进行Compaction操作。
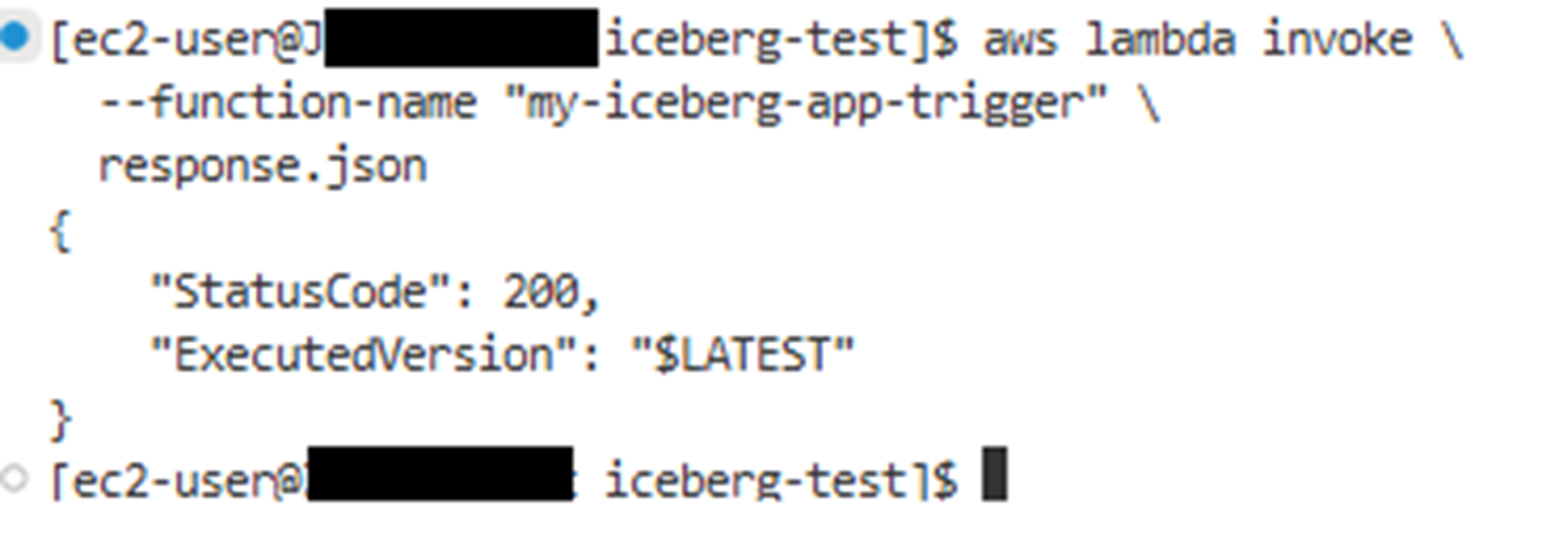
2),手动调用Lambda函数触发Glue Job测试小文件Compaction功能
使用如下Amazon CLI命令调用Lambda函数。
Pic 7: 手动调用Lambda函数来测试小文件Compaction功能
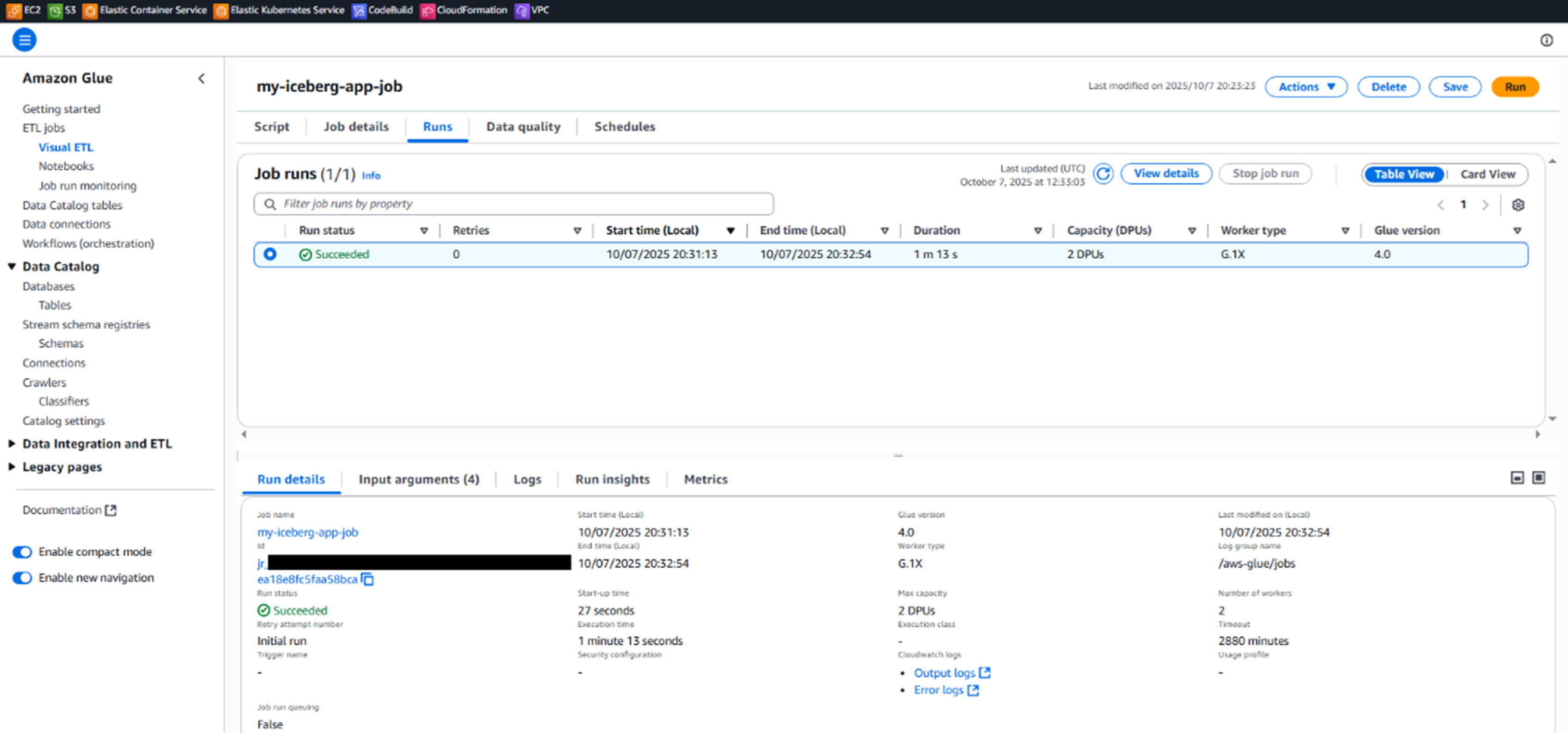
执行完成后,可以看到Glue Job被成功触发,执行结果为Success,并在S3桶里新生成了一个如下的文件,名为warehouse/sales_db.db/transactions/data/684a35a0/00000-0-9e3f39de-cd65-4f1d-8f5a-cb2c55349b29-00001.parquet,大小为1015字节。用Python打开该文件可以看到如下内容,有5条数据。
Pic 8: 观察Glue Job执行结果
Pic 9: Glue Job执行完成后,合并后的文件
3.4.清理被合并的老文件
由于已经合并完成,之前的小文件已经不需要,所以需要进行清理删除。本方案中使用Iceberg提供的专门的、安全的操作来清理过期的快照及其不再被引用的数据文件,即expire_snapshots功能。所以我们需要在合并任务之后,再增加一个清理任务。创建清理脚本为cleanup_snapshots.py,专门用于调用expire_snapshots过程。示例文件请参照本文4.5章节。把该python脚本上传到S3桶的scripts目录下,并且用类似下面的方式来创建 Glue Job。
aws glue create-job \
--name "cleanup-snapshots-job" \
--role "<Your-Glue-Job-Role-Arn>" \
--command '{ "Name": "glueetl", "ScriptLocation": "s3://<Your-Warehouse-Bucket-Name>/scripts/cleanup_snapshots.py", "PythonVersion": "3" }' \
--glue-version "4.0" \
--worker-type "G.1X" \
--number-of-workers 2 \
--default-arguments '{
"--datalake-formats": "iceberg",
"--conf": "spark.sql.catalog.glue_catalog=org.apache.iceberg.spark.SparkCatalog --conf spark.sql.catalog.glue_catalog.warehouse=s3://<Your-Warehouse-Bucket-Name>/warehouse/ --conf spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions --conf spark.sql.catalog.glue_catalog.catalog-impl=org.apache.iceberg.aws.glue.GlueCatalog --conf spark.sql.catalog.glue_catalog.io-impl=org.apache.iceberg.aws.s3.S3FileIO",
"--database_name": "sales_db",
"--table_name": "transactions"
}'
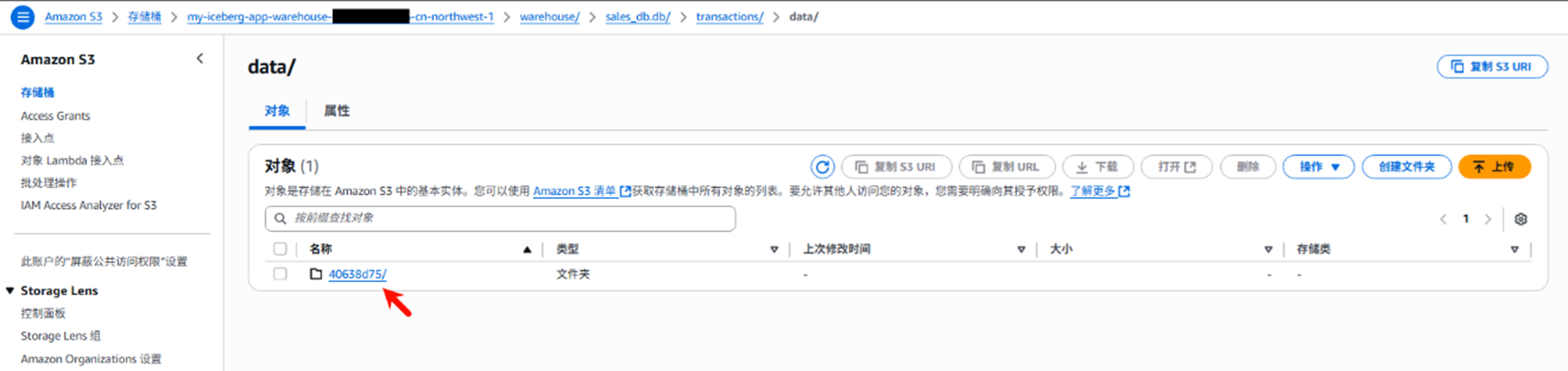
再运行aws glue start-job-run –job-name “cleanup-snapshots-job”执行该脚本,运行清理之后,可以看到S3桶里只剩1条最新的记录了。同时,用户可以将该清理任务也加入到自动化调度中,比如在Compaction任务成功后触发,或以周期(如每周)运行。
Pic 10: Glue Job执行清理后,旧小文件被删除清空
Pic 11: S3中只存在一个合并后的大文件
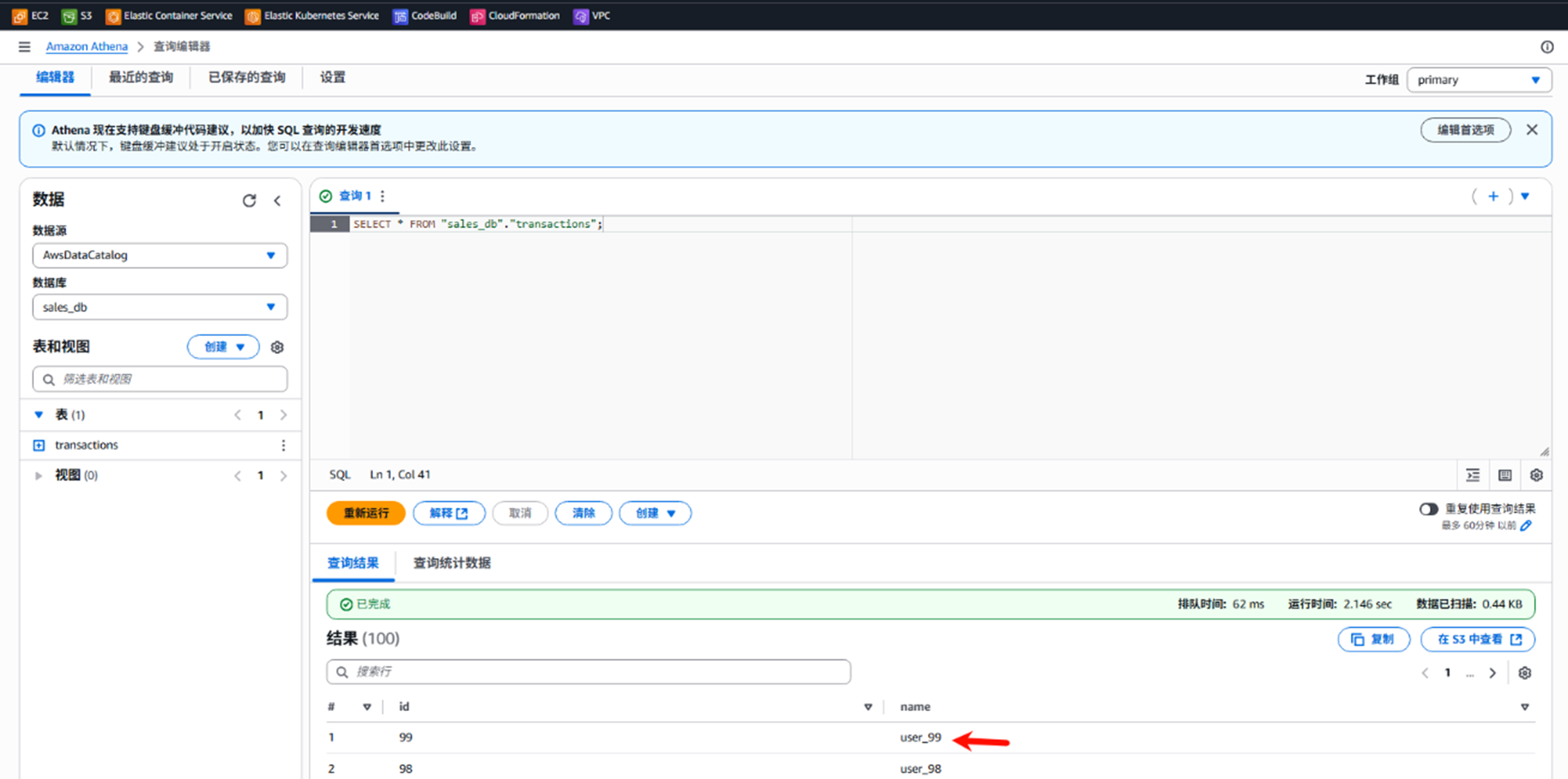
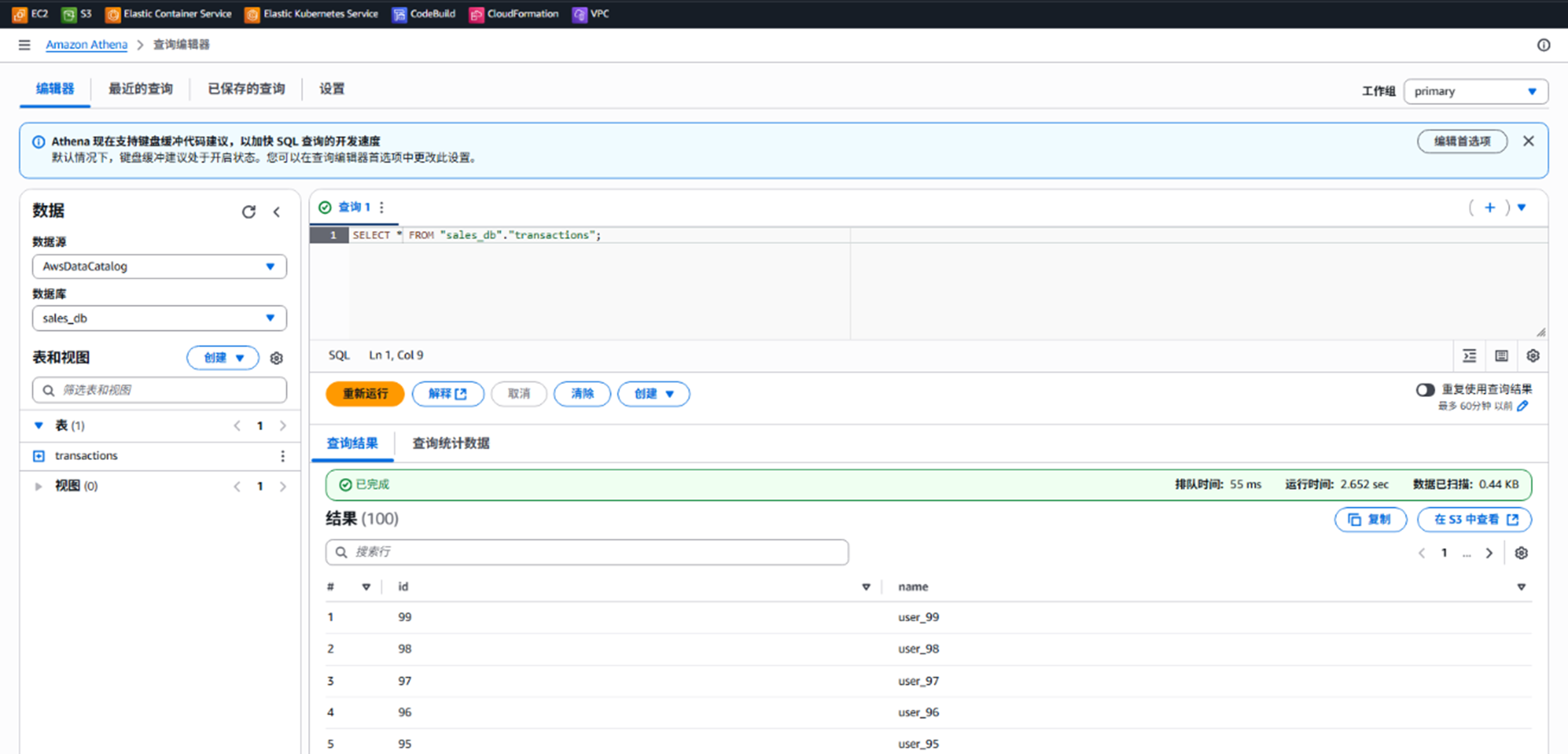
从Athena进⾏查询SELECT * FROM “sales_db”.”transactions”;可以得到如下类似结果,并且可以看到之前创建的100条记录已经全部合并入一个大文件中。
Pic 12:可以从Athena中看到合并后的所有100条记录在一个大文件里
4.测试演示环境中的文件示例
本文测试演示环境中,所使用的yaml、py文件示例提供如下。
4.1. 方案Cloudformation模板iceberg-compaction-template-minimal.yaml文件示例
本文中方案使用的Cloudformation模板会自动创建一个S3存储桶用于存放小文件和合并后的大文件、一个Glue数据库和一个Glue Job用于运行Compaction功能、一个Lambda函数以及相应的 IAM 角色和事件规则用于具体处理Compaction功能代码逻辑。示例如下:
iceberg-compaction-template-minimal.yaml
AWSTemplateFormatVersion: '2010-09-09'
Description: 'A minimal, working solution for scheduled Iceberg table compaction using Amazon Glue and Lambda.'
Parameters:
ProjectName:
Type: String
Default: 'iceberg-compaction-minimal'
Description: 'A prefix for all created resources to ensure uniqueness.'
DatabaseName:
Type: String
Default: 'iceberg_db'
Description: 'The name of the Amazon Glue database for your Iceberg tables.'
TableName:
Type: String
Default: 'my_iceberg_table'
Description: 'The name of the Iceberg table you want to compact.'
CompactionSchedule:
Type: String
Default: 'cron(0 2 ? * SUN *)' # 默认北京时间周日上午10点
Description: 'The cron schedule for running the compaction job (in UTC).'
Resources:
# 1. 创建用于Iceberg数据仓库和脚本的S3桶
WarehouseBucket:
Type: AWS::S3::Bucket
Properties:
BucketName: !Sub '${ProjectName}-warehouse-${AWS::AccountId}-${AWS::Region}'
PublicAccessBlockConfiguration:
BlockPublicAcls: true
BlockPublicPolicy: true
IgnorePublicAcls: true
RestrictPublicBuckets: true
# 2. 创建用于运行Glue Job的IAM Role
GlueJobRole:
Type: AWS::IAM::Role
Properties:
AssumeRolePolicyDocument:
Version: '2012-10-17'
Statement:
- Effect: Allow
Principal: { Service: 'glue.amazonaws.com' }
Action: 'sts:AssumeRole'
ManagedPolicyArns:
- !Sub 'arn:${AWS::Partition}:iam::aws:policy/service-role/AWSGlueServiceRole'
Policies:
- PolicyName: S3AccessPolicy
PolicyDocument:
Version: '2012-10-17'
Statement:
- Effect: Allow
Action: 's3:*'
Resource:
- !GetAtt WarehouseBucket.Arn
- !Sub '${WarehouseBucket.Arn}/*'
# 3. 创建用于运行Lambda函数的IAM Role
LambdaExecutionRole:
Type: AWS::IAM::Role
Properties:
AssumeRolePolicyDocument:
Version: '2012-10-17'
Statement:
- Effect: Allow
Principal: { Service: 'lambda.amazonaws.com' }
Action: 'sts:AssumeRole'
ManagedPolicyArns:
- !Sub 'arn:${AWS::Partition}:iam::aws:policy/service-role/AWSLambdaBasicExecutionRole'
Policies:
- PolicyName: GlueJobStartPolicy
PolicyDocument:
Version: '2012-10-17'
Statement:
- Effect: Allow
Action: 'glue:StartJobRun'
Resource: !Sub 'arn:${AWS::Partition}:glue:${AWS::Region}:${AWS::AccountId}:job/${CompactionJob}'
# 4. 创建Glue Database存放Iceberg table表结构
GlueDatabase:
Type: AWS::Glue::Database
Properties:
CatalogId: !Ref AWS::AccountId
DatabaseInput:
Name: !Ref DatabaseName
# 5. 创建Glue Job用来实现Compaction功能
CompactionJob:
Type: AWS::Glue::Job
Properties:
Name: !Sub '${ProjectName}-job'
Role: !GetAtt GlueJobRole.Arn
Command:
Name: glueetl
PythonVersion: '3'
ScriptLocation: !Sub 's3://${WarehouseBucket}/scripts/iceberg_compaction.py'
DefaultArguments:
'--datalake-formats': 'iceberg'
'--conf': !Sub 'spark.sql.catalog.glue_catalog=org.apache.iceberg.spark.SparkCatalog --conf spark.sql.catalog.glue_catalog.warehouse=s3://${WarehouseBucket}/warehouse/ --conf spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions --conf spark.sql.catalog.glue_catalog.catalog-impl=org.apache.iceberg.aws.glue.GlueCatalog --conf spark.sql.catalog.glue_catalog.io-impl=org.apache.iceberg.aws.s3.S3FileIO'
'--database_name': !Ref DatabaseName
'--table_name': !Ref TableName
GlueVersion: '4.0'
WorkerType: 'G.1X'
NumberOfWorkers: 2
# 6. 创建Lambda触发器,来触发Glue Job
CompactionTriggerFunction:
Type: AWS::Lambda::Function
Properties:
FunctionName: !Sub '${ProjectName}-trigger'
Runtime: python3.9
Handler: index.lambda_handler
Role: !GetAtt LambdaExecutionRole.Arn
Timeout: 60
Environment:
Variables:
GLUE_JOB_NAME: !Ref CompactionJob
Code:
ZipFile: |
import boto3
import os
import logging
logger = logging.getLogger()
logger.setLevel(logging.INFO)
glue_client = boto3.client('glue')
def lambda_handler(event, context):
job_name = os.environ['GLUE_JOB_NAME']
logger.info(f"Starting Glue job: {job_name}")
try:
response = glue_client.start_job_run(JobName=job_name)
logger.info(f"Successfully started job run. Run ID: {response['JobRunId']}")
return { 'statusCode': 200, 'body': f"Job {job_name} started." }
except Exception as e:
logger.error(f"Failed to start job {job_name}: {e}")
raise e
# 7. 创建EventBridge规则来定期执行Lambda函数
ScheduleRule:
Type: AWS::Events::Rule
Properties:
Name: !Sub '${ProjectName}-schedule'
ScheduleExpression: !Ref CompactionSchedule
State: ENABLED
Targets:
- Arn: !GetAtt CompactionTriggerFunction.Arn
Id: 'CompactionTriggerTarget'
# 8. 为Eventbridge创建相关权限来调用Lambda函数
LambdaInvokePermission:
Type: AWS::Lambda::Permission
Properties:
FunctionName: !GetAtt CompactionTriggerFunction.Arn
Action: 'lambda:InvokeFunction'
Principal: 'events.amazonaws.com'
SourceArn: !GetAtt ScheduleRule.Arn
Outputs:
WarehouseBucketName:
Description: 'S3 bucket for the Iceberg warehouse and scripts.'
Value: !Ref WarehouseBucket
CompactionJobName:
Description: 'Name of the created Amazon Glue job for compaction.'
Value: !Ref CompactionJob
LambdaFunctionName:
Description: 'Name of the trigger Lambda function.'
Value: !Ref CompactionTriggerFunction
4.2.部署脚本deploy-minimal.sh
部署脚本deploy-minimal.sh使用了aws cloudformation deploy命令来根据之前定义的模板创建Amazon Cloudformation堆栈,另外它可以自动判断是创建新堆栈还是更新现有堆栈。示例文件如下:
#!/bin/bash
# 部署Iceberg表Compaction功能脚本
set -e # Exit immediately if a command exits with a non-zero status.
# 配置列表
STACK_NAME="my-iceberg-compaction-stack"
TEMPLATE_FILE="iceberg-compaction-template-minimal.yaml"
# You can specify your region here, or it will use your default configured region.
AWS_REGION="${AWS_REGION:-cn-north-1}"
echo "Starting deployment of stack: ${STACK_NAME} in region: ${AWS_REGION}"
# 部署前检查验证模板文件
echo "Validating template: ${TEMPLATE_FILE}..."
aws cloudformation validate-template --template-body file://${TEMPLATE_FILE} > /dev/null
echo "Template validation successful."
# 部署Amazon Cloudformation堆栈,新建或更新堆栈
echo "Deploying CloudFormation stack..."
aws cloudformation deploy \
--stack-name "${STACK_NAME}" \
--template-file "${TEMPLATE_FILE}" \
--capabilities CAPABILITY_NAMED_IAM \
--region "${AWS_REGION}" \
--parameter-overrides \
ProjectName="my-iceberg-app" \
DatabaseName="sales_db" \
TableName="transactions"
echo "Deployment command sent. Waiting for stack operation to complete..."
# 输出堆栈outputs
echo "Deployment successful! Stack outputs:"
aws cloudformation describe-stacks \
--stack-name "${STACK_NAME}" \
--query "Stacks[0].Outputs" \
--output table \
--region "${AWS_REGION}"
echo "Next Steps: You need to upload your compaction Glue script to the created S3 bucket."
4.3.Python Glue 脚本iceberg_compaction.py
Python Glue脚本iceberg_compaction.py接收Glue Job传入的参数(数据库和表名),然后调用Spark SQL中专门为Iceberg设计的rewrite_data_files存储过程来执行文件合并。示例Python代码文件如下:
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
import logging
# 设置日志
logging.basicConfig()
logger = logging.getLogger(__name__)
logger.setLevel(logging.INFO)
# 主Spark任务
# 1. 初始化
args = getResolvedOptions(sys.argv, ['JOB_NAME', 'database_name', 'table_name'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
# 2. 从参数中获取数据库和表名
db_name = args['database_name']
table_name = args['table_name']
full_table_name = f"glue_catalog.{db_name}.{table_name}"
logger.info(f"Started Compaction operation on table '{full_table_name}'")
# 3. 执行核心合并逻辑
try:
logger.info("Calling 'rewrite_data_files' Stored Procedure")
result_df = spark.sql(f"""
CALL glue_catalog.system.rewrite_data_files(
table => '{db_name}.{table_name}',
strategy => 'binpack',
# OPTIONS map can make the compaction more aggressive, ensuring it processes all small files.
options => map(
'min-input-files', '2',
'target-file-size-bytes', '134217728'
)
)
""")
logger.info("'rewrite_data_files'Completed, and the results are as following:")
result_df.show()
result_data = result_df.first()
if result_data:
rewritten_files = result_data["rewritten_data_files_count"]
added_files = result_data["added_data_files_count"]
logger.info(f" Completed compaction on {rewritten_files} files. {added_files} new files generated.")
else:
logger.info(" No files need to be compacted. Current table is already optimized status.")
except Exception as e:
logger.error(f"Compaction job failed: {e}")
raise e
logger.info(f" Compaction operation on table '{full_table_name}' completed successfully")
job.commit()
4.4.数据生成脚本create_small_files.py
数据生成脚本create_small_files.py用于该方案的测试验证,实际生产环境中无需运行。该脚本会创建一个Iceberg表用于测试,并循环写入100次数据,每次只写一条数据,从而生成100个只包含一条数据的小文件。用户需要将该脚本上传到s3桶的scripts目录下。示例Python脚本如下:
import sys
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
from pyspark.sql.types import StructType, StructField, StringType, IntegerType
# 初始化
args = getResolvedOptions(sys.argv, ['JOB_NAME', 'database_name', 'table_name'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
db_name = args['database_name']
table_name = args['table_name']
full_table_name_for_sql = f"glue_catalog.{db_name}.{table_name}"
full_table_name_for_save = f"glue_catalog.{db_name}.{table_name}" # In Glue 4/Iceberg 1.x, save() also needs the full name
print(f"Preparing to generate testing data in table '{full_table_name_for_sql}'.")
# 使用SQL DDL语句创建测试用的Iceberg表,其中TBLPROPERTIES参数为启用Compaction功能的前提,非常重要
try:
print(f"Creating table {full_table_name_for_sql}")
spark.sql(f"""
CREATE TABLE IF NOT EXISTS {full_table_name_for_sql} (
id int,
name string
)
USING iceberg
TBLPROPERTIES (
'format-version'='2',
'write.object-storage.enabled'='true'
)
""")
print("Table created or exists")
except Exception as e:
print(f"Failed when creating table: {e}")
raise e
# 向创建后的表持续使用Append方式写入数据
schema = StructType([
StructField("id", IntegerType(), True),
StructField("name", StringType(), True)
])
for i in range(100):
print(f"Writing the No. {i+1}/100 file …")
data = [(i, f"user_{i}")]
df = spark.createDataFrame(data, schema)
df.write.format("iceberg").mode("append").save(full_table_name_for_save)
print("100 files created successfully!")
job.commit()
4.5.清理被合并的旧小文件脚本expire_snapshots.py
清理被合并的旧小文件脚本expire_snapshots.py,使用Iceberg专门提供的、安全的操作来清理过期的快照及其不再被引用的数据文件,从而实现清理合并后旧的小文件功能。示例Python代码如下:
import sys
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
import logging
from pyspark.sql.functions import current_timestamp
# 设置日志
logging.basicConfig()
logger = logging.getLogger(__name__)
logger.setLevel(logging.INFO)
# 清理逻辑的主Spark Job
# 1. 初始化
args = getResolvedOptions(sys.argv, ['JOB_NAME', 'database_name', 'table_name'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
# 2. 获取参数
db_name = args['database_name']
table_name = args['table_name']
full_table_name = f"glue_catalog.{db_name}.{table_name}"
logger.info(f"Started snapshot cleanup operation on table '{full_table_name}' .")
# 3. 执行核心清理逻辑,调用Iceberg内置的expire_snapshots存储过程。这会删除所有比当前时间早的旧快照,然后自动删除那些只被这些过期快照引用的数据文件。
try:
logger.info(" Calling Expire_Snapshots Stored Procedure ...")
# 获取当前时间戳用于清理
current_ts_df = spark.sql("SELECT current_timestamp()")
current_ts = current_ts_df.collect()[0][0]
result_df = spark.sql(f"""
CALL glue_catalog.system.expire_snapshots(
table => '{db_name}.{table_name}',
older_than => TIMESTAMP '{current_ts}'
)
""")
logger.info("Expire_Snapshots execution completed. Results are as following: ")
result_df.show(truncate=False)
except Exception as e:
logger.error(f" Snapshot cleanup job failed: {e}")
raise e
logger.info(f" Snapshot cleanup operation on table '{full_table_name}' completed! ")
job.commit()
5.结束语
亚马逊云科技中国区域在缺失对Iceberg表进行Compaction操作的情况下,本文给目前众多结合Snowflake、Iceberg和Amazon Glue执行数据仓库操作的客户提供了一个解决方案。该方案使用了Amazon Cloudformation模板,实现了一键式部署Amazon Glue Job、Lambda函数以实现Amazon Glue的Iceberg表合并合并相同的功能。
附录参考网址:
[1] https://docs.aws.amazon.com/glue/latest/dg/compaction-management.html
[2] https://aws.amazon.com/cn/blogs/aws/aws-glue-data-catalog-now-supports-automatic-compaction-of-apache-iceberg-tables/
*前述特定亚马逊云科技生成式人工智能相关的服务目前在亚马逊云科技海外区域可用。亚马逊云科技中国区域相关云服务由西云数据和光环新网运营,具体信息以中国区域官网为准。
本篇作者
AWS 架构师中心:云端创新的引领者
探索 AWS 架构师中心,获取经实战验证的最佳实践与架构指南,助您高效构建安全、可靠的云上应用

|
 |