亚马逊AWS官方博客
快速搭建 AWS Glue ETL 开发环境
前言
AWS Glue 是一项完全托管的提取、转换和加载 (ETL) 服务,可让您轻松准备和加载数据以进行分析。在这篇博客中,我们将介绍快速在本地或远程环境搭建AWS Glue测试环境,来编写和测试ETL 脚本,以便随后在正式生产环境中部署和使用。 AWS Glue 构建在 Apache Spark 之上,并且由AWS Glue产品团队在 Apache Spark 之上进行了许多改进,并拥有自己的 ETL 库,可以快速跟踪开发过程并减少代码。你可以参考aws-glue-libs的GitHub代码仓库获取更多信息。与使用Hadoop集群相比,AWS Glue 在无服务器环境中运行,没有需要管理的基础设施,且 AWS Glue 会预置、配置和扩展运行数据集成作业所需的资源。
AWS Glue还提供了许多内置的转换方法,可以将数据通过DynamicFrame结构进行,这是一种基于处理Apache Spark SQL DataFrame 的扩展。除此之外您可以参考此链接查看DynamicFrame的使用方法。相对的,您也可以选择在Glue ETL任务中调用Spark SQL来进行开发。AWS Glue具有不同的版本,这决定了AWS Glue所支持的Apache Spark 和 Python 版本。您可以参考此链接中的内容来查看不同AWS Glue版本的功能更新。
本文将展示如何自建Glue ETL的开发环境,以满足快速开发和调试的需求。配置Glue ETL的开发环境可以避免反复将依赖项打包上传到S3并创建Glue ETL任务进行尝试,提升开发效率。在Python开发中,一种非常受欢迎的方法是通过IDE提供的远程开发功能,连接到云服务器的开发环境。IDE可以同步服务器与本地的项目文件,并使用云服务器上配置的远程解析器。本文将展示如何快速在Amazon Linux EC2实例上配置Glue ETL开发环境,并结合PyCharm远程提交和测试代码。您也可以将配置好的远程环境与您的Glue ETL CI/CD管道结合使用,自动化测试和部署ETL脚本。
如果您更倾向于使用Notebook环境进行开发,您可以采用AWS Glue团队发布的Docker镜像快速启动环境,而无需采用本文中描述的步骤。该容器环境中预先配置了Jupyter和Zeppelin可以直接使用。您可以参考此链接了解关于使用容器环境的使用方法。
先决条件
在开始之前,请确保在本地开发环境中已经安装了PyCharm。本文中涉及的一些功能可能需要PyCharm专业版。同时,请准备好AWS账号,以及在本地环境中配置AK/SK。PyCharm还提供了AWS Toolkit插件,可以轻松管理AWS凭证。
建议启动一台新的Amazon Linux 2实例进行尝试,并配置SSH端口访问的安全组。这台实例还需要配置访问Glue和S3的最基本AWS权限。本文中所描述的方案目前仅在AWS Global Region的Amazon Linux 2系统上验证过。其他区域和操作系统可能会需要对一些命令和配置进行修改才能正常运行。
如果在此之前您并未了解过如何使用AWS Glue进行ETL开发,建议您先参考以下链接:
通过PyCharm连接到远程开发环境
如果您还未在本地Mac或Windows环境中配置PyCharm,您可以通过此链接访问PyCharm官方网站来进行IDE工具的下载。
要使用远程服务器进行Python开发,请先在公有子网中创建一台EC2实例,然后在PyCharm的项目设置界面中添加新的解析器:
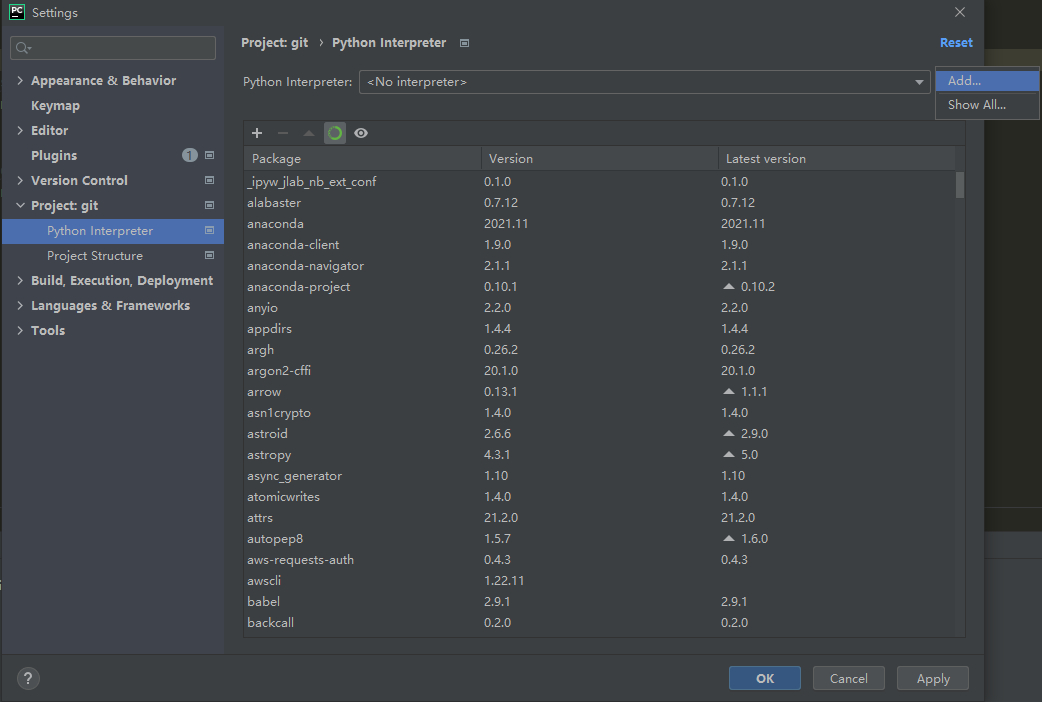
在弹出的界面左侧选择SSH解析器,然后输入EC2实例的公网IP和默认用户名:

注:为了安全起见,建议您在EC2安全组中只开放必要的端口,并且限制只能从您本地电脑的IP地址进行访问。
接下来的窗口中请选择通过秘钥对认证的方式,并且选择创建EC2时所使用的秘钥:

接下来PyCharm会尝试发起SSH连接到该服务器。如果连接成功,PyCharm会尝试寻找服务器中默认的Python解析器。以Amazon Linux 2为例:
在配置完成后,PyCharm会自动保存SSH登录信息,并且创建新的部署,将本地的项目代码同步到远程服务器的指定目录下。

接下来,就可以通过SSH连接到服务器了。

在Amazon Linux 2系统中搭建AWS Glue ETL 环境
在进行本地或者远程开发之前,您还需要对Python和Spark环境进行基础配置。除了Python环境之外,您还需要对Spark和awsglue环境进行配置。aws-glue-libs中提供了awsglue作为与Glue Spark进行交互的Python interface。除此之外,您还需要配置Glue ETL所需的Spark运行环境。接下来的示例中将以Amazon Linux 2为例搭建完整的运行环境。
配置Python运行环境
您可能会注意到,接下来的示例中使用了Anaconda进行Python环境的配置。Anaconda是一个开源的Python发行版本,其包含了conda、Python等180多个科学包及其依赖项。Conda是一个开源环境管理器,可以用于在同一个服务器上安装不同版本的Python以及软件包,并能够在不同的环境之间切换。您可以登录Anaconda官方网站获取最新安装包的下载链接,或者通过此链接查看历史安装包版本。
首先,通过SSH连接到服务器,以Anaconda3-2021.11版本为例,运行以下命令下载最新的Anaconda3安装包:
默认安装路径是home下的anaconda3。安装完成后,会提示是否运行conda init。通常conda init后需要启动一个新的SSH连接才能生效。如果conda命令仍然无法执行,可以运行以下命令:
如果 conda init 执行成功,应该可以看到如下的效果(其中红色部分是当前的Python环境名称):

接下来执行以下命令,以Glue3.0为例,创建一个新的Python运行环境:
conda create -n glue3.0 python=3.7
在Glue服务中,不同的Glue ETL任务对应不同的Python版本,建议您参考此链接查询版本信息,以避免测试环境和实际生产环境的差异。
环境创建完成之后,运行以下代码激活环境:
conda activate glue3.0
您可以观察到,环境从base切换到了glue3.0环境:

配置完成之后,回到PyCharm的项目设置中,更新解析器的名称,以及修改路径为
/home/ec2-user/anaconda3/envs/glue3.0/bin/python:

配置Glue ETL运行环境
Glue ETL的运行环境依赖Apache Spark。要在服务器上安装Spark,还需要配置Spark依赖的JDK。您可以通过Spark官方网站获取JDK的版本要求。
以Java8为例,首先运行以下代码安装JDK:
sudo yum install -y java-1.8.0-openjdk-devel.x86_64
安装完成之后可以运行java -version确认JDK版本。如果返回类似信息则证明安装成功:
接下来配置JAVA环境变量。通常来讲JDK的安装在/usr/lib/jvm/路径下。根据实际路径设置JAVA环境变量:
接下来安装Spark。您可以通过此链接获取不同Glue版本获取的代码分支名称和下载地址。
最后配置aws-glue-libs。这里需要将代码克隆到服务器上,然后选定指定的版本。您可以通过GitHub上的信息获取该版本分支的名称,最新版本命名为master。以Glue 3.0版本为例:
您可能代码仓库中包含了一个pom文件。安装的过程将需要使用Apache Maven下载Glue ETL的依赖项。您可以再次参考此链接获取AWS提供的Maven下载地址。以Glue 3.0版本为例:
接下来直接运行bin路径下的glue-setup.sh脚本完成安装:
这期间会下载Glue ETL 运行环境所需的JAR包,第一次运行可能会需要一段时间。运行成功之后,您可以注释掉aws-glue-libs/bin/glue-setup.sh脚本的以下代码,以避免在每次启动Glue ETL 任务的时候都重复运行 mvn 下载JAR包:
成功后,我们就可以使用Glue可执行文件来运行测试任务了。AWS Glue团队提供了三个实用工具和框架可以测试和运行ETL脚本。这包括:
- AWS Glue Shell:启动类似PySpark shell的工具来进行ETL代码的调试;
- AWS Glue Submit:类似Spark Submit提交ETL脚本;
- Pytest(可选):运行Python代码的单元测试工具。本文不会更深入地讨论单元测试,您可以参考pytest文档了解更多细节。
需要注意的是,每次启动SSH连接使用Glue ETL 的时候仍然需要保证 Python 环境以及 SPARK 变量。您可以选择将以上变量加入到$HOME/.bashrc中,避免后续重复操作:
通常来讲,遵循以上的步骤就可以成功搭建Glue ETL的测试环境了。通常来讲,搭建实验环境中的最常见问题可能包括:
- mvn build失败。这通常可能是由于网络问题或是没有正确配置JAVA和Maven的环境变量;
- 在执行二进制文件的时候出现mkdir: cannot create directory ‘/home/ec2-user/aws-glue-libs/conf’: File exists报错。这是每次启动Glue ETL 可执行文件时都会重新执行glue-setup.sh,这个报错通常不会影响执行,您可以选择修改glue-setup.sh文件取消mkdir的操作;
- 在启动可执行文件时出现关于io.netty的报错。这通常是由于
aws-glue-libs/jarsv1/和spark/jars/路径下有不同版本的netty-all的JAR包。通常可以通过删除aws-glue-libs/jarsv1/netty-all*版本并将spark/jars/netty-all-4.1.17.Final.jar拷贝到aws-glue-libs/jarsv1/路径下修复这个问题。您可以参考此issue的链接获取更多信息; - 在创建SparkContext的时候报ValueError: Cannot run multiple SparkContexts at once in spark with pyspark。这是由于环境有创建SparkContext的数量限制,可以尝试修改代码使用SparkContext.getOrCreate()方法来创建SparkContext;
- 在创建DynamicFrame的时候出现java.lang.NoSuchMethodError: com.google.common的报错。这通常是由于Guava版本的不匹配导致的。通常把
/home/ec2-user/aws-glue-libs/jarsv1/路径下的较新版本guava-*.jar拷贝到/home/ec2-user/spark/jars/路径下并删除老版本可以修复这个问题; - 代码执行过程中遇到错误AWS Endpoint的报错,比如
java.net.UnknownHostException: glue.cn-northwest-1.amazonaws.com。这是由于Maven下载的Java SDK 无法自动识别中国区的 endpoint,建议在这个问题修复前先在海外区域进行尝试。
通过PyCharm使用Glue ETL环境
如果您已经能够成功运行Glue ETL的测试环境,接下来的内容将介绍如何将测试环境与IDE集成使用。通过以下配置,您将可以直接在PyCharm中运行使用了awsglue库的ETL代码。 需要注意的是,使用自建的单机Glue ETL 环境有资源和一些Glue功能上的限制,比如无法使用Job Bookmark。您可以参考此链接获取更详细的内容。
配置解析器运行ETL脚本
您可以直接配置项目使用远程Glue ETL环境运行.py文件。回到项目的设置中,选择解析器设置。在界面中点击如下图所示的红色按钮:

如图所示,将以下路径加入到interpreter的path中:
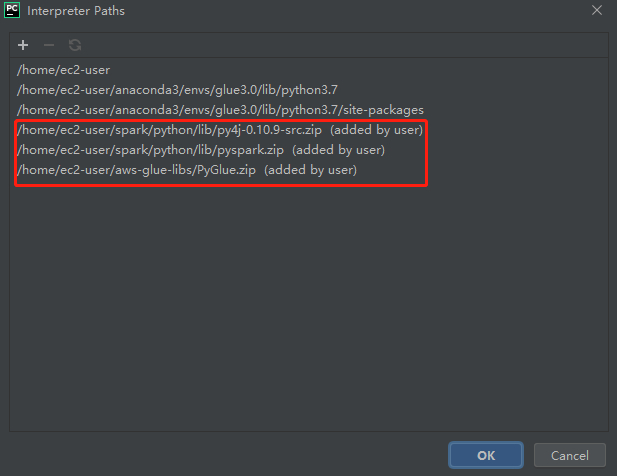
这样就可以直接在代码中import pyspark 和 awsglue 库了。接下来您可以直接在PyCharm中点击运行来测试ETL任务了:

使用Spark Submit功能提交代码
PyCharm 中还提供了通过 Spark Submit 的方式提交代码的功能,可以与gluesparksubmit二进制文件一起使用。因为Spark Submit功能会默认运行名为spark-submit的可执行文件,首先在SSH连接中,运行以下代码将gluesparksubmit重命名为spark-submit:
然后在PyCharm中,点击右上方的下拉菜单中标红选项修改运行选项:
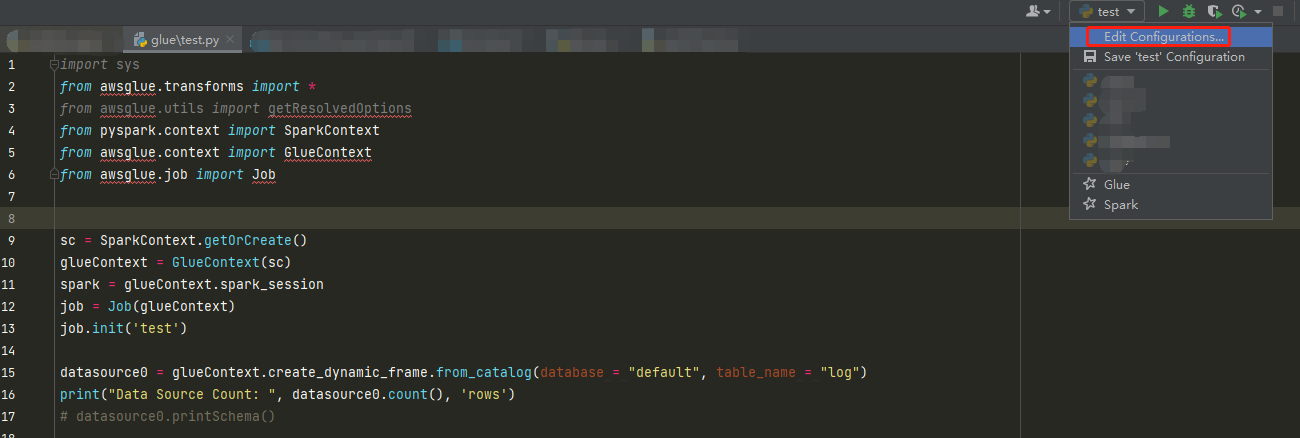
运行选项中选择Spark Submit下方的SSH:
在配置选项中,需要指定aws-glue-libs路径作为Spark home:

最后在右上方选中刚刚创建的Spark Submit运行选项,点击右侧的绿色三角运行代码:

可以看到PyCharm将脚本上传到远程服务器后执行成功:

参考链接
AWS官方文档:使用 Amazon Glue ETL 库在本地开发和测试 ETL 脚本