亚马逊AWS官方博客
研究热点:基于 Apache MXNet 的开源 BNN (二值神经网络) 库 – BMXNet
这是一篇由德国波茨坦 Hasso Plattner 研究所的 Haojin Yang、Martin Fritzsche、Christian Bartz 和 Christoph Meinel 发布的客座文章。我们很高兴看到研究工作促进了深度学习在低功耗设备上的实际实施。这项工作在将强大的智能功能拓展到我们日常生活的过程中发挥着举足轻重的作用。
近年来,深度学习技术在学术界和行业里取得了良好的业绩和众多突破。但是,最先进的深度模型计算成本高昂、占用大量存储空间。移动平台、可穿戴设备、自主机器人、IoT 设备等领域的众多应用也对深度学习有着强烈的需求。如何在这样的低功耗设备上有效实施深度模型成了一大难题。
最近提出的二值神经网络 (BNN) 使用位运算代替标准算术运算,大大降低了存储器大小和访问要求。通过显著提高运行时效率和降低能耗,我们得以在低功耗设备上实施最先进的深度学习模型。这项技术与对开发人员友好 (相比 VHDL/Verilog 而言) 的 OpenCL 相结合,也使 FPGA 成为了深度学习的可行选择。
在这篇文章中,我们将为大家介绍一种基于 Apache MXNet 的开源 BNN (二值神经网络) 库 – BMXNet。开发完成的 BNN 层可以无缝应用于其他标准库组件,并且在 GPU 和 CPU 模式下均可工作。BMXNet 由 Hasso Plattner 研究所的多媒体研究小组维护和开发,在 Apache 许可证下发布。https://github.com/hpi-xnor 提供了该程序库以及一些示例项目和预训练二值模型等下载资源。
框架
BMXNet 提供支持输入数据和权重二值化的激活、卷积和全连接层。这些层称作 QActivation、QConvolution 和 QFullyConnected,经过专门设计,可直接替换相应的 MXNet 变体。它们提供了一个附加参数 act_bit,用于控制层计算的位宽。列表 1 和列表 2 显示了提议的二值层的 Python 使用示例,并与 MXNet 做了对比。我们不为网络中的第一层和最后一层使用二值层,因为这可能会大幅降低准确性。BMXNet 中 BNN 的标准块结构实现为以下列表中显示的 QActivation-QConvolution 或 QFullyConnected-BatchNorm-Pooling。

在传统的深度学习模型中,全连接和卷积层严重依赖于矩阵点积,后者需要进行大量的浮点运算。相比之下,使用二值化权重和输入数据可借助 CPU 指令 xnor 和 popcount 实现高性能矩阵乘法。大多数现代 CPU 都对此类运算做了优化。计算两个二元矩阵 A◦B 的点积时不再需要乘法运算。可通过以下方法求得 A 中每行与 B 中每列元素的乘积和求和近似值:首先使用 xnor 运算组合这些值,然后统计结果中设置为 1 的位数,这称作位图计数。这样我们就可以充分利用位运算拥有硬件支持这一优势。支持 SSE4.2 的 x86 和 x64 CPU 都提供了位图计数指令;在 ARM 架构中,此指令包含在 NEON 指令集中。列表 3 显示了一个使用这些指令的未优化的 GEMM (通用矩阵乘法) 实现:

gcc 和 clang 编译器都内置了编译器内部函数 popcount,在支持的硬件上,此函数会转换为机器指令。BINARY_WORD 是一种打包数据类型,可存储 32 个 (x86 和 ARMv7) 或 64 个 (x64) 矩阵元素,一位代表一个元素。我们实现了多个优化版本的 xnor GEMM 内核,尝试通过分块和打包数据以及借助循环展开和并行化技术来充分利用处理器缓存的层次结构。
训练和推理
对于训练阶段,我们精心设计了二值化层,以便在将权重及输入限制为离散值 -1 和 +1 时,精确匹配 MXNet 内置层的输出 (通过 BLAS 点积运算计算)。计算出点积后,我们将结果映射回提议的 xnor 形式点积的值范围,如以下公式所示:
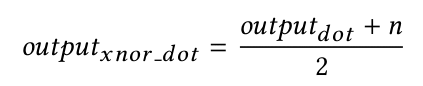
其中 n 是值范围参数。此设置通过应用 CuDNN 来借助 GPU 支持进行大规模并行训练。然后,训练后的模型可用于在功能不够强大的设备 (无 GPU 支持、存储空间小) 上进行推理,其中预测的前向传递将使用 xnor 和 popcount 运算代替标准算术运算来计算点积。
使用 BMXNet 训练网络后,权重存储在 32 位浮点变量中。使用 1 位位宽训练的网络也是如此。我们提供了一个 model_converter,用于读入二值训练模型文件和打包 QConvolution 及 QFullyConnected 层的权重。转换后,每个权重仅使用 1 位存储和运行时内存。例如,有一个具有全精度权重的 ResNet-18 网络 (在 CIFAR-10 上),其大小为 44.7MB。经过我们模型转换器的转换,生成的文件大小仅为 1.5MB,压缩率高达 29 倍。
分类精度
我们对 MNIST (手写数字识别)、CIFAR-10 (图像分类) 数据集进行了 BNN 试验。试验在配备 Intel(R) Core(TM) i7-6900K CPU、64 GB RAM 和 4 TITAN X (Pascal) GPU 的工作站上进行。

上表列出了在 MNIST 和 CIFAR-10 上训练的二值和全精度模型的分类测试精度。表中数据显示,二值模型的大小显著降低。同时,准确性仍保持极高水准。此外,我们还对 ImageNet 数据集进行了二值化、部分二值化和全精度模型试验,结果显示,部分二值化模型的结果较为精准,而全二值化模型仍有较大改进空间 (有关更多详情,请参阅我们的论文)。
效率分析
我们进行了一系列试验来测量不同 GEMM 方法的效率。这些试验在配备 Intel 2.50GHz × 4 CPU (支持 popcnt 内部指令 (SSE4.2)) 和 8G RAM 的 Ubuntu16.04/64 位平台上进行。测量在卷积层内进行。我们对参数做了如下设置:filter number=64、kernel size=5×5、batch size=200、matrix sizes (M, N, K) = 64, 12800, kernel_w × kernel_h ×inputChannelSize。下图显示了测试结果。
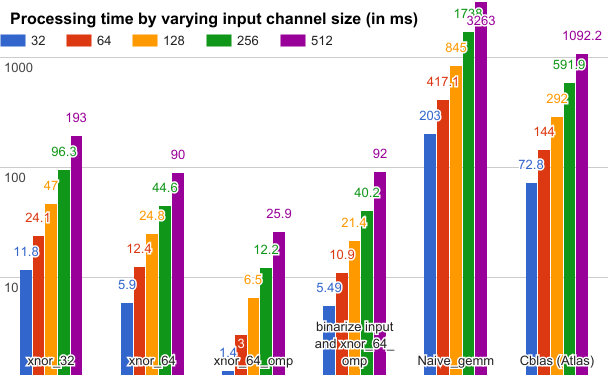
彩色列表示不同输入通道大小的处理时间 (毫秒);xnor_32 和 xnor_64 表示 32 位和 64 位 xnor gemm 操作数;xnor_64_omp 表示使用 OpenMP 并行编程库加速的 64 位 xnor gemm;二值化输入和 xnor_64_omp 进一步累加了输入数据二值化的处理时间。尽管计入了输入数据的二值化时间,我们的方法仍比 Cblas 方法快 13 倍。
结论
我们介绍了一种使用 C/C++ 基于 MXNet 实现的开源二值神经网络 – BMXNet。在目前的试验中,我们实现了高达 29 倍的模型大小节约和更高效的二元 gemm 计算。我们使用二值化 ResNet-18 模型开发了在 Android 和 iOS 上运行的图像分类示例应用程序。源代码、文档、预训练模型和示例项目发布在 GitHub 上。接下来,我们打算对不同深度架构的准确性和效率进行更系统的探索,重新实现 Q_Conv 层中的 unpack_patch2col 方法,进一步提高 CPU 模式下的推理速度。