亚马逊AWS官方博客
在EMR 6.0.0 中使用 Docker 简化您的 Spark 依赖项管理
Original URL: https://amazonaws-china.com/cn/blogs/big-data/simplify-your-spark-dependency-management-with-docker-in-emr-6-0-0/
Apache Spark是一套功能强大的数据处理引擎,能够为数据分析人员及工程技术团队提供易于使用的API与工具,快速实现数据分析。但对团队而言,Spark中的Python与R库依赖项管理往往具有一定难度。安装作业可能需要使用各个依赖项,而依赖项的运行又可能与库版本有所冲突,整个协调过程既耗时又复杂。Amazon EMR 6.0.0允许大家使用通过Docker Hub与Amazon ECR发布的Docker镜像,借此打包各依赖项以简化上述管理流程。如此一来,我们即可对单一Spark作业或notebook中的依赖项进行打包与管理,而不必直面整体集群中如蜘网般盘根错节的依赖项体系。
本文将向大家介绍如何使用Docker通过Amazon EMR 6.0.0与EMR Notebooks管理notebook依赖项。我们需要启动EMR 6.0.0集群,并将Amazon ECR中特定notebook的Docker镜像与EMR Notebook配合使用。
创建Docker镜像
第一步是创建一套包含Python 3与最新版本numpy Python软件包的Docker镜像。大家可以使用Dockerfile创建Docker镜像,该文件负责定义需要包含在镜像中的软件包与具体配置。与Amazon EMR 6.0.0配合使用的Docker镜像必须包含Java开发工具包(JDK)。以下Dockerfile使用Amazon Linux2与Amazon Corretto JDK 8:
FROM amazoncorretto:8
RUN yum -y update
RUN yum -y install yum-utils
RUN yum -y groupinstall development
RUN yum list python3*
RUN yum -y install python3 python3-dev python3-pip python3-virtualenv
RUN python -V
RUN python3 -V
ENV PYSPARK_DRIVER_PYTHON python3
ENV PYSPARK_PYTHON python3
RUN pip3 install --upgrade pip
RUN pip3 install numpy
RUN python3 -c "import numpy as np"
我们使用此Dockerfile创建Docker镜像,而后将其标记并上传至Amazon ECR。上传完成之后,我们还需要启动一套EMR 6.0.0集群,通过配置将此Docker镜像设定为Spark作业的默认镜像。通过以下操作步骤,大家可以完成Docker镜像的构建、标记与上传:
- 使用以下命令创建一个目录,并在其中创建一个名为
Dockerfile的新文件:
- 复制并粘贴Dockerfile的内容,保存内容,而后运行以下命令以构建Docker镜像:
- 使用以下命令,为本次演练创建
emr-docker-examplesAmazon ECR repo: - 使用以下命令标记在本地创建的镜像,并将其中的123456789123.dkr.ecr.us-east-1.amazonaws.com替换为您的Amazon ECR端点:
- 使用以下命令获取您Amazon ECR账户的登录行:
- 在get-login命令中输入并运行以上输出结果:
- 将本地构建的镜像上传至Amazon ECR,并将其中的123456789123.dkr.ecr.us-east-1.amazonaws.com部分替换为您的Amazon ECR端点。详见以下命令:
启动EMR 6.0.0集群并启用Docker
要配合Amazon EMR使用Docker,大家需要启动一套支持Docker运行时的EMR集群,并在其中使用正确的配置以接入您的Amazon ECR账户。要允许集群从Amazon ECR处下载镜像,请保证集群的实例配置具备AmazonEC2ContainerRegistryReadOnly的权限。在以下列出的第一步操作中,我们将EMR 6.0.0集群配置为使用Amazon ECR下载Docker镜像,并将Apache Livy与Apache Spark配置为使用pyspark-latest Docker镜像作为所有Spark作业的默认Docker镜像。请完成以下操作步骤以启动集群:
- 使用以下配置,在本地目录当中创建一个名为
emr-configuration.json的文件(将其中的123456789123.dkr.ecr.us-east-1.amazonaws.com部分替换为您的Amazon ECR端点): - 输入以下命令(将myKey部分替换为您通过SSH访问集群的EC2密钥对,并将subnet-1234567 部分替换为集群启动所在子网的ID):
- 使用您的EC2密钥对,通过SSH接入集群内的某一核心节点。
- 要生成Docker CLI命令来为集群创建用于从Amazon ECR处下载Docker镜像的凭证(有效期为12小时),请输入以下命令:
- 在
get-login命令中输入并运行以上输出结果: - 使用以下命令,将生成的
config.json文件放置在HDFS中的/user/hadoop/位置处:
现在,我们已经拥有了启用Docker运行时并可从Amazon ECR获取镜像的EMR集群。接下来,大家可以使用EMR Notebooks创建并运行自己的notebook了。
创建一个EMR Notebook
EMR Notebooks属于可通过Amazon EMR控制台直接使用的无服务器Jupyter notebooks。我们可以借此将notebook环境与底层集群基础设施剥离开来,并在无需额外设置SSH访问或者配置浏览器进行端口转发的前提下访问自己的notebook。大家可以在ERM控制台的左侧导航栏中找到EMR Notebooks。
要自行创建notebook,请完成以下操作步骤:
- 在EMR Console中点击Notebooks。
- 为您的notebook选择一个名称。
- 点击Choose and existing cluster,并选择您刚刚创建的集群。
- 点击Create notebook。

- 在notebook处于Ready状态之后,大家可以点击Open in JupyterLab按钮在新的浏览器选项卡中将其打开。在默认情况下,系统会创建一个带有您EMR Notebook名称的默认notebook。点击该notebook,系统会要求您选择Kernel,请选择PySpark。
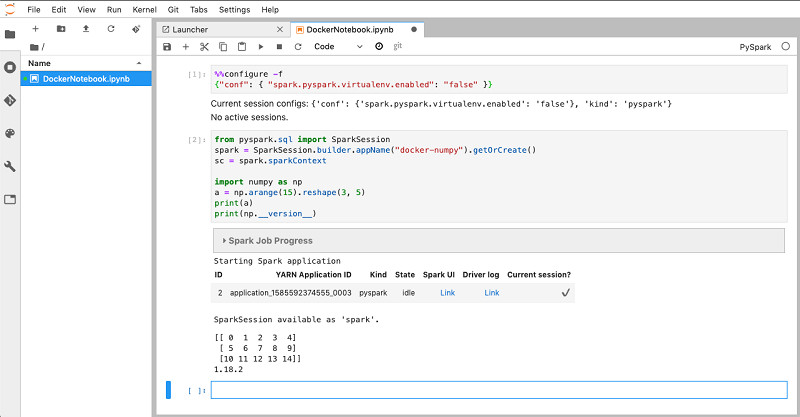
- 在notebook的第一栏中输入以下配置,而后单击▸(Run):

- 在notebook中输入以下PySpark代码,而后点击▸(Run):
输出结果应该类似于以下截屏所示;这里使用的是numpy的最新版本(截至本文撰稿时,为1.18.2版本)。

此PySpark代码将运行在您使用YARN、Docker以及pyspark-latest镜像的EMR 6.0.0集群之上。EMR Notebooks通过Apache Livy接入该EMR集群。在emr-configuration.json中指定的配置会将您EMR集群中的Spark与Livy实例设定为使用Docker、并将pyspark-latest Docker镜像作为全部Spark作业的默认Docker镜像。如此一来,我们就可以直接使用numpy,而不必在各个集群节点上单独安装numpy。在下一节中,我们将介绍为特定的notebook创建并使用不同的Docker镜像。
为特定notebook使用自定义Docker镜像
某些工作负载可能要求使用特定的库依赖项版本。为了保证各notebook能够使用不同的Docker镜像,我们首先需要创建一套新的Docker镜像,并将其推送至Amazon ECR。接下来,我们将notebook配置为使用这套新镜像,而非默认的pyspark-latest镜像。
请完成以下操作步骤:
- 使用特定
numpy版本(1.17.5)创建新的DOckerfile: - 使用以下命令创建一个目录,并在其中创建名为
Dockerfile的新文件: - 输入新的Dockerfile内容,并使用以下代码构建Docker镜像:
- 使用以下命令,将在本地构建的镜像标记并上传至Amazon ECR,注意将其中的123456789123.dkr.ecr.us-east-1.amazonaws.com 部分替换为您的Amazon ECR端点:
- 返回EMR Notebook,点击File、New、Notebook而后选择PySpark内核以创建一份新的Notebook。要引导EMR Notebook使用新Docker镜像以替代默认镜像,我们需要使用以下配置参数。
- 在您的notebook中输入以下代码(注意将其中的123456789123.dkr.ecr.us-east-1.amazonaws.com 部分替换为您的Amazon ECR端点),而后选择▸(Run):
- 在notebook中输入以下代码并选择Run:
总结
本文向大家讲解了如何使用Amazon EMR 6.0.0与Docker简化Spark中的依赖项管理流程。我们创建一套Docker镜像以打包现有Python依赖项,创建一个集群并将其设定为使用Docker运行时,而后将创建的Docker镜像与EMR Notebook配合使用以运行PySpark作业。关于将Docker镜像与EMR配合使用的更多详细信息,请参阅EMR说明文档中的使用Amazon EMR 6.0.0运行Spark应用程序部分。另外,也欢迎大家继续关注Apache Spark on Amazon EMR推出的更多新功能与后续改进。