在当今数据驱动业务的时代,大数据已经成为企业业务驱动的利器之一,Amazon EMR 是一个托管集群平台,可简化在 AWS 上运行大数据框架的过程,使组织能够在几分钟内启动具有多个实例的集群,让您能够轻松经济的通过并行处理来处理各种数据工程和商业智能工作负载。在Amazon EMR中,我们经常会用到Apache Hadoop,Apache Spark等大数据框架运行我们的海量数据处理作业,而基于内存计算的Apache Spark框架,毫无疑问在批处理或是流处理领域都是EMR中最热门的点选组件之一。面向企业数据工程师,我们可能需要一两天学习并编写完我们的第一个Spark作业,而针对Spark的作业进行调整和优化则拥有不断完善的空间。 本文将通过一次Spark作业的调优实践,测试不同参数和配置下的作业运行效果,深入的解读EMR中运行Spark多项重要配置参数意义,这些参数将影响包括性能优化,资源分配,成本降低,编码/配置作业中的常见错误等。
实践中,我们将以150G的TXT格式公开数据集作为测试对象,使用Amazon EC2下载并将数据导入到Amazon S3,使用Amazon EMR集群运行Apache Spark进行数据处理,我们也将在该环节进行多种配置参数的调测并重点展开。
下载测试数据
首先,我们使用一台Amazon EC2从FreddieMac下载测试数据,FreddieMac提供了美国单亲家庭购房贷款的近20年的历史数据,可免费用于非商业的学术/研究性工作,原始数据包含50多个属性近250亿条数据,经过我们处理的数据还可以进行机器学习等其他尝试。我准备了简单的Python遍历脚本去自动下载并解压数据集,这里我们使用1999年至2019年20年的数据测试,代码如下,在main方法中需要我们在FreddieMac注册并在代码中填入您的账号,也可以在这里依据需要测试的数据大小定义历史数据起始年份。
#!/usr/bin/env python
# coding: utf-8
from urllib.request import urlopen
from bs4 import BeautifulSoup
from zipfile import ZipFile
from io import BytesIO
import requests
import os
def payloadCreation(user, password):
creds={'username': user,'password': password }
return creds
def getFilesFromFreddieMac(payload, startY, endY):
# 定义要遍历URL.
url='https://freddiemac.embs.com/FLoan/secure/auth.php'
postUrl='https://freddiemac.embs.com/FLoan/Data/download.php'
# 定义本地下载到本地文件夹.
target_folder = 'TestData'
# 定义session,进行登录.
s = requests.Session()
preUrl = s.post(url, data=payload)
payload2={'accept': 'Yes','acceptSubmit':'Continue','action':'acceptTandC'}
finalUrl=s.post(postUrl,payload2)
# 定义遍历目标压缩包.
linkhtml =finalUrl.text
allzipfiles=BeautifulSoup(linkhtml, "html.parser>)
ziplist=allzipfiles.find_all('a')
# 定义年份变量.
year_list = []
start_year = startY
end_year = endY
for i in range(int(start_year),int(end_year)+1):
year_list.append(str(i))
# 拼出最终下载链接.
historicaldata_links=[]
local_path=str(os.getcwd())+"/" + target_folder
for year in year_list:
for li in ziplist:
if year in li.text and 'historical' in li.text:
final_link ='https://freddiemac.embs.com/FLoan/Data/' + li.get('href')
print(final_link)
historicaldata_links.append(final_link)
# 循环下载和解压.
for lin in historicaldata_links:
r = s.get(lin)
z = ZipFile(BytesIO(r.content))
z.extractall(local_path)
print('.’)
def main():
print("Starting")
start_year = '1999'
end_year = '2019'
user = 'xxxx@xxxx.com'
password = 'xxxxxx'
payload=payloadCreation(user,password)
getFilesFromFreddieMac(payload, start_year, end_year)
if __name__ == '__main__':
main()
下载完成后,我们顺序使用以下命令将数据移动到S3:
sudo aws s3 mv /home/<-your path->/TestData/ s3://<-your backet->/aquisition/ --recursive --exclude "*" --include "historical_data1_Q*"
sudo aws s3 mv /home/<-your path->/TestData/ s3://<-your backet->/performance/ --recursive --exclude "*" --include "historical_data1_time_*"
加载完毕后原始数据集在S3中保存如下: 

启动测试环境
现在我们去启动EMR,测试环境在AWS美国东部(弗吉尼亚北部)区域。众所周知,Apache Spark 是一个开源、快速、通用的集群计算框架,广泛应用于大数据的分布式处理。Apache Spark有别于MapReduce,Spark作业在集群内跨节点内存中执行并行计算,以减少任务与磁盘的 I/O ,大大缩短了执行时间。AWS提供了诸多针对内存进行了优化的内存优化型实例可供我们选择。EMR还提供了多种实例采购方式供我们不同的作业类型选择。合适的选择将大大帮助我们节省集群成本,例如,选择Spot实例的成本将可能是按需类实例成本的10%。在这里可以查看更多EMR on EC2 Spot的信息。本实践中,我们选择5台r5.4xlarge实例进行测试,同时使用Spot计费方式搭建集群以节省成本。下图可以看出,我们的实例类型Spot计费类型目前可以节省近80%成本。 
在AWS 控制台中依次点击 服务 –>EMR –>创建集群 –>转到高级模式 即来到创建集群页面,在编辑软件设置中,我们填入任何集群初始化参数,我们也可以在建设集群之后再进行参数的补充或修改。现在我们可以先不填写任何参数,点选上Spark,Hadoop,Ganglia即可轻松快速创建本测试需要的大数据环境。 值得注意的是在实例配置页面,我们可以选择需要的实例,配置EBS存储空间。在安全选项页面,我们应该选择EC2 键对,以便于我们可以安全的登录集群节点。 确认创建集群,几分钟后集群创建完成,我们成功登录到Master节点,现在将用于测试的pyspark代码复制到Master节点。在该代码中,我们将原始字符串数据进行格式转换;使用Spark SQL对Performance表数据进行了排序,窗口,UDF等转换逻辑创建出8个过程表,与Acquisition表进行join,最终形成一张61列的结果表。这些数据处理逻辑来自数据集网站的SAS脚本,使用pyspark 进行了重写。我们可以在这里去查看原始数据结构和处理逻辑的介绍。pyspark代码如下:
# Import All Libraries.
from pyspark.sql import SparkSession
from pyspark.conf import SparkConf
from pyspark.sql.types import StructField, StringType, IntegerType, DecimalType, StructType, ArrayType
from pyspark.sql.window import Window
from pyspark.sql.functions import lag, isnull, udf, col, lit, row_number, unix_timestamp, from_unixtime, months_between, count, when, isnull
from pyspark import StorageLevel
if __name__ == '__main__':
spark = SparkSession.builder.appName('data_prep_persist').getOrCreate()
# Define Acquisition Schema.
orig_fields = [StructField('fico', StringType(), True),
StructField('dt_first_pi', StringType(), True),
StructField('flag_fthb', StringType(), True),
StructField('dt_matr', StringType(), True),
StructField('cd_msa', StringType(), True),
StructField('mi_pct', StringType(), True),
StructField('cnt_units', StringType(), True),
StructField('occpy_sts', StringType(), True),
StructField('cltv', StringType(), True),
StructField('dti', StringType(), True),
StructField('orig_upb', StringType(), True),
StructField('ltv', StringType(), True),
StructField('int_rt', StringType(), True),
StructField('channel', StringType(), True),
StructField('ppmt_pnlty', StringType(), True),
StructField('prod_type', StringType(), True),
StructField('st', StringType(), True),
StructField('prop_type', StringType(), True),
StructField('zipcode', StringType(), True),
StructField('id_loan', StringType(), True),
StructField('loan_purpose', StringType(), True),
StructField('orig_loan_term', StringType(), True),
StructField('cnt_borr', StringType(), True),
StructField('seller_name', StringType(), True),
StructField('servicer_name', StringType(), True),
StructField('flag_sc', StringType(), True),
StructField('pre_harp', StringType(), True)]
orig_schema = StructType(fields=orig_fields)
# Define Transaction Schema.
svcg_fields = [StructField('id_loan', StringType(), True),
StructField('period', StringType(), True),
StructField('act_endg_upb', StringType(), True),
StructField('delq_sts', StringType(), True),
StructField('loan_age', StringType(), True),
StructField('mths_remng', StringType(), True),
StructField('repch_flag', StringType(), True),
StructField('flag_mod', StringType(), True),
StructField('cd_zero_bal', StringType(), True),
StructField('dt_zero_bal', StringType(), True),
StructField('new_int_rt', StringType(), True),
StructField('amt_non_int_brng_upb', StringType(), True),
StructField('dt_lst_pi', StringType(), True),
StructField('mi_recoveries', StringType(), True),
StructField('net_sale_proceeds', StringType(), True),
StructField('non_mi_recoveries', StringType(), True),
StructField('expenses', StringType(), True),
StructField('legal_costs', StringType(), True),
StructField('maint_pres_costs', StringType(), True),
StructField('taxes_ins_costs', StringType(), True),
StructField('misc_costs', StringType(), True),
StructField('actual_loss', StringType(), True),
StructField('modcost', StringType(), True),
StructField('stepmod_ind', StringType(), True),
StructField('dpm_ind', StringType(), True),
StructField('eltv', StringType(), True)]
svcg_schema = StructType(fields=svcg_fields)
# UDF to calculate prior_variables.
def calulate_prior_variables(id_loan, New_Int_rt, Period, delq_sts, lag_id, lag2_id, lag_act_endg_upb, lag_delq_sts, \
lag2_delq_sts, lag_period, lag_new_int_rt, lag_non_int_brng_upb):
if lag_id is None:
prior_upb=0
prior_int_rt=New_Int_rt
prior_delq_sts='00'
prior_delq_sts_2='00'
prior_period = 0
prior_frb_upb = 0
else:
prior_delq_sts=lag_delq_sts
if id_loan==lag2_id:
prior_delq_sts_2=lag2_delq_sts
else:
prior_delq_sts_2=None
prior_period=lag_period
prior_upb=lag_act_endg_upb
prior_int_rt=lag_new_int_rt
prior_frb_upb = lag_non_int_brng_upb
if Period is None:
Period=0
if prior_period is None:
prior_period=0
period_diff = Period - prior_period
if delq_sts != 'R':
delq_sts_new = delq_sts
elif delq_sts == 'R' and period_diff == 1 and prior_delq_sts == '5':
delq_sts_new = '6'
elif delq_sts == 'R' and period_diff == 1 and prior_delq_sts == '3':
delq_sts_new = '4'
elif delq_sts == 'R' and period_diff == 1 and prior_delq_sts == '2':
delq_sts_new = '3'
else:
delq_sts_new = None
return prior_delq_sts, prior_delq_sts_2, prior_period, prior_upb, prior_int_rt, prior_frb_upb, delq_sts_new
schema = StructType([
StructField("prior_delq_sts", StringType(), True),
StructField("prior_delq_sts_2", StringType(), True),
StructField("prior_period", IntegerType(), True),
StructField("prior_upb", DecimalType(), True),
StructField("prior_int_rt", DecimalType(), True),
StructField("prior_frb_upb", IntegerType(), True),
StructField("delq_sts_new", StringType(), True)
])
calulate_prior_variables_udf = udf(calulate_prior_variables,schema)
# UDF to calculate UPB.
def calc_upb(act_endg_upb_, prior_upb_, orig_upb_):
if (act_endg_upb_ != 0) & (act_endg_upb_ is not None):
upb = act_endg_upb_
elif (prior_upb_ != 0) & (prior_upb_ is not None):
upb = prior_upb_
else:
upb = orig_upb_
return upb
calc_upb_udf = udf(calc_upb,DecimalType())
# UDF to calculate current_int_rt.
def calc_current_int_rt(new_int_rt, prior_int_rt):
if (new_int_rt != 0) & (new_int_rt is not None):
current_int_rt = new_int_rt
else:
current_int_rt = prior_int_rt
return current_int_rt
calc_current_int_rt_udf = udf(calc_current_int_rt,DecimalType())
# Read input files.
orig_path = 's3a://...path../aquisition/'
orig_df = spark.read.option("delimiter", "|").option("encoding", "UTF-8").schema(orig_schema).csv(orig_path)
svcg_path= 's3a://...path../performance/'
svcg_df = spark.read.option("delimiter", "|").option("encoding", "UTF-8").schema(svcg_schema).csv(svcg_path)
# Typecasting.
orig_df = orig_df.withColumn("fico", orig_df['fico'].cast(IntegerType()))
orig_df = orig_df.withColumn("dt_first_pi", orig_df['dt_first_pi'].cast(IntegerType()))
orig_df = orig_df.withColumn("dt_matr", orig_df['dt_matr'].cast(IntegerType()))
orig_df = orig_df.withColumn("cd_msa", orig_df['cd_msa'].cast(IntegerType()))
orig_df = orig_df.withColumn("mi_pct", orig_df['mi_pct'].cast(IntegerType()))
orig_df = orig_df.withColumn("cnt_units", orig_df['cnt_units'].cast(IntegerType()))
orig_df = orig_df.withColumn("cltv", orig_df['cltv'].cast(DecimalType()))
orig_df = orig_df.withColumn("dti", orig_df['dti'].cast(IntegerType()))
orig_df = orig_df.withColumn("orig_upb", orig_df['orig_upb'].cast(IntegerType()))
orig_df = orig_df.withColumn("ltv", orig_df['ltv'].cast(IntegerType()))
orig_df = orig_df.withColumn("int_rt", orig_df['int_rt'].cast(DecimalType()))
orig_df = orig_df.withColumn("zipcode", orig_df['zipcode'].cast(IntegerType()))
orig_df = orig_df.withColumn("orig_loan_term", orig_df['orig_loan_term'].cast(IntegerType()))
orig_df = orig_df.withColumn("cnt_borr", orig_df['cnt_borr'].cast(IntegerType()))
svcg_df = svcg_df.withColumn("period", svcg_df['period'].cast(IntegerType()))
svcg_df = svcg_df.withColumn("act_endg_upb", svcg_df['act_endg_upb'].cast(DecimalType()))
svcg_df = svcg_df.withColumn("loan_age", svcg_df['loan_age'].cast(IntegerType()))
svcg_df = svcg_df.withColumn("mths_remng", svcg_df['mths_remng'].cast(IntegerType()))
svcg_df = svcg_df.withColumn("cd_zero_bal", svcg_df['cd_zero_bal'].cast(IntegerType()))
svcg_df = svcg_df.withColumn("dt_zero_bal", svcg_df['dt_zero_bal'].cast(IntegerType()))
svcg_df = svcg_df.withColumn("new_int_rt", svcg_df['new_int_rt'].cast(DecimalType()))
svcg_df = svcg_df.withColumn("amt_non_int_brng_upb", svcg_df['amt_non_int_brng_upb'].cast(IntegerType()))
svcg_df = svcg_df.withColumn("dt_lst_pi", svcg_df['dt_lst_pi'].cast(IntegerType()))
svcg_df = svcg_df.withColumn("mi_recoveries", svcg_df['mi_recoveries'].cast(DecimalType()))
svcg_df = svcg_df.withColumn("non_mi_recoveries", svcg_df['non_mi_recoveries'].cast(DecimalType()))
svcg_df = svcg_df.withColumn("expenses", svcg_df['expenses'].cast(DecimalType()))
svcg_df = svcg_df.withColumn("legal_costs", svcg_df['legal_costs'].cast(DecimalType()))
svcg_df = svcg_df.withColumn("maint_pres_costs", svcg_df['maint_pres_costs'].cast(DecimalType()))
svcg_df = svcg_df.withColumn("taxes_ins_costs", svcg_df['taxes_ins_costs'].cast(DecimalType()))
svcg_df = svcg_df.withColumn("misc_costs", svcg_df['misc_costs'].cast(DecimalType()))
svcg_df = svcg_df.withColumn("actual_loss", svcg_df['actual_loss'].cast(DecimalType()))
svcg_df = svcg_df.withColumn("modcost", svcg_df['modcost'].cast(DecimalType()))
svcg_df = svcg_df.withColumn("eltv", svcg_df['eltv'].cast(DecimalType()))
#orig_df.persist(StorageLevel.MEMORY_AND_DISK_SER)
#svcg_df.persist(StorageLevel.MEMORY_AND_DISK_SER)
# Create SVCG Detail Records
# Step-1 >> Drop duplicates and Null Loan-ID if any from both the tables.
orig_df = orig_df.dropDuplicates()
svcg_df = svcg_df.dropDuplicates()
orig_df = orig_df.na.drop(subset='id_loan')
svcg_df = svcg_df.na.drop(subset='id_loan')
# Step-2 >> Create SVCG DETAIL table.
orig_df.createOrReplaceTempView("orig_table")
svcg_df.createOrReplaceTempView("svcg_table")
df1 = (spark.sql("""select distinct a.*, b.orig_upb
from svcg_table a, orig_table b
where a.id_loan = b.id_loan
order by a.Id_loan"""))
# Step-3 >> Define WINDOW and Create LAG variables.
window = Window.partitionBy("id_loan").orderBy("period")
lagid = lag("id_loan", 1).over(window)
lag2id = lag("id_loan", 2).over(window)
lagactendgupb = lag("act_endg_upb", 1).over(window)
lagdelqsts = lag("delq_sts", 1).over(window)
lag2delqsts = lag("delq_sts", 2).over(window)
lagperiod = lag("period", 1).over(window)
lagnewintrt = lag("new_Int_rt", 1).over(window)
lagnonintbrngupb = lag("amt_non_int_brng_upb", 1).over(window)
df2 = df1.withColumn("lag_id_", lagid) \
.withColumn("lag2_id_", lag2id) \
.withColumn("lag_act_endg_upb_", lagactendgupb) \
.withColumn("lag_delq_sts_", lagdelqsts) \
.withColumn("lag2_delq_sts_", lag2delqsts) \
.withColumn("lag_period_", lagperiod) \
.withColumn("lag_new_int_rt_", lagnewintrt) \
.withColumn("lag_non_int_brng_upb_", lagnonintbrngupb)
# Step-4 >> Order by loan_id and period.
df3 = df2.orderBy('id_loan','period')
# Step-5 >> Calculate prior variables using pre-defined UDF.
df4 = df3.withColumn("prior", calulate_prior_variables_udf(col("id_loan"), col("new_int_rt"), col("period"), col("delq_sts"), \
col("lag_id_"), col("lag2_id_"), col("lag_act_endg_upb_"), \
col("lag_delq_sts_"), col("lag2_delq_sts_"), col("lag_period_"), \
col("lag_new_int_rt_"), col("lag_non_int_brng_upb_")))
# Step-6 >> Drop temporary lag variables.
svcg_dtls = df4.drop("lag_act_endg_upb_", "lag2_id_", "lag_delq_sts_", "lag2_delq_sts_", "lag_period_", "lag_new_int_rt_")
#svcg_dtls.persist(StorageLevel.MEMORY_AND_DISK_SER)
# Create a TempView for svcg_dtls.
svcg_dtls.createOrReplaceTempView("svcg_dtls_table")
# Create Terminated Records
# Step-1 >> Select all the records from SVCG DETAILS file.
trm_rcd = (spark.sql("""SELECT * FROM svcg_dtls_table ORDER BY id_loan, period"""))
trm_rcd = trm_rcd \
.withColumnRenamed("id_loan","t_id_loan") \
.withColumnRenamed("period","t_period") \
.withColumnRenamed("current_int_rt","t_current_int_rt") \
.withColumnRenamed("repch_flag","t_repch_flag") \
.withColumnRenamed("cd_zero_bal","t_cd_zero_bal") \
.withColumnRenamed("dt_zero_bal","t_dt_zero_bal") \
.withColumnRenamed("new_int_rt","t_new_int_rt") \
.withColumnRenamed("expenses","t_expenses") \
.withColumnRenamed("mi_recoveries","t_mi_recoveries") \
.withColumnRenamed("non_mi_recoveries","t_non_mi_recoveries") \
.withColumnRenamed("net_sale_proceeds","t_net_sale_proceeds") \
.withColumnRenamed("actual_loss","t_actual_loss") \
.withColumnRenamed("legal_costs","t_legal_costs") \
.withColumnRenamed("taxes_ins_costs","t_taxes_ins_costs") \
.withColumnRenamed("maint_pres_costs","t_maint_pres_costs") \
.withColumnRenamed("misc_costs","t_misc_costs") \
.withColumnRenamed("modcost","t_modcost") \
.withColumnRenamed("dt_lst_pi","t_dt_lst_pi") \
.withColumnRenamed("id_delq_sts","t_delq_sts") \
.withColumnRenamed("delq_sts","t_delq_sts") \
.withColumnRenamed("cd_zero_bal","t_cd_zero_bal") \
.withColumnRenamed("act_endg_upb","t_act_endg_upb") \
.withColumnRenamed("prior","t_prior") \
.withColumnRenamed("orig_upb","t_orig_upb")
# Step-2 >> Create a window by loan-id. Select last period record by ordering in descending manner and selecting first row.
w = Window.partitionBy("t_id_loan").orderBy(trm_rcd["t_period"].desc())
trm_rcd = trm_rcd.withColumn("row",row_number().over(w)).filter("row == 1").drop("row")
# Step-3 >> Select records with respect to value of cd_zero_bal.
trm_rcd = trm_rcd.filter((trm_rcd['t_cd_zero_bal'] >=3 ) & (trm_rcd['t_cd_zero_bal'] <= 9))
# Step-4 >> calculate default-upb.
trm_rcd = trm_rcd.withColumn("t_default_upb", calc_upb_udf(col("t_act_endg_upb"), col("t_prior.prior_upb"), col("t_orig_upb")))
# Step-5 >> create terminated records after calulating current interest rate.
trm_rcd = trm_rcd.withColumn("t_current_int_rt", calc_current_int_rt_udf(col("t_new_int_rt"), col("t_prior.prior_int_rt")))
#trm_rcd.persist(StorageLevel.MEMORY_AND_DISK_SER)
pop_1 = spark.sql("""select a.id_loan, a.act_endg_upb, a.prior.*, a.orig_upb, 1 as p1_dlq_ind
from svcg_dtls_table a , (select id_loan, min(period) as min_period from svcg_dtls_table group by id_loan) b
where a.id_loan=b.id_loan and a.period=b.min_period""")
pop_1 = pop_1 \
.withColumnRenamed("id_loan","p1_id_loan") \
.withColumnRenamed("act_endg_upb","p1_act_endg_upb") \
.withColumnRenamed("prior_upb","p1_prior_upb") \
.withColumnRenamed("orig_upb","p1_orig_upb")
pop_1 = pop_1.dropDuplicates()
pop_1 = pop_1.orderBy("p1_id_loan")
pop_1 = pop_1.withColumn("p1_dlq_upb", calc_upb_udf(col("p1_act_endg_upb"), col("p1_prior_upb"), col("p1_orig_upb")))
#pop_1.persist(StorageLevel.MEMORY_AND_DISK_SER)
pop_2 = spark.sql("""select a.id_loan, a.act_endg_upb, a.prior.*, a.orig_upb, 2 as p2_dlq_ind
from svcg_dtls_table a , (select id_loan, min(period) as min_period from svcg_dtls_table group by id_loan) b
where a.id_loan=b.id_loan and a.period=b.min_period""")
pop_2 = pop_2 \
.withColumnRenamed("id_loan","p2_id_loan") \
.withColumnRenamed("act_endg_upb","p2_act_endg_upb") \
.withColumnRenamed("prior_upb","p2_prior_upb") \
.withColumnRenamed("orig_upb","p2_orig_upb")
pop_2 = pop_2.dropDuplicates()
pop_2 = pop_2.orderBy("p2_id_loan")
pop_2 = pop_2.withColumn("p2_dlq_upb", calc_upb_udf(col("p2_act_endg_upb"), col("p2_prior_upb"), col("p2_orig_upb")))
#pop_2.persist(StorageLevel.MEMORY_AND_DISK_SER)
pop_3 = spark.sql("""select a.id_loan, a.act_endg_upb, a.prior.*, a.orig_upb, 3 as p3_dlq_ind
from svcg_dtls_table a , (select id_loan, min(period) as min_period from svcg_dtls_table group by id_loan) b
where a.id_loan=b.id_loan and a.period=b.min_period""")
pop_3 = pop_3 \
.withColumnRenamed("id_loan","p3_id_loan") \
.withColumnRenamed("act_endg_upb","p3_act_endg_upb") \
.withColumnRenamed("prior_upb","p3_prior_upb") \
.withColumnRenamed("orig_upb","p3_orig_upb")
pop_3 = pop_3.dropDuplicates()
pop_3 = pop_3.orderBy("p3_id_loan")
pop_3 = pop_3.withColumn("p3_dlq_upb", calc_upb_udf(col("p3_act_endg_upb"), col("p3_prior_upb"), col("p3_orig_upb")))
#pop_3.persist(StorageLevel.MEMORY_AND_DISK_SER)
pop_4 = spark.sql("""select a.id_loan, a.act_endg_upb, a.prior.*, a.orig_upb, 4 as p4_dlq_ind
from svcg_dtls_table a , (select id_loan, min(period) as min_period from svcg_dtls_table group by id_loan) b
where a.id_loan=b.id_loan and a.period=b.min_period""")
pop_4 = pop_4 \
.withColumnRenamed("id_loan","p4_id_loan") \
.withColumnRenamed("act_endg_upb","p4_act_endg_upb") \
.withColumnRenamed("prior_upb","p4_prior_upb") \
.withColumnRenamed("orig_upb","p4_orig_upb")
pop_4 = pop_4.dropDuplicates()
pop_4 = pop_4.orderBy("p4_id_loan")
pop_4 = pop_4.withColumn("p4_dlq_upb", calc_upb_udf(col("p4_act_endg_upb"), col("p4_prior_upb"), col("p4_orig_upb")))
#pop_4.persist(StorageLevel.MEMORY_AND_DISK_SER)
pop_6 = spark.sql("""select a.id_loan, a.act_endg_upb, a.prior.*, a.orig_upb, 6 as p6_dlq_ind
from svcg_dtls_table a , (select id_loan, min(period) as min_period from svcg_dtls_table group by id_loan) b
where a.id_loan=b.id_loan and a.period=b.min_period""")
pop_6 = pop_6 \
.withColumnRenamed("id_loan","p6_id_loan") \
.withColumnRenamed("act_endg_upb","p6_act_endg_upb") \
.withColumnRenamed("prior_upb","p6_prior_upb") \
.withColumnRenamed("orig_upb","p6_orig_upb")
pop_6 = pop_6.dropDuplicates()
pop_6 = pop_6.orderBy("p6_id_loan")
pop_6 = pop_6.withColumn("p6_dlq_upb", calc_upb_udf(col("p6_act_endg_upb"), col("p6_prior_upb"), col("p6_orig_upb")))
#pop_6.persist(StorageLevel.MEMORY_AND_DISK_SER)
# CREATE D180 INSTANCES
d180_temp = (spark.sql("""SELECT * FROM svcg_dtls_table ORDER BY id_loan, period"""))
d180 = d180_temp.filter(d180_temp['prior.delq_sts_new'] == 6)
d180 = d180.orderBy('id_loan','period')
# CREATE Pre D180 INSTANCES
pre180_temp = (spark.sql("""SELECT * FROM svcg_dtls_table ORDER BY id_loan, period"""))
pre_d180 = pre180_temp.drop(((pre180_temp['prior.delq_sts_new'] >= 6) & (pre180_temp['cd_zero_bal'] == 3)) | \
((pre180_temp['prior.delq_sts_new'] >= 6) & (pre180_temp['delq_sts'] == 'R')))
pre_d180 = pre_d180.orderBy('id_loan','period')
# Merge D180 and Pre-D180 instances.
d180_pr = d180.union(pre_d180)
d180_pr = d180_pr.dropDuplicates()
d180_pr = d180_pr.orderBy("id_loan")
# Process merged records.
d180_pr.createOrReplaceTempView("d180_pr_tab")
pd_180 = (spark.sql("""select a.id_loan, a.act_endg_upb, a.orig_upb, a.prior.*
from d180_pr_tab a, (select id_loan, min(period) as min_period from d180_pr_tab group by id_loan) b
where a.id_loan=b.id_loan and a.period=b.min_period"""))
pd_180 = pd_180 \
.withColumnRenamed("id_loan","pd180_id_loan") \
.withColumnRenamed("act_endg_upb","pd180_act_endg_upb") \
.withColumnRenamed("prior_upb","pd180_prior_upb") \
.withColumnRenamed("orig_upb","pd180_orig_upb") \
pd_180 = pd_180.withColumn("pd180_d180_upb", calc_upb_udf(col("pd180_act_endg_upb"), col("pd180_prior_upb"), col("pd180_orig_upb")))
pd_180 = pd_180.withColumn("pd180_d180_ind", lit(1))
#pd_180.persist(StorageLevel.MEMORY_AND_DISK_SER)
# CREATE MODIFIED RECORDS
# Create a dataset containing Modified records.
mod_loan = (spark.sql("""SELECT distinct a.id_loan, a.period, a.act_endg_upb, a.orig_upb, a.prior.*
FROM svcg_dtls_table a , (SELECT id_loan FROM svcg_dtls_table WHERE flag_mod='Y' ) b
WHERE a.id_loan = b.id_loan
ORDER BY a.id_loan, a.period"""))
# Create a mod indicator.
mod_loan = mod_loan.withColumn("mod_ind", lit(1))
# Order by loan-id and period.
mod_loan = mod_loan.orderBy('id_loan','period')
# Select First modified record.
w = Window.partitionBy("id_loan").orderBy("period")
mod_loan = mod_loan.withColumn("row",row_number().over(w)).filter("row == 1").drop("row")
mod_loan = mod_loan \
.withColumnRenamed("id_loan","mod_id_loan") \
.withColumnRenamed("act_endg_upb","mod_act_endg_upb") \
.withColumnRenamed("prior_upb","mod_prior_upb") \
.withColumnRenamed("orig_upb","mod_orig_upb")
mod_loan = mod_loan.withColumn("mod_upb", calc_upb_udf(col("mod_act_endg_upb"), col("mod_prior_upb"), col("mod_orig_upb")))
#mod_loan.persist(StorageLevel.MEMORY_AND_DISK_SER)
# Define SQL tables to be joined later.
orig_df.createOrReplaceTempView("orig_tab")
trm_rcd.createOrReplaceTempView("trm_rcd_tab")
pop_1.createOrReplaceTempView("pop_1_tab")
pop_2.createOrReplaceTempView("pop_2_tab")
pop_3.createOrReplaceTempView("pop_3_tab")
pop_4.createOrReplaceTempView("pop_4_tab")
pop_6.createOrReplaceTempView("pop_6_tab")
pd_180.createOrReplaceTempView("pd_d180_tab")
mod_loan.createOrReplaceTempView("mod_loan_tab")
# LAST STEP >> JOIN ALL TABLES
final = (spark.sql( """select
o.*,
t.t_current_int_rt,
t.t_repch_flag,
t.t_cd_zero_bal,
t.t_dt_zero_bal as zero_bal_period,
t.t_expenses,
t.t_mi_recoveries,
t.t_non_mi_recoveries,
t.t_net_sale_proceeds,
t.t_actual_loss,
t.t_legal_costs,
t.t_taxes_ins_costs as maint_pres_costs,
t.t_maint_pres_costs as taxes_ins_costs,
t.t_misc_costs,
t.t_modcost,
t.t_dt_lst_pi,
t.t_delq_sts as zero_bal_delq_sts,
(case when t.t_cd_zero_bal in ('01','06') then 1 end) as prepay_count,
(case when t.t_cd_zero_bal in ('03','09') then 1 end) as default_count,
(case when t.t_cd_zero_bal in ('01','06') then t.t_prior.prior_upb end) as prepay_upb,
(case when t.t_cd_zero_bal in ('') then t.t_act_endg_upb end) as rmng_upb,
p1.p1_dlq_ind as dlq1_ever30_ind,
p1.p1_dlq_upb as dlq1_ever30_upb,
p2.p2_dlq_ind as dlq2_ever60_ind,
p2.p2_dlq_upb as dlq2_ever60_upb,
p3.p3_dlq_ind as dlq3_everd90_ind,
p3.p3_dlq_upb as dlq3_everd90_upb,
p4.p4_dlq_ind as dlq4_everd120_ind,
p4.p4_dlq_upb as dlq4_everd120_upb,
p6.p6_dlq_ind as dlq6_everd180_ind,
p6.p6_dlq_upb as dlq6_everd180_upb,
n.pd180_d180_ind as pd_d180_ind,
n.pd180_d180_upb as pd_d180_upb,
m.mod_ind as mod_ind,
m.mod_upb as mod_upb
from orig_tab o
left join trm_rcd_tab t on o.id_loan = t.t_id_loan
left join pop_1_tab p1 on o.id_loan = p1.p1_id_loan
left join pop_2_tab p2 on o.id_loan = p2.p2_id_loan
left join pop_3_tab p3 on o.id_loan = p3.p3_id_loan
left join pop_4_tab p4 on o.id_loan = p4.p4_id_loan
left join pop_6_tab p6 on o.id_loan = p6.p6_id_loan
left join pd_d180_tab n on o.id_loan = n.pd180_id_loan
left join mod_loan_tab m on o.id_loan = m.mod_id_loan
order by o.id_loan
"""))
# Save final output file.
finalOut = "s3a://...path..../....path../"
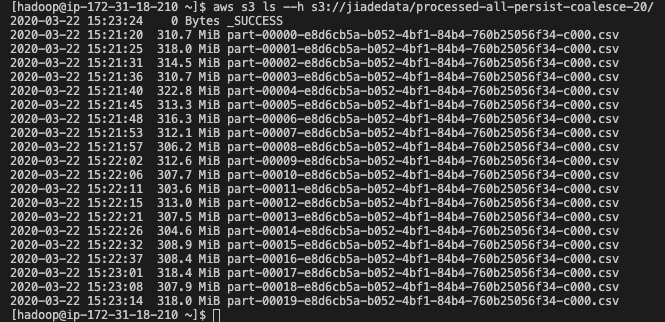
final.coalesce(20).write.option("delimiter", "|").option("header", "true").mode("overwrite").csv(finalOut)
# Save final output file(Parquet).
# final.coalesce(10).write.option("delimiter", "|").option("header", "true").mode("overwrite").parquet(finalOut)
orig_df.unpersist()
svcg_df.unpersist()
svcg_dtls.unpersist()
trm_rcd.unpersist()
pop_1.unpersist()
pop_2.unpersist()
pop_3.unpersist()
pop_4.unpersist()
pop_6.unpersist()
pd_180.unpersist()
mod_loan.unpersist()
使用默认参数提交作业与常见报错
我们现在直接使用spark-submit spark.py 提交作业进行测试,由于我们没有填写任何参数,执行脚本将去调用EMR默认参数:
Amazon EMR 设置的 Spark 默认值
|
设置
|
描述
|
值
|
| spark.executor.memory |
每个执行者进程要使用的内存量。(例如,1g、2g) |
基于集群中的核心和任务实例类型配置设置。 |
| spark.executor.cores |
要对每个执行程序使用的内核的数量。 |
基于集群中的核心和任务实例类型配置设置。 |
| spark.dynamicAllocation.enabled |
是否使用动态资源分配,这将基于工作负载增大和减小注册到应用程序的执行程序的数目。 |
true (emr-4.4.0 或更高版本) |
| 注意Spark Shuffle Service 自动由 Amazon EMR 配置 |
作业运行半小时后,发生如下报错:
ERROR FileFormatWriter : ExecutorLostFailure Reason: Container killed by YARN for exceeding memory limits.
22.0 GB of 22 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead or disabling yarn.
nodemanager.vmem-check-enabled because of YARN-4714.
 在
在
Spark作业中,内存相关进程被终止,out of memory的报错时有发生。常见的报错信息如:
ExecutorLostFailure (executor 9 exited caused by one of the running tasks) Reason: Container killed by YARN for exceeding memory limits.
22.1 GB of 22 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead
or disabling yarn.nodemanager.vmem-check-enabled because of YARN-4714.
WARN TaskSetManager: Loss was due to
java.lang.OutOfMemoryError
java.lang.OutOfMemoryError: Java heap
WARN CacheManager:71 - Not enough space to cache partition rdd_1_1 in memory! Free memory is 278099801 bytes.
ncaught error from thread [spark-akka.actor.default-dispatcher-3]
shutting down JVM since 'akka.jvm-exit-on-fatal-error' is enabled for ActorSystem[spark]
发生OOM大多数情况是因为使用者对Spark作业和内存管理的不理解,而理解了内存管理的机制,并结合我们自身任务情况进行参数的评估不光能保障任务不会OOM,也是我们的任务能充分利用资源,实现性能优化的关键环节。现在我们来了解Spark的内存管理。
在Spark的定义中,我们的作业会以一个行动算子为单位拆分成不同的Job。Job 根据RDD之几间的依赖关系分成不同的Stage。每个Stage里包含若干个Task,Task是Spark中运行计算的具体单位,调度器会为它提供计算的资源并分配它计算哪些数据。
资源上,Task会以一个vCPU为单位被调度到executor中执行,executor将使用默认或我们配置的资源配置参数,如executor的数量,executor内存大小,executor CPU数量等。
数据上,即是去指定一个Task要处理的数据量,Task会依据我们配置或默认的的任务并行度参数在Stage中要处理的全部数据中拿到相应的切分数据量。
那么针对一个executor来说,最大并行处理的Task数量是它的vCPU数量,每个Task的数据量是我们总数据量除以Task的并行度参数。这些就会关系到我们executor的内存是否够用。例如一个executor被定义的内存很小,并行了多个数据量很大的Task做shuffle读写,很自然会内存溢出。Executor针对不同职能进行了细颗粒度的内存空间定义和划分,下图描述了一个executor的默认划分情况。

- 堆外内存 (Overhead memory):存放共享库、Memory mapping、Perm Space、线程Stack;
- 执行内存 (Executor Memory) :存放 Shuffle、Join、Sort、Aggregation 等计算过程中的临时数据;
- 存储内存 (Storage Memory) :存放 Spark 的 cache 数据,例如RDD的缓存、unroll数据;
- 用户内存(User Memory):存放 RDD 转换操作所需要的数据,例如 RDD 依赖等信息;
- 预留内存(Reserved Memory): 存放Spark内部对象系统预留内存.
包括上面提到的数量、大小、比例都是直接影响作业是否能正常运行,是否充分利用可用资源的重要参数,我们将常用参数归纳如下:
--driver-memory : driver内存大小
--executor-memory : 每个executor的内存
--num-executors : 总共申请的executor数目
--executor-cores : 每个executor内的核数,即每个executor中的可并行的任务task数
--spark.default.parallelism : join、reduceByKey、parallelize等转换返回RDD中的默认分区数
--spark.sql.shuffle.partitions:sparks SQL join、聚合等进行数据shuffling会使用的分区数
--spark.dynamicAllocation.enabled : 设置是否开启动态资源配置
--spark.executor.memoryOverhead : 分配给每个executor的堆外内存量
影响作业内存的更多参数可以在Spark官网参数说明找到。
发生内存报错可以考虑自身的作业情况进行作业参数调整,包括:
<spark.driver/executor.memoryOverhead>可设置分配给每个executor的堆外内存量。默认情况下,内存开销被设置为executor内存的 10% 或 384,以较高者为准。内存开销用于 Java NIO 直接缓冲区、线程堆栈、共享本机库或内存映射文件,在处理较大数据量的作业中,该参数常常因为配比较低而引发报错。可以将该值调整为2g-4g,但要注意保障<spark.driver/executor.memory + spark.driver/executor.memoryOverhead 小于 yarn.nodemanager.resource.memory-mb>
该参数代表一个stage将要处理的数据分成多少分区,每个分区会交给一个task处理,由<spark.default.parallelism和spark.sql.shuffle.partitions>两个参数指定,增加分区数量可减少每个task所需的内存量。这是较为直接避免OOM以及提高效率的参数
减少executor核心数等于减小executor最大并行任务数量,从而减少所需的内存量。这往往是为了保障作业成功运行适当降低集群整体资源利用率的手段。
考虑增加driver和executor的内存,但不能超过<yarn.nodemanager.resource.memory-mb>的值。可以考虑更换集群实例去解决问题。
计算最优资源配置
在我们的作业中有较大的数据处理量,下面观察我们的集群配置并计算参数值:
- 统计节点资源:在我们的环境中使用了4台的4xlarge实例,每台实例具有16个vCPU,128 GB RAM。但在计划我们可支配的使用率时应该排除额外的资源占用,可以通过YARN资源控制器或在这里查看到节点可支配内存为120G,我们为每个节点操作系统保留一个vCPU核心(16–1 = 15核),我们可以分配的资源为4台实例各15核,120G内存。依据资源我们可以统计出以下多种vCPU和内存的配比组合:
组合1: (7 GB + 1 core) -> 15 * 4 = 60 executors
组合2: (14 GB + 2 cores) -> 7 * 4 = 28 executors
组合3: (18 GB + 3 cores) -> 5 * 4= 20 executors
组合4: (30 GB + 5 cores) -> 3 * 4 = 12 executors
组合5: (100 GB + 15cores) -> 1 * 4 = 4 executors
我们比较几种组合的优劣势:
|
组合1–微型executors
|
组合5–大型executors
|
组合3–中型executors
|
优缺点
|
✔️ 可以很好的支持密集的小型计算任务 *降低同一个JVM 个中并发度 *广播变量将被复制每个节点15次 * Hadoop的进程将争抢资源 *在大型集群中会打开太多传输连接 |
✔️很好的支持集群中不需要交互的计算,例如大小表的Join,map side等
*与存储端交互的吞吐量下降明显,例如HDFS客户端的并发线程。通常每次执行大约五个任务,可以实现全写吞吐量。
*将导致过多的垃圾收集延迟
|
✔️为执行者和存储进程提供足够的内存
✔️平衡兼顾:大executer的并行性和微型executer的最佳吞吐量。
✔️由于减少了集群相互连接,相对减少数据传输。
|
针对我们的作业任务,不存在密集和集中的场景,我们可以选择组合3进行测试,计算方式如下:
- 每个实例的Executor数量 =(每个实例的vCPU总数-1)/ 每个Executor具有3个内核实例内核,我们每个实例可以有5个执行程序(16–1)/ 3 = 5 . 我们的集群有4个核心节点,则 num-executors = 5 * 4 = 20。
- 将executor.memory设置为18 GB 在我们的情况下验算:<spark.driver/executor.memory + spark.driver/executor.memoryOverhead 小于 yarn.nodemanager.resource.memory-mb> :(18 +(0.1 * 18))* 5 = 99GB < 120GB(实例可用内存)
 下面考虑数据的分区数,大部分情况下Spark官方文档中推荐每个CPU core设定2~3个Task,这样将待处理的数据量拆小可以保障一个Task完成后连续的加载下一个Task,因此这个值要设定为(num-executors * executor-cores)的2~3倍。此参数非常重要,不经设定的默认值分区数将由RDD本身的分区去决定,造成较大内存溢出的风险和效率的降低。并且较大的分区数可以把任务分解得更均衡,有效的降低数据倾斜。我们设定为400进行测试。那么我们所计算出的参数为:
下面考虑数据的分区数,大部分情况下Spark官方文档中推荐每个CPU core设定2~3个Task,这样将待处理的数据量拆小可以保障一个Task完成后连续的加载下一个Task,因此这个值要设定为(num-executors * executor-cores)的2~3倍。此参数非常重要,不经设定的默认值分区数将由RDD本身的分区去决定,造成较大内存溢出的风险和效率的降低。并且较大的分区数可以把任务分解得更均衡,有效的降低数据倾斜。我们设定为400进行测试。那么我们所计算出的参数为:
–num-executors 20
–executor-memory 18g
–spark.executor.cores=3
–spark.sql.shuffle.partitions=400
–spark.default.parallelism=400
现在使用我们计算过的参数再次进行测试,提交作业:
spark-submit --num-executors 20 --executor-memory 18g
--conf spark.executor.cores=3 --conf spark.sql.shuffle.partitions=400
--conf spark.default.parallelism=400 --conf spark.dynamicAllocation.enabled=false spark_no_persist.py
另外,如果我们不便对集群和任务的参数值进行计算时候和默认配置时,可以将maximizeResourceAllocation 参数设定为开启。此参数为Amazon EMR 特定的选项,他将计算在核心实例组中的实例上执行程序可用的最大计算和内存资源。然后在spark默认配置中设置这些参数。这将提供我们更优化的默认参数配置,我们可以基于此默认参数针对作业进行再调整,其计算规则如下:
启用 spark-defaults时在 maximizeResourceAllocation 中配置的设置
|
设置
|
描述
|
值
|
| spark.default.parallelism |
在用户未设置的情况下由转换 (如联接、reduceByKey 和并行化) 返回的 RDD 中的分区数。 |
对 YARN 容器可用的 CPU 内核数的 2 倍。 |
| spark.driver.memory |
要用于驱动程序进程(即初始化 SparkContext)的内存量。(例如,1g、2g)。 |
基于集群中的实例类型配置设置。但是,由于 Spark 驱动程序可在主实例或某个核心实例 (例如,分别在 YARN 客户端和集群模式中) 上运行,因此将根据这两个实例组中的实例类型的较小者进行设置。 |
| spark.executor.memory |
每个执行者进程要使用的内存量。(例如,1g、2g) |
基于集群中的核心和任务实例类型配置设置。 |
| spark.executor.cores |
要对每个执行程序使用的内核的数量。 |
基于集群中的核心和任务实例类型配置设置。 |
| spark.executor.instances |
执行程序数。 |
基于集群中的核心和任务实例类型配置设置。除非同时将 spark.dynamicAllocation.enabled 显式设置为 true,否则将设置。 |
经过计算的基本参数spark.default.parallelism 默认值将被设置为集群可用虚拟核心数的 2 倍,对于数据量较大的作业,提交作业时可以将它调高(Spark参数优先级:SparkConf > CLI > spark-defaults.conf)。同时在Amazon EMR 4.4或以上版本中,集群默认开启了spark动态资源调度功能spark.dynamicAllocation.enabled ,这将在作业中自动设定executor的数量。我们也可以使用动态分配是否会影响作业中其他可能存在的作业,依据不同集群情况可以定义动态资源调度开启和关闭、自动调度executor的最大值和最小值。例如
| spark.shuffle.service.enabled |
true |
打开External Shuffle Service服务 |
| spark.dynamicAllocation.enabled |
true |
打开Spark动态资源调度 |
| spark.dynamicAllocation.minExecutors |
1 |
每个应用中最少executor的个数 |
| spark.dynamicAllocation.maxExecutors |
15 |
每个应用中最多executor的个数 |
| spark.shuffle.service.port |
7337 |
Shuffle服务监听数据获取请求的端口 |
回到我们的作业,EMR提供了便捷版本的Spark UI直接集成到EMR console里,我们可以方便的查看任务状态:  可以看见Spark已经按照我们的配置参数进行工作:
可以看见Spark已经按照我们的配置参数进行工作: 
Executor=20 + AM =1

整个作业进行了4.5小时并返回成功。 

我们通过Ganglia验证查看资源的使用统计是相对饱满的: 
验证查看代码中S3的目的路径已经如我们的预想将结果表切片生成了20个文件。 
RDD持久化
但是整整4.5小时的作业时间存在太多优化空间。第一大效率降低的原因是我们的代码中没有将数据进行持久化。现在我们进行数据持久化的性能对比测试。 RDD是 Spark 最基础的数据抽象,可以被创建在存储上或者通过其他存在的的 RDD 执行转换产生一个新的 RDD。转换后的 RDD 与最初的 RDD之间产生的依赖关系(DAG),凭借依赖关系记录,Spark 保障每一个 RDD 都可以被重新恢复。但 RDD 的转换算子被定义为惰性算子,只有遇到行动算子Spark 才会创建任务读取RDD,执行我们定义的操作。而Task 启动的第一个任务就是先判断这个分区是否已有持久化或Checkpoint数据,如果没有将找到依赖关系记录进行重新计算,这将大大降低我们的执行效率。所以如果数据需要进行多次的处理和计算,可以在第一次行动中使用 persist 或 cache 方法,在内存或磁盘中持久化或缓存这个 RDD,大大提升后续的计算任务效率。 Spark提供了多种可以选择持久化的方式如下:
持久化级别
|
描述
|
| MEMORY_ONLY |
将RDD作为非序列化的Java对象存储在JVM中。如果RDD的partition不能全部存在内存中,则会造成某些partition不被缓存,每次需要时进行重新进行计算。这是默认的持久化级别。 |
| MEMORY_AND_DISK |
将RDD作为非序列化的Java对象存储在JVM中。如果RDD的partition不能全部存在内存中,将存储这些partition到磁盘上,需要时从磁盘读取 |
| MEMORY_ONLY_SER |
将RDD存储为序列化的Java对象(每个分区一个字节数组)。通常,这比反序列化的对象更节省空间,尤其是在使用快速序列化程序时,但读取时会占用更多的CPU。 |
| MEMORY_AND_DISK_SER |
雷同于MEMORY_ONLY_SER, 但内存中放不下的存储到磁盘中. |
| DISK_ONLY |
完全使用磁盘存储RDD |
| MEMORY_ONLY_2, MEMORY_AND_DISK_2, etc. |
与上面的级别相同,但是在两个群集节点上复制每个partition,若有节点丢失可以去复制的节点取数据。 |
理论上大多数情况可以选择MEMORY_AND_DISK_SER,但也要评估我们的作业任务因地制宜。如假设我们的计算任务只做数据转换,不需要频繁调用RDD缓存,那我们可以选择DISK_ONLY,让更多的内存空间留给单纯的转换任务。现在我们将pyspark代码中的persist的注释号取消,共有11个持久化注释,我们可搜索MEMORY_AND_DISK_SER进行修改,如
orig_df.persist(StorageLevel.MEMORY_AND_DISK_SER)
svcg_df.persist(StorageLevel.MEMORY_AND_DISK_SER)
....
现在使用之前计算完一样的参数提交任务,本次的测试的变化已在我们的代码中定义。
spark-submit --num-executors 20 --executor-memory 18g --conf spark.executor.cores=3
--conf spark.sql.shuffle.partitions=400 --conf spark.default.parallelism=400
--conf spark.dynamicAllocation.enabled=false spark_no_persist.py
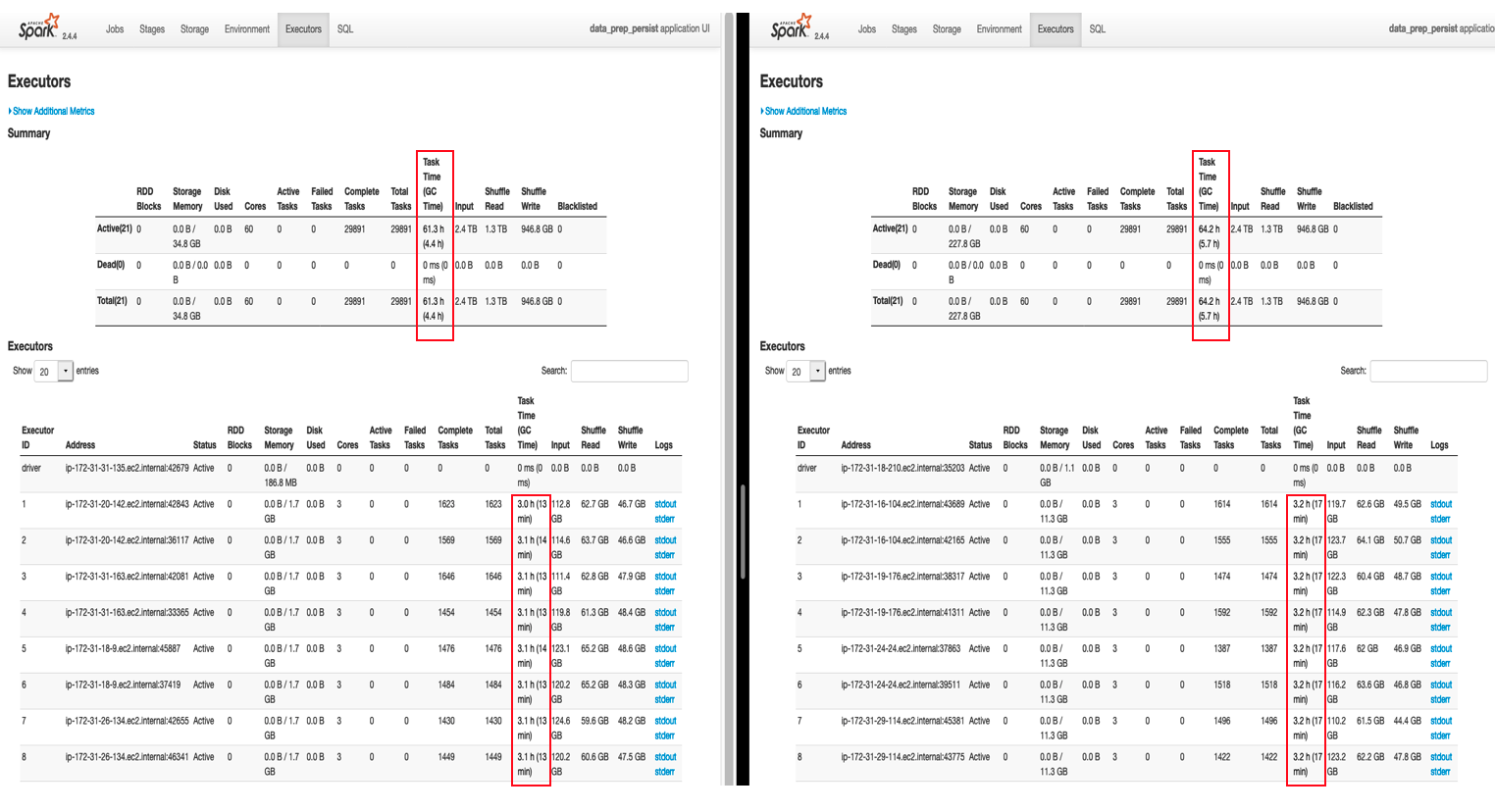
添加了持久化代码的任务耗时1.6小时完成任务。我们可以看见简单的持久化定义操作为我们节省了1倍多时间,可见在Spark作业中对RDD进行数据持久化的重要性。 
值得注意的是,配置RDD持久化无论选择了哪种持久化方式,都应该考虑我们的存储空间是否足够存放数据,例如在EMR硬盘被写满造成如下报错:
ExecutorLostFailure (executor 12 exited caused by one of the running tasks) Reason: Container marked as failed:
container_1572839353552_0008_01_000002 on host: ip-xx-xxx-xx-xx Exit status: -100. Diagnostics: Container released on a *lost* node
我们可以动态的添加EBS卷,挂载到对应的路径并重新启动NodeManager以解决问题,可以在这里查看*lost* node错误排除指导。
Kryo序列化
下面,我们进行数据序列化参数的测试,由于我们的pyspark中进行了序列化的工作,在上面配置的持久化选项中也选择了数据序列化保存的方式,该参数会对我们带来一定优化效果。正如Spark官方文档中说明,通过Kryo序列化将大大提高默认情况下java序列化的压缩度(约10倍),我们将spark.serializer参数设置为“org.apache.spark.serializer.KryoSerializer” 及以下面脚本提交作业。
spark-submit --num-executors 20 --executor-memory 18g
--conf spark.executor.cores=3 --conf spark.sql.shuffle.partitions=400
--conf spark.default.parallelism=400 --conf spark.dynamicAllocation.enabled=false
--conf spark.serializer="org.apache.spark.serializer.KryoSerializer"
--conf spark.dynamicAllocation.enabled=false spark_no_persist.py
在该参数下,任务耗时1.2小时完成。

使用静态内存分配优化Shuffle spill和GC时间
除了计算资源,持久化,序列化等通用的优化手段外,我们下一步可以根据自身作业的数据反馈进行进一步的针对性优化。通过应用程序历史记录页面,我们选取一个上次作业的stage查看: 
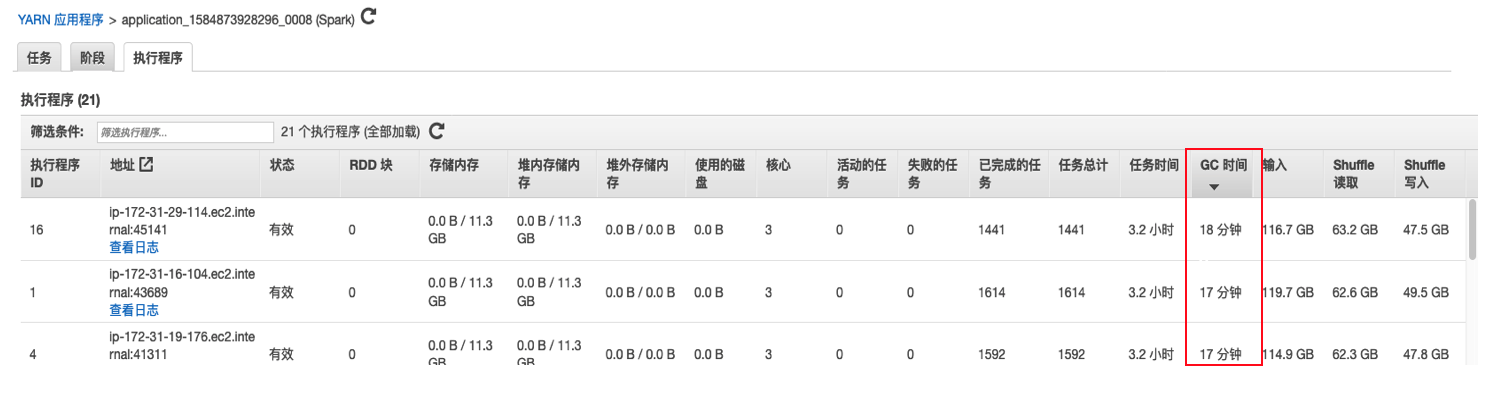
我们发现,作业存在Shuffle spill(内存):492.8 GiB 、Shuffle spill (磁盘):39.0 GiB。 
Executor的GC时间为17~18分钟。 了解这Shuffle spill和GC时间两个数值产生的原因将涉及到对spark中UnifiedMemory和GC回收机制的理解 
在老版本的Spark内存管理中,executor内存中针对Storage空间和Execution空间有清晰的界限划分,任一职能内存空间不能干涉别的空间,由于这样的涉及不够灵活,在Spark1.6版本之后推出了统一内存管理模式,StorageMemory和ExecutionMemory在适当的时候可以借用彼此的Memory,依据默认值作为起始,两种内存比重各为0.5,这样大大的增加了架构的灵活性,降低了运维管理的难度。 但是当我们能清楚的定义自己的作业类型会较多的使用StorageMemory或ExecutionMemory空间时,我们依然可以使用老版本的内存划分方式执行作业,这也将提升作业效率,例如我们的实践中的作业,我们进行了很多转换操作,最好系统一次性加载足够大的数据使用ExecutionMemory的空间进行处理,适当的放弃RDD缓存的空间,减小shuffle过程中spill出去的数据。 GC(Garbage Collector)可以找到内存中哪些数据可能不再使用了将它删除,这个动作在应用请求需要的内存空间而没有对应空闲空间时发生。如果内存中数据量较大,例如长期缓存了RDD数据,就可能频繁的造成内存空间用满,造成 GC 频繁发生,而在GC运行的时候,GC线程会让Task线程直接停下来,让GC线程单独运行,如果能有效的降低GC的评率,缩短GC花费的时间,能为我们的Spark作业起到显著的优化作业,虽然在统一内存管理模式下两种内存可以互相借用并且Execution有绝对优先级,但依然有可能效率低于我们的静态直接配置。那么由于StorageMemory的空间太大或者说缓存的数据过多,RDD缓存长期保存,这将会导致频繁的垃圾回收,降低任务执行时的性能。 我们可以了解以下两个参数:
< spark.shuffle.spill> : 这个参数的默认值是true,用于指定Shuffle过程中如果内存中的数据超过阈值(参考spark.shuffle.memoryFraction的设置)时是否需要将部分数据临时写入外部存储。如果设置为false,那么这个过程就会一直使用内存,会有内存溢出的风险。
< spark.shuffle.memoryFraction> : 参数决定了当Shuffle过程中使用的内存达到总内存多少比例的时候开始spill。通过这个参数可以设置Shuffle过程占用内存的大小,它直接影响了写入到外部存储的频率和垃圾回收的频率。可以适当调大此值,可以减少磁盘I/O次数。
为了降低Shuffle spill和GC时间,现在我们使用以下参数添加到作业脚本中 spark.memory.useLegacyMode=true ,spark.storage.memoryFraction=0.1 ,spark.shuffle.memoryFraction=0.9 使用以下参数命令提交作业
SparkSubmit --conf spark.memory.useLegacyMode=True --conf spark.default.parallelism=400
--conf spark.storage.memoryFraction=0.1 --conf spark.shuffle.memoryFraction=0.9
--conf spark.serializer=org.apache.spark.serializer.KryoSerializer --conf spark.executor.cores=3
--conf spark.sql.shuffle.partitions=400 --conf spark.dynamicAllocation.enabled=false
--num-executors 20 --executor-memory 18g spark.py
1.1小时后,作业完成。我们的作业时间减少了0.1小时。 
查看之前观察的相同的stage ( job 10 stage 95),该任务没有发生任何spill了,能看见参数效果是明显的。

对比两次作业的统计信息: 

最终作业资源使用统计: 
测试总结
以上,我们的性能测试实践将4.5小时的任务优化为1.1小时完成,优化测试先告一阶段,当然还有很多优化的空间值得我们去尝试,例如GC垃圾回收年轻代优化、代码中谓词下推优化、算子优化、map端reduce端缓冲区优化、广播变量优化等,我们可以在未来进行尝试。 总结下我们的测试结果:
优化项
|
使用默认参数及动态资源调配
|
计算最优资源配置
|
RDD持久化
|
Kryo序列化
|
静态分配内存
|
优化参数
|
spark.dynamicAllocation.enabled=ture spark.sql.shuffle.partitions=200 |
num-executors 20 executor-memory 18 spark.executor.cores =3 spark.sql.shuffle.partitions=400 spark.default.parallelism=400 |
orig_df.persist(StorageLevel.
MEMORY_AND_DISK_SER) svcg_df.persist(StorageLevel.
MEMORY_AND_DISK_SER)
|
spark.serializer=org.apache.spark.
serializer.KryoSerializer
|
spark.memory.useLegacyMode spark.storage.memoryFraction=0.1 spark.shuffle.memoryFraction=0.9 |
作业时间
|
任务失败 |
4.5h |
1.6h |
1.2h |
1.1h |
性能提升
|
null |
null |
180% |
30% |
8% |
使用无服务器数据分析进行数据验证
接下来我们进行数据结果的验证并体验AWS云上数据分析的灵活性,我们已经获得S3上的结果表,现在可以主动释放Stop EMR集群资源,并且使用AWS Glue创建表,将表元数据保存到Glue中,使用Amazon Athena进行查询。当然,这些真实房贷金融数据还可以支持我们使用Amazon SageMaker进行更多AI尝试,例如房屋贷款评估模型,防欺诈模型等。下面我们尝试使用Glue和Athena查询我们的结果数据。(ps.在整个测试过程中,我的Spot中断过一次 Master node was terminated due to not enough capacity in the Spot Instance pool,我的同事编写了EMR生产环境中Spot实例的最佳实践可以供大家参考)。 
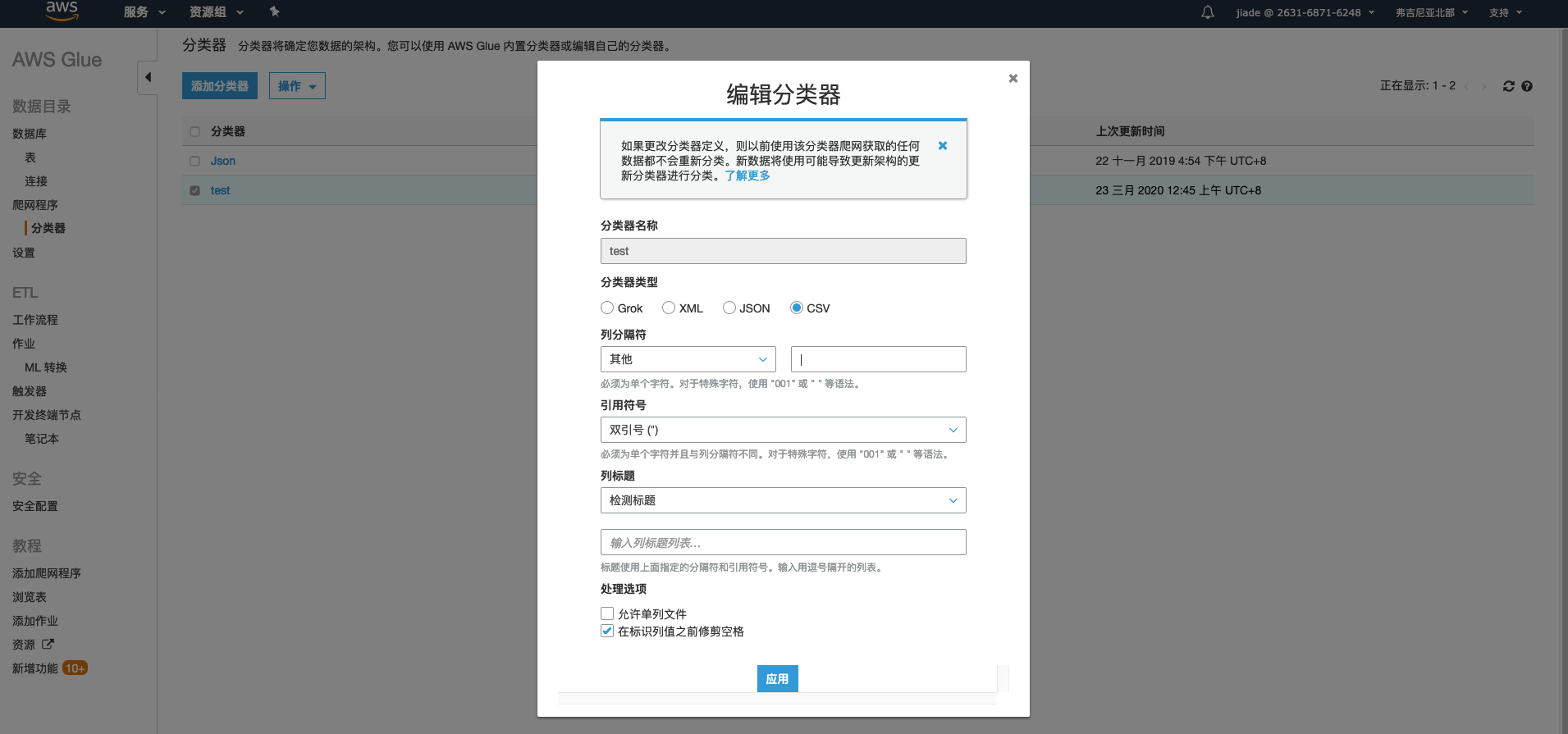
打开Glue 控制台,我们点击 分类器 并使用“|”作为分列符定义一个CSV格式的分类器: 
使用Glue爬网程序,点击创建,依次操作 分类器 –> 填入S3上数据路径 –> 选择带有读取S3桶的IAM权限 –> 选择或创建一个存表结构的数据库 –> 选择按需运行 –> 完成并执行网爬程序。

待网爬程序运行完毕后,我们查看Glue数据库页面,可以看见我们的数据结构被清晰的定义: 
现在我们可以使用Athena进行表操作 进入Athena 控制台 ,点选刚刚创建的表名称,输入查询语句。结果正确返回,验证完毕。 
小结
在本次实践中,我们通过Spot实例创建Amazon EMR集群,使用资源配置参数,数据持久化,数据序列化和定向内存划分进行了运行测试对比和优化分析,并且通过AWS Glue和Amazon Athena进行数据验证。希望本文能为您的Spark作业优化和大数据处理项目构建找到灵感。
本篇作者



 在
在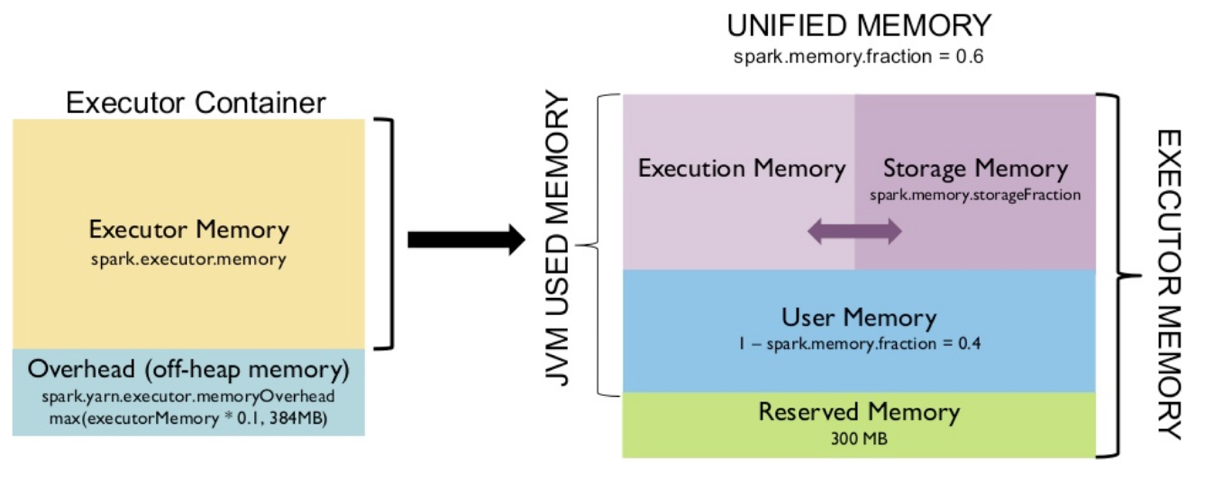
 下面考虑数据的分区数,大部分情况下Spark官方文档中推荐每个CPU core设定2~3个Task,这样将待处理的数据量拆小可以保障一个Task完成后连续的加载下一个Task,因此这个值要设定为(num-executors * executor-cores)的2~3倍。此参数非常重要,不经设定的默认值分区数将由RDD本身的分区去决定,造成较大内存溢出的风险和效率的降低。并且较大的分区数可以把任务分解得更均衡,有效的降低数据倾斜。我们设定为400进行测试。那么我们所计算出的参数为:
下面考虑数据的分区数,大部分情况下Spark官方文档中推荐每个CPU core设定2~3个Task,这样将待处理的数据量拆小可以保障一个Task完成后连续的加载下一个Task,因此这个值要设定为(num-executors * executor-cores)的2~3倍。此参数非常重要,不经设定的默认值分区数将由RDD本身的分区去决定,造成较大内存溢出的风险和效率的降低。并且较大的分区数可以把任务分解得更均衡,有效的降低数据倾斜。我们设定为400进行测试。那么我们所计算出的参数为: