Apache HBase是一种构建在HDFS之上的分布式、面向列的存储系统。在需要实时读写、随机访问超大规模数据集时,作为用户的首选分布式数据库;但HBase也有其局限性,譬如说不支持SQL语句查询,随着数据规模的变大,造成用户成本的大幅增加,其稳定性和故障恢复能力会变差,也给运维人员带来很大的挑战;我们在拜访客户时也发现有些用户将大量的历史数据和在线数据全部存储在HBase中也遇到了上述问题。因而本文将介绍一种帮助用户从HBase数据库中剥离出历史数据,减小HBase数据库的规模,提高其稳定性并大幅降低客户的成本,实现对历史数据的查询的方案。
Apache HBase 特点及应用场景
Apache HBase是一个分布式,版本化,面向列的开源数据库,构建在Aapche Hadoop 和Aapche ZooKeeper之上。它特别适合千万级的高并发海量数据的瞬间写入,而相对读数据量小的应用,支持存储结构化和非结构化数据和数据的多版本化。但它不适合大范围的扫描查询和支持多条件的查询,不支持基于SQL语句的查询。
Amazon Athena特点及应用场景
Amazon Athena 是一种交互式查询服务,让您能够轻松使用标准 SQL 直接分析 Amazon S3 中的数据。只需在 AWS 管理控制台中单击几下,客户即可将 Athena 指向自己在 S3 中存储的数据,然后开始使用标准 SQL 执行临时查询并在数秒内获取结果。Athena 是Serverless服务,因此没有需要设置或管理的基础设施,客户只需为其执行的查询付费。它特别适合使用 Athena 处理日志、执行即席分析以及运行交互式查询。Athena 可以自动扩展并执行并行查询,因此可快速获取结果,对于大型数据集和复杂查询也不例外。
本次实验演示的Demo数据来自于纽约出租车公司公布的公开数据源2017年1月到6月份Green Taxi trip 数据,下载链接:https://www1.nyc.gov/site/tlc/about/tlc-trip-record-data.page。
准备模拟数据并上传到S3 Bucket
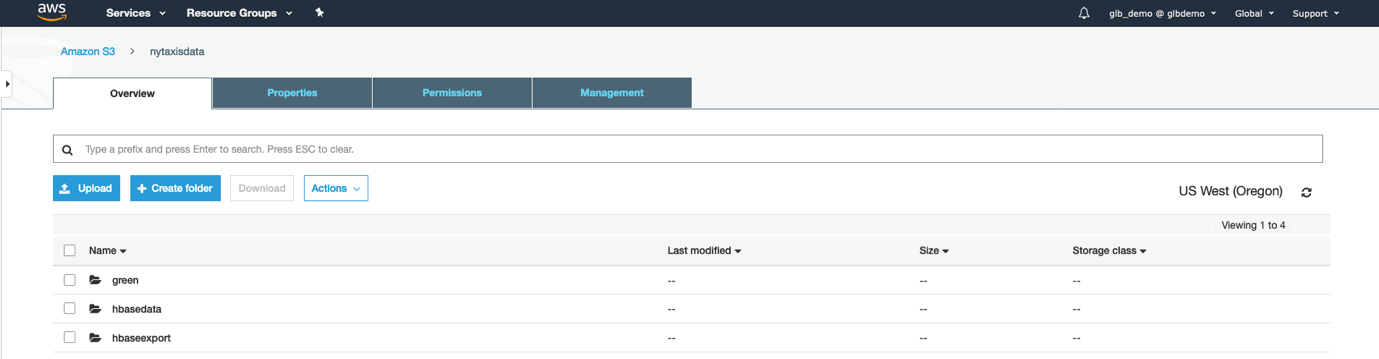
登陆AWS 管理控制台,创建S3 bucket 命名为nytaxisdata,然后创建三个文件夹分别命名为green,hbasedata,hbaseexport如下图所示:

处理数据
清理掉原始数据中的空格列,运行如下命令:
awk 'BEGIN{FS=OFS=","}{gsub(/ /,"-",$2);gsub(/ /,"-",$3);print $0}' green_tripdata_2017-01.csv |more
[hadoop@ip-172-31-28-170 ~]$ awk 'BEGIN{FS=OFS=","}{gsub(/ /,"-",$2);gsub(/ /,"-",$3);print $2,$3,$1,$6,$7}' green_tripdata_2017-01.csv >>greentrip01.csv
如下图所示:

分别依次处理完对应的6个excel文件。然后将处理完的2017年1月到6月份的数据文件上传到green文件夹内,如下图所示:

创建EMR集群
登陆到AWS 管理控制台,选择EMR 服务,点击创建集群,如下图所示:

点击Go to Advanced options,选择Hadoop和 HBase服务如下图所示:

在Storage Mode中选择S3,并设置上面刚创建的bucket路径s3://nytaxisdata/hbasedata,如下图所示:

在Hardware Configuration设置中选择Uniform instance groups,并设置网络,子网组及根卷大小,此处设置为100G,如下图所示:

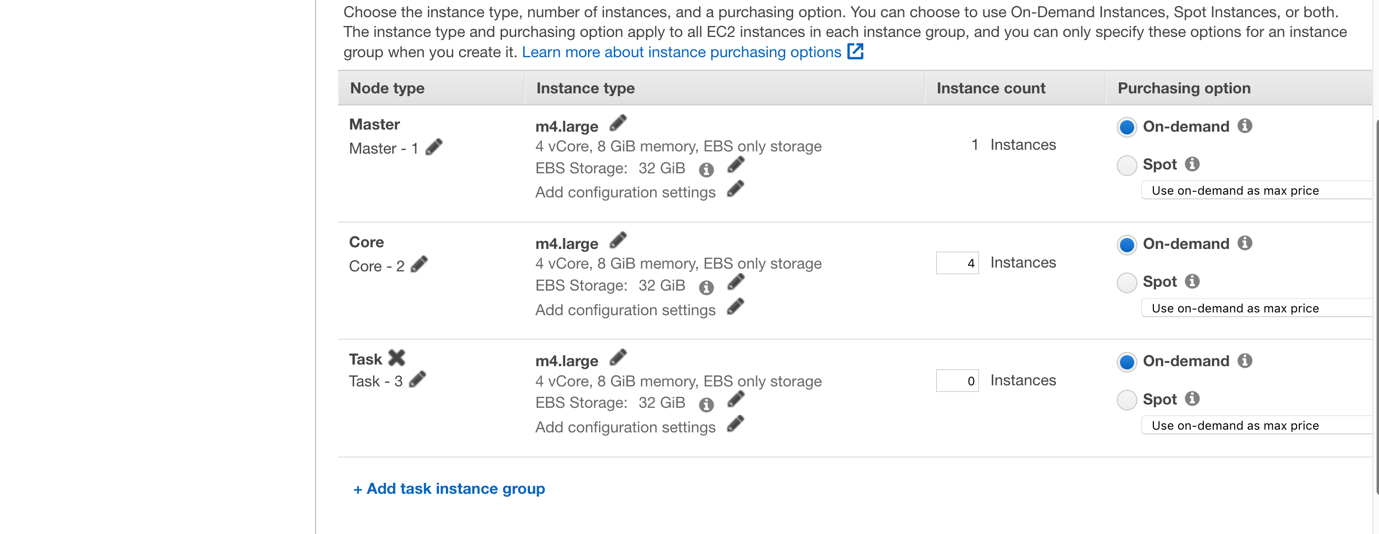
点击下一步,设置EMR集群的节点类型和实例数,如下图所示:

点击下一步输入集群名称hbasecluster,其他默认即可,如下图所示:

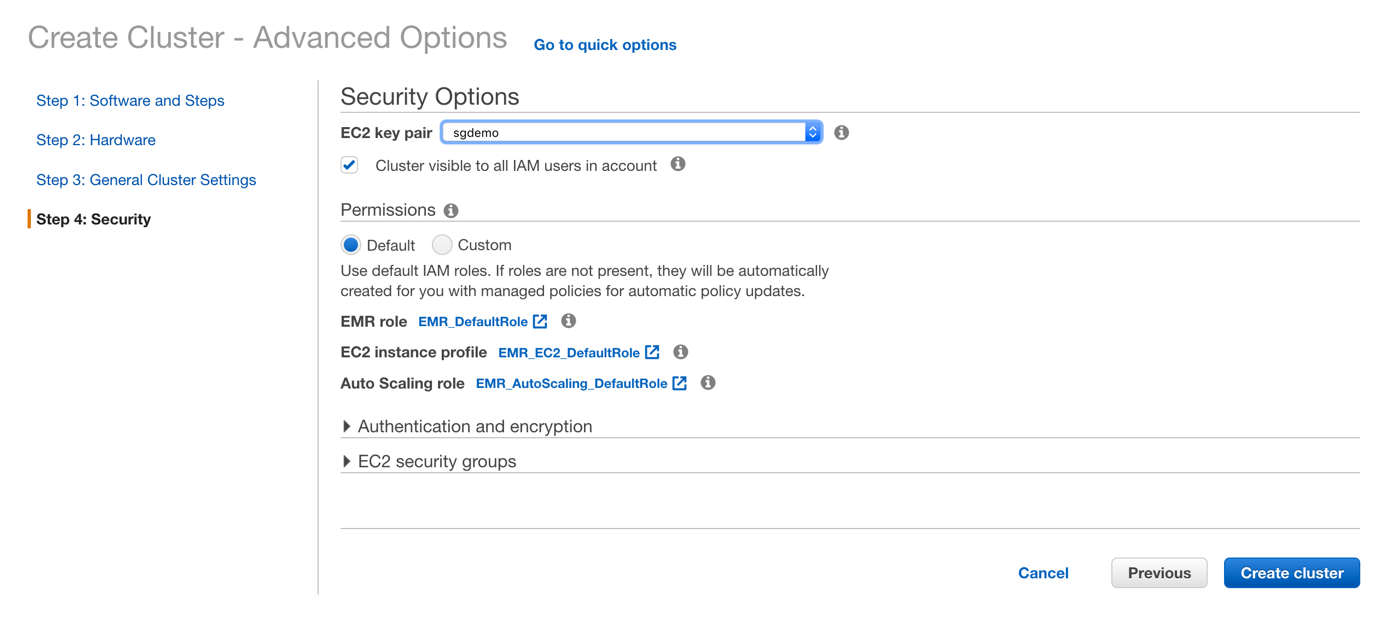
点击Next,设置EC2 key pair,如下图所示:

点击Create cluster,等待集群创建完成。
登陆HBase集群
创建一个表名为taxiinfo的表,指定列簇为userinfo 和Others,运行如下命令:
hbase(main):001:0> create 'taxiinfo','dropofftime','comno','others'
如下图所示:

导入数据到HBase集群
运行如下命令:
sudo hbase org.apache.hadoop.hbase.mapreduce.ImportTsv -Dimporttsv.separator="," -Dimporttsv.columns=HBASE_ROW_KEY,dropofftime,comno,others:distance,others:length taxiinfo s3://nytaxisdata/green/greentrip01.csv
一次运行上面的命令将greentrip01.csc到greentrip06.csv文件全部导入到hbase数据库名为taxiinfo中。
统计表中的数据总行数,运行命令count,如下所示:
hbase(main):002:0> count 'taxiinfo',INTERVAL=>100000
Current count: 100000, row: 2017-01-04-22:58:55
Current count: 200000, row: 2017-01-08-16:39:14
Current count: 300000, row: 2017-01-12-15:35:40
……
Current count: 4300000, row: 2017-06-04-03:39:03
Current count: 4400000, row: 2017-06-08-09:56:53
Current count: 4500000, row: 2017-06-11-18:32:27
Current count: 4600000, row: 2017-06-15-20:14:35
Current count: 4700000, row: 2017-06-19-13:37:54
Current count: 4800000, row: 2017-06-23-15:21:13
Current count: 4900000, row: 2017-06-27-14:46:20
4989642 row(s) in 257.1330 seconds
=> 4989642
至此,验证HBase中的数据准备完毕。
剥离HBase数据库中的历史数据
根据需要用户可以将HBase数据库中的历史数据进行导出,HBase数据库中的数据导出为CSV文件有多种方式,譬如自己编写MapReduce类实现,或者借助Pig应用等,本文采用happybase包实现。HappyBase是方便开发人员通过python实现与HBase进行交互的开发库,通过编写Python脚本方式非常灵活的将任意条件的存储在HBase中的数据抽取处理转换成CSV文件。
安装HappyBase
登陆到EMR Master节点,运行如下命令:
[hadoop@ip-172-31-36-88 ~]$ sudo pip install happybase
如下图所示:

导出HBase数据
编写Python脚本如下所示:
import happybase, sys, os, string
# 设置导出数据目录/mnt
# Output directory for CSV files
outputDir = "/mnt"
# HBase Thrift server to connect to. Leave blank for localhost
server = ""
# 连接到HBASE数据库
c = happybase.Connection(server)
# Get the full list of tables
tables = c.tables()
# 轮询数据库中的所有表
for table in tables:
# 写文件
file = open(outputDir + "/" + table + ".csv", "w")
t = c.table(table)
print table + ": ",
count = 0
for prefix in string.printable:
try:
for key, data in t.scan(row_prefix=prefix):
# 第一个key
if count == 0:
startRow = key
for col in data:
value = data[col]
column = col[col.index(":")+1:]
# 写行,列,值
file.write("%s, %s, %s\n" % (key, column, value))
count += 1
except:
os.system("hbase-daemon.sh restart thrift")
c = happybase.Connection(server)
t = c.table(table)
continue
# 最后一个key
endRow = key
print "%s => %s, " % (startRow, endRow),
print str(count)
保存运行命令:
python hbase_export_csv.py
如下图所示数据导出4989642:

将导出的csv文件上传到s3://nytaxisdata/exportdata文件夹下,如下图所示:

使用Amazon Athena实现对历史数据的查询
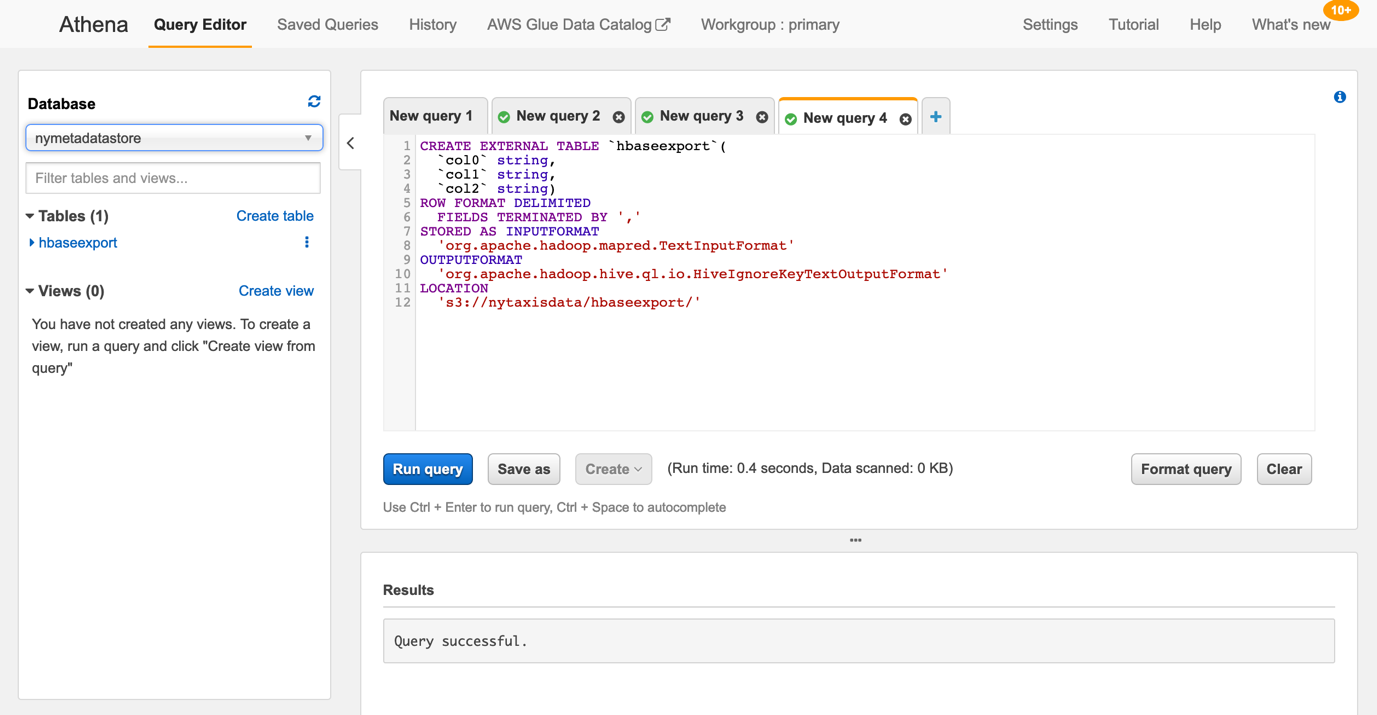
打开AWS Athena 管理控制台,运行如下命令:
CREATE EXTERNAL TABLE `hbaseexport`(
`col0` string,
`col1` string,
`col2` string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
's3://nytaxisdata/hbaseexport/'
如下图所示:

数据查询
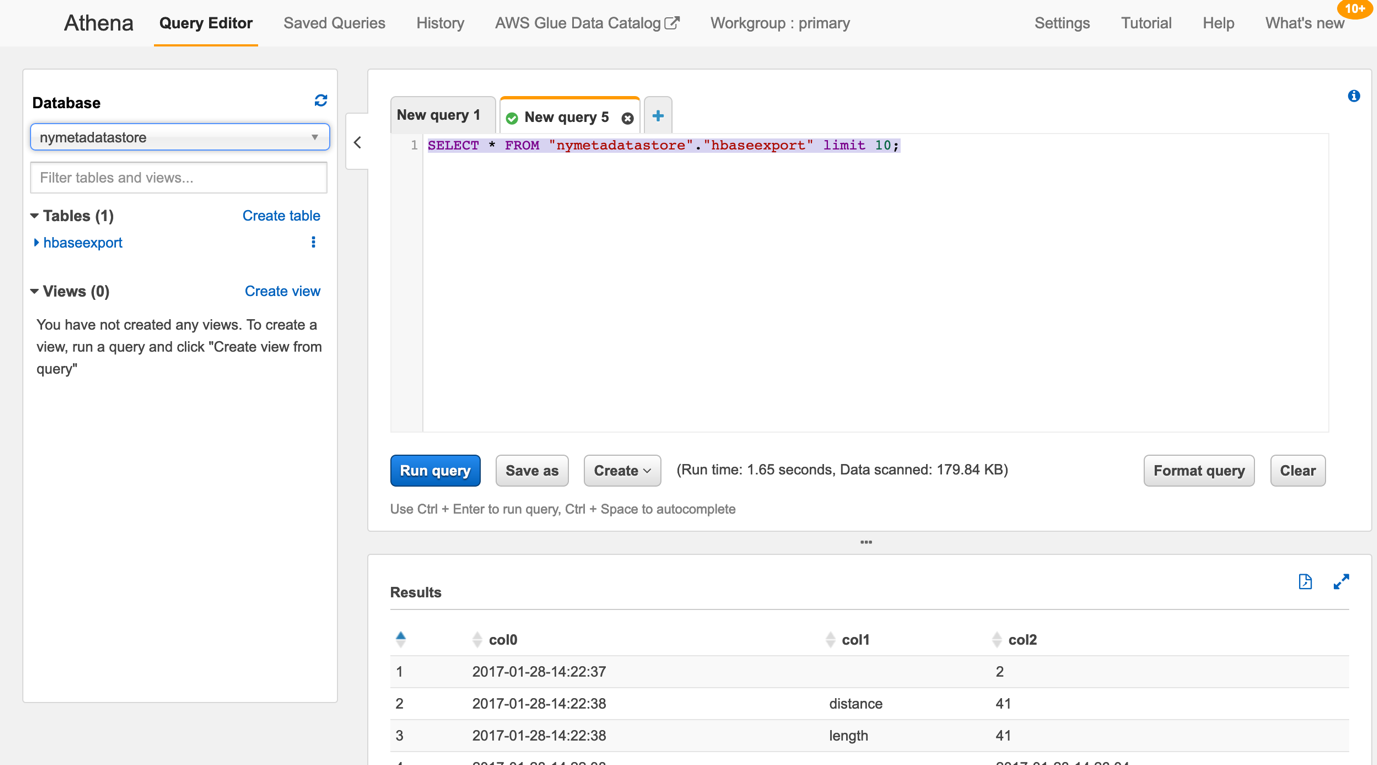
在SQL脚本编写区,运行如下查询:
SELECT * FROM "nymetadatastore"."hbaseexport" limit 10;
如下图所示:

总结
通过本篇您将了解到如何使用使用HappyBase库编写Python脚本实现将HBase数据库中的历史数据的随意抽取并转换成csv文件,利用Athena实现对存储在S3上数据文件的访问。该方案可以帮助客户减小HBase集群,大幅降低数据的访问成本。
本篇作者